多元时间序列预测任务主要解决的是输入多变量时间序列,预测多变量未来序列的问题,多变量的序列之间存在一定的相互影响关系。多元时间序列预测相比一般的单变量时间预测,如何在建模temporal关系的同时建立不同变量空间上的关系至关重要。今天给大家介绍两篇2022年8月份发表的最新多元时间序列预测工作,两篇工作均有开源代码。
两篇文章的概要分别如下。
论文1-Expressing Multivariate Time Series as Graphs with Time Series Attention Transformer:通过SMD将时间序列分解成多个IMF周期性序列+趋势项后,建立多变量之间的关系图,利用改进的Transformer实现节点信息、边关系、图结构三者信息融合进行预测。
论文2-Spatial-Temporal Identity: A Simple yet Effective Baseline for Multivariate Time Series Forecasting:通过引入id embedding的方式缓解历史趋势相同、未来趋势不同导致的样本无法区分问题。这种方式可以替代STGCN等引入图结构的复杂模型。
1
论文1-多元序列转换为图进行预测

论文题目:Expressing Multivariate Time Series as Graphs with Time Series Attention Transformer
下载地址:https://arxiv.org/pdf/2208.09300v1.pdf
开源代码:https://github.com/radiantresearch/tsat
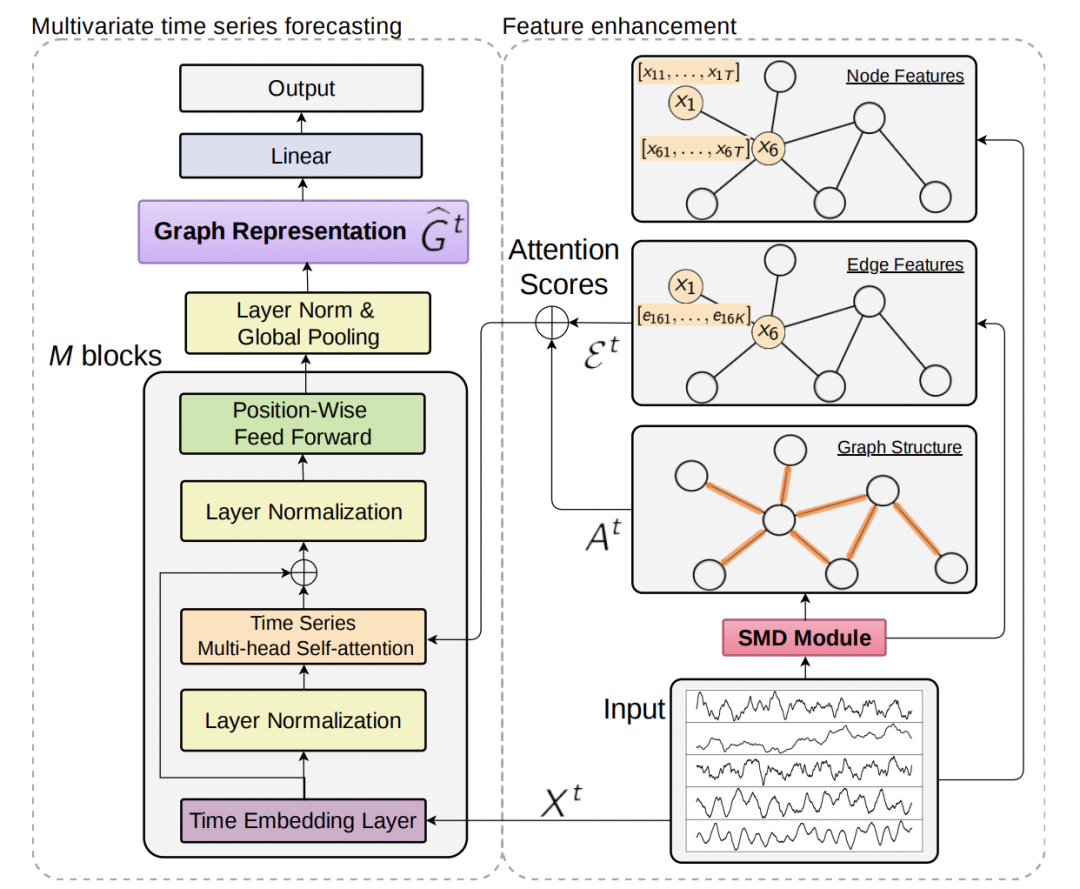
这篇工作的核心主要包括多变量序列构图和Transformer改进两个部分。
在多变量序列构图中,首先通过SMD对原时间序列进行分解,再根据SMD提取出的特征信息进行构图。SMD是经验模态分解的一种方法,它可以将原始的序列拆分成多个序列加一个趋势项,分解出来的序列叫作IMF(内涵模态分量)。IMF是有一定要求的,如极值点的个数和过零点的个数必须相等或相差最多不能超过一个、局部极大值点形成的上包络线和由局部极小值点形成的下包络线的平均值为零等。通过SMD可以把原始序列拆分成多个子序列,这些子序列会作为后续建模的重要特征。EMD分解有比较成熟的python包emd,大家可以自行体验一下分解结果。
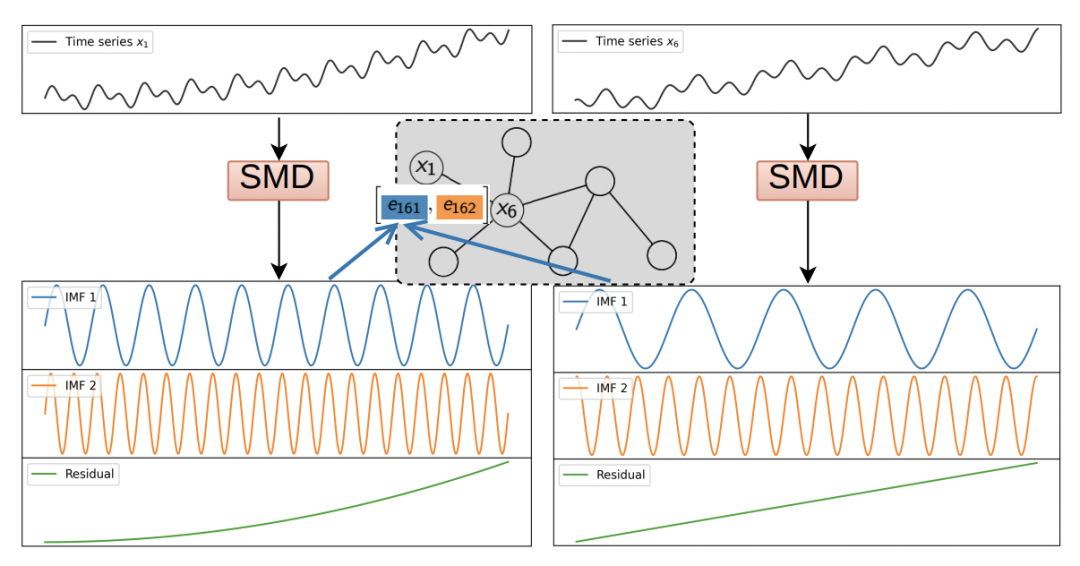
在得到每个序列的IMF后,下一步是根据IMF进行构图。每个变量作为一个节点,节点的特征是该变量的时间序列。每两个节点之间都有边特征,边特征是根据两个序列各个IMF分解结果分别计算的相似度,公式如下,计算第i和第j个节点中第k个IMF的相似度:
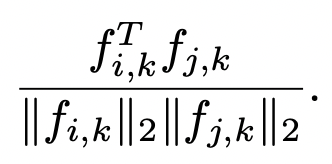
在邻接矩阵的构造上,文中计算两两节点序列趋势项对应序列的相似度,当相似度大于一定阈值时,这两个序列建立边,通过这种方式将具有相似趋势的变量连接起来。
第二个核心点是Transformer模型的应用。首先对于每个节点使用一个RNN生成embedding,这和我们之前介绍过的Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting(2019)相同,通过RNN的时序建模能力取代position embedding,增强Transformer对序列中各个点位置关系的感知。
本文将self-attention模块的计算方法修改为如下公式,同时考虑节点序列信息、节点间关系信息、图结构信息:
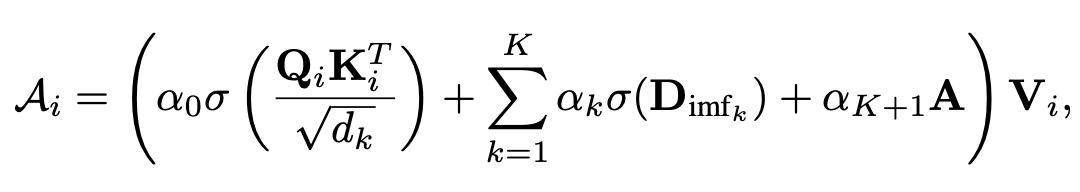
其中第一项就是传统Transformer对每个节点时间序列内部进行self-attention;第二项是引入每个IMF对应边特征的信息,第三项是将邻接矩阵的信息引入。经过多层Transformer后通过layer norm和全连接输出预测结果。
文中在经典的多元序列预测上进行实验,对比了一些图学习模型、深度学习模型的效果,实验结果如下:
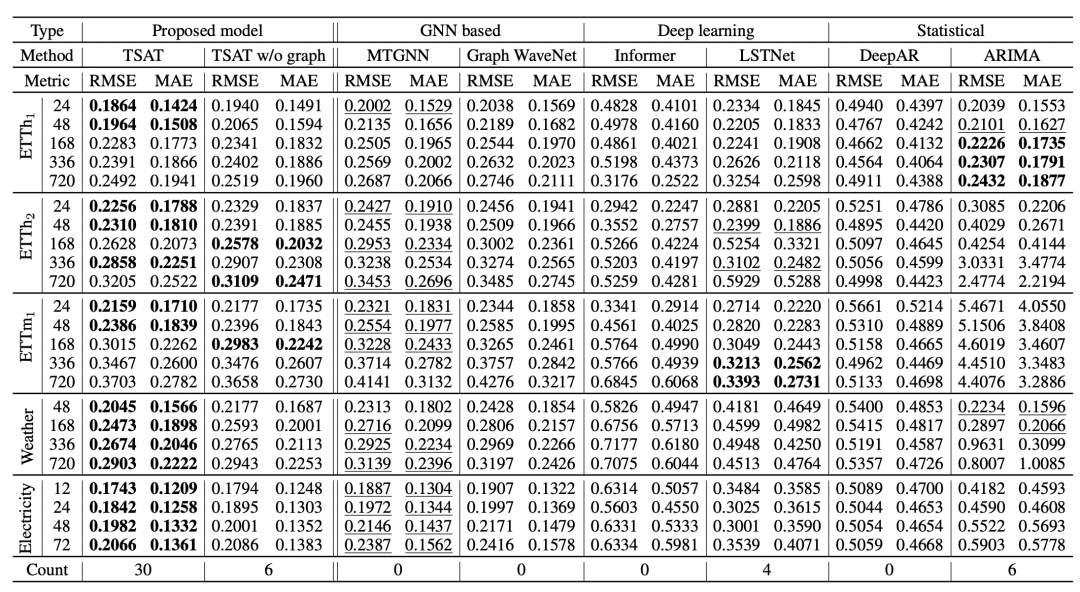
2
论文2-id特征代替复杂图模型

论文题目:Spatial-Temporal Identity: A Simple yet Effective Baseline for Multivariate Time Series Forecasting
开源代码:https://arxiv.org/pdf/2208.05233v2.pdf
开源代码:https://github.com/zezhishao/STID
本文的是CIKM 2022上发表的一篇短文,出发点是一个很简单的现象:历史规律相同的序列,未来的曲线可能不同,导致模型难以只根据历史序列作为不同的预测。比如下面这个例子,最上面的图选取了3个不同的窗口W,P代表历史,F代表未来。W1是空间中两个传感器的变量历史和未来的序列,这两个传感器历史序列基本相同,未来的差异却很大,只根据历史序列拟合一个回归模型是无法建立这种区别的。
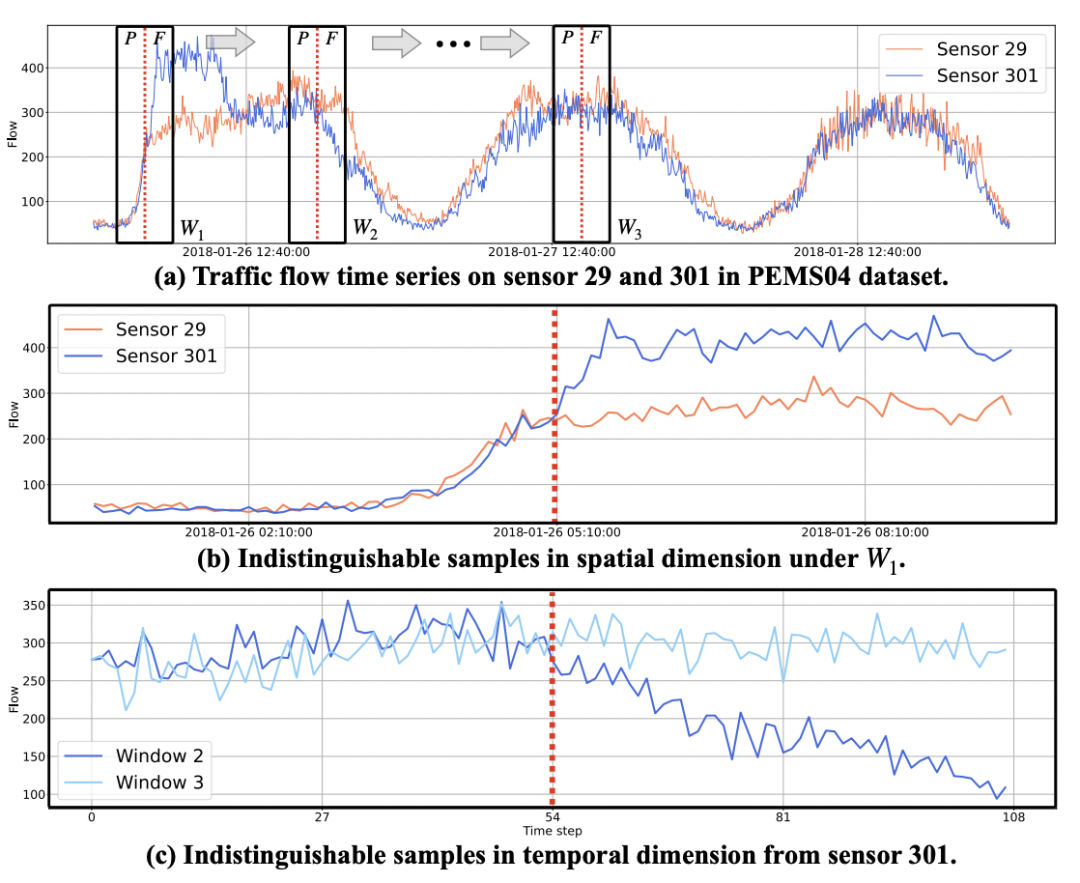
以往解决图学习的模型,例如STGCN中,利用图卷积建立空间不同节点之间的关系,同时使用时序模型进行时序建模。这种方式带来效果提升的原因,主要在于引入了卷积带来的了不同节点相同历史序列但是不同未来序列的区分能力。本文认为直接通过加入id embedding的方式就能解决这个问题,因此设计了如下结构:将序列的id、时间信息的id等转换成embedding,和时间序列模型生成的序列表示拼接到一起,用于后续的预测。

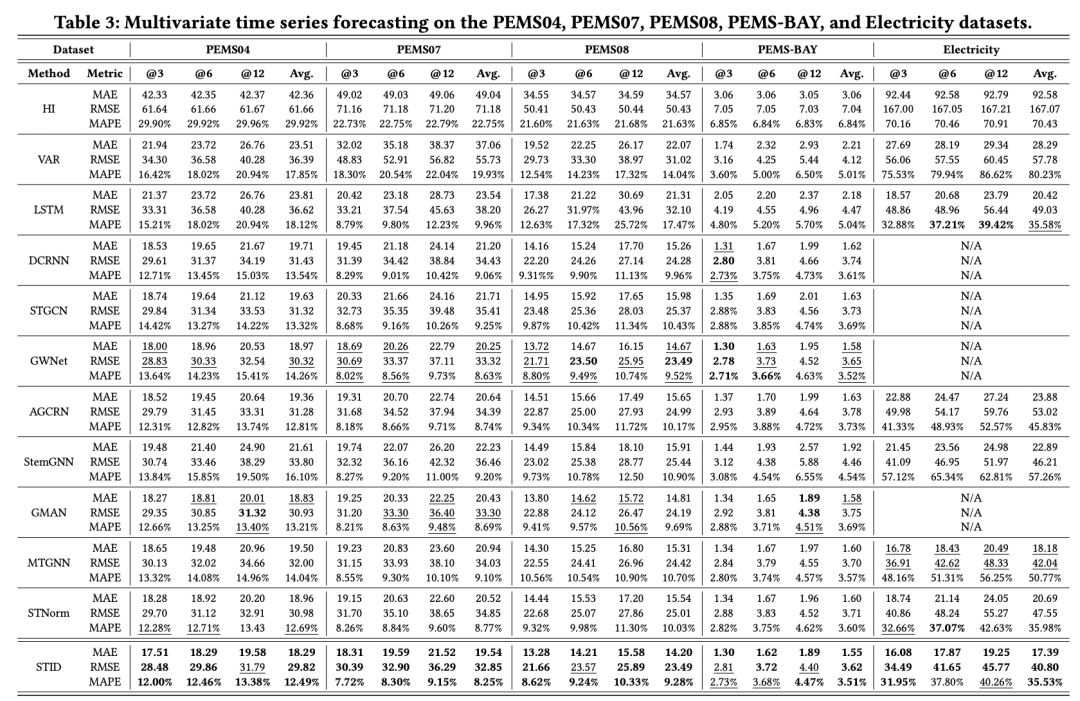
从下面的实验结果来看,这种简单的方法效果比之前很多图模型的效果都好:
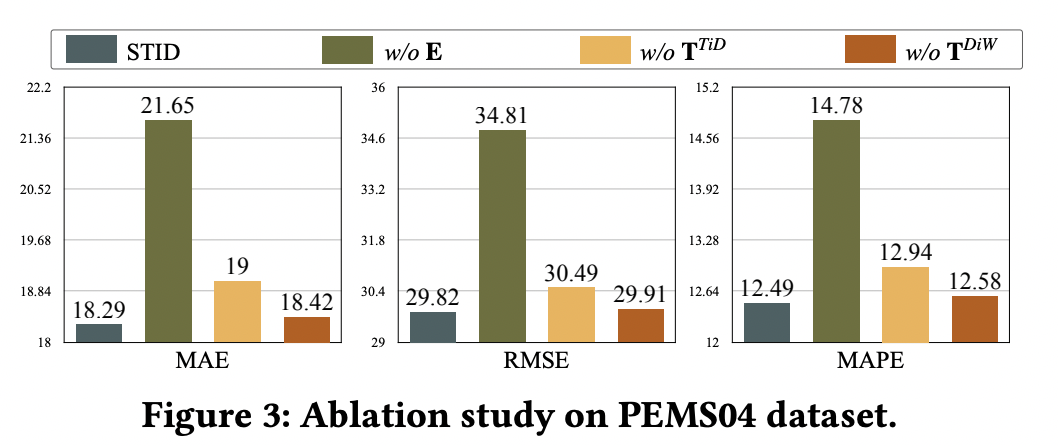
从下面的消融实验中可以看到,加入每个序列的id embedding对效果影响非常大:
3
总结
本文介绍了两篇近期发表的多元时间序列预测模型文章,第一篇通过SMD分解原序列建立各个节点的空间关系,并改造Transformer融合时序信息、节点关系信息、图结构信息。第二篇通过简单的引入id embedding的方式达到了和复杂图时空预测模型相当的效果。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书