之前已经用RNN和CNN进行文本分类,随着NLP的热门,又出现了大热的Attention,Bert,GPT等模型,接下来,就从理论进行相关学习吧。接下来,我们会经常听到“下游任务”等名词,下游任务就是NLP领域称之为利用预先训练的模型或组件的监督学习任务。
目录
1 学习路径

2 Seq2Seq
Seq2Seq全称是Sequence to Sequence,称之为序列到序列模型,是RNN的一个变体,常用于机器翻译、语音识别、自动对话等任务。其核心思想是通过深度神经网络将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码输入到解码输出两个环节构成。编码器Encoder和解码器Decoder各由一个循环神经网络构成,两个网络是共同训练的。

Encoder-Decoder模型能有效地解决建模时输入序列和输出不等长的问题。Seq2Seq的编码器就是循环神经网络(RNN,LSTM,GRU),将句子输入至encoder中,生成一个Context vector,Context vector是Encoder的最后一个hidden state,即将输入句压缩成固定长度的context vector,再通过Decoder将context vector内的信息产生输出句。相关函数为:
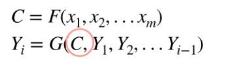

其中,C为编码器函数,Y为解码器函数。
解码时采用集束搜索策略,会保存b个当前的较佳选择,然后解码时每一步根据保存的选择进行下一步扩展和排序,接着选择前b个进行保存,循环迭代直到找到最佳结果。
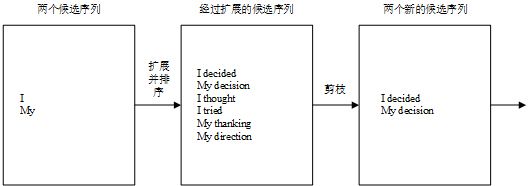
除此之外,堆叠RNN、增加Dropout机制、与编码器之间建立残差连接等均是常用的改进措施。但是在实际应用中,会发现随着输入序列的增长,模型的性能发生了显著的下降。因为编码时输入序列的全部信息压缩到了一个向量表示,随着序列增长,句子越前面的词的信息丢失就越严重。同时,Seq2Seq模型的输出序列中,会损失部分输入序列的信息,在解码时,当前词及对应的源语言词的上下文信息和位置信息丢失了。
3 Attention
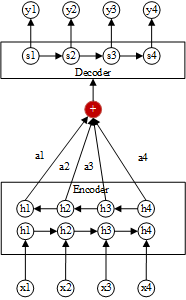
为解决上述存在的问题(句子过长,效果不佳),引入了注意力机制(Attention Mechanism),改进点为:Seq2Seq编码之后有一个固定长度的context vector,Attention模型是生成N个(N个输入文字)固定长度的context vector,结构如图所示:
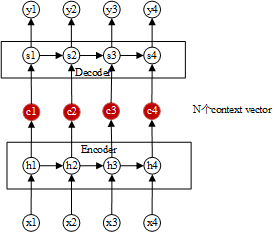
context vector是输入序列全部隐藏状态的一个加权和,即attention score乘以一个输入的隐状态,其计算为:
![]()
神经网络a将上一个输出序列隐状态和输入序列隐状态
作为数据,计算得到
,然后归一化,得到
(此时存在一个softmax操作),用来衡量输入句中的每个文字对目标句中的每个文字所带来重要性的程度。其score计算为
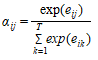
![]()
Attention模型的编码器是双向RNN(Bi-directional RNN),每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。
Attention model虽然解决了输入句仅有一个contect vector的缺点,依然存在很多问题:
- context vector计算的是输入句、目标句间的关联,却忽略了输入句中文字间的关联,和目标句中文字间的关联性
- RNN的自身缺点就是无法平行化处理,导致模型训练的时间很长
4 Transformer
2017年,发表了“The transformer”模型,解决了传统的Attention model 无法平行化的缺点,主要概念有(1)self attention (2)Multi-head。The Transformer和Seq2Seq有一样的结构,Encoder和Decoder,Transformer的结构是有6个Encoder和6个Decoder,结构如下:

细节结构展示:
(1)位置编码(Positional Encoding)
因为该模型并不包括任何的循环或卷积神经网络,所以模型添加了位置编码,为模型提供了关于单词再句子中相对位置的信息。这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。计算方法如下:
偶数位置用正弦,奇数位置用余弦。
(2)编码器(Encoder)
Encoder的编码结构是一层self Attention,一层Feed Forward,self Attention是得到一个矩阵来最终Feed Forward的输入,在进行Feed Forward之前,还进行了残差连接和归一化操作。Feed Forward是前馈神经网络,常用的有DNN、CNN等。

a.自身注意力(self Attention)
self Attention结构里是分为Scaled-Dot-Product Attention 和Multi head Attention。
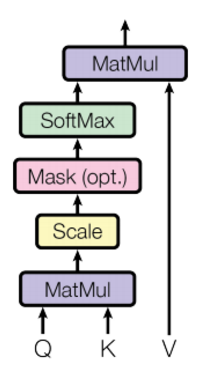
(一)Scaled-Dot-Product Attention
Scaled-Dot-Product Attention首先要计算Q(Query),K(Key),V(Value)矩阵,输入句中的每个文字是由一系列成对的<key,value>组成,而目标中的每个文件是Query,则如何用Q,K,V来重新表示context vector呢?
首先计算Query和各个key的相似性,得到每个key对应value的权重系数,即为attention score,value是对应的讯息,再对value进行加权求和得到最终的Attention。计算过程如下:
Attention到self Attention的变化为:
![]() ——>
——>
——> 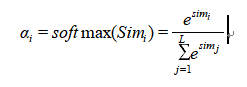
![]() ——>
——>
为避免内积过大,使得softmax之后的结果非1即0,在计算相似性的时候增加一个,即变为

Transformer是进行并行计算的,计算过程(忽略了的计算)如图所示:

(二)Multi-head Attention
只计算单个Attention很难捕捉输入句中所有空间的讯息,为了优化模型,论文提出了一个multi head的概念,把key,value,query线性映射到不同空间h次,但是在传入Scaled-Dot-Product Attention中时,需要固定的长度,因此再对head进行concat,结构如下:

Multi-head attention由四部分组成:
-
用linear并分拆成Multi head;
-
经过Scaled-Dot-Product Attention生成n个z矩阵;
-
concat,新增一个权重系数,将z1,...,zn,合并成z传入下一层;
-
再增加一层Linear Layer。
Multi Head Attention的过程如下(以两个head为例):

b.残差连接(Residual Connections)
在进行self attention和feed forward两个模块连接时,增加一个sub layer,主要进行residual connection和layer normalization。
深度学习常见的归一化有BN(Batch Normalization)、LN(Layer Normalization),Batch Normalization 的处理对象是对一批样本进行纵向处理, Layer Normalization 的处理对象是单个样本,禁止横向处理。Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
为什么Transformer用LN,而不用BN?
1)layer normalization 有助于得到一个球体空间中符合0均值1方差高斯分布的 embedding, batch normalization不具备这个功能。
2) layer normalization可以对transformer学习过程中由于多词条embedding累加可能带来的“尺度”问题施加约束,相当于对表达每个词一词多义的空间施加了约束,有效降低模型方差。batch normalization也不具备这个功能。
LN用于RNN进行Normalization时,取得了比BN更好的效果。但用于CNN时,效果并不如BN。
只有一个编码器(Encoder)时的结构:

有多个编码器和解码器的结构:

c.前馈神经网络(Feed Forward)
模型里边是增加了两个dense层,就是普通的全连接层。
(3)解码器(Decoder)
解码器和编码器相比略有不同,在解码器中,只允许self Attention的输出序列中较早的位置,通过在self Attention计算的softmax步骤之前屏蔽未来位置(将它们设置为-inf)来完成的。
每个解码器层包括以下子层:
- 遮挡的多头注意力(padding mask和sequence mask)
- 多头注意力(用填充遮挡)。V(数值)和 K(主键)接收编码器输出作为输入。Q(请求)接收遮挡的多头注意力子层的输出。
- 点式前馈网络
- 每个子层在其周围有一个残差连接,然后进行层归一化。
a、masked mutil-head attetion
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
(4)线性层和softmax层( Linear and Softmax Layer)
在解码器(Decoder)之后有增加了一层Linear和Softmax,结构如下:

(5)常见面试题
a、
b、self-attention为什么要缩放,并选用?
缩放是为了防止梯度消失。
softmax把一些输入映射为0-1之间的实数,并且归一化保证和为1,公式为:
基于Transformer的模型另开一篇博客,细节太多了。
参考:
https://jalammar.github.io/illustrated-transformer/
https://www.sohu.com/a/258474757_505915
https://tensorflow.google.cn/tutorials/text/transformer#创建_transformer
https://www.aboutyun.com/thread-27818-1-1.html
https://www.jianshu.com/p/367c456cc4cf
Transformer——李宏毅视频
https://www.zhihu.com/question/395811291/answer/1260290120