对YOLOV5进行轻量化:
一、backbone部分
yaml配置文件:
backbone:
# [from, number, module, args]
[[-1, 1, conv_bn_relu_maxpool, [32]], # 0-P2/4
[-1, 1, Shuffle_Block, [116, 2]], # 1-P3/8
[-1, 3, Shuffle_Block, [116, 1]], # 2
[-1, 1, Shuffle_Block, [232, 2]], # 3-P4/16
[-1, 7, Shuffle_Block, [232, 1]], # 4
[-1, 1, Shuffle_Block, [464, 2]], # 5-P5/32
[-1, 1, Shuffle_Block, [464, 1]], # 6
]
1.1、Focus替换
原始的YOLOv5s-5.0的stem是一个Focus切片操作,而v6是一个6x6Conv,这里是仿照v6对Focus进行改进,改为1个3x3卷积(因为我的任务本身不复杂,改为3x3后可以降低参数)
class conv_bn_relu_maxpool(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super(conv_bn_relu_maxpool, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
1.2、所有Conv+C3替换为Shuffle_Block
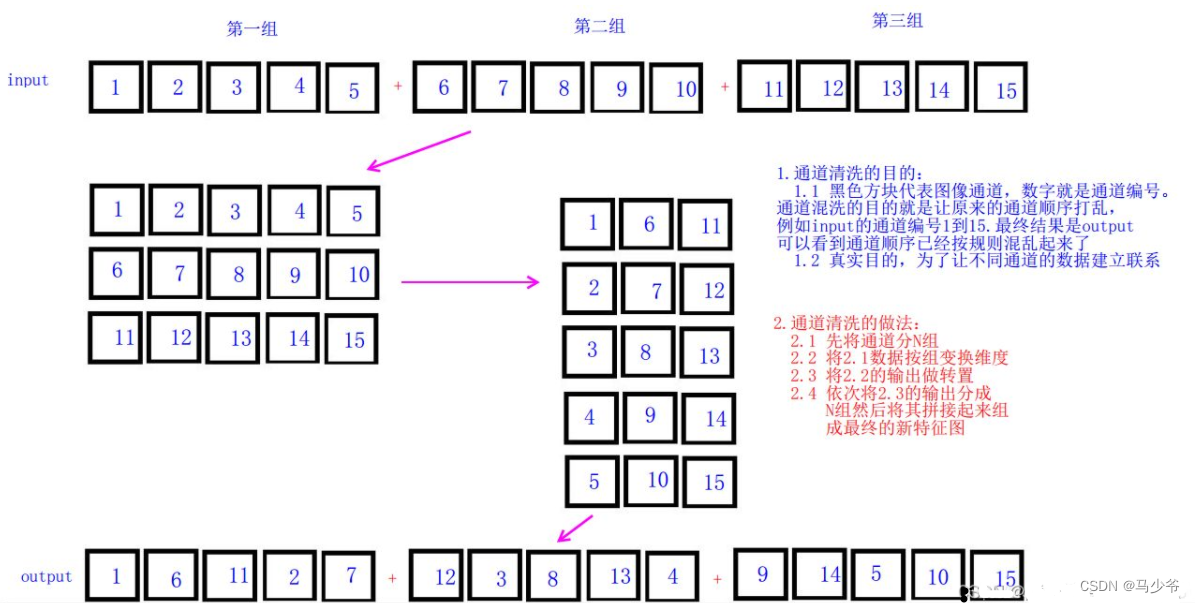
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size() # bs c h w
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups, channels_per_group, height, width) # [bs,c,h,w] to [bs,group,channels_per_group,h,w]
x = torch.transpose(x, 1, 2).contiguous() # channel shuffle [bs,channels_per_group,group,h,w]
# flatten
x = x.view(batchsize, -1, height, width) # [bs,c,h,w]
return x
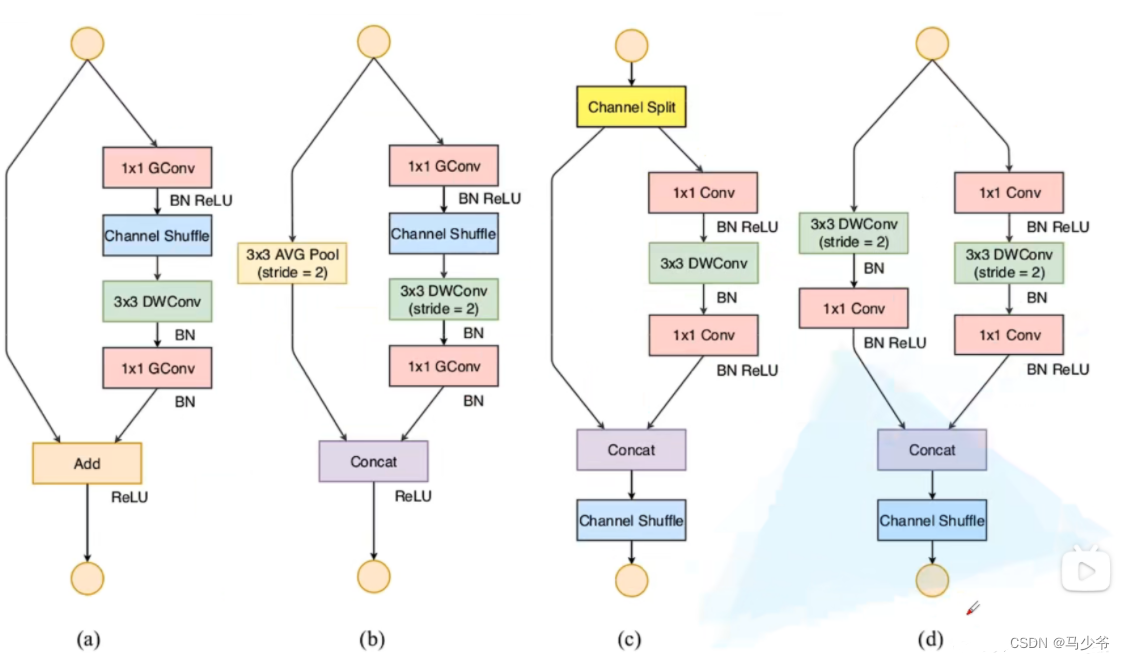
class Shuffle_Block(nn.Module):
def __init__(self, inp, oup, stride):
super(Shuffle_Block, self).__init__()
if not (1 <= stride <= 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2 # channel split to 2 feature map
assert (self.stride != 1) or (inp == branch_features << 1)
# stride=2 图d 左侧分支=3x3DW Conv + 1x1Conv
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
# 右侧分支=1x1Conv + 3x3DW Conv + 1x1Conv
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
# x/out: [bs, c, h, w]
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # channel split to 2 feature map
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
1.3、砍掉SPP
砍掉了SPP结构和后面的一个C3结构,因为SPP的并行操作会影响速度。
二、head部分
head:
[[-1, 1, Conv, [96, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[ -1, 4 ], 1, Concat, [1]], # cat backbone P4
[-1, 1, DWConvblock, [96, 3, 1]], # 10
[-1, 1, Conv, [96, 1, 1 ]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P3
[-1, 1, DWConvblock, [96, 3, 1]], # 14 (P3/8-small)
[-1, 1, DWConvblock, [96, 3, 2]],
[[-1, 11], 1, ADD, [1]], # cat head P4
[-1, 1, DWConvblock, [96, 3, 1]], # 17 (P4/16-medium)
[-1, 1, DWConvblock, [ 96, 3, 2]],
[[-1, 7], 1, ADD, [1]], # cat head P5
[-1, 1, DWConvblock, [96, 3, 1]], # 20 (P5/32-large)
[[14, 17, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.1、所有层结构输入输出channel相等
2.2、所有C3结构全部替换为DWConv
2.3、PAN的两个Concat改为ADD
三、、总结
ShuffleNeckV2提出的设计轻量化网络的四条准则:
G1、 卷积层的输入特征channel和输出特征channel要尽量相等;
G2、 尽量不要使用组卷积,或者组卷积g尽量小;
G3、 网络分支要尽量少,避免并行结构;
G4、 Element-Wise的操作要尽量少,如:ReLU、ADD、逐点卷积等;
YOLOv5s-ShuffleNetV2改进点总结:
backbone的Focus替换为一个3x3Conv(c=32),因为v5-6.0就替换为了一个6x6Conv,这里为了进一步降低参数量,替换为3x3Conv;
backbone所有Conv和C3替换为Shuffle Block;
砍掉SPP和后面的一个C3结构,SPP并行操作太多了(G3)
head所有层输入输出channel=96(G1)
head所有C3改为DWConv
PAN的两个Concat改为ADD(channel太大,计算量太大,虽然违反了G4,但是计算量更小)
四、实验结果
GFLOPs=值/10^9
参数量(M)=值*4/1024/1024
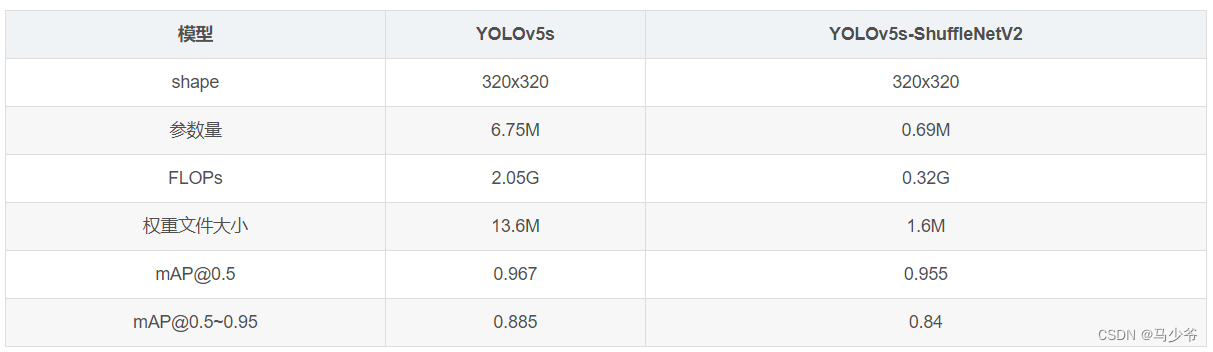
参数量、计算量、权重文件大小都压缩到YOLOv5s的1/10,精度[email protected]掉了1%左右(96.7%->95.5%),[email protected]~0.95掉了5个点左右(88.5%->84%)。
参考文献:https://blog.csdn.net/qq_38253797/article/details/124803531