模式识别介绍
模式:指需要识别且可测量的对象的描述。
这些对象与实际的应用有关,如:字符识别的模式——每个字符图像;人脸识别的模式——每幅人脸图像。
模式识别:利用机器(计算机)模仿人脑对现实世界各种事物进行描述、分类、判断和识别的过程。
- 样本(sample):所研究对象的一个个体。
- 样本集(sample set):若干样本的集合。
- 类和类别(class):在所有样本上定义的一个子集,处于同一类的样本在我们所关心的某种性质上是不可区分的。
- 特征(feature):指用于表征样本的观测。
- 已知样本(know samples):指事先知道类别标号的样本。
- 未知样本(unknow samples):指类别标号未知但特征已知的样本。
所谓模式识别的问题,就是用计算的方法根据样本的特征将样本划分到一定的类别中去。
模式识别的目的是为了通过机器完成对事物的分类,可以归纳为基于知识的方法和基于数据的方法两大类。基于知识的方法一般是通过人的经验来进行判定,如吃肉的归为肉食动物,吃草归为草食动物,有羽毛归为鸟类等,其中吃肉、吃草、有羽毛是特征,肉食动物、草食动物、鸟类是分类。基于知识的方法的基本思想是根据人们已知的关于研究对象的知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,对未知样本通过这些知识推理来决策它的类别。
基于数据的模式识别方法不是依靠人们对所研究对象的认识来建立分类系统,通过收集一定数量的已知样本,用这些样本作为训练集来训练一定的模式识别机器,使它在训练以后能够对未知样本进行分类。它学习的目标是离散的对象类别。基于数据的模式的基础是统计模式识别,依据统计原理来建立分类器。除了统计模式识别之外还有人工神经网络和支撑向量机。
统计模式识别方法流程
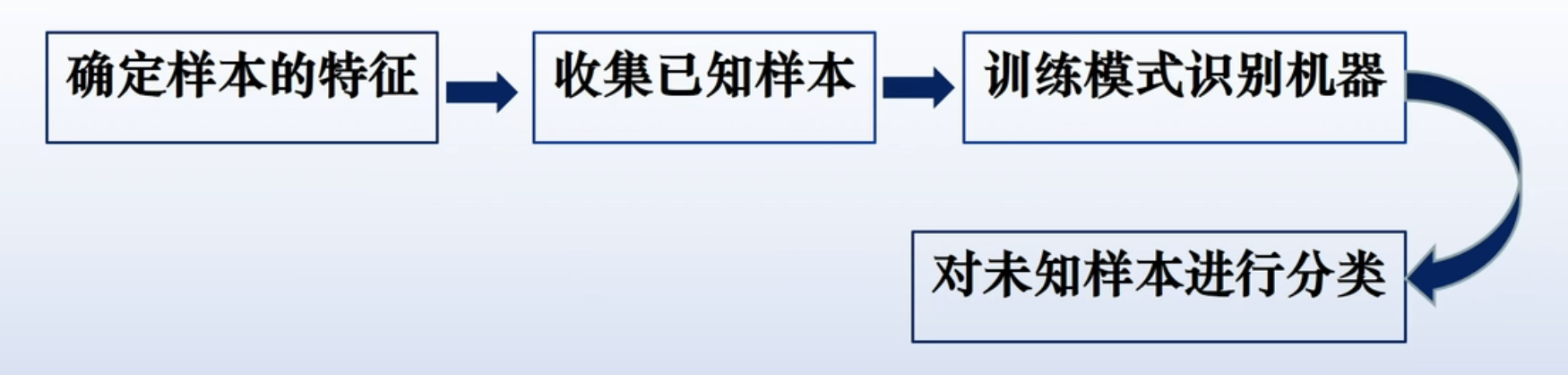
统计模式识别的基本思想
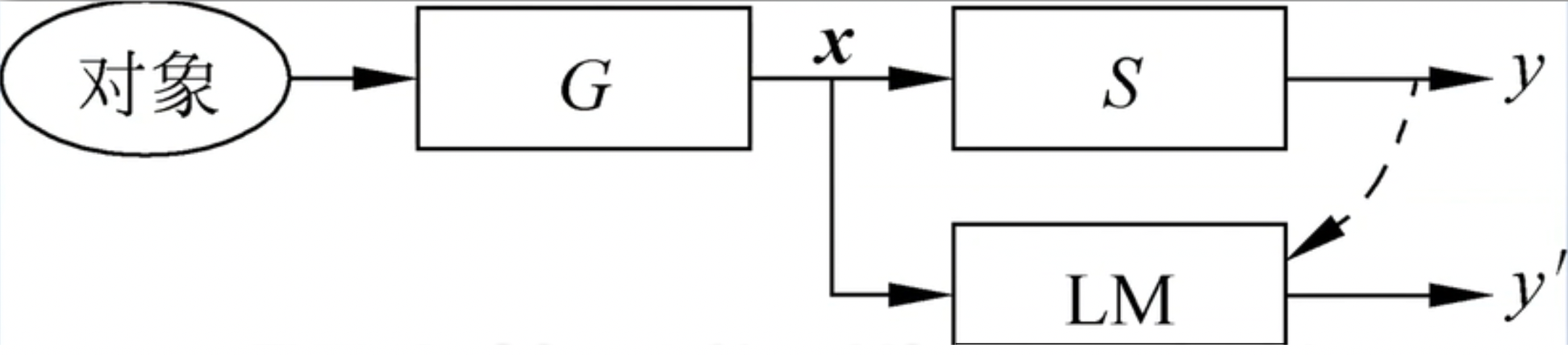
上图中,G表示的是需要从对象观测得到的特征的一个过程,通过观测以后构成了一个特征向量x,y表示我们所关心的对象的类别。S表示x和y之间关系的系统,实际情况当中,我们可能并不知道S的内部机理。我们只能通过一定数量的已知样本,是已知的x和y之间的数据对,用来训练一个学习机器LM,建立一个从特征x到类别y'的数学模型,通过这个数学模型,我们就可以对未知的样本进行预测它的类别。y'是特征向量x的函数,它的函数值代表了对未知样本的类别预测。这个函数称为分类器。
模式识别的适用范畴

- 基于数据的模式识别方法适用于已知对象的某些特征与我们所感兴趣的类别性质有关,但无法确切描述这种关系的情况。
- 分类和特征之间的关系可以完全确切的描述出来,采用基于知识的方法可能更有效。
- 若二者的关系完全随机,在分类和特征之间不存在规律性的关系,即不存在规律性的练习,应用模式识别也无法得到有意义的结果。模式识别不是万能的,是有局限性的,不能解决所有情况下的识别问题。
监督模式识别与非监督模式识别
- 监督模式识别:已知类别,并且能够获得类别已知的训练样本,这种情况下建立的问题属于监督学习问题,称为监督模式识别。
- 非监督模式识别:事先并不知道类别,更没有类别已知的样本,根据样本特征降样本聚成几个类,使属于同一类的样本在一定意义上是相似的,而不同类别之间的样本有较大差异。这种学习过程称为非监督模式识别。

如这张图中,这些人应该分成几类?根据什么分类?如果要求把这些人分成两类,如何分?根据性别,是否戴眼镜?头发颜色?长相?在没有给出具体的分类要求的时候,我们给出的分类结果是不唯一的。很难判断哪种分类方案更合理。这也是非监督模式识别的特点。
模式识别应用举例
- 鱼的分类

我们假设有鲈鱼(salmon)和鲑鱼(sea bass)两种鱼,首先需要通过光学感知手段来拍摄若干样品的图像来区分鲈鱼和鲑鱼。这两种鱼存在一些物理特性上的差异,比如长度、光泽、宽度、鳍的数量和形状以及嘴的位置等等,我们可以利用这些要素来作为模式识别的特征。图像会存在一些干扰和噪声,在提取特征之前需要先将图像进行一些预处理去除噪声,同时采用分割技术将图像中的鱼和背景分割开。
- 特征提取
就是上面说的长度、光泽、宽度、鳍的数量和形状以及嘴的位置等。
- 分类判别——单一特征
先研知识:鲈鱼一般比鲑鱼长,因此可以选择长度为分类特征;长度超过阈值时判定为鲈鱼,否则判定为鲑鱼。如何确定合适的长度阈值?
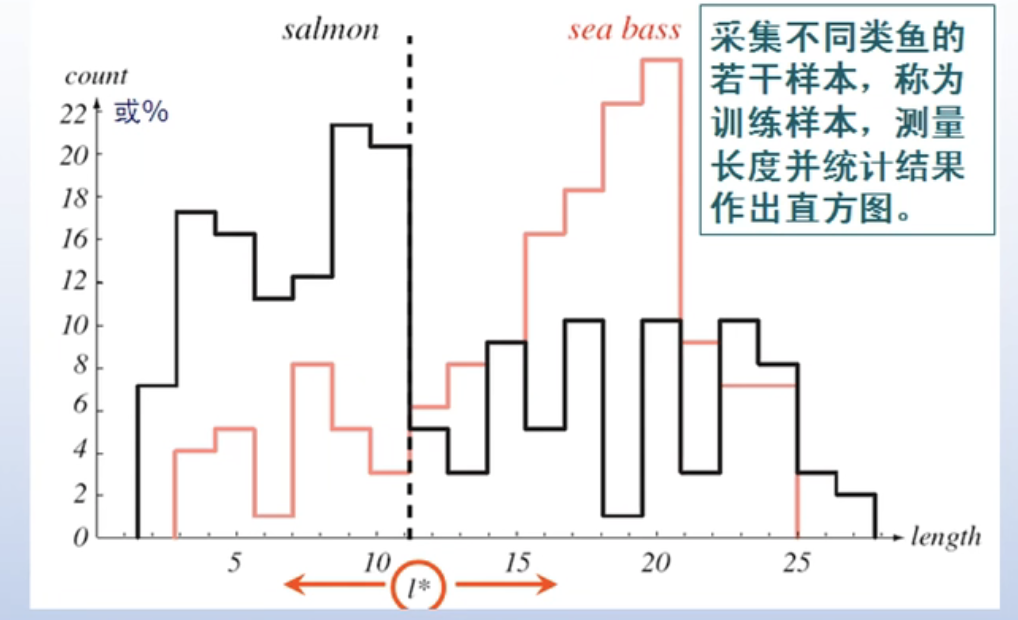
上图中横坐标表示长度,纵坐标表示数量。黑色的线表示鲈鱼的直方图数据,红色的线表示鲑鱼的直方图数据。虽然一般鲈鱼比鲑鱼要长,但是通过上述的直方图,我们会发现想通过长度来区分鲈鱼和鲑鱼是不太可能的,因为在相同的长度上即有鲈鱼也有鲑鱼。我们无法只凭长度阈值将两种鱼完全区分开。
既然单一的长度特征无法区分,那我们来看一下有没有其他的单一特征可以区分这两种鱼。
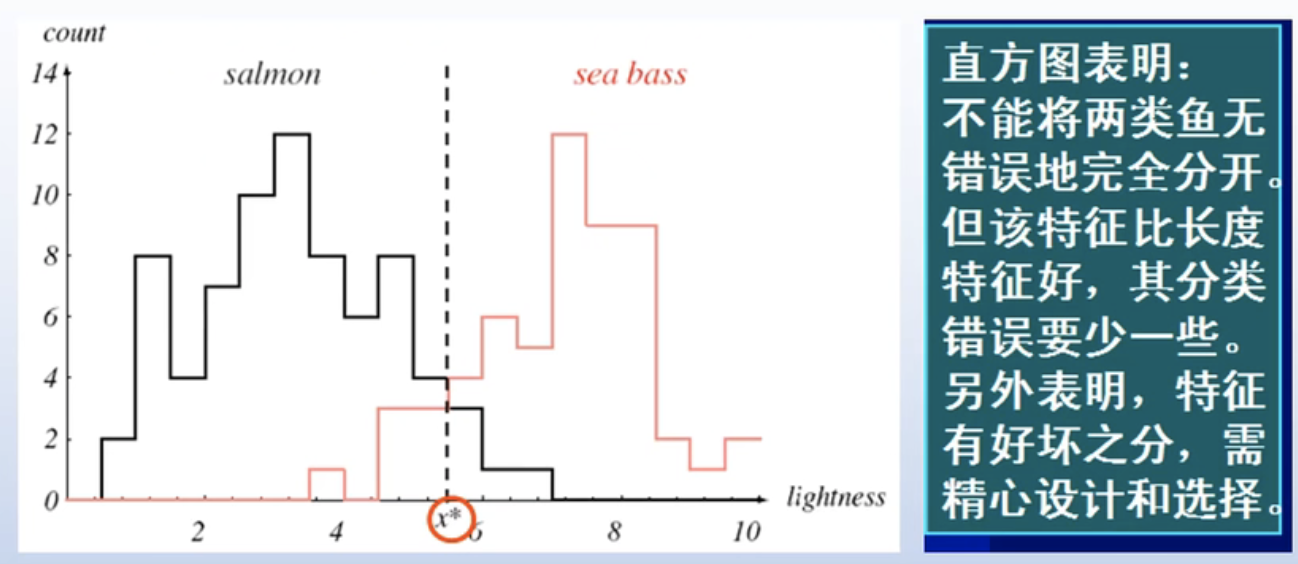
上图是光泽度的直方图,大部分的鲑鱼的光泽度比鲈鱼要高一些。但是要选择一个光泽度的理想阈值将两类完全区分开,还是不可能。但是选择了一个阈值后,分错的概率比长度要小的多。
- 利用多个特征进行分类
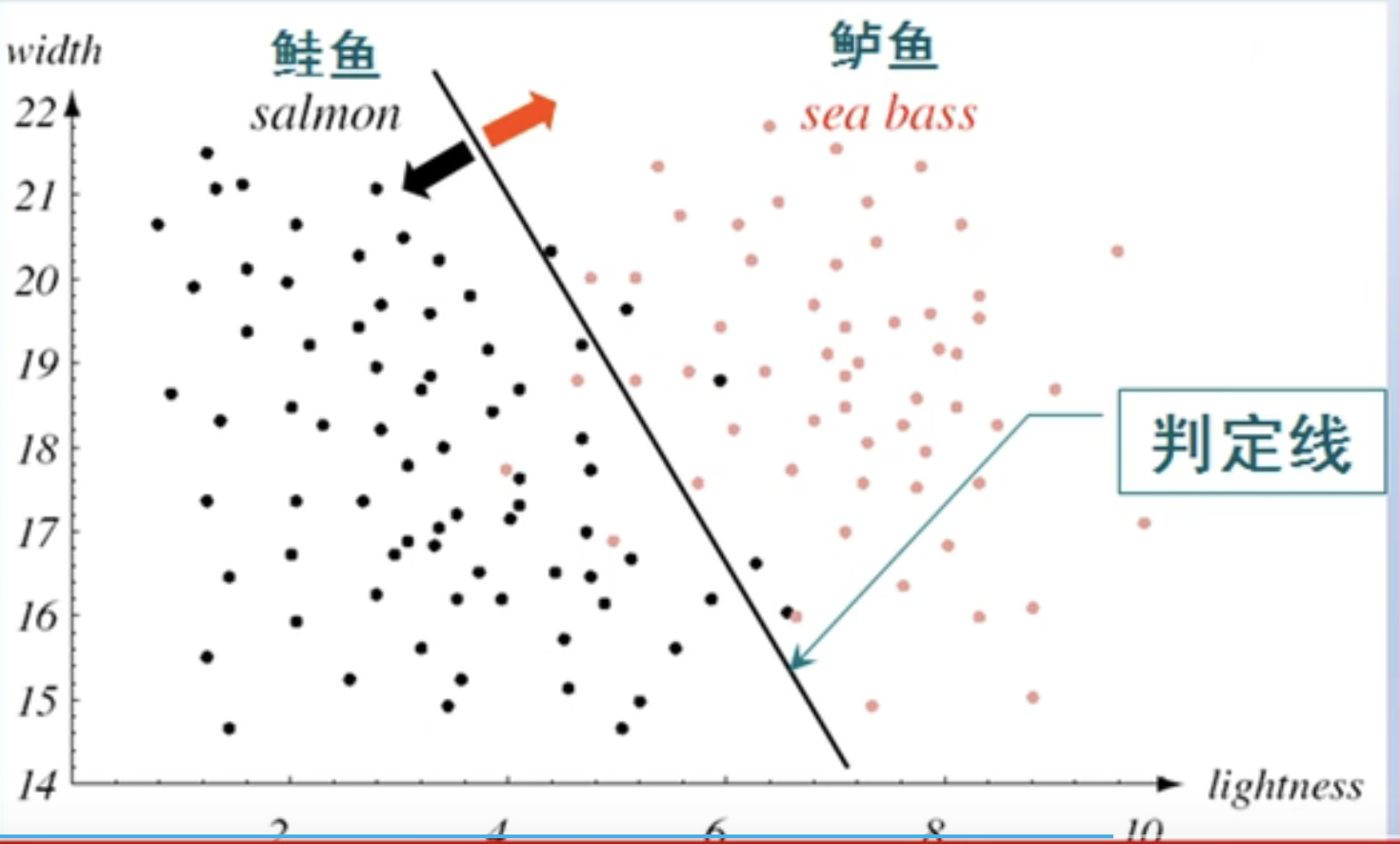
上图是在众多的特征中选择宽度和光泽度两个特征来组合成特征向量,再由宽度和光泽度构成的二维特征空间中,对所有样本进行分类。每个样本都对应空间中的一个点,中间有一个分类线将样本分成两部分。在分类线的一侧时鲑鱼,一侧时鲈鱼,我们会发现组合特征的分类效果要优于单一特征,但是仍然存在一些错误的分类。这个分类线即可以是直线也可以是曲线。
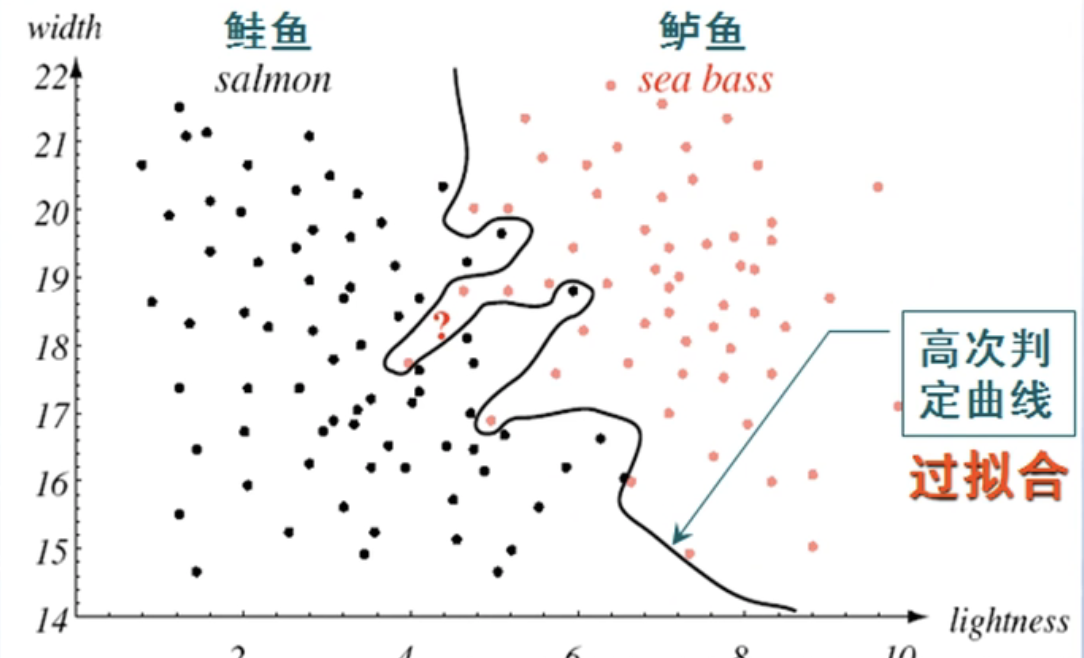
复杂的分类算法会产生复杂的分类界面,它对于训练样本的分类效果很好,几乎对所有的训练样本都进行正确分类,但是它的推广能力很差,如果对未知样本来进行分类的时候,错误率反而会高一些。判定界面不一定需要这么复杂,即使对一些训练样本不能完美识别,但是它只要对新模式有足够的推广能力就可以接受。分类器如何产生比较简单的判别界面,使得其比直线和复杂边界更优秀?如何预测分类器对新模式的推广能力,都是模式识别要研究的问题。
线性分类器
如果能够知道样本的概率密度模型,就可以使用贝叶斯决策的方法最优的实现分类决策。但是这里有一个前提,就是我们要假设事先知道样本的概率密度函数,这并不是容易的事情,尤其在特征空间的维度很高和样本比较少的情况下更是如此。我们需要绕过概率密度函数估计这个步骤,如果能够事先知道判别函数的形式,就可以设法从数据中直接估计这种判别函数中的参数。这就是基于样本直接进行分类器设计的思想。
基于样本进行分类器设计的三要素
- 确定分类器,也就是判别函数的类型。我们要确定是线性判别函数还是非线性判别函数。
- 确定分类器的目标或准则。我们需要按照什么样的原则来设计分类器,是按照最小错误率的原则还是按照风险最小的原则。
- 设计算法利用样本数据搜索到最优的函数参数。

线性分类器虽然是最简单的分类器,但是在样本为某些分布的时候,线性判别函数可以成为最小错误率或者是最小风险意义下的最优分类器。在一般情况下,线性分类器只是次优分类器,但是就因为简单,在很多情况下效果接近最优,所以应用也是比较广泛的。在样本有限的情况下,甚至能够取得比复杂的分类器更好的效果。
![]()
多类情况下

如果有c个类,我们需要设计c个判别函数。在确定了判别函数的类型以后,采用不同的准则及不同的巡游算法,就会得到不同的线性判别方法。
一个判别函数是指由样本X的各个分量的线性组合而成的函数。X--d维特征向量,表示为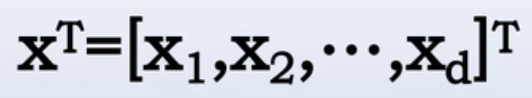 ;W--权向量,表示为
;W--权向量,表示为 ;
;![]() --常数,称为阈值权,一般也称偏置。分类时,c类一般会有c个这样的判别函数,每个判别函数会对应着c类中的一类。
--常数,称为阈值权,一般也称偏置。分类时,c类一般会有c个这样的判别函数,每个判别函数会对应着c类中的一类。
在最简单的两类情况下,判别函数可以写成
![]()
g1(x)是第一类的判别函数,g2(x)是第二类的判别函数。
- 决策规则:

如果g(x)>0,归为第一类,g(x)<0归为第二类,g(x)=0可以拒绝决策或者归为任何一类进行特殊处理。
线性判别函数g(x)=0定义了一个超平面H,称为决策面。
超平面表达式:
假设x1和x2都在决策面H上,则有
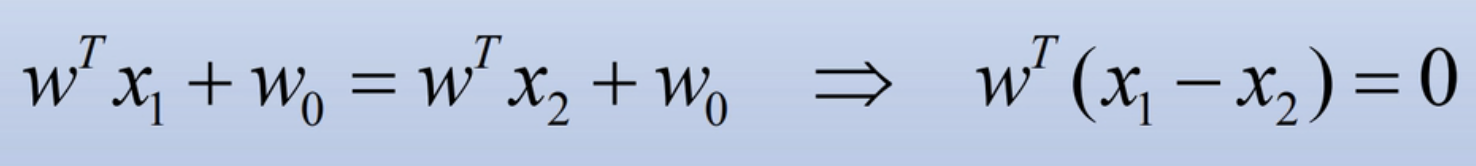
从右边的式子中可以看出,W实际上是和超平面上任意两点之间的连线是垂直的。因为两个向量的点乘为0,表示这两个向量是垂直的。
超平面的性质:
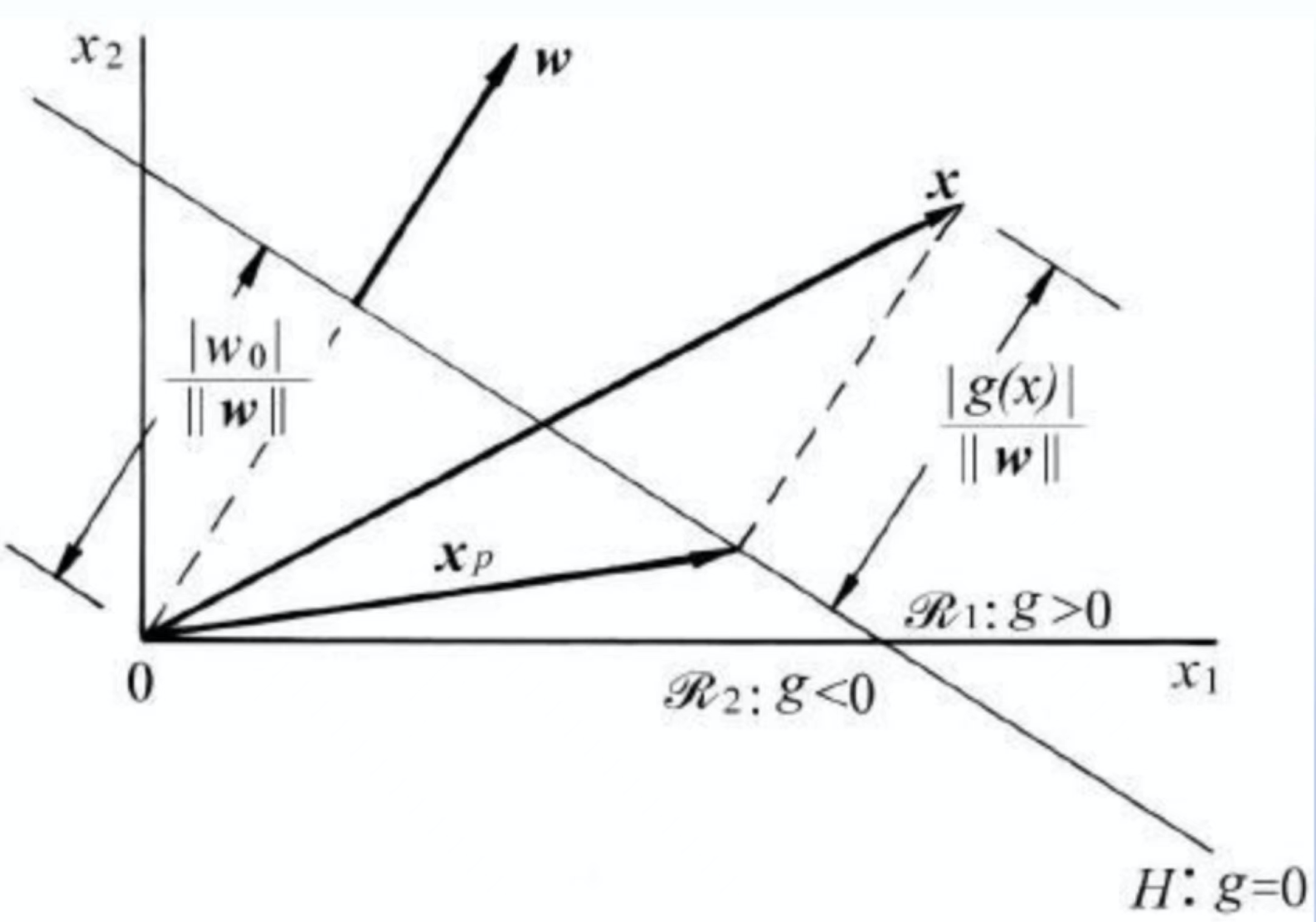
上图是由x1、x2构成的一个特征空间,直线H代表了超平面,在超平面上满足判别函数g(x)=0。超平面上任意的向量都和全向量W是垂直的,也就是说全向量W是超平面H的一个法向量。超平面将特征空间分成了两个空间R1和R2,在上面的空间R1中满足判别函数g(x)>0,在下面的空间R2中满足判别函数g(x)<0。样本x为特征空间中的一点,当x位于R1中的时候,g(x)是大于0的,所以超平面的法向量W是指向R1区域,因此把R1中的任意一个x称为它是位于超平面H的正侧;相应的称R2中的任意向量位于超平面H的负侧。
判别函数g(x)的含义,特征空间中的一点x到超平面有一个距离,它在超平面上的投影可以用一个向量xp来表示,此时我们可以把x用xp加上一个x到超平面的距离来表示。
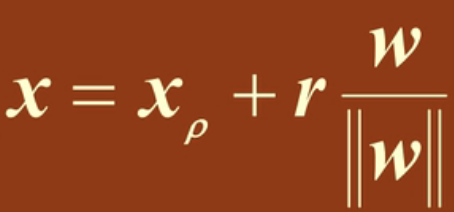
上式中,![]() 就是x在H上的投影,r是x到H的垂直距离,
就是x在H上的投影,r是x到H的垂直距离,![]() 为单位向量,只表示方向。
为单位向量,只表示方向。
我们将x的表达式代入g(x)的表达式
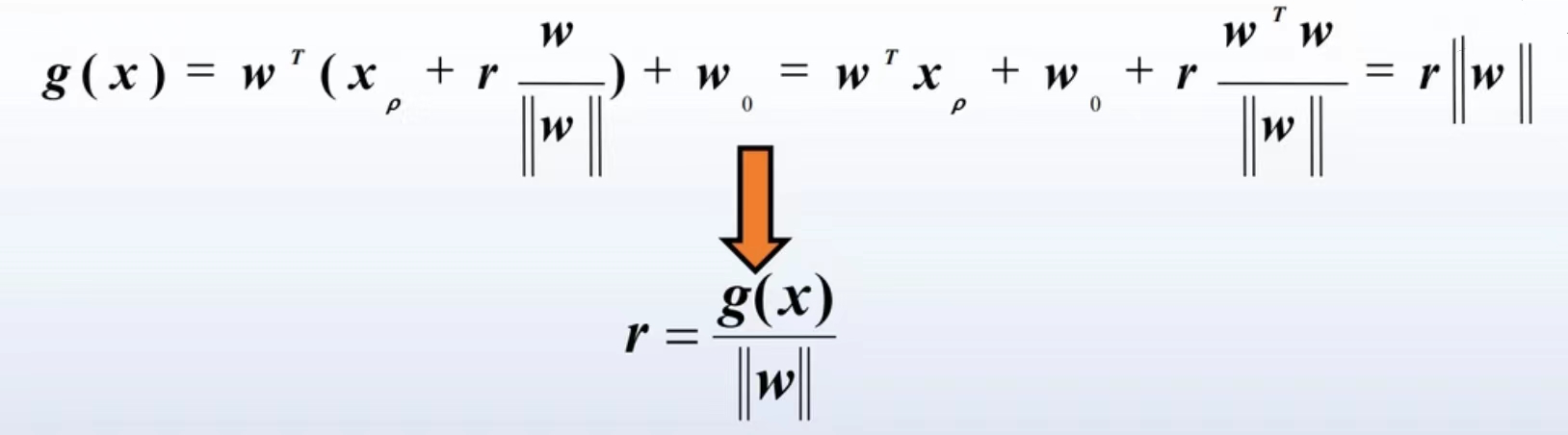
由于![]() 是超平面上的向量,所以
是超平面上的向量,所以![]() =0,
=0,![]() =||w||^2,故最终得r||w||,也就可以推得
=||w||^2,故最终得r||w||,也就可以推得![]() 。判别函数g(x)可以看作是样本x到超平面的距离的一种代数度量。若x为原点,则g(x)=
。判别函数g(x)可以看作是样本x到超平面的距离的一种代数度量。若x为原点,则g(x)=![]() ,就是原点到超平面的距离。
,就是原点到超平面的距离。
- 若
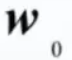 >0,则原点在H的正侧;
>0,则原点在H的正侧; - 若<0,则原点在H的负侧;
- 若=0,则H通过原点,具有齐次形式,超平面过原点。
Fisher线性判别
判别准则:确定投影方向

在上图中有两类样本,一种是点,一种是叉。我们要想将这两类样本区分开,一种直观的方法就是可以将样本往不同方向上投影,观察投影后是否更容易分类。
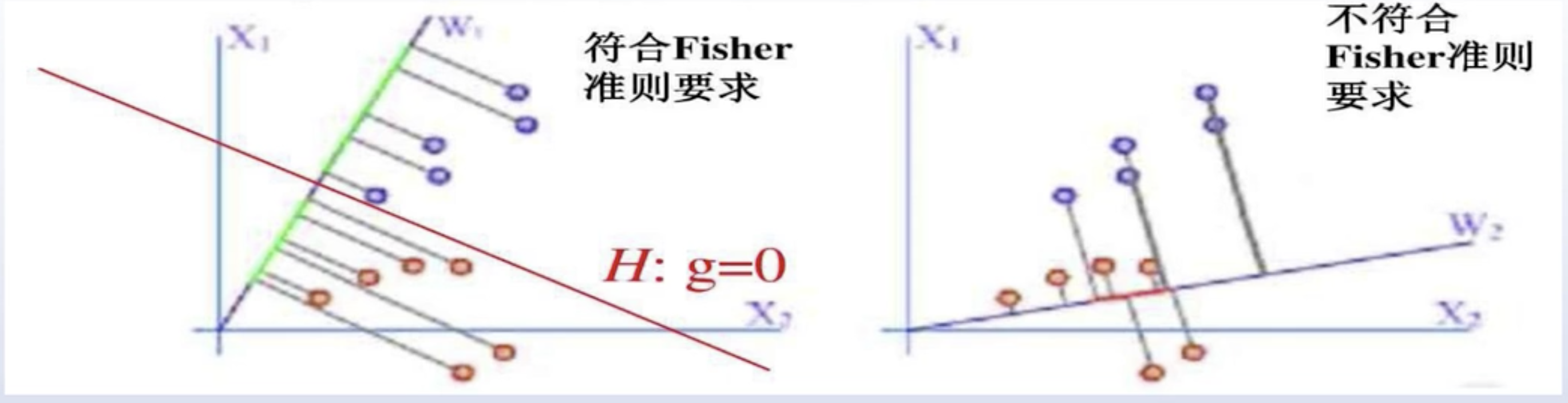
我们将这些样本分别向W1和W2两个方向上进行投影。在W1方向上投影以后,两类样本之间的距离会更大了,可以将两类样本比较好的分开。在W2方向上投影以后,这两类样本会混叠在一起,会为分类增加难度。
两类的线性判别问题可以看作是把所有的样本都投影到一个方向上,然后在一维空间中确定一个分类的阈值,过这个阈值点并且和投影方向垂直的超平面就是两类的分界面。Fisher线性判别的思想:选择投影方向,使得两类样本投影的均值之差尽量大,而使类内样本的离散程度尽可能小。即投影之后两类样本相隔要尽量的远,同时每一类内部的样本要尽可能地聚集。
- 最佳投影方向的确定
已知:n个d维的样本x1,x2,...Xn,其中:n1的样本子集X1属于类别w1,n2的样本子集X2属于类别w2,样本在w的方向上投影为:
![]()
这里w的维数和x的维数是相同的,投影以后的值y是一个标量。这里的问题就是如何确定投影方向w?
为了确定投影方向w,我们需要先确定一些基本参量
- d维原样本空间的参量。以下是以二分类为例来说明的,所以有i=1,2
 为样本均值向量(d维):
为样本均值向量(d维):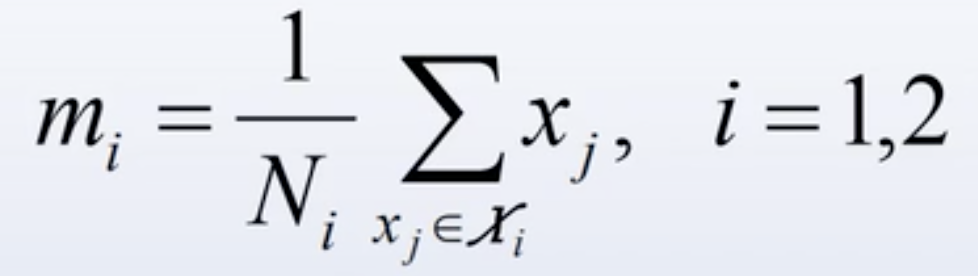
 为各类的类内离散度矩阵:
为各类的类内离散度矩阵: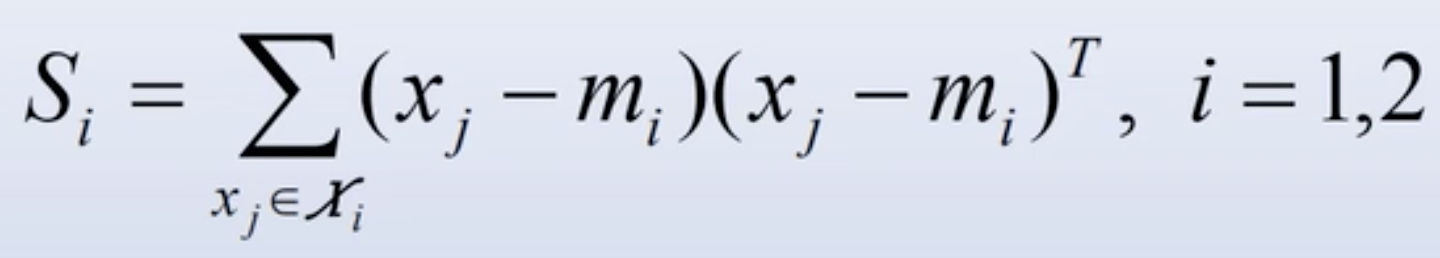
 为总类内离散度矩阵:
为总类内离散度矩阵: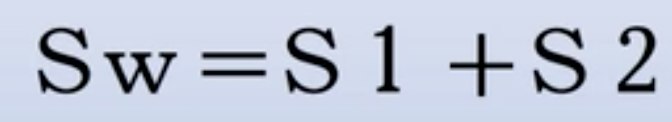
 为类间离散度矩阵:
为类间离散度矩阵: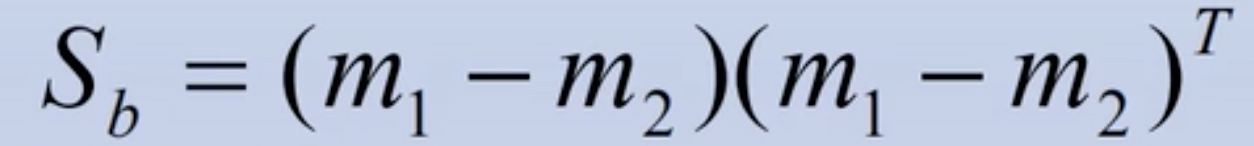
- 投影后一维样本空间的参量
- 样本在w方向上的投影:
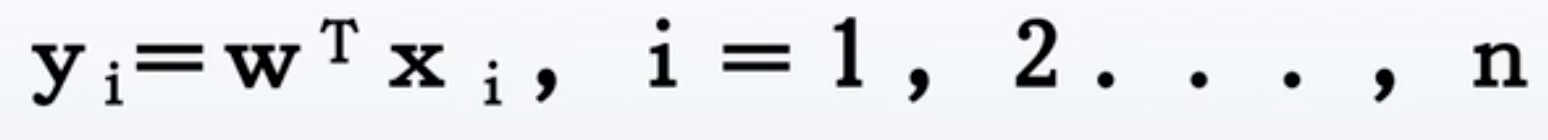
- 两类的均值:

- 类内离散度矩阵:
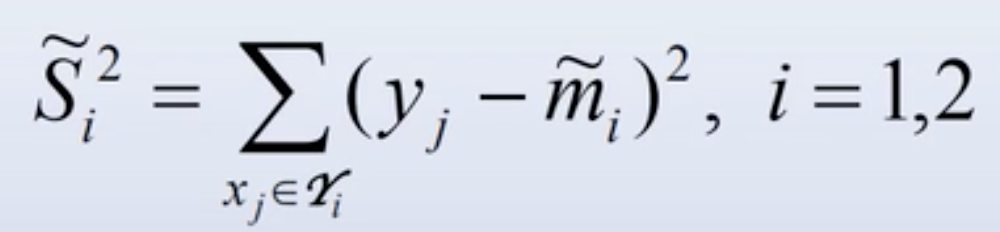
- 总类内离散度:
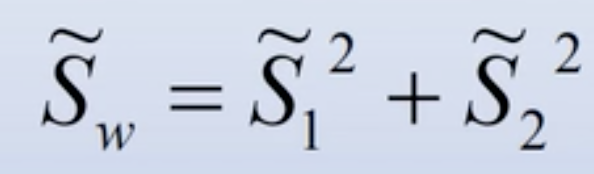
- 类间离散度:
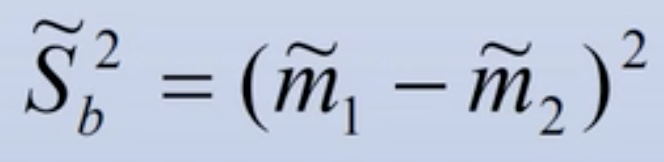
- Fisher准则函数
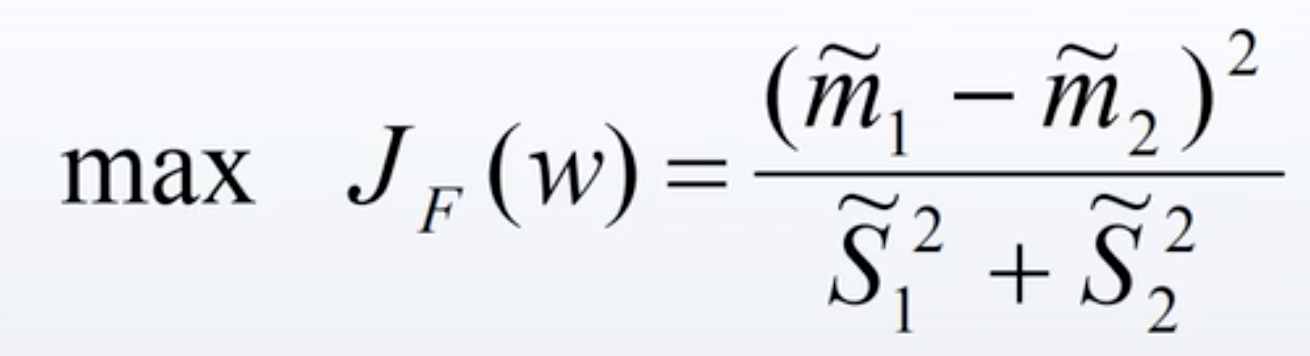
即:使两类尽可能的分开,各类内部尽可能聚集。它的分子是投影后两类样本均值之差的平方,反映了两类之间距离的大小;分母是投影后两类样本内类离散度矩阵之和,反映了每一类类内的样本的聚集程度。我们希望分子越大越好,分母越小越好。
代入![]() ,可得
,可得
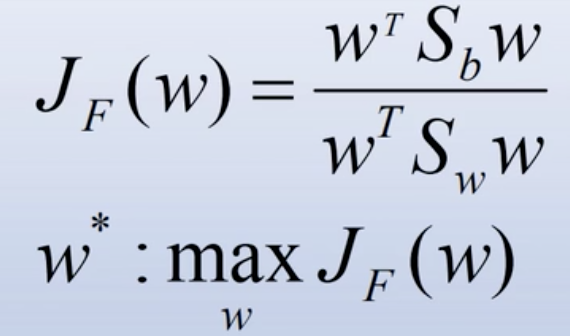
这个是准则函数的另外一种表达形式,分子是原样本空间中类间离散度矩阵的一个表达式,分母是原样本空间中类内离散度矩阵的一个表达式。此时我们说使准则函数J(w)取得最大值的w*就是我们求的最佳投影方向。
在上式中,分子分母都是关于w的二次项,因此准则函数中的解与w的长度无关,只和它的方向有关。假设准则函数表达式中的分母为常数,而最大化分子部分。这样上述的优化问题就转换成了令分母为常数c,即![]() ,使分子最大化。
,使分子最大化。
利用拉格朗日函数的方法对上述问题进行求解(有关拉格朗日函数的内容可以参考机器学习算法整理(三) SVM 背后的最优化问题),在只考虑w*的方向的情况下,得到
![]()
它等于原样本空间中总的类内离散度矩阵的逆乘以两类样本均值之差。这就是Fisher判别准则下的最佳投影方向,w*就是类间离散度和类内离散度比值达到最大的线性函数。
- 分类阈值w0的确定方法
我们只是确定了样本的投影方向w,但并没有确定分类面的具体位置。分类阈值w0的确定会有不同的方法。
- 当样本数量N和样本维数d很大的时候,y近似正态分布,可在空间内用贝叶斯分类器。在两类的协方差相同时,Fisher线性判别所得的方向实际就是最优贝叶斯决策方向,此时:
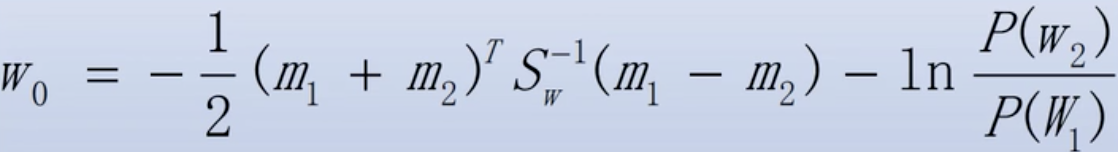
- 可以根据经验确定阈值
- 在不考虑先验概率的情况下,可以采用阈值
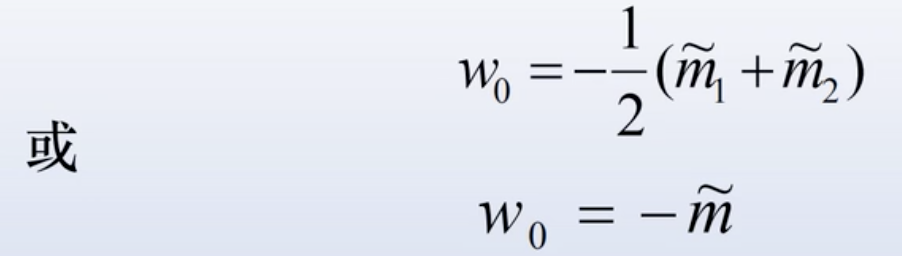
- 在考虑先验概率的情况下,也可以采用如下的阈值估计值
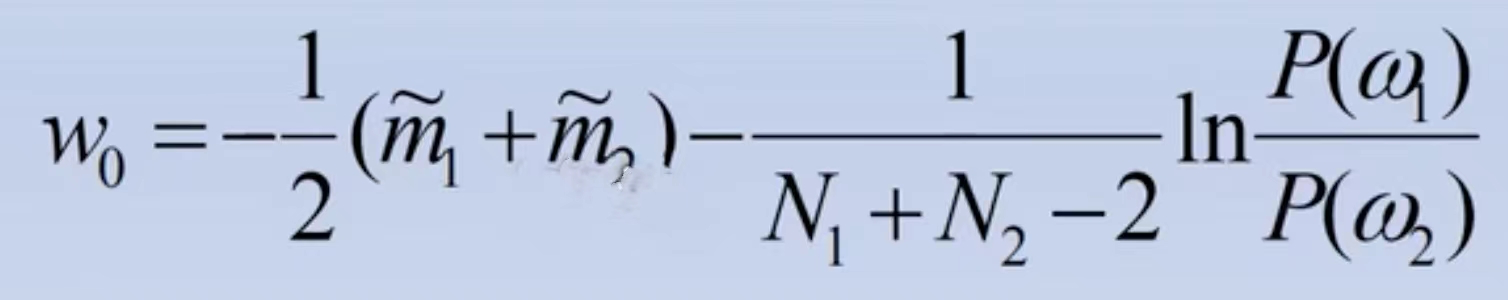
- 在不考虑先验概率的情况下,可以采用阈值
- 决策规则
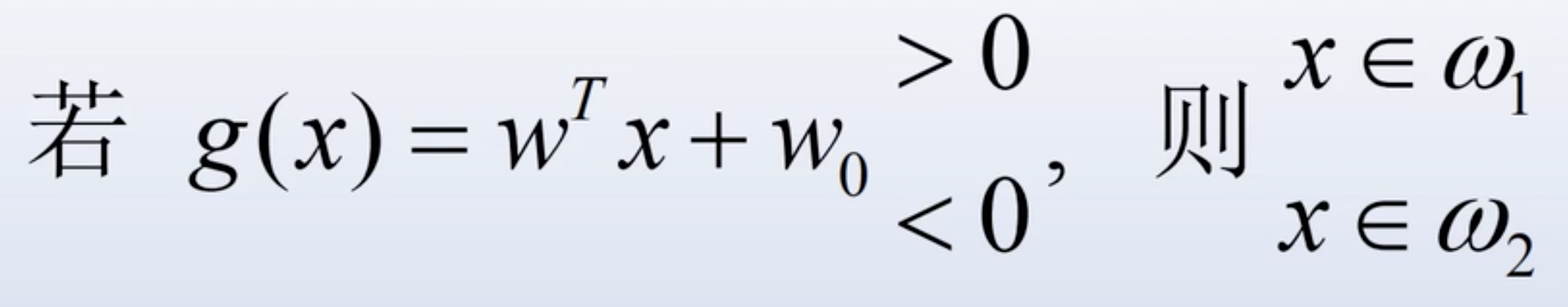
感知器算法
感知器算法有别于Fisher线性分类,Fisher线性分类器第一步需要确定投影方向,第二步是在这个方向上确定分类阈值,而感知器算法是一种直接得到线性判别函数的方法。
我们已经知道了线性分类判别函数![]() 。这其中有一个常数项ω0,为了方便,我们会把向量x增加一维,变为增广样本向量Y,这里
。这其中有一个常数项ω0,为了方便,我们会把向量x增加一维,变为增广样本向量Y,这里
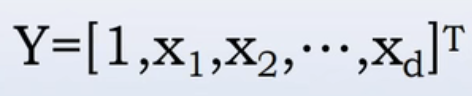 。
。
此时权向量也相应要增加一维,增广后的权向量为
![]() ,
,
线性判别函数变为
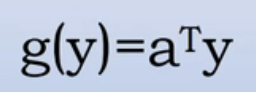 。
。
决策规则也就变为

- 线性可分性
假设有一个包含n个样本的集合,我们希望用这些样本来确定一个判别函数![]() 的权向量a,
的权向量a,
- 若
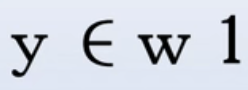 ,则
,则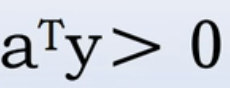 ,
, - 若
 ,则
,则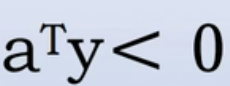 。
。
如果这个权向量a存在,这些样本就被称为"线性可分"的。
- 样本规范化
定义一个新的变量y',使得第一类样本y'=y,而对第二类样本则y'=-y,即
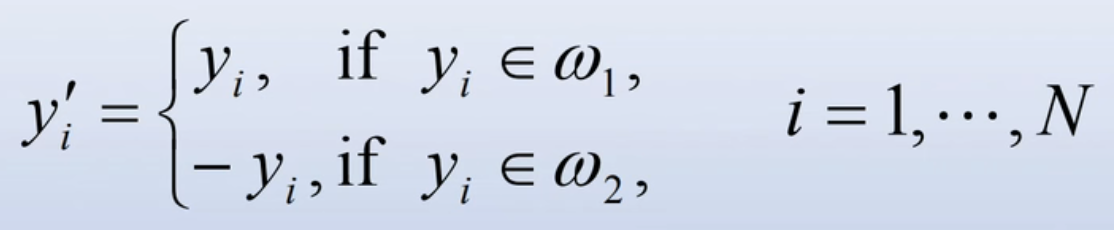
这样定义的y'称为规范化增广样本向量,仍记为![]() 。样本的可分性条件就变成了存在一个a,使得
。样本的可分性条件就变成了存在一个a,使得
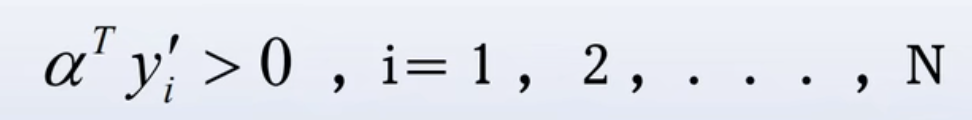
在感知器这部分里我们所说的样本![]() ,都是经过了规范化和增广的样本。
,都是经过了规范化和增广的样本。
- 解向量
在线性可分的情况下,寻找一个对所有的样本都满足![]() 的a称为权向量,记为a*,这个权向量又称为解向量。
的a称为权向量,记为a*,这个权向量又称为解向量。
一个权向量a是权空间中的一个点。每个样本![]() 对a的可能位置都起到限制作用。即要满足
对a的可能位置都起到限制作用。即要满足![]() 。对所有样本满足
。对所有样本满足![]() 的a即为一个解。
的a即为一个解。
- 解区
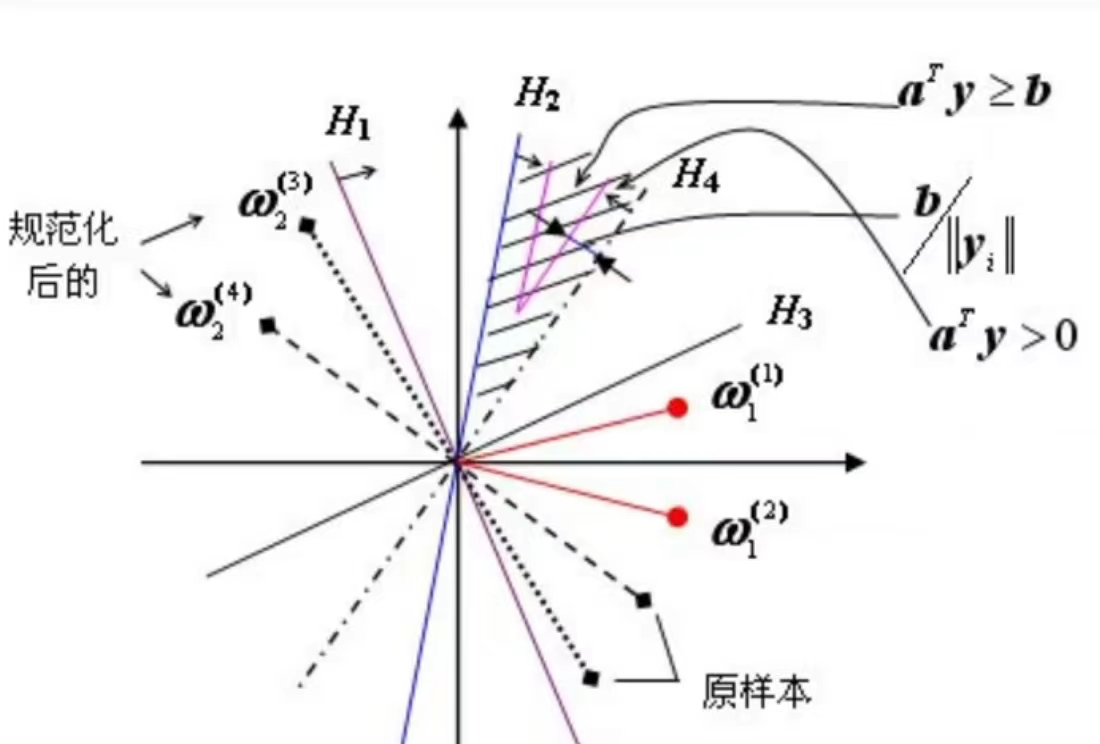
- 对于每个样本
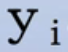 来说,等式
来说,等式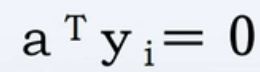 确定了一个穿过权空间原点的超平面,为其法向量。
确定了一个穿过权空间原点的超平面,为其法向量。 - 解向量如果存在的话,必须在超平面的正侧。
- 对于N个样本,解向量必定在N个正半平面的交叠区,而且该区中的任意向量都是解向量。
上图中有四个样本,对于第一类样本ω1来说,它保持不变;对于第二类样本ω2,需要将其规范化为负值。与这四个样本相垂直的是四个超平面H1、H2、H3、H4。这四个超平面正侧的交叠区,就是图上的阴影部分就构成了权向量a的解区间或者是解空间,解区间中的任意一个向量都是解向量。
- 余量
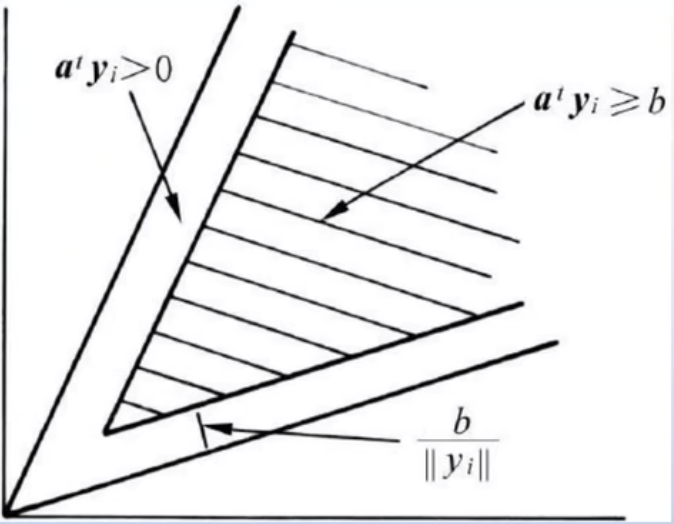
从直观角度来说,如果一个解区间的解向量太靠近边缘的话,虽然所有的样本都满足![]() ,但是某些样本的判别条件可能刚刚大于0。
,但是某些样本的判别条件可能刚刚大于0。
- 此时我们考虑到噪声、数值计算误差等因素的影响,把解区向中间缩小,不取靠近边缘的解。
- 用b表示余量,要求解向量满足:
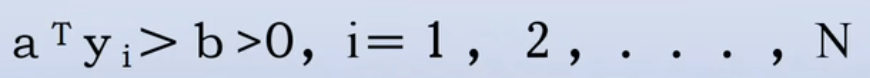
在解空间中,越靠近中间的解向量,对样本错分的可能性越小。
神经网络
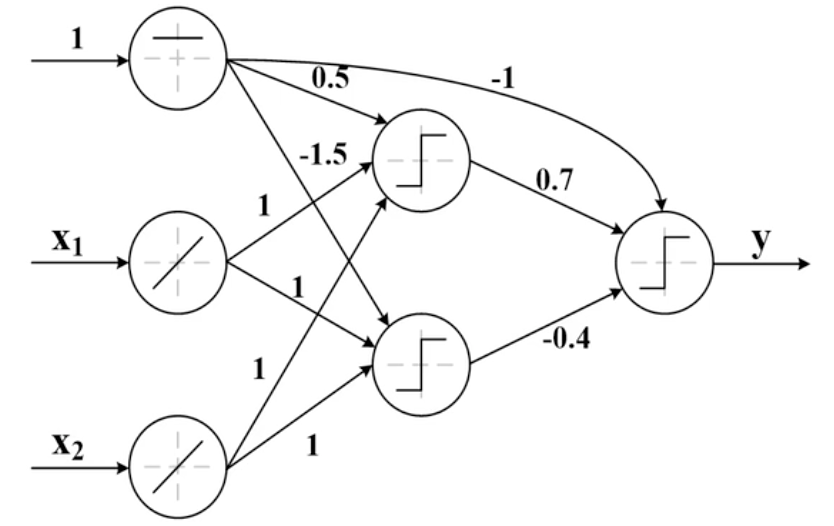
单个感知器能够完成线性可分数据的分类问题,感知器是一种最简单的可以学习的机器。但是感知器无法解决非线性问题。比如下面图中的异或问题。
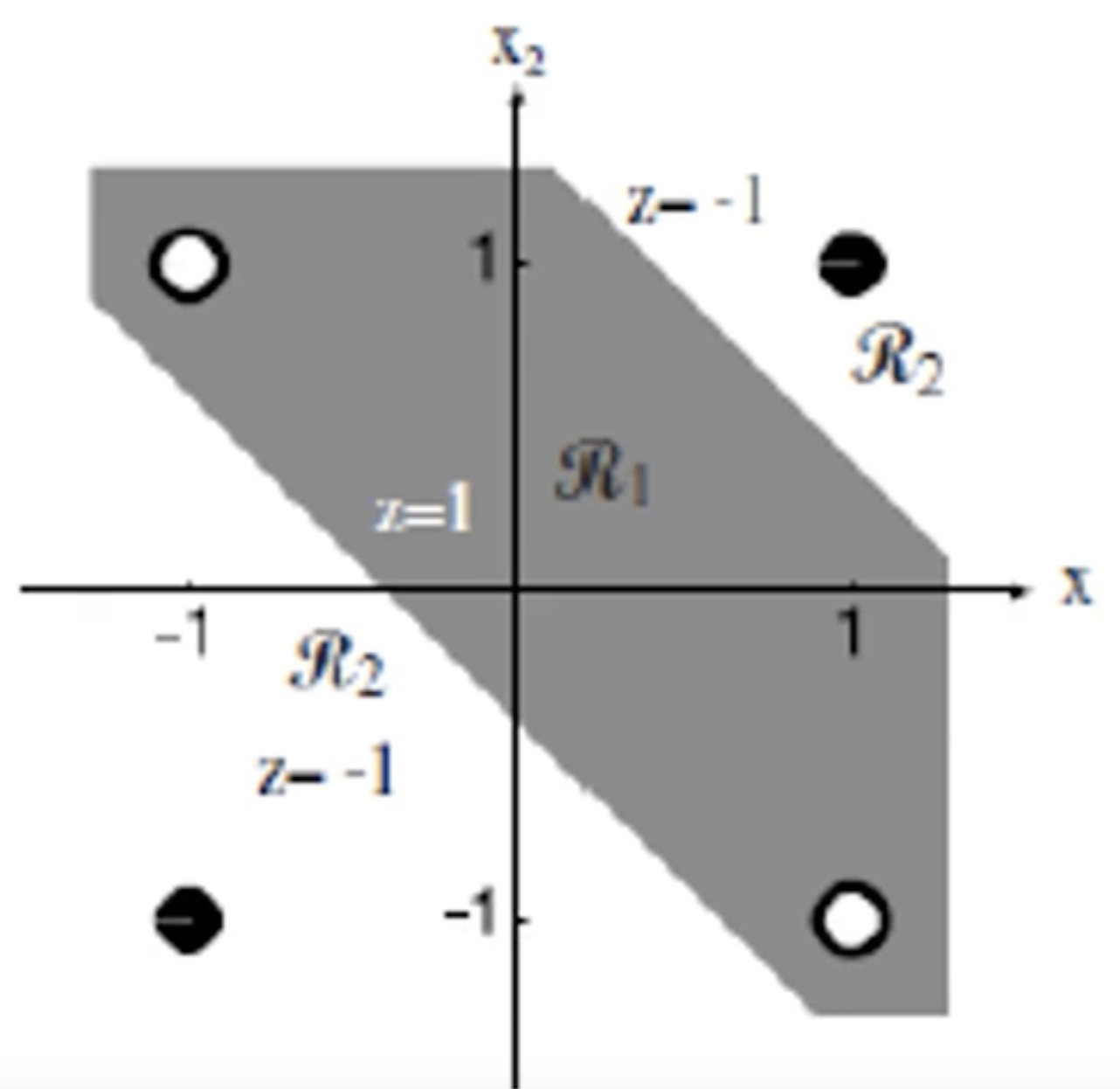
在上图中,点(1,1)和点(-1,-1)是属于第一类;点(1,-1)和点(-1,1)是属于第二类。我们无法使用单个感知器将这两类正确分类。但是我们将两层感知器按照一定的结构和系数进行组合。第一层感知器用来实现两个线性分类器,把特征空间分割,而在这两个感知器的输出之上再加一层感知器,就可以实现异或运算。
- 神经网络的基本概念和思想
- 上图是一个简单的三层神经网络,由一个输入层,一个隐含层和一个输出层组成。
- 各层之间由可修正的权值互联,这些权值由层间的连线表示,反映了各个输入信号的作用强度。
- 除了连接输入单元,每个单元还连接着一个偏置。这些单元有时也被称为"神经元".
神经元的作用是将这些输入信号加权求和,当求和超过一定的阈值后神经元即进入激活状态;否则神经元处于抑制状态。
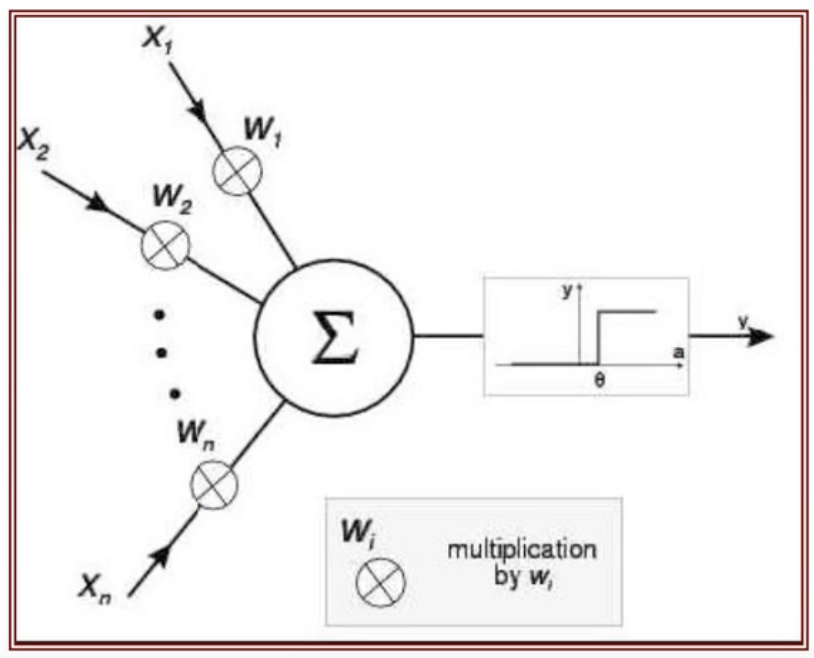
在模式识别里,输入单元提供特征量,而输出单元激发的信号则为用来分类的判别函数的值。
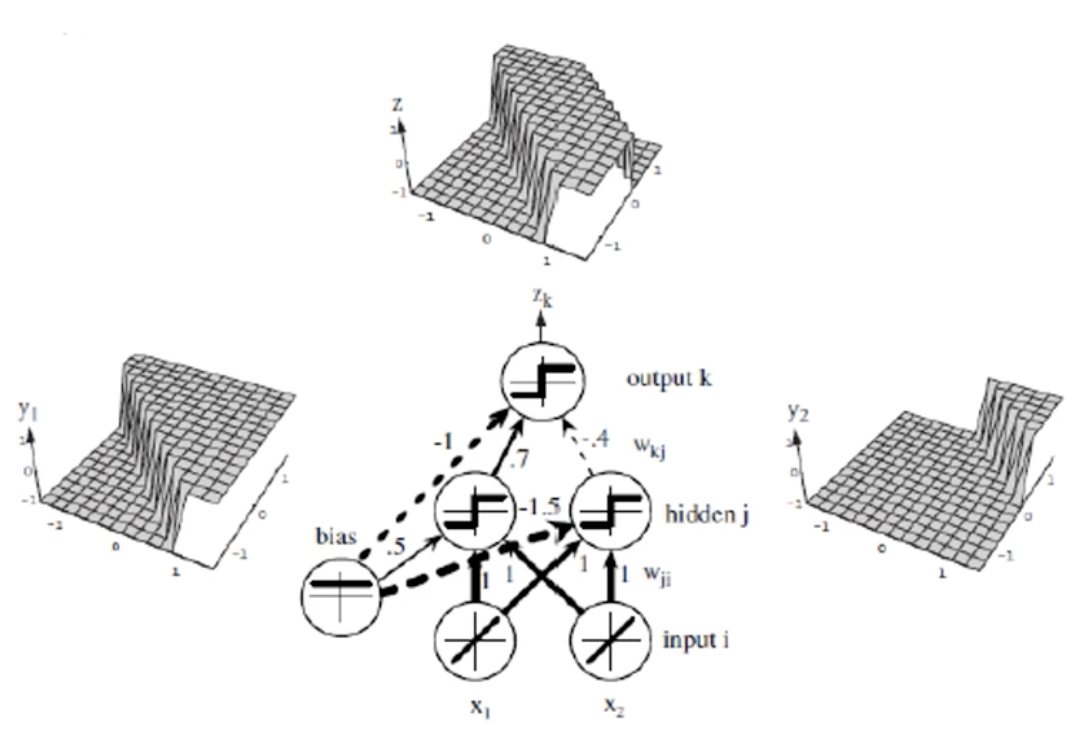
在这个异或问题里,有两个特征,每一个特征对应一个输入单元,所以有两个输入单元,输入单元的输出结果则等于相应的特征。上图中有x1、x2两个输入,隐藏层的各个单元会对于它的各个输入进行加权求和运算而形成标量的值,这个值是输入信号与隐藏层权值的内积,这个值也被称为"净激活"(简称net)。如果我们将输入向量增广化处理,即输入向量增加一个特征值![]() =1,权向量也增加一个值
=1,权向量也增加一个值![]() ,就可以把净激活写成:
,就可以把净激活写成:
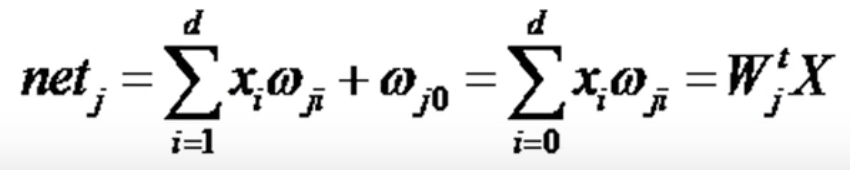
上式中i是输入层单元的索引,j是隐含层单元的索引。![]() 表示输入层单元i到隐含层单元j的权值。类比于神经元,这种权或连接也被称为突触,连接的值叫突触权。每一个隐含层单元激发出一个输出分量,这个分量是它激活的非线性函数,f(net),即
表示输入层单元i到隐含层单元j的权值。类比于神经元,这种权或连接也被称为突触,连接的值叫突触权。每一个隐含层单元激发出一个输出分量,这个分量是它激活的非线性函数,f(net),即
![]()
这个f()函数也被称为激活函数。激活函数可以是线性函数、阈值函数、sigmoid函数等多种形式。
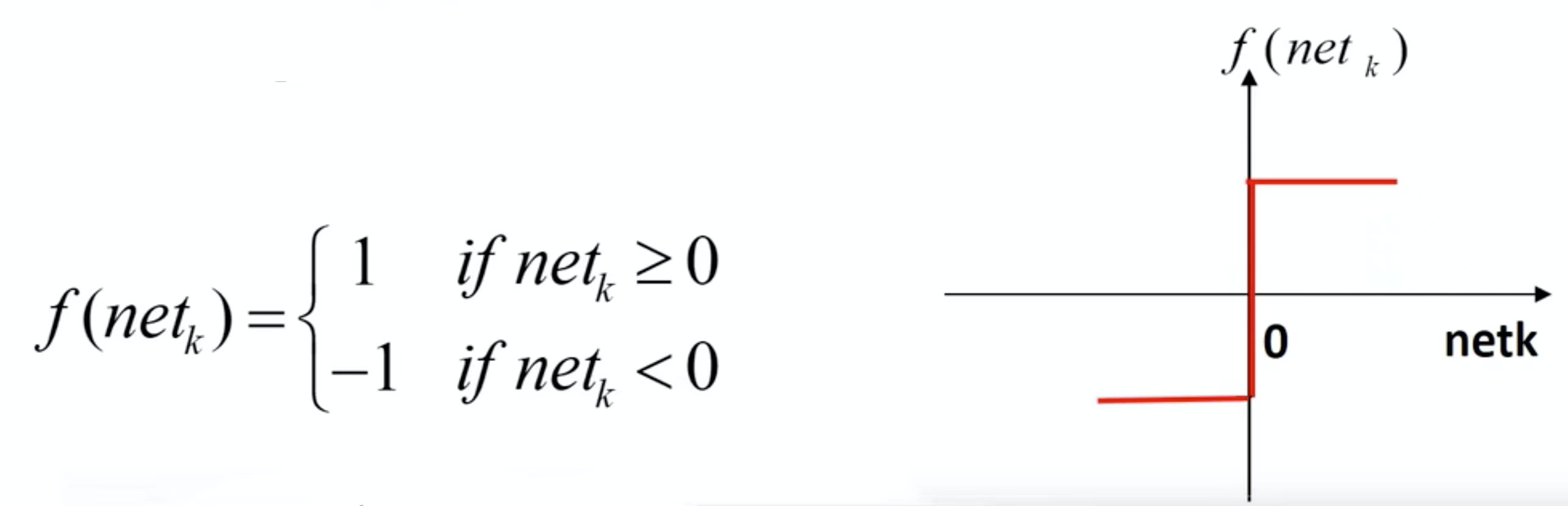
上图是一个分段线性激活函数,如果净激活值net≥1则直接输出1,反之则直接输出-1。
- 输出单元的输出可以看成是输入特征向量x的函数,当有c个输出单元时,计算c个判别函数,并通过使判别函数最大来将输入信号分类。
- 在只有两种类别的情况下,一般只采用单个输出单元,而用输出值的符号来对输入样本进行分类。
在异或问题中,采用了三层神经网络的结构,输入层包含两个输入单元,隐含层包含两个单元,输出层包含一个单元。这个三层神经网络的权值是给定的,隐含层的输出分别是y1和y2,y1的输出分别是1或-1。y1的输出是通过计算一个判别边界来实现的,这个判别边界是和该隐含层的偏置有关系的,左边的隐含层单元的偏置是0.5,所以它的计算判别边界是x1+x2+0.5=0。如果进入一个输入向量x能够使得该判别边界大于等于0的话,那么这个隐含单元的输出y1就是1,否则就是-1;对于隐含层的第二个单元的偏置是-1.5,它的判别边界为x1+x2-1.5=0。如果进入一个输入向量x能够使得该判别边界大于等于0的话,那么这个隐含单元的输出y2就是1,否则就是-1。只有y1和y2同时为1,输出单元的输出才是1,否则输出单元的输出就是-1,这也就得到了图中所示的适当的非线性判别区域,解决了异或问题。
import torch import torch.nn as nn class network(nn.Module): def __init__(self): super(network, self).__init__() self.hidden_layer = nn.Linear(2, 2) self.out_layer = nn.Linear(2, 1) nn.init.constant_(self.hidden_layer.weight, 1) nn.init.constant_(self.hidden_layer.bias[0], 0.5) nn.init.constant_(self.hidden_layer.bias[1], -1.5) self.out_layer.weight.data = nn.Parameter(torch.Tensor([[0.7, -0.4]])) nn.init.constant_(self.out_layer.bias, -1) def forward(self, x): out = self.hidden_layer(x) out = self.out_layer(self.hidden_act(out)) return self.out_act(out) def hidden_act(self, x): mid = torch.ge(x, torch.zeros(x.size()[0], 2)).to(torch.float32) rep = -torch.ones(x.size()[0], 2) mid = torch.where(mid == 0, rep, mid) return mid def out_act(self, x): mid = torch.ge(x, torch.zeros(x.size())).to(torch.float32) rep1 = -torch.ones(x.size()) rep2 = torch.ones(x.size()) mid = torch.where(mid == 1, rep1, mid) mid = torch.where(mid == 0, rep2, mid) return mid if __name__ == '__main__': x = torch.Tensor([[-1, -1], [-1, 1], [1, -1], [1, 1]]) model = network() out = model(x) print(out)
运行结果
tensor([[ 1.],
[-1.],
[-1.],
[ 1.]])
- 一般前馈网络
- 把之前的讨论推广为更多的输入单元、其他的非线性函数、任意多个输出单元。
- 在分类方面,我们有c个输出单元,每个类别一个,每个输出单元产生的信号就是判别式函数
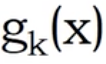 。
。 - 判别函数:
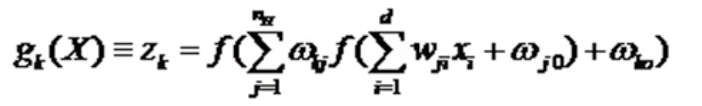
- 任何期望函数都可以通过一个三层网络来执行,条件是给定足够数量的隐单元,适当的非线性函数和权值。
BP神经网络
- BP(Back Propagation)网络是一种按照误差传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
- BP网络能学习和存储大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
- 它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
- BP神经网络模型拓扑结构
BP神经网络模型拓扑结构包括输入层(input)、隐层(hidelayer)和输出层(output layer)。每层都包含若干神经元。
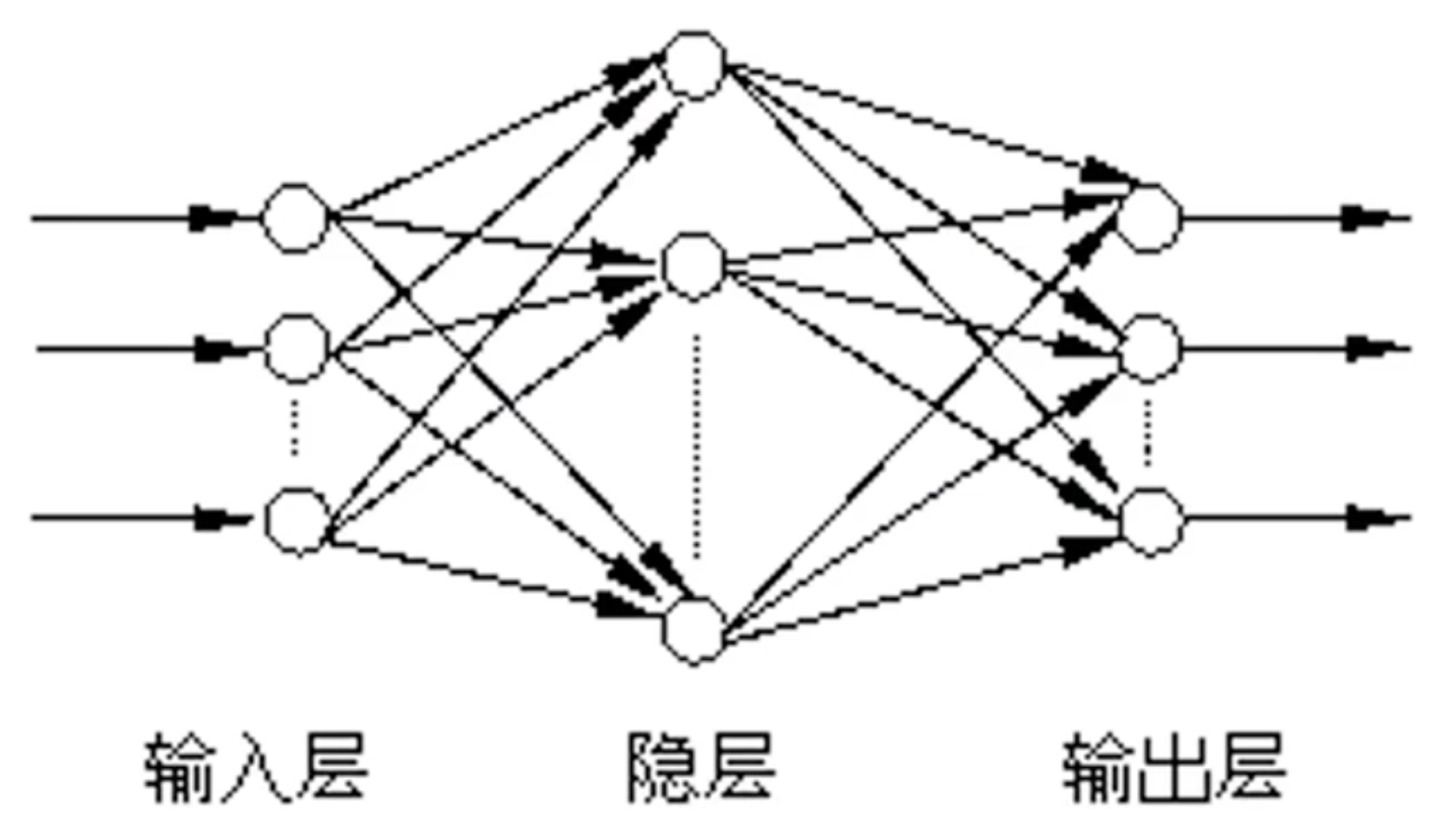
第j个基本BP神经元(节点)的模型,它只模仿了生物神经元所具有的三个最基本也是最重要的功能:加权、求和与转移。
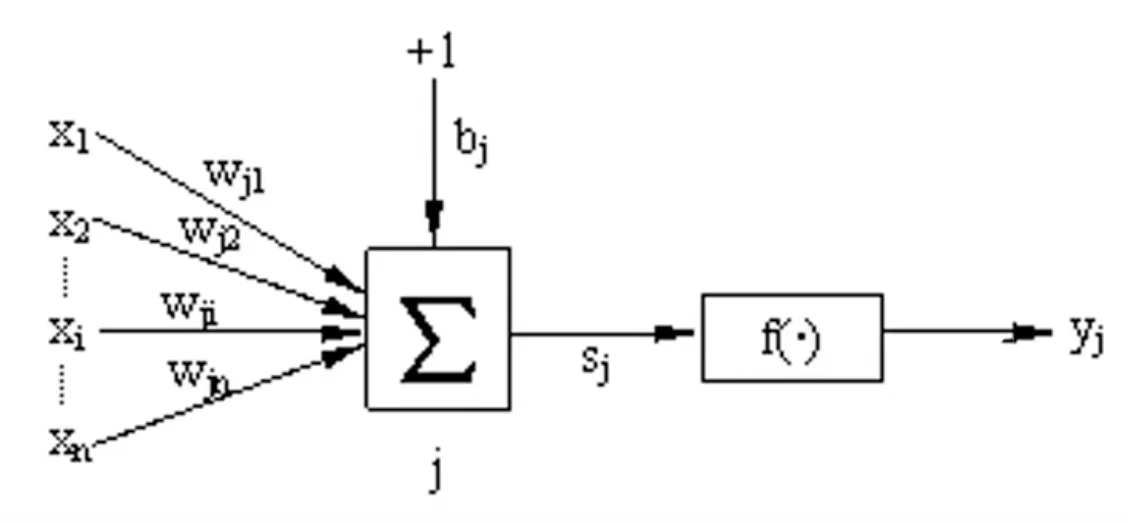
其中x1、x2...xi...xn分别代表来自神经元1、2...i...n的输入;wj1、wj2...wji...wjn分别代表的是神经元1、2...i...n与第j个神经元的连接强度(权值);bj是阈值,f()函数就是激活函数,yj是第j个神经元的输出。上图中第j个神经元的净输入值Sj为:
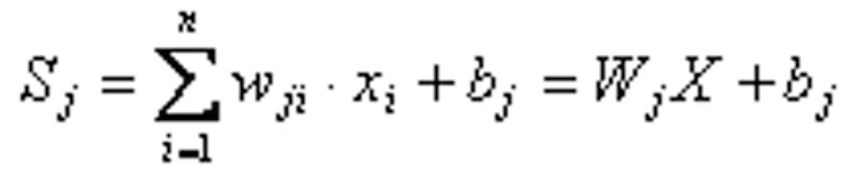
净输入Sj通过激活函数f()后,便得到第j个神经元的输出yj:
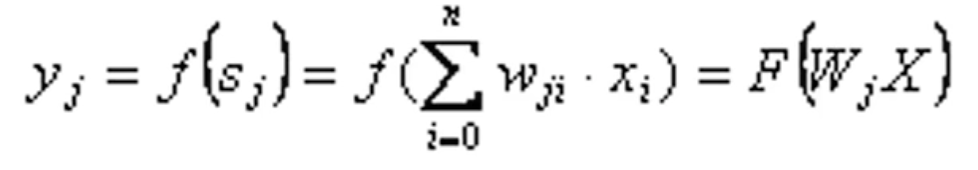
- BP网络的算法
- BP算法由数据流的前向计算(正向传播)和误差信号的反向传播两个过程构成。
- 正向传播时,传播方向为输入层->隐层->输出层,每层神经元的状态只影响下一层神经元。
- 若在输出层得不到期望的输出,则转向误差信号的反向传播流程。

通过这两个过程的交替进行,在权向量空间执行误差函数梯度下降策略,动态迭代搜索一组权向量,使网络误差函数(损失函数)达到最小值,从而完成信息提取和记忆功能。
- 正向传播
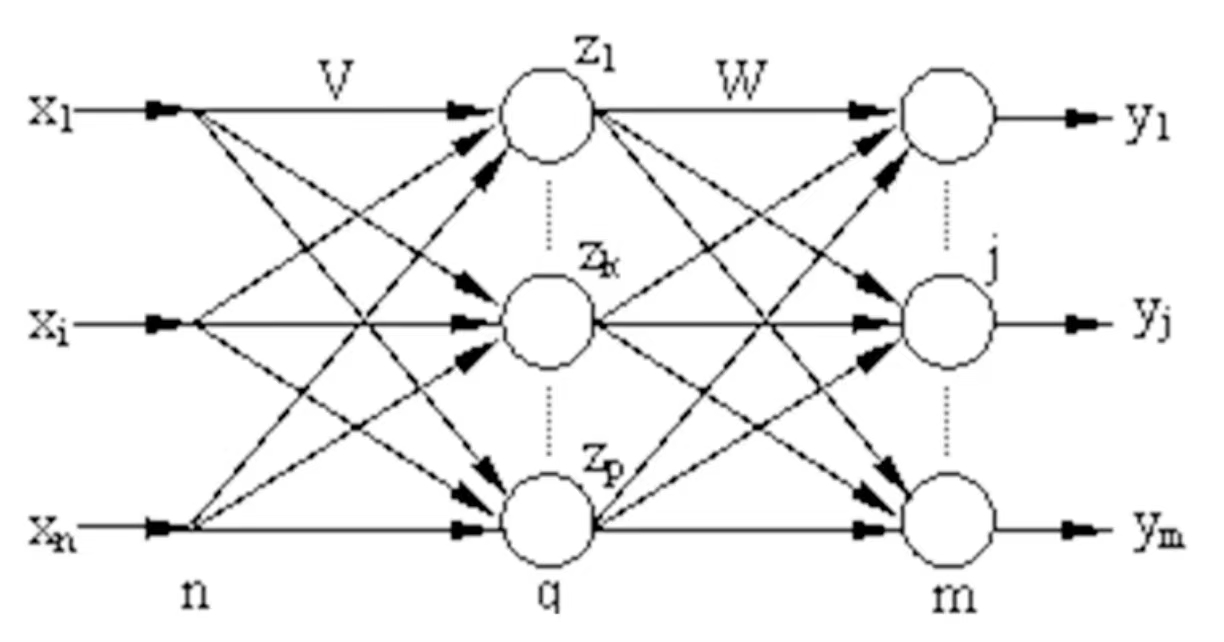
上图中,BP网络的输入层有n个节点,隐层有q个节点,输出层有m个节点。输入层与隐层之间的权值是V,隐层与输出层之间的权值是W。隐层的激活函数为f1(),输出层的激活函数为f2(),则隐层节点的输出为
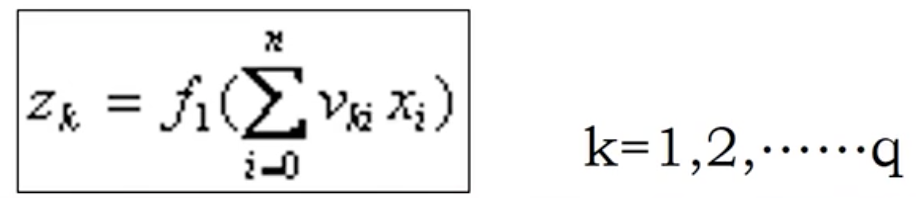
输出层节点的输出为
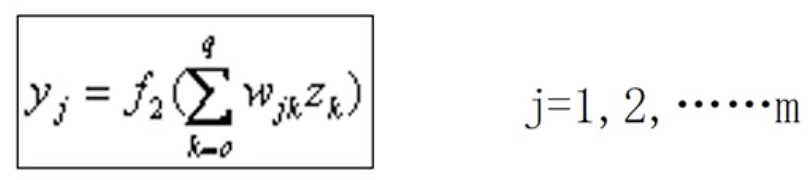
至此BP网络就完成了n维空间向量到m维空间的近似映射。
- 反向传播
定义误差函数(损失函数):输入p个学习样本,用x1、x2、...、xp来表示。第p个样本输入到网络后得到输出![]() 。采用平方型误差函数,于是得到第p个样本的误差Ep:
。采用平方型误差函数,于是得到第p个样本的误差Ep:

式中:![]() 为期望输入,也就是ground truth,标签。
为期望输入,也就是ground truth,标签。
对于p个样本全部输入,全局误差为:
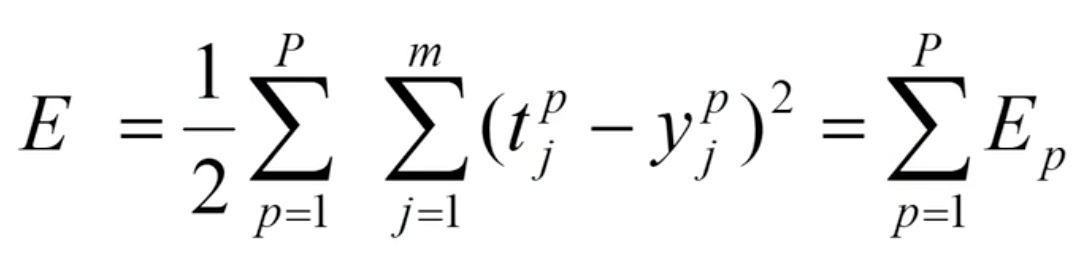
- 输出层权值的变化:
采用累计误差BP算法调整![]() ,使全局误差E变小,即
,使全局误差E变小,即
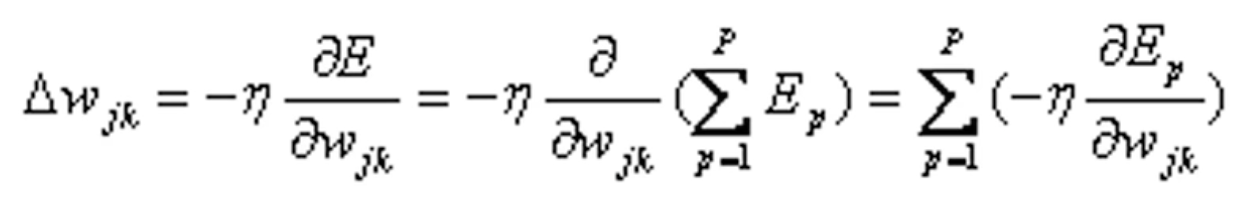
式中:η为学习率
定义误差信号为:
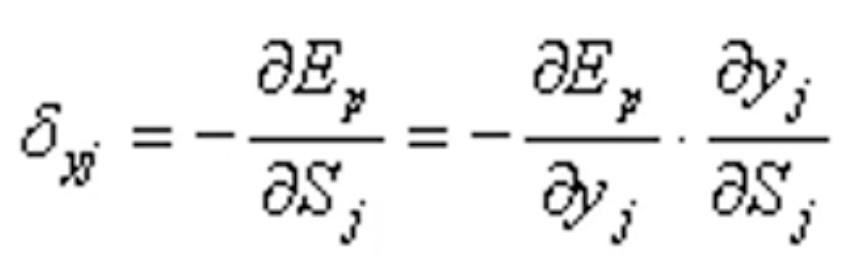
这里![]() 是单个样本的损失函数值,
是单个样本的损失函数值,![]() 是单个样本输出层的净激活值,
是单个样本输出层的净激活值,![]() 是输出值,也就是激活函数后的值。
是输出值,也就是激活函数后的值。
其中第一项:
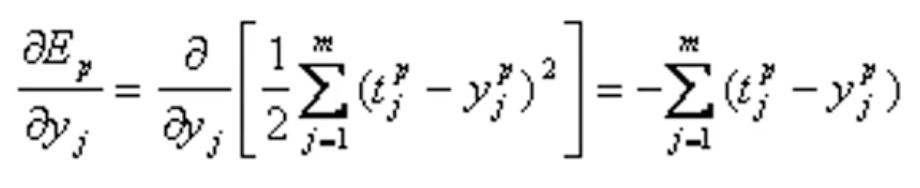
第二项:
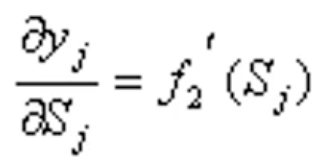
是输出层激活函数的偏微分。于是:
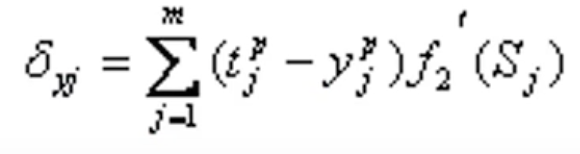
由链定理(复合函数求导)得:
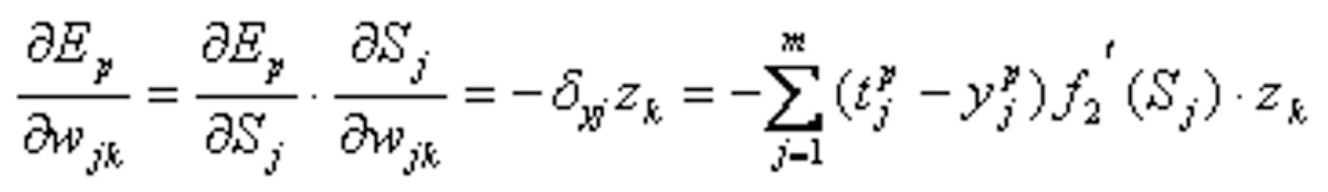
于是输出层各神经元的权值调整公式为:
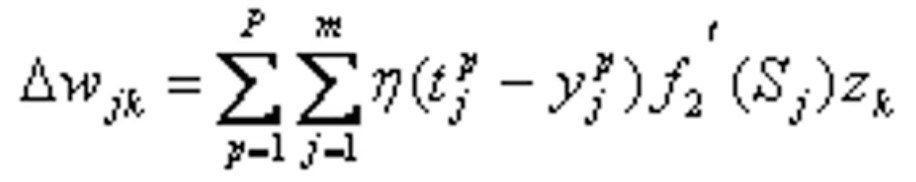
- 隐层权值的变化:
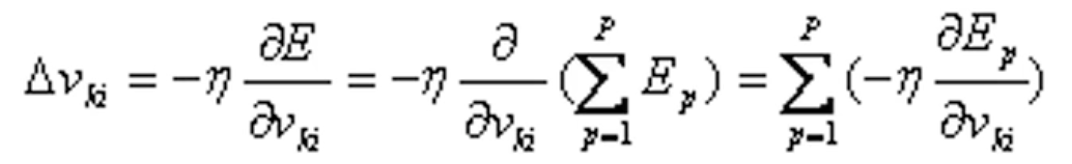
定义误差信号为:
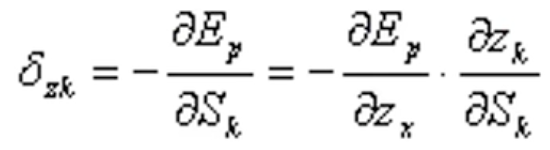
这里![]() 是单个样本的损失函数值,
是单个样本的损失函数值,![]() 是隐层的净激活值,
是隐层的净激活值,![]() 是隐层的输出值,也就是经过隐层激活函数的值。
是隐层的输出值,也就是经过隐层激活函数的值。
其中第一项:
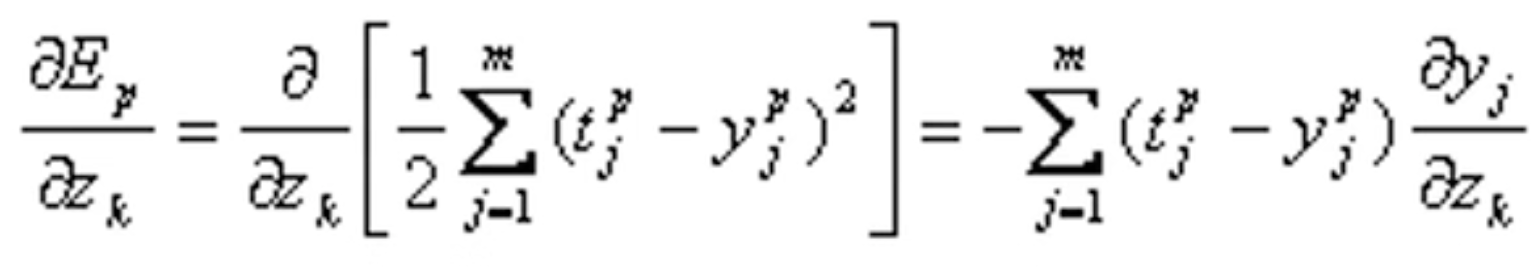
依链定理(复合函数求导)有:
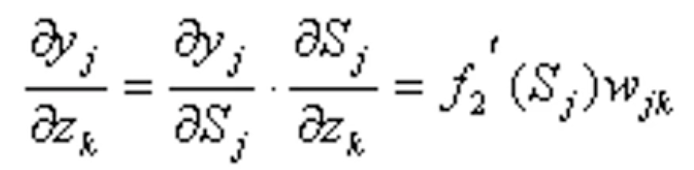
第二项:
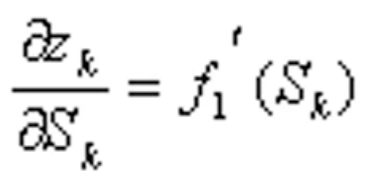
是隐层传递函数的偏微分。
于是:
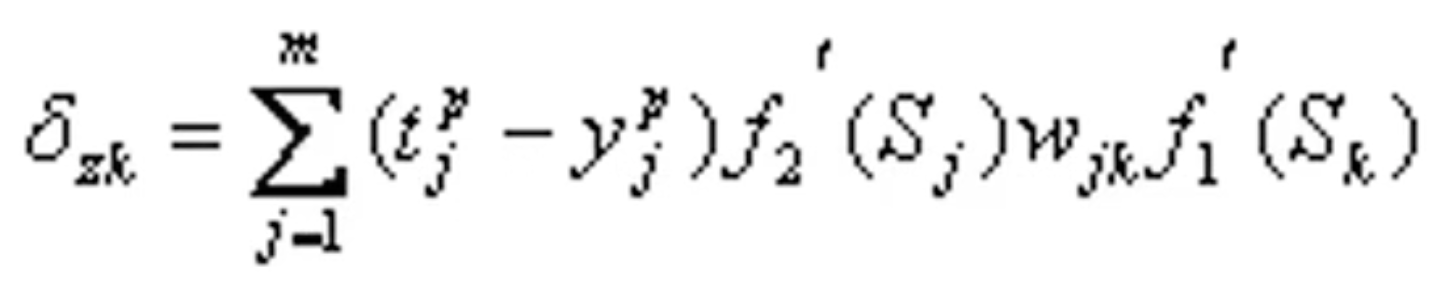
由链定理(复合函数求导)得:
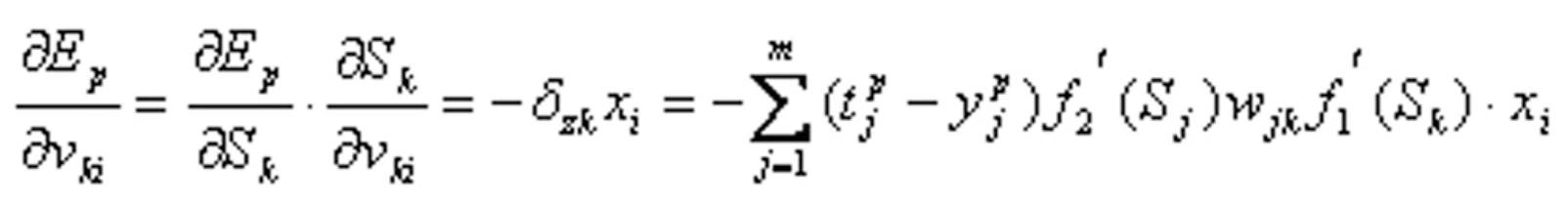
从而得到隐层各神经元的权值调整公式为:
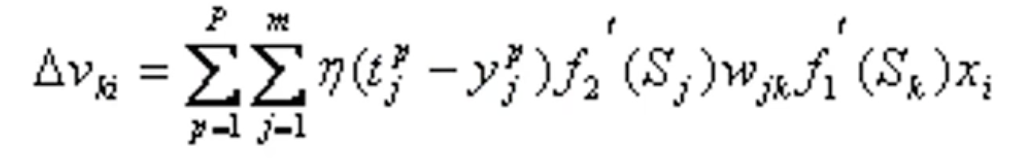
- BP模型学习算法的基本步骤:
- 从训练样例中取出一样例,把输入信息输入到网络中;
- 由网络分别计算各层节点的输出;
- 计算网络的实际输出和期望输出的误差;
- 从输出层反向计算到第一隐层,根据一定原则向减小误差方向调整网络的各个连接权值;
- 对训练样例集中的每一个样例重复以上步骤,直到对整个训练样集的误差达到要求为止。
BP算法理论具有依据可靠,推导过程严谨,精度较高,通用性较好等优点。但是标准的BP算法存在着以下缺点:
- 收敛速度缓慢;
- 容易陷入局部极小值;
- 难以确定隐层数和隐层节点个数。
- BP算法的改进
1、利用动量法改进BP算法
动量法权值调整算法的具体做法是:将上一次权值调整量的一部分迭加到按本次误差计算所得到的权值调整量上,作为本次的实际权值调整量,即:
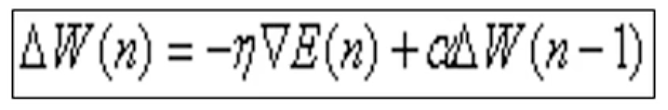
其中,α为动量系数,通常0<α<0.9;η为学习率,范围在0.001~10之间。
这种方法所加的动量因子实际上相当于阻尼项,它可以减小学习过程中的震荡趋势,从而改善收敛性。动量法降低了网络对于误差曲面局部细节的敏感性,有效的抑制网络陷入局部极小。
2、自适应调整学习速率
标准的BP算法收敛速度缓慢的一个重要原因是学习率选择不当。学习率选的太小,收敛太慢;而学习率选的太大,则有可能修正过头,导致震荡甚至是发散。
调整的基本指导思想是:在学习收敛的情况下,增大η,以缩短学习时间;当η偏大致使不能收敛时,要及时减小η,直到收敛为止。
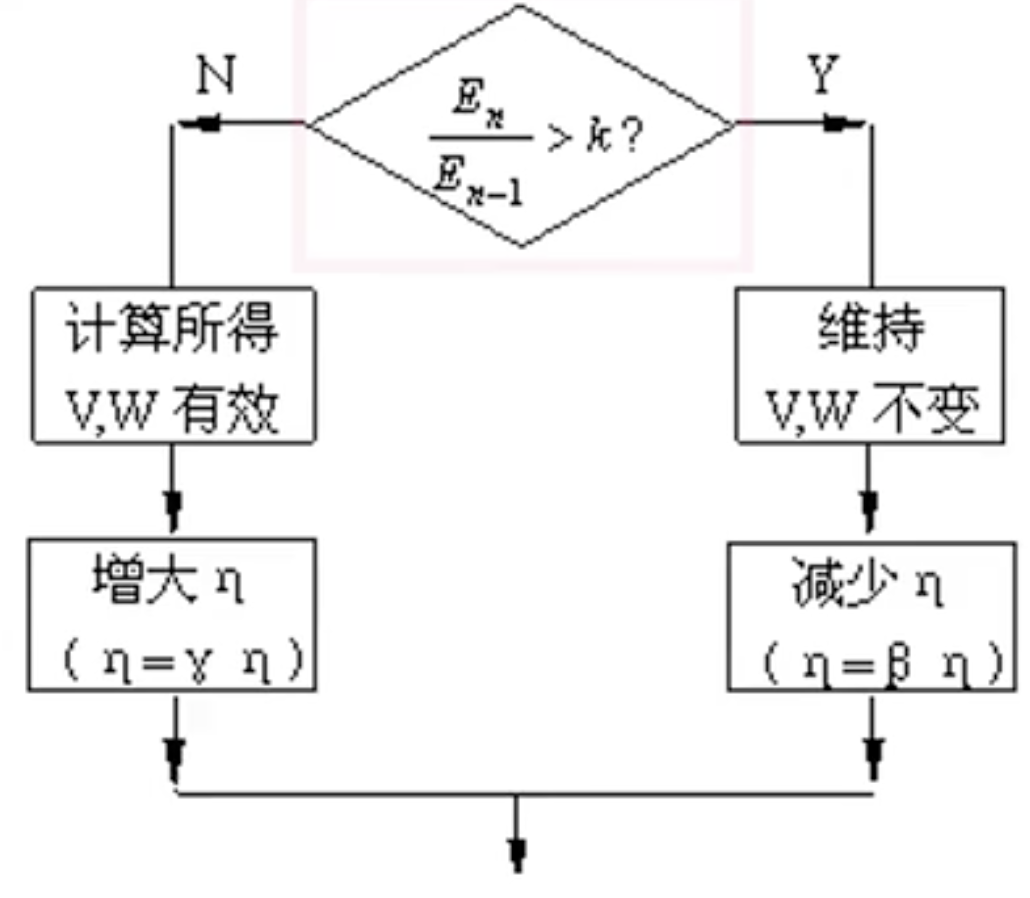
在上图中是第k次迭代中所得到的错误率![]() 除以第n-1次得到的错误率
除以第n-1次得到的错误率![]() ,用它们的比值和阈值k相比,如果比值大于k,说明此时学习率选的不恰当,需要维持V、W不变,减小学习率η;如果比值小于k,说明第n次得到的错误率要比前一次得到的错误率要小,说明得到的V、W有效,需要继续增大学习率η。这就是自适应调整学习率的算法。
,用它们的比值和阈值k相比,如果比值大于k,说明此时学习率选的不恰当,需要维持V、W不变,减小学习率η;如果比值小于k,说明第n次得到的错误率要比前一次得到的错误率要小,说明得到的V、W有效,需要继续增大学习率η。这就是自适应调整学习率的算法。
3、动量-自适应学习速率调整算法
采用动量法时,BP算法可以找到更优的解;采用自适应学习速率法时,BP算法可以缩短训练时间。将以上两种方法结合起来,就得到动量-自适应学习速率调整算法。
特征变换
通过适当的变换把D个特征转换为d个新特征。从一组已有的特征通过一定的数学运算得到一组新特征。这样做不仅可以降低维度,还可以消除特征之间可能存在的相关性。进而减少特征中与分类无关的信息,使得新特征更有利于分类。最经常采用的特征变换是线性变换。
线性变换
如果![]() 是D维原始特征,变换后的d维新特征
是D维原始特征,变换后的d维新特征![]() 为
为
![]()
其中W是D*d维矩阵,称为变换阵。
K-L变换
K-L变换也是模式识别中一种常用的特征变换方法——正交变换,有多个变种,但基本原理和主成分分析是相似的(主成分分析属于线性变换,主要内容可以参考机器学习算法整理 中的PCA 与梯度上升法)。
- K-L展开式
- 模式识别中的一个样本可以看作是随机向量的一次实现。
- 假设X的一个集合是N维随机模式向量x的一个集合,对于每一个x都可以用确定归一化正交向量系中的正交向量展开:
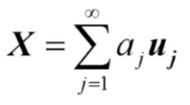
其中![]() :线性组合系数。从上面的表达式可以看出我们可以把X表示成一系列正交向量
:线性组合系数。从上面的表达式可以看出我们可以把X表示成一系列正交向量![]() 的线性组合。正交意味着
的线性组合。正交意味着
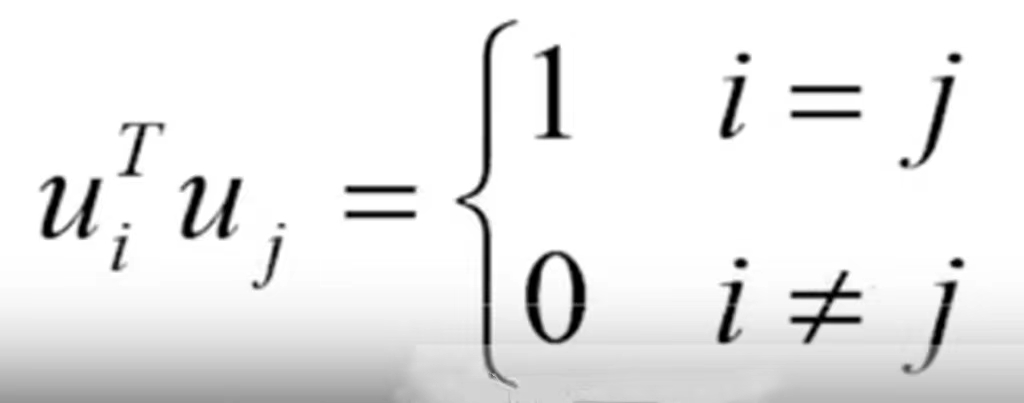
i、j相同表示是同一个向量,转置相乘为1,i、j不同,两个不同的正交向量,相乘为0。这里其实是一组正交基,有关正交基的内容可以参考线性代数整理(二) 中的正交基与标准正交基。
这里我们可以把x看成是一组波形
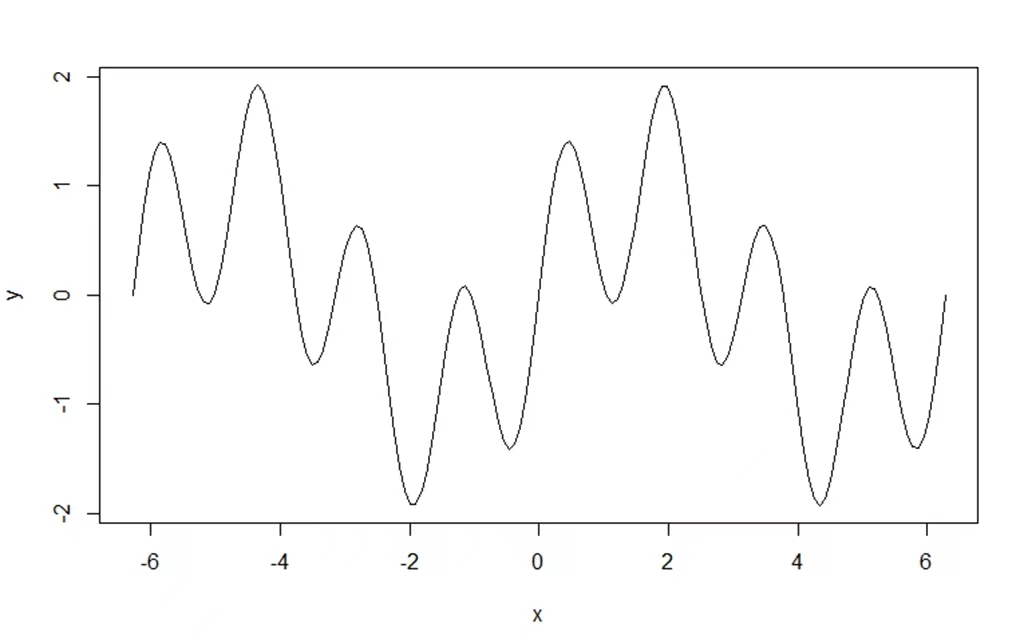
这组波形实际上是由两组不同频率的正弦波叠加而成
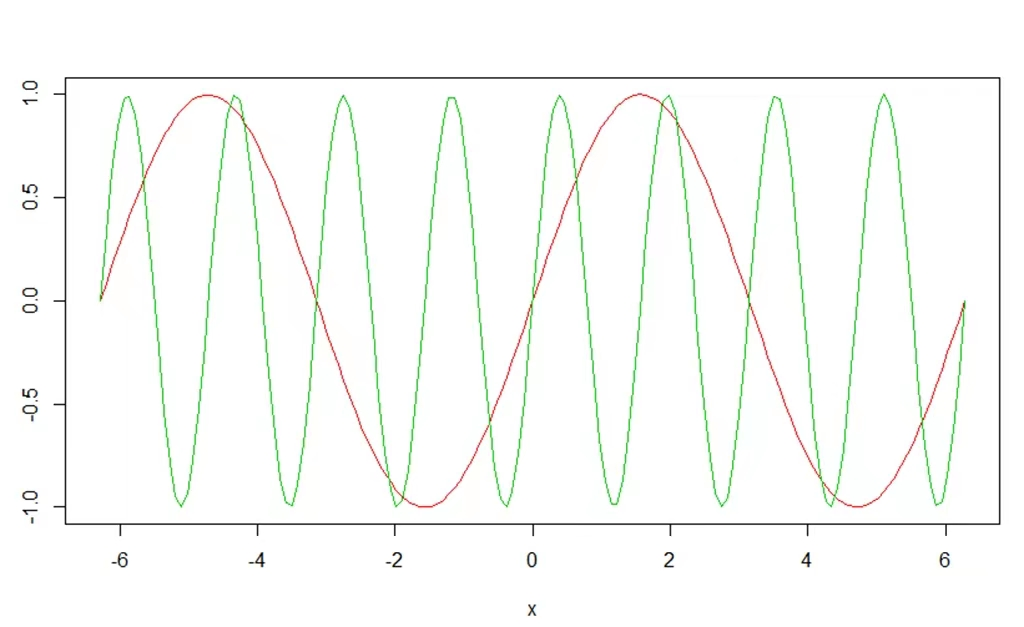
我们希望通过变换将这两种波形分解出来,中的X就是原始波,而![]() 中的每一个a1、a2...就是分离出来的正弦波,而
中的每一个a1、a2...就是分离出来的正弦波,而![]() 就是正交基,这就是正交变换。
就是正交基,这就是正交变换。
- 均方误差
如果只用有限项来逼近,即
 (x为D维,d<D)
(x为D维,d<D)
均方误差为:![]()
将x和x的逼近值代入均方误差,得到:
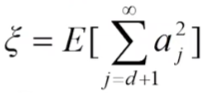
![]() 是正交向量系,得到:
是正交向量系,得到:
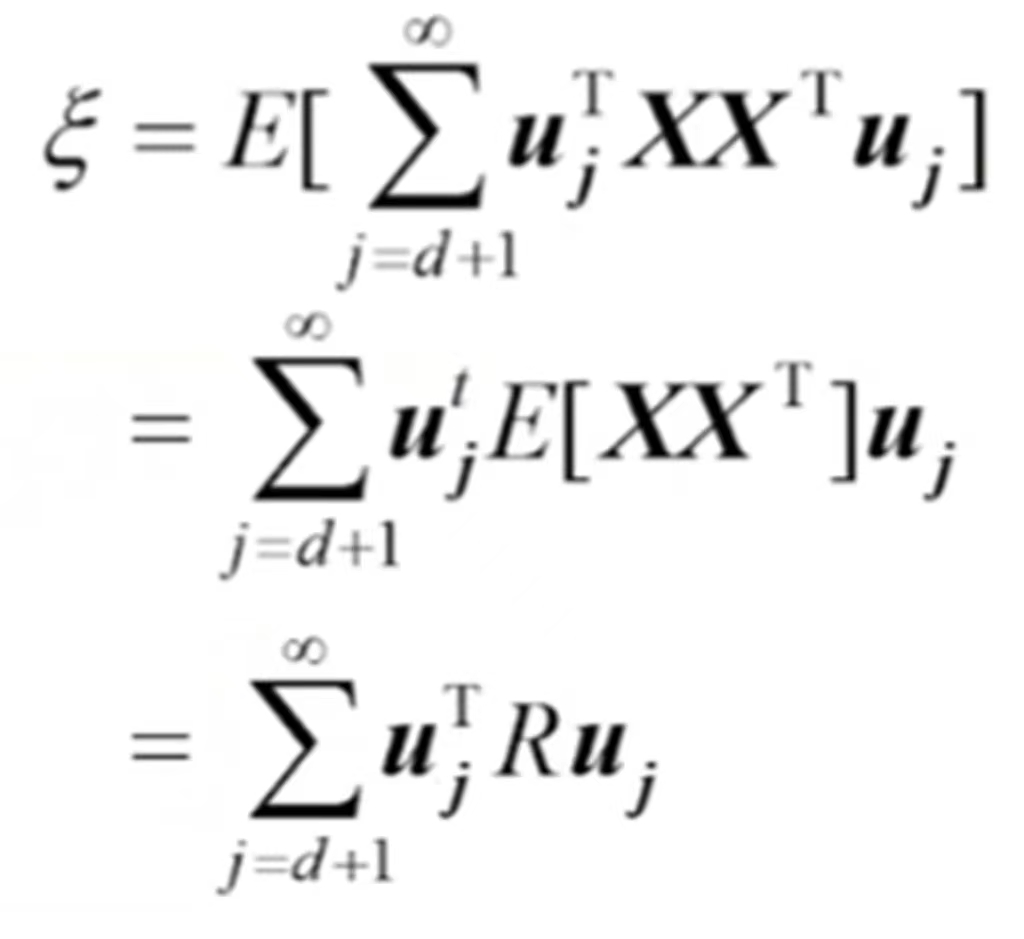
其中R为产生矩阵。
不同的![]() 对应不同的均方误差,
对应不同的均方误差,![]() 的选择应使ξ最小。利用拉格朗日乘数法使ξ最小的正交系{
的选择应使ξ最小。利用拉格朗日乘数法使ξ最小的正交系{![]() },令
},令
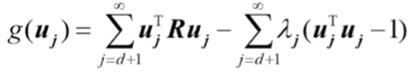
这里![]() 为拉格朗日系数
为拉格朗日系数
用函数![]() 对
对![]() 求导,并令导数为0,得
求导,并令导数为0,得
![]()
这说明![]() 是矩阵R的特征向量,
是矩阵R的特征向量,![]() 是矩阵R的特征值。
是矩阵R的特征值。
将![]() 代入均方误差ξ的表达式,得到选前d项估计X时引起的均方误差为:
代入均方误差ξ的表达式,得到选前d项估计X时引起的均方误差为:
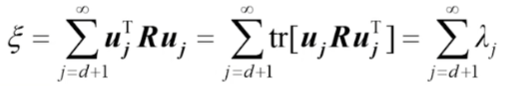
![]() 决定截断的均方误差,
决定截断的均方误差,![]() 的值小,那么ξ也小。
的值小,那么ξ也小。
把矩阵R的特征值按照从大到小的顺序排列,选择前d个特征值对应的特征向量作为![]() ,这样可以使得均方误差ξ最小。
,这样可以使得均方误差ξ最小。