目录
35.3假设所有的业务,只要一条DML语句就能完成,还有必要存在事务机制吗?
1,读未提交:read uncommitted(最低的隔离级别)(没有提交就读到了)
2,读已提交:read committed(提交之后才能读到)
3,可重复读:repeatable read(提交之后也读不到,永远读取的都是刚开启事务 时的数据)
4,序列化/串行化:serializable(最高的隔离级别)
34,存储引擎(了解内容)
34.1什么是存储引擎,有什么用
存储引擎是mysql中特有的一个术语,其他数据库没有(oracle中有,但是不叫这 个名字)
存储引擎实际上是一个表存储/组织数据的方式,不同的存储引擎,表存储数据的方式不同
34.2怎么给表添加/指定存储引擎
show create table t_student;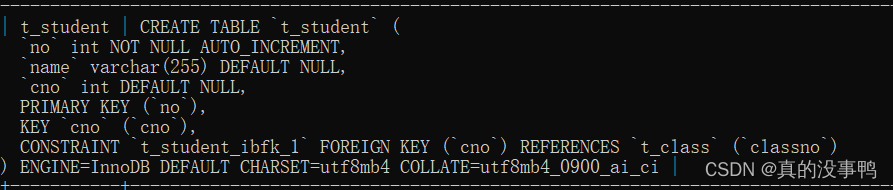
在建表的时候可以在最后小括号的”)”的右边使用:ENGINE来指定存储引擎,CHARSET来指定这张表的字符编发方式
mysql> create table t_protect(
id int primary key,
name varchar(255)
)ENGINE=InnoDB default CHARSET=utf8;说明:
mysql默认的存储引擎是:InnoDB
mysql默认的字符编码方式是utf8
34.3怎么查看mysql支持那些存储引擎
命令:
mysql> show engines \G;34.4关于mysql常用的存储引擎
1,MyISAM存储引擎
它管理的表具有以下特征:
使用三个文件表示每个表
格式文件-存储表结构的定义(mytable.frm)
数据文件-存储表行的内容(mytable.MYD)
索引文件-存储表上索引(mytable.MYI)
索引是一本书的目录,缩小扫描范围,提高查询效率的一种机制
可被转换为压缩,只读表来节省空间
说明:对于一张表来说,只要是主键,或者加有unique约束的字段上会自动创建索引
MyISAM存储引擎特点:
可被转换为压缩,只读表来节省空间
这是这种存储引擎的优势
MyISAM不支持事务机制,安全性低
2,InnoDB存储引擎
这是mysql默认的存储引擎,同时也是一个重量级的存储引擎
InnoDB支持事务,支持数据库崩溃后自动恢复机制
InnoDB存储引擎最主要的特点是:非常安全
它管理的表具有以下特征
-每个InnoDB表在数据库目录中以.frm格式文件表示
-InnoDB表空间tablespace被用于存储表的内容
-提供一组用来记录事务性活动的日志文件
-用COMMIT(提交)、SAVEPOINT及ROLLBACK(回滚)支持事务处理
-提供全ACID兼容
-在mysql服务器崩溃后提供自动恢复
-多版本(MVCC)和行级锁定
-支持外键及引用的完整性,包括级联删除和更新
InnoDB最大的特点就是支持事务:以保证数据的安全,但是效率不是很高, 并且也不能压缩,不能转换为只读,不能很好的节省存储空间
3,MEMORY存储引擎
使用MEMORY存储引擎的表,其数据存储在内存中,且行的长度固定
这两个特点使得MEMORY存储引擎非常快
MEMORY存储引擎管理的表具有以下特征:
-在数据库目录内,每个表均以.frm格式的文件表示
-表数据及索引被存储在内存中(目的就是快,查询快)
-表级锁机制
-不能包含TEXT或BLOB字段
MEMORY存储引擎以前被称为HEAP引擎
MEMORY引擎优点:查询效率是最高的
MEMORY引擎缺点:不安全,关机之后数据消失,因为数据和索引都是在内 存当中
35,事务(重点,必须掌握)
35.1什么是事务
一个事务其实就是一个完整的业务逻辑
什么是一个完整的业务逻辑?
假设转账,从A账户向B账户中转账10000,将A账户的钱减去10000(update语句),将B账户的钱加上10000(update语句)。这就是一个完整的业务逻辑
以上的操作是一个最小的工作单元,要么同时成功,要么同时失败,不可再分
这两个update语句要求必须同时成功或者同时失败,这样才能保证钱是正确 的
35.2只有DML语句才会有事务一说,其他语句和事务无关!
insert
delete
Update
只和以上的三个语句和事务有关系,其他都没有关系,因为只有以上的三个语句是数据库表中数据进行增,删,改的。只要你的操作一旦涉及到数据增,删,改,那么就一定要考虑安全问题
数据安全是第一位!!!
35.3假设所有的业务,只要一条DML语句就能完成,还有必要存在事务机制吗?
正是因为做某件事的时候需要多条DML语句共同联合起来才能完成,所以需要事务的存在,如果任何一件复杂的事都能一条DML语句搞定。那么事务则没有存在的价值
到底什么是事务呢?
说到底,本质上,一个事务其实就是多条DML语句同时成功,或者同时失败
事务:就是批量的DML语句同时成功,或者同时失败!
35.4事务是怎么做到多条DML语句同时成功和同时失败的呢
InnoDB存储引擎:提供一组用来记录事务性活动的日志文件
在事务的执行过程中,每一条DML的操作都会记录到”事务性活动的日志文件 中”
在事务的执行过程中,我们可以提交事务,也可以回滚事务
提交事务:
清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中
提交事务标志着事务的结束,并且是一种全部成功的结束
回滚事务:
将之前所有的DML操作全部撤销,并且清空事务性活动的日志文件
回滚事务标志着事务的结束,并且是一种全部失败的结束
35.5怎么提交事务,怎么回滚事务
提交事务:commit;语句
回滚事务:rollback;语句(回滚永远都是只能回滚到上一次的提交点)
事务对应的英语单词是:transaction
测试一下:在mysql当中默认的事务行为是怎样的?
mysql默认情况下是支持自动提交事务的(自动提交)
什么是自动提交?
每执行一条DML语句,则提交一次。这种自动提交实际上是不符合我们的开发习惯,因为一个业务通常是需要多条DML语句共同执行才能完成的,为了保证数据的安全必须要求同时成功之后再提交,所以不能执行一条就提交一条
怎么将mysql的自动提交机制关闭掉呢
先执行这个命令:start transaction;
演示事务:
---------------------------------回滚事务----------------------------------------------
mysql> start transaction;
mysql> insert into dept_bak values(10,'abc','beijing');
mysql> insert into dept_bak values(10,'abc','beijing');
mysql> insert into dept_bak values(10,'abc','beijing');
mysql> select * from dept_bak;
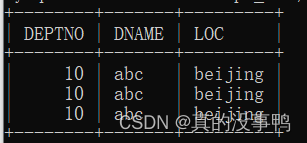
mysql> rollback;
mysql> select * from dept_bak;

可以发现dept_bak表中数据已经清空了,也就是回滚了
---------------------------------提交事务----------------------------------------------
mysql> start transaction;
mysql> insert into dept_bak values(10,'abc','beijing');
mysql> insert into dept_bak values(10,'abc','beijing');
mysql> insert into dept_bak values(10,'abc','beijing');
mysql> commit;
mysql> select * from dept_bak;
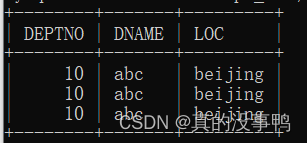
mysql> rollback;
mysql> select * from dept_bak;
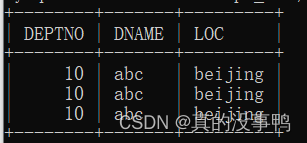
可以发现,经过commit(提交)后再rollback也不会回滚了
35.6事务包括四个特性
A:原子性
说明事务是最小的工作单元,不可再分
C:一致性
所有事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败以保证数据的一致性
I:隔离性
a事务和b事务之间具有一定的隔离
教室A和教室B之间有一道墙,这道墙就是隔离性
a事务在操作一张表的时候,另一个事务b也操作这张表会怎样???
D:持久性
事务最终结束的一个保障,事务提交,就相当于将没有保存到硬盘上的数据保 存到硬盘上!
35.7重点研究事务的隔离性
A教室和B教室中间有一道墙,这道墙可以很厚,也可以很薄。这就是事务的隔离 级别。这道墙越厚表示隔离级别就越高
事务和事务之间的隔离级别有哪些呢?4个级别
1,读未提交:read uncommitted(最低的隔离级别)(没有提交就读到了)
什么是读未提交:
事务A可以读取到事务B未提交的数据
这种隔离级别存在的问题就是:
脏读现象!(Dirty Read),我们称读到了脏数据
这种隔离级别一般都是理论上的,大多数的数据隔离级别都是二档起步
2,读已提交:read committed(提交之后才能读到)
什么是读已提交:
事务A只能读取到事务B提交之后的数据
这种隔离级别解决了什么问题:
解决了脏读的现象
这种隔离级别存在什么问题:
不可重复读取数据,就是在事务开启之后,第一次读到的数据是3 条,当前事务还没有结束,可能第二次再读取的时候,读到的数据是 4条,3不等于4称为不可重复读取
这种隔离级别是比较真实的数据,每一次读到的数据是绝对的真实
Oracle数据库默认的隔离级别是:read committed
3,可重复读:repeatable read(提交之后也读不到,永远读取的都是刚开启事务 时的数据)
什么是可重复读取:
事务A开启之后,不管是多久,每一次在事务A中读取到的数据都 是一致的。即使事务B将数据已经修改,并且提交了,事务A读取到的数据还是没有发生改变,这就是可重复读取
可重复读解决了什么问题
解决了不可重复读取数据的问题
可重复读存在的问题是什么
可能会出现幻影读,每一次读到的数据都是幻想,不够真实
比如:早晨9点开始开启事务,只要事务不结束,到晚上9点,读取的数 据还是那样,读到的是假象,不够真实!
mysql默认的事务隔离级别就是这个!!
4,序列化/串行化:serializable(最高的隔离级别)
这是最高隔离级别,效率最低,解决了所有的问题
这种隔离级别表示事务排队,不能并发
每一次读取到的数据都是最真实的,并且效率是最低的
35.8验证各种隔离级别
查看隔离级别命令:mysql> select @@transaction_isolation;
mysql默认的隔离级别就是repeatable read(可重复读)
被测试的表t_user
mysql> create table t_user(name varchar(255));1,验证:read uncommitted
mysql> set global transaction isolation level read uncommitted;//设置全局隔离级别事务A 事务B
---------------------------------------------------------------------------------------------------------
start transaction;
start transaction;
select * from t_user;//无数据
insert into t_user values('zhangsan');
select * from t_user;//可以发现有zhangsan了
rollback;
select * from t_user;//可以发现又没有数据了
---------------------------------------------------------------------------------------------------------
上面演示的就是read uncommitted隔离级别,当事务B插入一条数据时,没有 commit,事务A就可以读取到事务B未提交的数据
2,验证:read committed
mysql> set global transaction isolation level read committed;//设置全局隔离级别事务A 事务B
---------------------------------------------------------------------------------------------------------
start transaction;
start transaction;
select * from t_user;//无数据
insert into t_user values('zhangsan');
select * from t_user;//无数据
commit;
select * from t_user;//可以发现有zhangsan了
---------------------------------------------------------------------------------------------------------
这个演示就是read committed(读已提交),当事务B插入一条数据时,没有提交, 事务A是读取不到事务B的数据,当事务B提交commit之后事务A才能读取到事 务B的数据,也就是说事务A只能读取到事务B提交之后的数据
3,验证:repeatable read
mysql> set global transaction isolation level repeatable read;//设置全局隔离级别事务A 事务B
---------------------------------------------------------------------------------------------------------
start transaction;
start transaction;
select * from t_user;//无数据
insert into t_user values('lisi');
insert into t_user values('wangwu');
commit;
select * from t_user;//无数据
---------------------------------------------------------------------------------------------------------
上面演示的就是可重复读(repeatable read),可以发现当start transaction之后不 管事务B是插入数据还是删除数据,事务A查询到永远是事务B开始时的状态, 都是假象
4,验证:serializable
mysql> set global transaction isolation level serializable;//设置全局隔离级别事务A 事务B
---------------------------------------------------------------------------------------------------------
start transaction;
start transaction;
select * from t_user;//无数据
insert into t_user values('zhangsan');
select * from t_user;//无结果
commit;
上面的查询自动出来结果
---------------------------------------------------------------------------------------------------------
这个演示的就是序列化(serializable),当事务A开启事务,对t_user进行操作时, 事务B也对这个表进行查询操作,但是没有结果。当事务A提交事务之后,事务B 会自动出来查询结果。这表示事务是排队的,只有当事务A完成对t_user的操作 之后,事务B才能对t_user进行操作