这篇文章主要解答的一个问题就是:
kylin 是什么 ?
根据官方的介绍 http://kylin.apache.org/cn/docs/
这篇博客也很优秀:http://tech.meiyou.com/?p=97
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc.开发并贡献至开源社区。

关键词:
开源
任何人都可以接触到源代码,目前已经贡献给Apache基金会,并成为顶级项目
分布式
基于 mr , spark 的底层计算, 实现分布式计算
基于hbase的计算结果存储,实现分布式调用
分析引擎
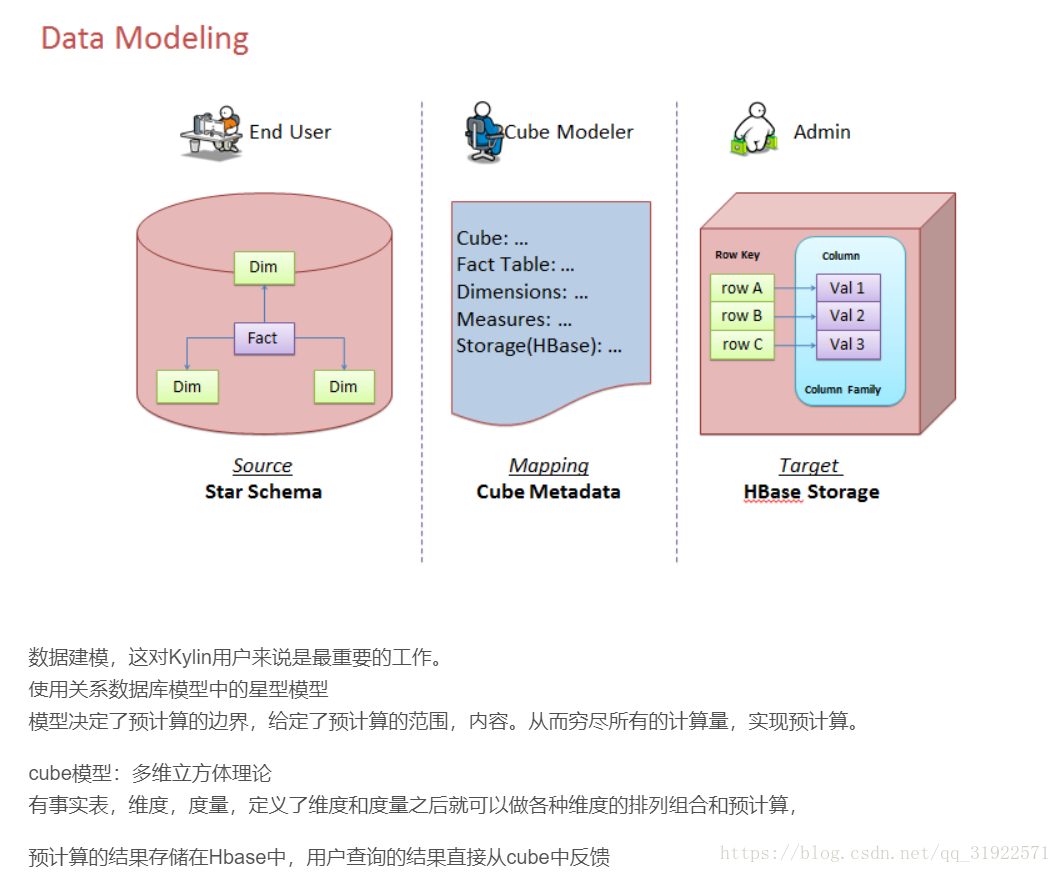
cube建模,三维立体的数据集合,对于任意二维的组合,都可以实现,也就让数据分析的需求更加容易落地.
Kylin的核心思想是利用空间换时间,由于查询方面制定了多种灵活的策略,进一步提高空间的利用率,使得这样的平衡策略在应用中是值得采用的
Hadoop之上
Hadoop解决了分布式存储,分布式计算,分布式协调等基础问题.kylin可以对Hadoop上的数据(hive) 进行SQL操作, 达到一个预处理,预计算的效果.
SQL查询接口
kylin的结果数据,可以提供SQL查询. 并且 拥有JDBC API . 方便程序扩展
多维度OLAP
STEP1. 根据Cube定义的事实表和维度,在Hive中生成一张中间表;
STEP2. 使用MapReduce,从事实表中抽取维度的Distinct值,并以字典树的方式压缩编码,同时也对所有维度表进行压缩编码,生成维度字典;
STEP3. 计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid;
STEP4. 创建HBase Table;
STEP5. 利用step1中间表的数据,使用MapReduce,生成每一种维度组合的数据;
STEP6. 将Cuboid数据转换成HFile,并导入到HBase Table中:
STEP7. 更新Cube信息,清理中间表:
整个Build过程结束。
cube 建模过程结束以后,我们就可以进行多维度的OLAP分析了
Cube是一种典型的多维数据分析技术,一个Cube可以有多个事实表,多个维表构成。
1、维度组合Cuboid
Cube是所有的维度组合,任一维度的组合称为cuboid。
理论上来说,一个N维的Cube,便有2的N次方种维度组合(Cuboid),一个Cube包含time,item, location, supplier四个维度,那么组合便有16种:
Kylin中Cube的Build过程,其实是将所有的维度组合事先计算,存储于HBase中,以空间换时间,HTable对应的RowKey,就是各种维度组合,指标存在Column中。
这样,将不同维度组合的查询SQL,转换成基于RowKey的范围扫描,然后对指标进行汇总计算。
2、Kylin构建Cube的过程
如下图所示:
超大规模
只要你有足够的hbase存储kylin结果,那规模肯定是巨大的
因为进行了预处理,所以才会快