聚类分析与k均值聚类算法
督学习算法。在给定样本的情况下,聚类分析通过度量特征相似度或者距离,将样本自动划分为若干类别。
距离度量和相似度度量方式
距离度量和相似度度量是聚类分析的核心概念,大多数聚类算法建立在距离度量之上。常用的距离度量方式包括闵氏距离和马氏距离,常用的相似度度量方式包括相关系数和夹角余弦等。
相关系数。
相关系数(correlation coefficent)是度量样本相似度最常用的方式。相关系数越接近1,表示两个样本越相似;相关系数越接近0,表示两个样本越不相似。

夹角余弦。
夹角余弦(angle cosine)也是度量两个样本相似度的方式。夹角余弦越接近1,表示两个样本越相似;夹角余弦越接近0,表示两个样本越不相似。
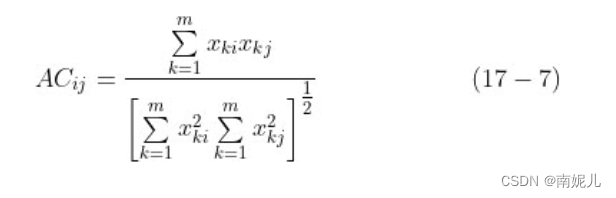
聚类算法
聚类算法通过距离度量将相似的样本归入同一个簇(cluster)中,这使得同一个簇中的样本对象的相似度尽可能大,同时不同簇中的样本对象的差异性也尽可能大
常用的聚类算法有如下几种:
- 基于距离的聚类,该类算法的目标是使簇内距离小、簇间距离大
- 基于密度的聚类,该类算法是根据样本邻近区域