1 FastText 学习路径
FastText 是 facebook 近期开源的一个词向量计算以及文本分类工具,FastText的学习路径为:
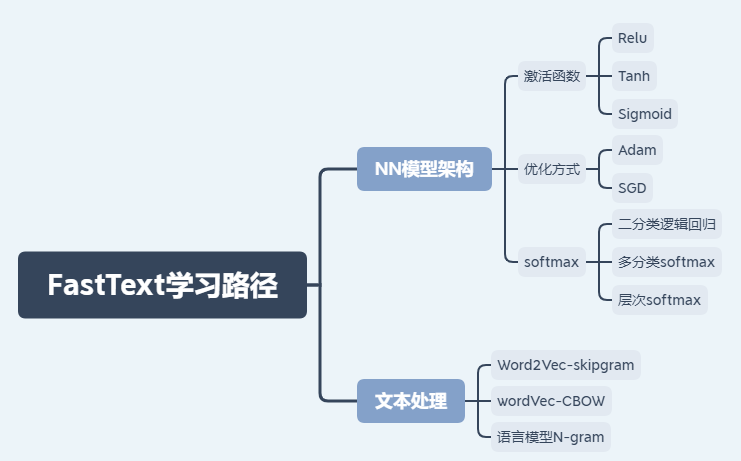
具体原理就不作解析了,详细教程见:https://fasttext.cc/docs/en/support.html
2 FastText 安装
2.1 基于框架的安装
需要从github下载源码,然后生成可执行的fasttext文件
(1)命令:git clone https://github.com/facebookresearch/fastText.git

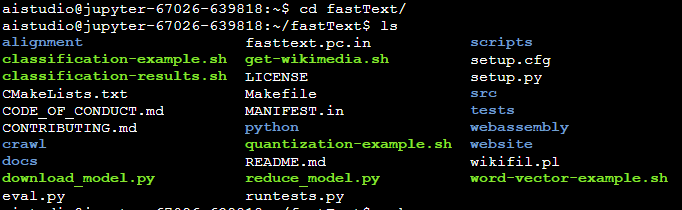
(2)命令:cd fastText/ and ls
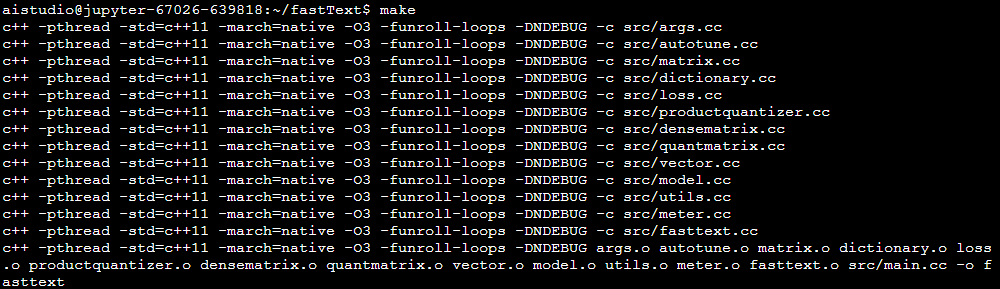
(3)命令:make
2.2 基于Python模块的安装
(1)直接pip安装:pip install fasttext
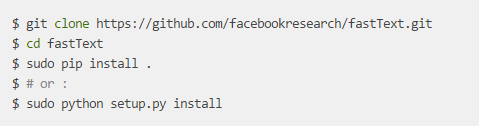
(2)源码安装:
3 FastText 实现文本分类
3.1 例子
(1)下载数据
#读取数据
wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz
#解压数据
tar xvzf cooking.stackexchange.tar.gz
#显示前几行
head cooking.stackexchange.txt(2)划分数据集
#查看数据
wc cooking.stackexchange.txt
#划分数据集
head -n 12404 cooking.stackexchange.txt > cooking.train
tail -n 3000 cooking.stackexchange.txt > cooking.valid
(3)训练与调参
此处是基于命令行的展示,Python的展示可参考:https://fasttext.cc/docs/en/supervised-tutorial.html
fasttext的参数有:
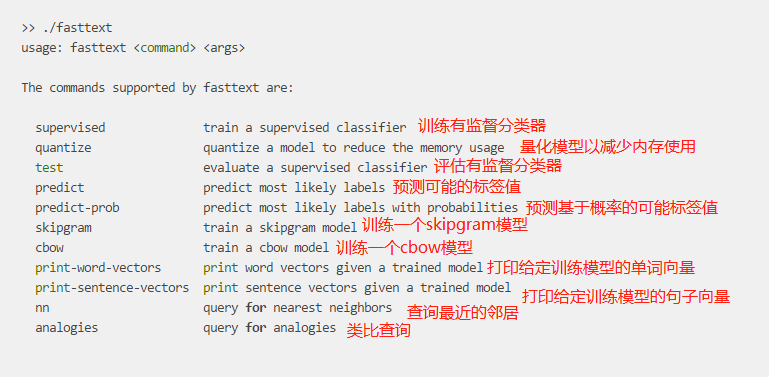
训练:
./fasttext supervised -input cooking.train -output model_cooking预测:
./fasttext predict model_cooking.bin -3.2 基于新闻文本的FastText分析
import fasttext
import pandas as pd
from sklearn.metrics import f1_score
train_df = pd.read_csv('data/data45216/train_set.csv',sep='\t')
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv',index=None,header=None,sep='\t')
model = fasttext.train_supervised('train.csv',lr=1.0,wordNgrams=2,verbose=2,minCount=1,epoch=25,loss='hs')
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str),val_pred,average='macro'))
输出结果为:
4 FastText调参
FastText的train_supervised参数有:

可通过以上参数进行手动设置,也可用过FastText的自动调参功能进行调参。
4.1 基于命令行
(1)验证集验证-autotune-validation
./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid(2)设置执行时间-autotune-duration
./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid -autotune-duration 600(3)模型大小 -autotune-modelsize
./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid -autotune-modelsize 2M(4)指标 -autotune-metric
-autotune-metric f1:__label__baking
-autotune-metric precisionAtRecall:30
-autotune-metric precisionAtRecall:30:__label__baking
-autotune-metric recallAtPrecision:30
-autotune-metric recallAtPrecision:30:__label__baking4.2 基于Python模块
(1)验证集验证autotuneValidationFile
model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid')(2)设置执行时间autotuneDuration
model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid', autotuneDuration=600)(3)模型大小autotuneModelSize
model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid', autotuneModelSize="2M")(4)指标 autotuneMetric
model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid', autotuneMetric="f1:__label__baking")5 作业
使用自动调参进行训练:
import fasttext
import pandas as pd
from sklearn.metrics import f1_score
train_df = pd.read_csv('data/data45216/train_set.csv',sep='\t')
#将label值转成fasttext识别的格式
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
#划分训练集和验证集
train_df[['text','label_ft']].iloc[:10000].to_csv('train.csv',index=None,header=None,sep='\t')
train_df[['text','label_ft']].iloc[10000:15000].to_csv('valid.csv',index=None,header=None,sep='\t')
#建立模型
model = fasttext.train_supervised('train.csv',lr=1.0,wordNgrams=2,verbose=2,minCount=1,epoch=25,loss='hs',autotuneValidationFile='valid.csv',autotuneMetric="f1:__label__baking")
#预测
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str),val_pred,average='macro'))