文章目录
参考文献:
https://blog.csdn.net/weixin_44791964/article/details/107406072
1 什么是孪生神经网络
不要被名字误导,孪生和双胞胎没什么关系…
简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
(突然想到CNN 的特点也是权值共享…)
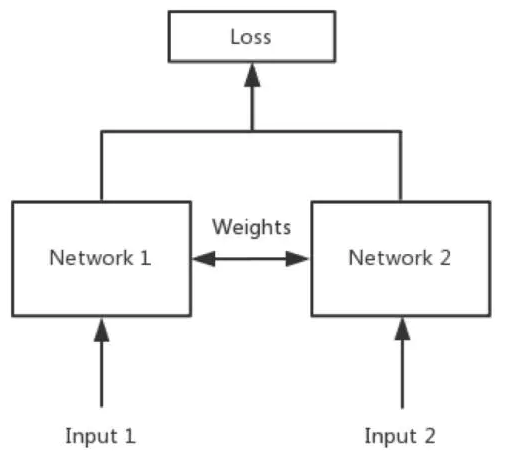
- 权值共享:当神经网络有两个输入的时候,这两个输入使用的神经网络的权值是共享的(可以理解为使用了同一个神经网络)
如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。这个时候我们就可以理解孪生神经网络为什么要进行权值共享了。
2 主干网络
作用:对数据进行特征提取,各种神经网络都是适用的。(图片学习可以用VGG16)
3 比较网络
在获得主干特征提取网络之后,我们可以获取到一个多维特征,我们可以使用flatten的方式将其平铺到一维上,这个时候我们就可以获得两个输入的一维向量了。(比如说两个32d的向量,1*32)
将这两个一维向量进行相减,再进行绝对值求和,相当于求取了两个特征向量插值的L1范数。也就相当于求取了两个一维向量的距离。
然后对这个距离再进行两次全连接,第二次全连接到一个神经元上,对这个神经元的结果取sigmoid,使其值在0-1之间,代表两个输入图片的相似程度。
4 数据集格式
对于神经网络来说,处理好数据集是非常重要的一步。现在我们使用的是一些开源数据集,是一些已经被整理好、处理过的数据集,但是对于自己的研究来说,要学会如何处理数据集,如何打标签、如何索引到每个数据都是很重要的!
本文所使用的数据集为Omniglot数据集。
其包含来自 50不同字母(语言)的1623 个不同手写字符。每一个字符都是由 20个不同的人通过亚马逊的 Mechanical Turk 在线绘制的。
相当于每一个字符有20张图片,然后存在1623个不同的手写字符,我们需要利用神经网络进行学习,去区分这1623个不同的手写字符,比较输入进来的字符的相似性。
- 数据的层级目录:
- image_background
- Alphabet_of_the_Magi
- character01
- 0709_01.png
- 0709_02.png
- ……
- character02
- character03
- ……
- Anglo-Saxon_Futhorc
- ……
数据集的下载,我是在bubbliiiing的博文里找到他的代码然后根据代码里面的readme 找到他给出的百度网盘的链接下载的!
5 训练模型——学习代码train.py
5.1 引入依赖包
import os
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from nets.siamese import Siamese
from utils.callbacks import LossHistory
from utils.dataloader import SiameseDataset, dataset_collate
from utils.utils import (download_weights, get_lr_scheduler, load_dataset,
set_optimizer_lr, show_config)
from utils.utils_fit import fit_one_epoch
5.2 把训练好的权重放到文件夹中
bubbliiiing提供了VGG训练好的权重,可以直接使用,下载方式同Omniglot数据集。
放在model_data文件夹下就好了。

权值文件的下载请看README,可以通过网盘下载。模型的预训练权重 对不同数据集是通用的,因为特征是通用的。
模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
当model_path = ''的时候不加载整个模型的权值。
此处使用的是整个模型的权重,因此是在train.py进行加载的,pretrain不影响此处的权值加载。
***如果想要让模型从主干的预训练权值开始训练,则设置model_path = '',pretrain = True,此时仅加载主干。
如果想要让模型从0开始训练,则设置model_path = '',pretrain = Fasle,此时从0开始训练。
一般来讲,从0开始训练效果会很差,因为权值太过随机,特征提取效果不明显。
网络一般不从0开始训练,至少会使用主干部分的权值,有些论文提到可以不用预训练,主要原因是他们 数据集较大 且 调参能力优秀。
如果一定要训练网络的主干部分,可以了解imagenet数据集,首先训练分类模型,分类模型的 主干部分 和该模型通用,基于此进行训练。
经过阅读了readme 和代码中的注释之后,我决定加载预训练好的主干网络(VGG)的模型权重。
那么代码就是:
pretrained = True
model_path = ""
5.3 从预训练权重开始训练
- 第一部分的代码
Cuda = True
distributed = False # 不是Ubuntu不用管
sync_bn = False # 不是Ubuntu不用管
fp16 = False # 不是Ubuntu不用管
dataset_path = "datasets"
input_shape = [105, 105] # 输入图像的大小,默认为105,105,3
train_own_data = False # 训练Omniglot为False,训练自己的数据集为True
pretrained = True # 使用预训练好的vgg模型权重
model_path = ""
Init_Epoch = 0
Epoch = 100
batch_size = 32
- 注释:
(一)从预训练权重开始训练:
Adam:
Init_Epoch = 0,Epoch = 100,optimizer_type = 'adam',Init_lr = 1e-3,weight_decay = 0。
SGD:
Init_Epoch = 0,Epoch = 100,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 5e-4。
#其中:UnFreeze_Epoch可以在100-300之间调整。
(二)batch_size的设置:
在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。
受到BatchNorm层影响,batch_size最小为2,不能为1。
正常情况下Freeze_batch_size建议为Unfreeze_batch_size的1-2倍。不建议设置的差距过大,因为关系到学习率的自动调整。
- 第二部分的代码:
在这里插入代码片
- 注释:
Init_lr 模型的最大学习率
当使用Adam优化器时建议设置 Init_lr=1e-3
当使用SGD优化器时建议设置 Init_lr=1e-2
Min_lr 模型的最小学习率,默认为最大学习率的0.01