目前在目标检测方面有着众多的检测框架,比如两阶段的FasterRcnn、以及yolo系列的众多模型。yolo系列在实际中用的最多,一方面性能确实不错,另一方面具有着较多的改进型系列。今天我们主要使用的yolov5系列。具体原理过程就不多说了,大家自行百度。放一张v5的网络结构图。
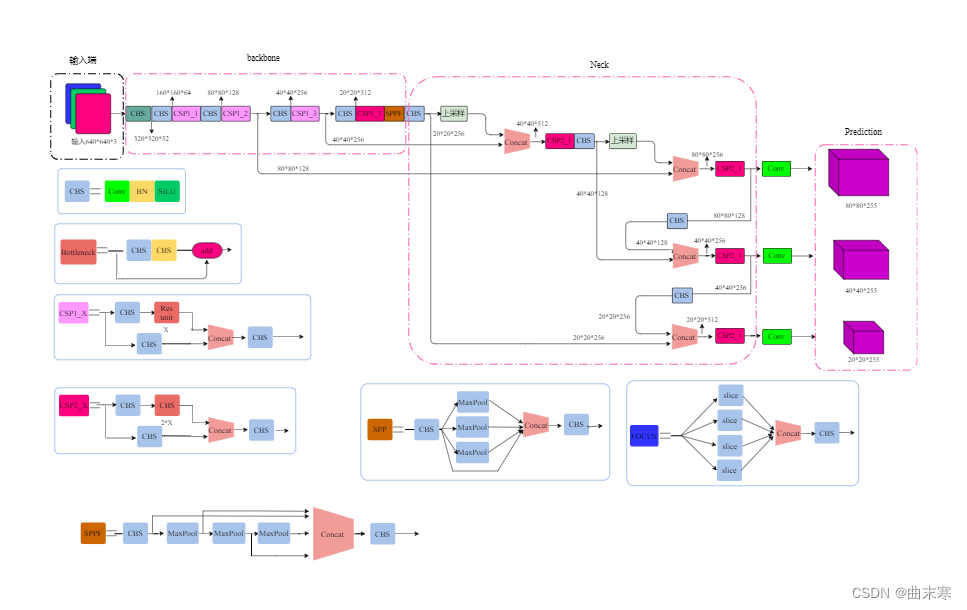
在目标检测中小目标检测尤为困难,而众多yolo系列的预训练模型主要针对COCO数据集来训练的,整体的MAP看上去还不错,但是用到小目标确实不行,尤其是图像尺寸比较大的小目标,那效果更是辣眼睛了。
在众多文章中有对小目标进行改进的比如添加一个检测头(四个检测头,对一些数据集确实有一定的作用),再者一些博客有介绍多添加各种注意力机制或者一些模块改进,当然了也有一些人评判添加注意力机制的,认为它作用甚小,甚至有人认为他只是水水论文作用,对此我只是呵呵一笑哦,实践才是检测真理的唯一标准,不能因为一个注意力在你得数据集上不行就否定了整个注意力,ppyolo系列中还明确的表示了添加了注意力机制了。
还有一些博客认为添加无脑的添加数据集,扩大训练尺寸就很不错,确实这样带来的效果也是有着明显的提升,但是这不是学术也不是demo,在实际的工程中部署会涉及到很多,模型的推理速度,以及你训练时候的显存。。。。。。
下面介绍一种大家其实都知道的一种方法,切图(1、滑动切图;2、中心切图)切图里面的细节有很多,这里采用的是滑动切图,想要了解其他的可以参考:这里有江大白老师介绍的很多trick去使用。
1、滑动切图
下面这张图可以很好的解释。
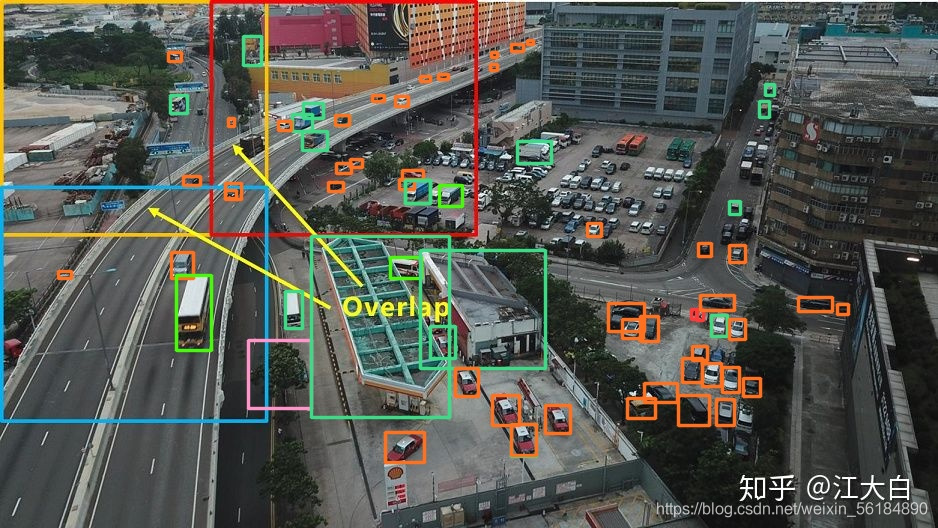
大家切割的时候可以参考下面的博客:
(1条消息) 滑动窗口切割图片并重定位标注框_Lavi_qq_2910138025的博客-CSDN博客
(1条消息) YOLOV5 模型和代码修改——针对小目标识别_xiaoY322的博客-CSDN博客
下面我将使用DOTA进行切割:
原图:

切割之后的图:






下面就是正常的训练。。。。。。。。。。。。。。。。。。。。