目标检测是计算机视觉中一项艰巨的下游任务。对于车载边缘计算平台,大模型很难达到实时检测的要求。而且,由大量深度可分离卷积层构建的轻量级模型无法达到足够的准确性。因此本文引入了一种新方法 GSConv 来减轻模型的复杂度并保持准确性。 GSConv 可以更好地平衡模型的准确性和速度。并且,提供了一种设计范式, Slim-Neck ,以实现检测器更高的计算成本效益。在实验中,与原始网络相比,本文方法获得了最先进的结果(例如, SODA10M 在 Tesla T4 上以 ~100FPS 的速度获得了 70.9% mAP0.5)。
目标检测是无人驾驶汽车所需的基本感知能力。目前,基于深度学习的目标检测算法在该领域占据主导地位。这些算法在检测阶段有两种类型:单阶阶段和两阶段。两阶段检测器在检测小物体方面表现更好,通过稀疏检测的原理可以获得更高的平均精度(mAP),但这些检测器都是以速度为代价的。单阶段检测器在小物体的检测和定位方面不如两阶段检测器有效,但在工作上比后者更快,这对工业来说非常重要。
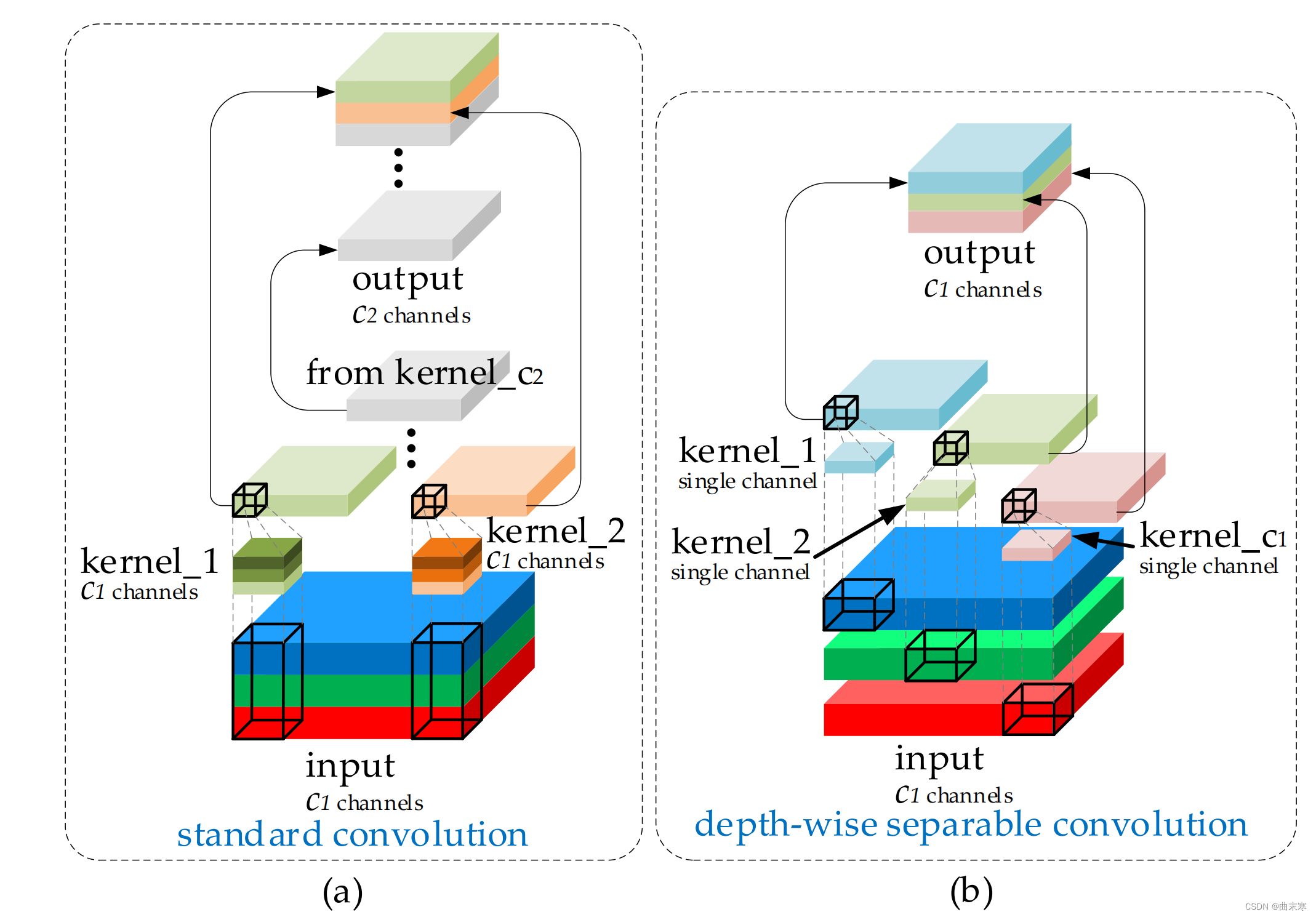
类脑研究的直观理解是,神经元越多的模型获得的非线性表达能力越强。但不可忽视的是,生物大脑处理信息的强大能力和低能耗远远超出了计算机。无法通过简单地无休止地增加模型参数的数量来构建强大的模型。轻量级设计可以有效缓解现阶段的高计算成本。这个目的主要是通过使用 Depth-wise Separable Convolution ( DSC )操作来减少参数和 FLOPs 的数量来实现的,效果很明显。