文章目录
一、什么是分类问题
在分类问题中,因变量是离散型变量,如:是否患癌症,西瓜是好瓜还是坏瓜等。
二、如何解决分类问题
- 首先,拿到数据需要确定属于什么性质类的问题,回归还是分类?
- 然后,探索性分析不同特征之间的特点,相关性等等。
- 接着,了解回归模型有哪些,以及他们之间的使用场景,优缺点等等。
- 最后,用分类模型建立模型。
三、分类模型有哪些
贝叶斯、决策树、逻辑回归、XGBoost等
四、作业
-
回归问题和分类问题的联系和区别,如何利用回归问题理解分类问题?
答:
相同点:他们都属于有监督学习,都是对输入的数据进行预测。
不同点:输出的类型不一样。回归问题输出的是连续型变量,是一种定量输出。分类问题输出的是离散型变量,是一种定性输出。
分类问题是回归问题的一种特殊情况,如果将连续的数据离散化就变成了分类问题。 -
为什么分类问题的损失函数可以是交叉熵而不是均方误差?
答:交叉熵使得梯度与绝对误差成正比,均方误差导致梯度变得扭曲。
神经网络中如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛,如果预测值与实际值的误差小,各种参数调整的幅度就要小,从而减少震荡。
使用平方误差损失函数,误差增大参数的梯度会增大,但是当误差很大时,参数的梯度就会又减小了。
使用交叉熵损失是函数,误差越大参数的梯度也越大,能够快速收敛。 -
线性判别分析(LDA)和逻辑回归(LR)在估计参数方面有什么异同点?
答:从形式上看LDA和LR的log-ratio(对数几率)具有相同的形式,但它们其实并不是一样的模型。
不同点:
- 假设不同。LDA需要假设x服从正态分布,LR无此假设。
- 参数估计方式不同。LDA根据样本计算均值和协方差矩阵,然后带入判别式。LR使用极大对数似然估计参数。
- 模型意义不同。LDA属于生成模型,用到样本的先验信息,极大化后验概率,maximizing full log-likelihood。LogitsR属于判别模型,只考虑给定x时的条件概率,maximizing conditional log-likelihood。LR概率等价于每个类别具有相同先验概率时的贝叶斯后验概率。
优缺点比较:
-
LDA不稳健,容易受异常值影响,可以采取一些稳健的均值和协方差估计方法。Sigmoid函数将任意x对应的类别概率压缩到[0,1]内,再使用相对熵损失函数,因此LR是稳健的。
-
LDA适用于半监督学习。回忆一下没有label的混合高斯分布,可以用EM算法估计出每一类的均值和方差。现在的情况是,有一堆样本,其中部分样本有label,部分样本没有label。我们仍可以用EM算法估计每一类的均值和方差,只不过有label的那部分样本所属类别确定。这其实就是半监督的LDA学习。LR不适用于半监督学习。
-
尝试从0推到svm?(面试题)
答:线性支持向量机 (SVM) 是一种线性二分类模型,需要满足:
找到一组合适的参数 (w, b),使得
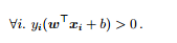
即线性二分类模型希望在特征空间找到一个划分超平面,将属于不同标记的样本分开。 -
二次判别分析,线性判别分析,朴素贝叶斯之间的联系和区别?
-
使用python+numpy实现逻辑回归?
-
了解梯度下降法,牛顿法,拟牛顿法与smo算法等优化算法?
五、总结
分类问题可以使用很多模型来解决,但是要了解什么模型适用什么样的条件,以及模型的优缺点,这样就可以快速有效的得到预测结果。