渲染分类
谈渲染管线之前,我想有必要看看渲染的分类。渲染可以按不同的分类依据进行分类:
- 按照渲染时机可以分成实时渲染(除了用于3D游戏还多用于工业仿真方面,注重交互性和实时性)和离线渲染(离线渲染多用于影视、动画、广告片等领域,注重视觉效果)
- 按照实现技术可以分为光栅化、光线追踪(注意这里分类有的还提到了光线投射,但其实光线投射就是实现光追的第一步——生成初始光线)
虎书中第四章就按照实现技术将渲染分成了两类:
- object-order rendering
- image-order rendering
image-order rendering
each pixel is considered in turn, and for each pixel all the objects that influence it are found and the pixel value is computed.依次考虑每个像素,并为每个像素找到它所影响的所有对象,计算像素值。
——《Real-Time Rendering 4th》
101中学习的光线追踪(ray tracing)就是image-order算法。
object-order rendering
这里的对象,其实是指:geometric pimitives(《入门精要》中也提到rendering primitives)暂且就跟其他翻译一样,称primitives为图元吧!通俗来讲,图元可以是点、线、面等等。
each object is considered in turn, and for each object, all the pixels that it influences are found and updated.依次考虑每个对象,找到并更新每个对象所影响的所有像素。
——《Real-Time Rendering 4th》
The process of finding all the pixels in an image that are occupied by a geometric primitve is called rasterization.——寻找被几何图元(对象)影响的所有像素的过程可以被称为光栅化。
——《Real-Time Rendering 4th》
因此object-order rendering又被叫做光栅化渲染(rendering by rasterization)。

我们一直提到的渲染管线/渲染流水线,是从物体对象开始到最后获取图片像素的一系列操作。因此,本篇博客将要介绍的图形渲染管线(rendering graphics pipeline)其实是属于以上两种渲染中的object-order rendering。
渲染流水线
我最初接触到管线(Pipeline)这个概念,是101第7课讲图形管线时候了解到的,当时老师展示了这样的图形管线(下图),了解了管线后让我对之前学习的每部分的内容有了一个大概的框架,“哦!原来一直学习的模型变换、shader、光栅化都是这一整个管线的其中一个小部分!”
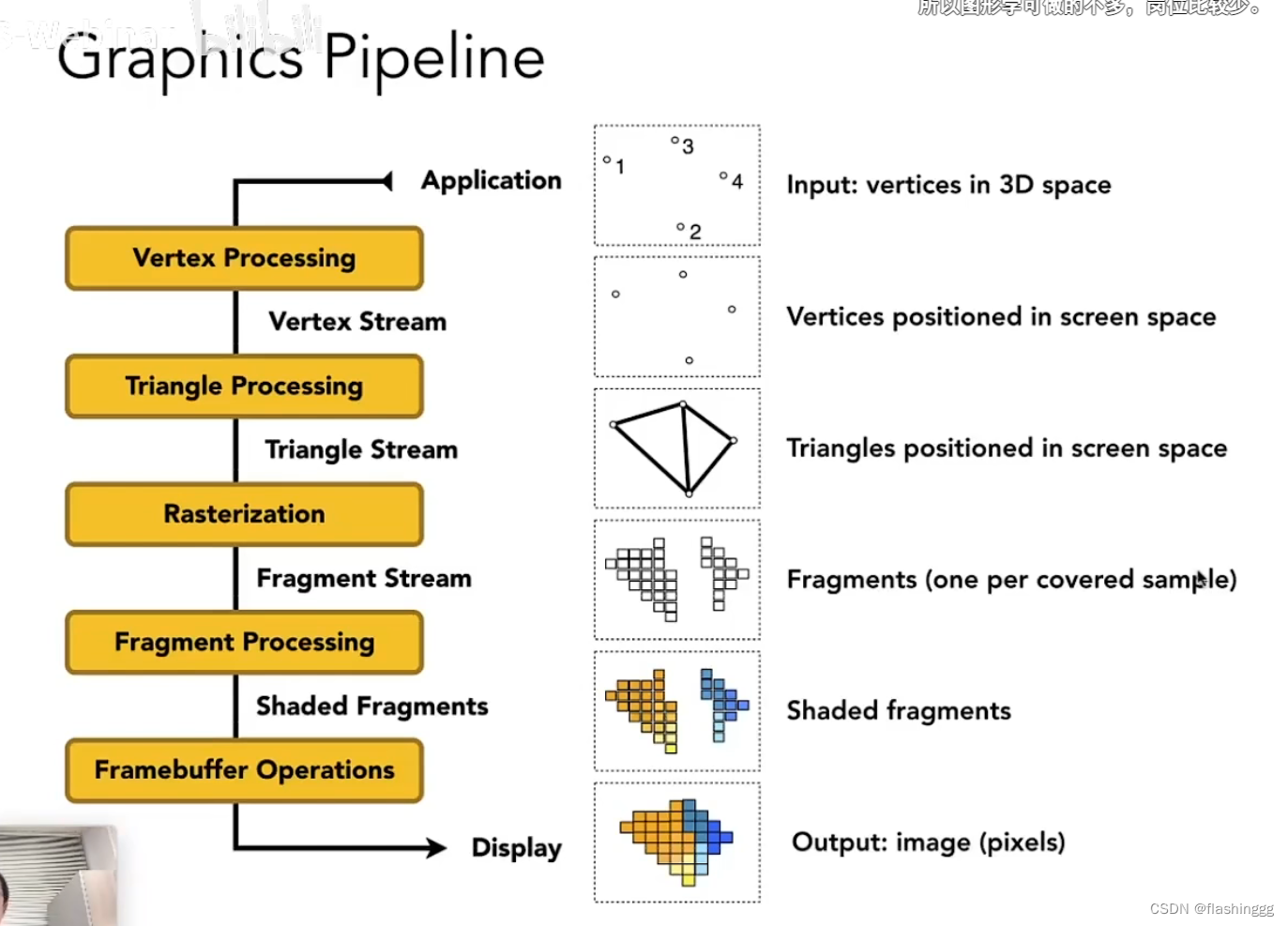
What——从3D场景出发渲染一张2D图像
渲染管线的主要功能
渲染管线的主要功能,是决定在给定虚拟相机(virtual camera)、3D场景物体(three-dimensional objects)、光源(light sources),以及纹理等诸多条件的情况下,生成或渲染一副2D图像的过程,渲染管线是实现实时渲染(real-time rendering)的核心组件。
这个过程是由CPU和GPU共同完成的。以下简单罗列了一下从最初的信息(顶点数据、纹理等信息)出发通过三个阶段最终输出结果的整个渲染输入输出过程。
注意:我画这个图的时候是依据RTR3rd三阶段走的,因此没有把RTR4中像素处理阶段考虑进去:
要点1:渲染管线的划分并不唯一
进行渲染管线的学习时有一点值得注意:渲染管线并非严格要求必须按某种方法划分,不同的教材会有不同的划分方法。除了上面列举的101中老师的划分方法,虎书(《fundamentals of computer graphics 5th》,文末有附书PDF链接)第九章The Graphics Pipeline讨论管线时是根据以下四阶段划分的:
- 顶点处理 Vertex Processing
- 光栅化 Rasterization
- 片元处理Fragment Processing
- 混合阶段 Blending
(下图是虎书5th中的插图)

而《Real-Time Rendering 4rd》中将整个渲染流程又分成了这四个阶段(比第三版多了像素处理阶段),这也是本篇博客讲述依据的划分方法:
- 应用阶段 Application Stage
- 几何阶段 Geometry Stage
- 光栅化阶段 Rasterizer Stage
- 像素处理阶段 Pixel Processing
(下图是RTR4书中的插图)
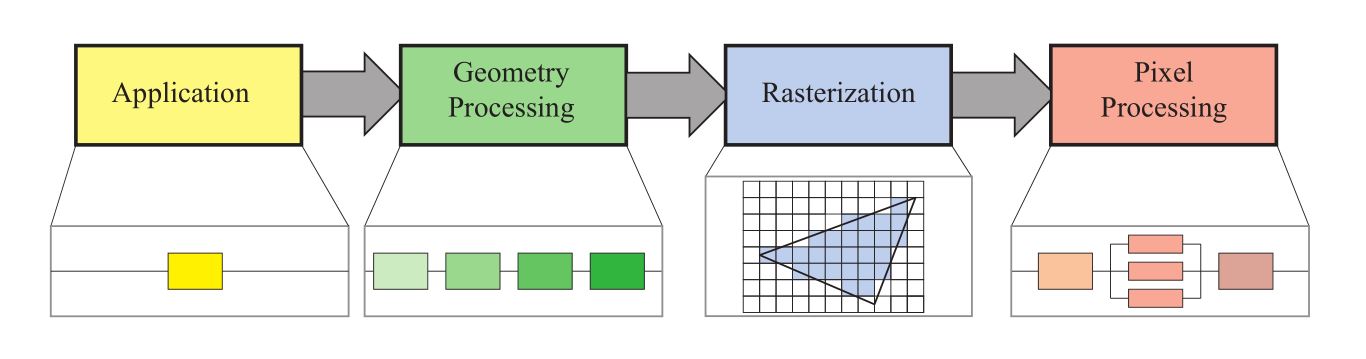
虽然有不同的划分方法,但流程都大差不离。
要点2:四个阶段只是概念性阶段
这四个阶段只是概念性的阶段,每个阶段又可以有自己的管线,比如后续的GPU又有自己的一套GPU渲染管线。
要点3:渲染管线和渲染路径的关系
我不是故意要在这提一嘴渲染路径的。
其实是我在学习应用阶段-渲染设置-渲染路径时,搜寻延迟渲染和正向渲染相关信息看到了:
(原文链接:常见渲染管线整理与总结 - 简书 (jianshu.com))
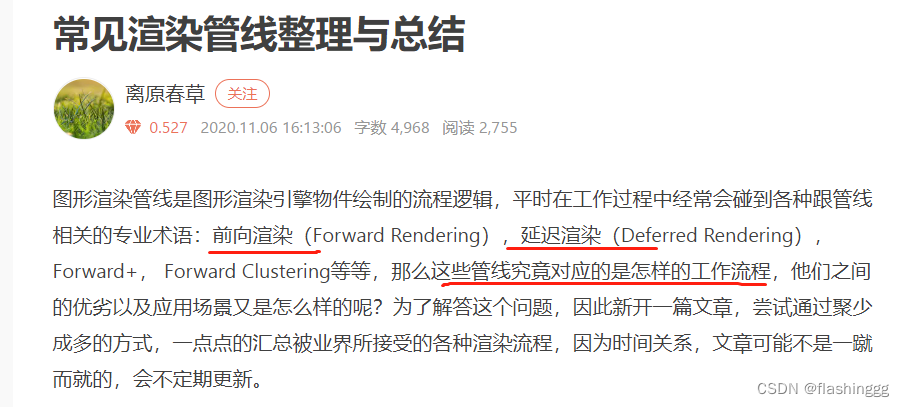
看到的当下想法:“好家伙!渲染管线怎么这么多?”
写到这里,突然发现要点3和要点2想要强调的其实是一样的——管线是一种泛指,并不是只有“四个阶段”才能叫做管线,个人认为任何一套流程走下来都可以叫做管线。之所以每次搜索“渲染管线”都会出来“四个阶段”,可能是默认大部分搜索“渲染管线”的人想找的都是“四个阶段”这个大的、概念性的管线吧。
上图里出现的前向渲染、延迟渲染、包括后续的分块延迟渲染、分块正向渲染等等,都是属于“四个阶段”概念性管线的一个环节——渲染路径(Rendering Path),即渲染场景中光照的方式。当然,这么多种渲染目标使用光照的流程自然可以称为xx管线。
要点4:渲染速度怎么表示
最慢的流水线阶段决定整体的绘制速度,即图像更新的速度(渲染速度),这个速度其实就是我们常说的FPS——每秒传输的帧数(Frames per second),或者叫每秒渲染的图像数量。
除了FPS另一种表示方法——赫兹(Hz),渲染图像所需时间,即更新频率。
Why——流水线提升了效率
现在完成渲染工作都是以渲染管线绘制的,但在过去绘制工作都是由CPU自己完成的:由CPU一次一次访问顶点数据进行绘制,这样效率非常低。面对3D游戏成千上万个面更是如此,如果没有任何手段去加快渲染速度,每个图元都逐个计算,速度可想而知有多么的慢!
理解流水线概念
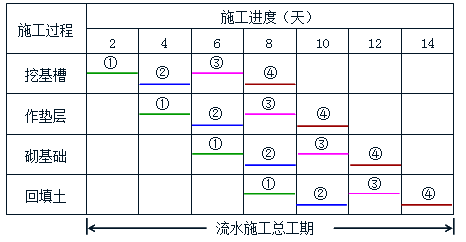
类似施工流水线(如下图的施工进度图),相互独立的工序是可以同时进行的(例如下图的工序①②③④),这样就大大缩短了施工总时间。
(没想到有一天施工进度可以拿出来举例子,本土木人落泪了)
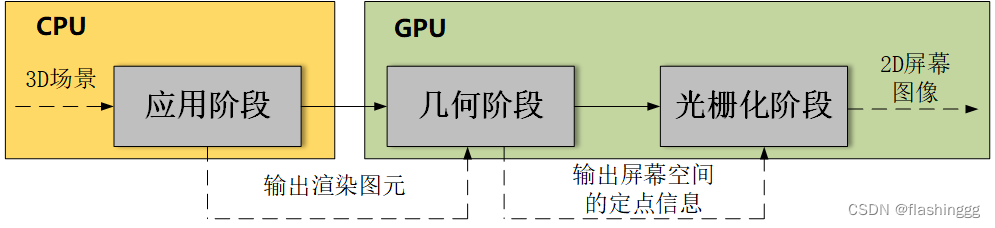
CPU和GPU间的流水线
理解了流水线概念后,能对整个渲染流程有更深的体会。
上面提到了,渲染流程是CPU和GPU共同进行的。进行计算时,应用阶段的最后CPU会发出指令,告诉GPU——“可以开始执行啦!”。这个指令的发出也是流水线进行的:CPU会发出一个个渲染命令指定渲染哪个图元,这些命令被储存在命令缓冲区中,GPU再依次取出命令,调用一个个计算单元对CPU传递过来的数据进行处理,最终输出成一个2D图像。
至于CPU到底给了GPU哪些东西,在后面的应用阶段会具体讲到。
How——举例说明
用RTR4书中第二章开头展示的例子例子说说渲染是如何进行的:
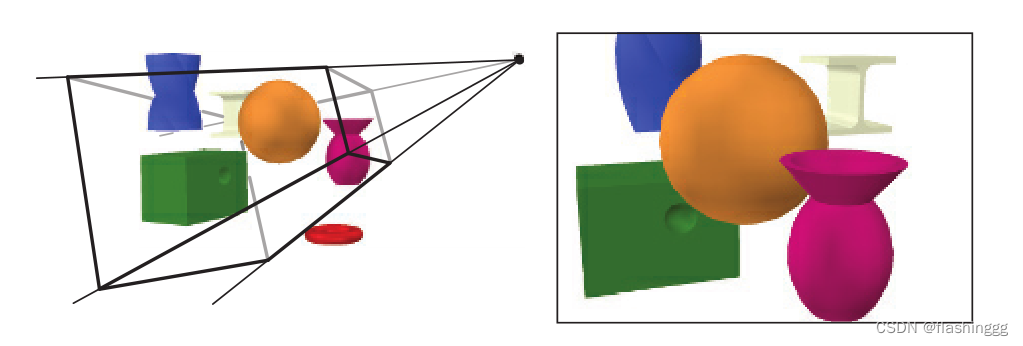
左图展示了渲染前准备的东西:
- 虚拟相机——渲染时仅计算view volume-视锥(furstum)中的物体,案例中采用的是透视投影
- 物体信息——场景中物体的位置和大小信息
- 渲染参数——材质(material properties)、光源(light sources)、纹理(textures)和着色方程(sahding equations)等决定物体外观的参数
右图展示了屏幕图像呈现的图片,观察可以发现:
- 有物体没有被渲染——左图的红色物体不在视锥内,因此被舍弃了
- 有物体被裁剪了——左图的蓝色物体部分在视锥内,可以看到它在右图中被剪切了一部分
前期知识告一段落, 接下来将依据RTR4中的四个阶段,具体讲讲几个阶段到底在执行些什么操作。
1 应用阶段
应用阶段由CPU主要负责,因此应用阶段完全由开发人员掌控。CPU将决定传递给GPU什么数据,以及这些数据的渲染状态,并可以对这些数据做剔除处理。接下来我主要借鉴《Unity Shader 入门精要》书中的内容,对应用阶段CPU干的工作做一个介绍。
1.1 将基本场景数据加载到显存中
硬盘 -> 系统内存 -> 显存
所有渲染所需的数据都需要从硬盘(Hard Disk Drive, HDD)中加载到系统内存(Random Access Memory, RAM)中,接着3D场景中物体的网格、纹理等数据又从系统内存加载到显存(Video Random Access Memory, VRAM)中。
这里涉及到系统内存和显存的概念。为什么加载到显存?首先大多数显卡没有系统内存的直接访问权限,其次显卡访问显存的速度更快。关于显存和内存更加具体的区别,可以看看这篇的高赞回答:显存与内存的区别在哪里? - 知乎 (zhihu.com)
那么到底有哪些数据呢?
1.1.1 场景物体数据
- 物体变换数据:位置、旋转、缩放等
- 物体网格数据:顶点位置、顶点颜色、法线方向、UV贴图等
1.1.2 光源及阴影数据
- 光源类型:方向光?点光源?聚光?...
- 光源的位置、方向等参数
- 阴影:是否绘制阴影?阴影贴图
1.1.3 摄像机数据
- 摆放位置、朝向
- 正交pr透视投影
- 视口长宽比
1.2 加速和剔除算法
其实《入门精要》里是没有提及这部分内容的,这部分是参考技术美术百人计划-渲染流水线
In real-time rendering, we have at least four performance goals: more frames per second, higher resolution and sampling rates, more realistic materials and lighting, and increased geometrical complexity. 实时渲染中我们至少有四个性能目标:每秒更多帧数、更高的分辨率和采样率、更逼真的材质和照明、更高的几何复杂度。
——《Real-Time Rendering 4th》
RTR4中介绍了一系列加速图形渲染的算法,特别是面对大量几何渲染的加速算法。
- 常用的空间数据结构(Spatial Data Structures):BVH、BSP、四叉树、KD-Tree、八叉树等;
记得101的作业6就是实现BVH算法:GAMES101作业6-BVH完成全过程
- 各种裁剪技术(Culling Techniques):背面裁剪、视锥裁剪、遮挡剔除、入口裁剪、细节裁剪等;
- 各种层次细节技术(LOD, Level of Detail),秉持着“好钢用在刀刃上”的理念——为近处分配高模,远处分配低模,节省资源消耗又不失真!是不是想到了纹理的Mipmap!!!!没错LOD和Mipmap一个是模型金字塔一个是纹理金字塔
- 渲染大型场景(Rendering Large Scenes)
这里不展开描述,可以去看RTR书或者直接搜索“游戏中的加速渲染算法”都可以直接了解到。
1.3 设置渲染状态
这一步骤定义了场景中的网格是如何被渲染的,以“指导”GPU进行渲染,通常会涉及到:
1.3.1 渲染设置
- 设置使用的顶点着色器(Vertex Shader)/片元着色器(Fragment Shader)
- 合批方式、动态批处理等设置
1.3.2 渲染顺序
可以有很多种方式,例如根据相机、图层、材质等等
可以看看这篇文章:Unity渲染顺序总结 - 简书 (jianshu.com)
1.3.3 渲染目标
参考
[译文]Unreal Engine 4 渲染目标(Render Target)教程 之 使用渲染目标绘制(上)
渲染概念:3.RenderTarget-渲染目标 - 知乎 (zhihu.com)
渲染目标(Render Target)就是一种可以在运行时写入的纹理。可以把他看作一个缓冲区,但并不是帧缓冲区或后缓冲区。它允许将2D场景渲染到中间储存缓冲区或者渲染目标纹理(Render Target Texture, RTT),方便之后通过着色器操纵这个RTT,以便最终在屏幕显示图像前将其他效果加上去。从引擎角度讲,渲染目标会储存颜色、发现以及AO等信息。
通过搜索我发现,这部分需要在使用引擎的时候再去了解,因此这里仅提一下渲染目标的概念。
1.3.4 渲染路径(光照算法)
参考
渲染路径(Rendering Path)与常见渲染技术 - 知乎 (zhihu.com)
还是那句话,如果你接触过引擎,那在渲染时肯定需要选择Rendering Path参数。 这个参数其实就是选定光照算法,游戏的光照算法从最开始的前向渲染(Forward Render),到延迟渲染(Deferred Render),再到后来发展到了Forward+,Forward Clustering等等。
- 前向渲染
是基于实时计算的,先计算光照再裁剪。也是最普遍用到的渲染路径。这么着的好处是可以对场景中的每个物体使用不同的着色模型和技术,还适合渲染半透明物体,缺点——无效渲染太多,难以支持过多光源。
- 延迟渲染
是基于缓存的,先裁剪再计算光照。它的优点:可以支持大量的实时光照,因此大部分的3A游戏都是延迟渲染了。同时由于只渲染可见像素,不会进行无效计算。缺点——要求使用更少的Shader种类,且不支持半透明物体渲染。从浅谈《原神》中的图形渲染技术中了解到了原神渲染灯光是采用延迟渲染+集群,用集群思想去弥补延迟渲染的不足,具体的话可以看看这篇博客。(除了集群延迟渲染还有其他的内容,讲得非常有趣且通俗易懂。)
渲染路径内容点到为止,后面会新开一个博客讲讲渲染路径里面的门道。
1.4 调用Draw Call
终于到了最后一步!CPU将会调用一个渲染命令来告诉GPU——无序列表“我已经给准备好了数据,你可以按照我的设置开始渲染啦!”
这个渲染命令就是Draw Call,例如
- OpenGL中的glDrawElements命令
- DirectX中的DrawIndexedPrimitive命令
它是CPU调用图像编程的接口,由CPU发起,GPU接收。
上面讲CPU和GPU间的流水线时讲到了:Draw Call的发出是流水线进行的:CPU会发出一个个渲染命令指定渲染哪个图元,这些命令被储存在命令缓冲区中,GPU再依次取出命令,调用一个个计算单元对CPU传递过来的数据进行处理,最终输出成一个2D图像。
1.4.1 Draw Call多了影响帧率
为什么Draw Call多了会影响帧率?
GPU具有超强的渲染能力,渲染速度往往会快于CPU提交命令也就是Draw Call的速度,命令缓冲区里的Draw Call很快就被GPU处理完了,而CPU还没准备好下一个Draw Call呢!GPU就闲下来了没事儿干,此时CPU就会把大量时间花费在反复多次提交Draw Call上——造成CPU过载。
一个很形象的说法是,CPU无法喂饱GPU
谈到这儿了你或许已经意识到了:Draw Call影响帧率造成性能问题的元凶是CPU而不是GPU!
1.4.2 合批——优化Draw Call
这一部分参考了 合批是什么?为什么可以减少Drawcall?有什么合批方法?
了解了Draw Call造成性能问题,为了发挥硬件的最大性能,下一步是想办法减少这些问题。优化Draw Call是一个老生常谈的问题,减少Draw Call最常见的是批处理(Draw Call Batching),也叫做合批,即每次提交尽可能多的物体。合批的首要条件是提交绘制的物体一定要是同一材质,合批也有不同的方式:
- 离线合批
美术师们提前把相关资源合批处理,例如静态模型和场景物件。
- 静态合批 Static Batching
引擎中可以给Mesh标记static,直接将标记为static的自动合批,以储存更多的网格数据为代价换取性能提升,这个方式占用的内存会非常大。
- 动态合批 Dynamic Batching
每一帧都合并一次数据,是实时的,但动态合批只能处理一些面数低的、小的模型,同时如果物体材质被改变也无法参与动态合批。
- GPU渲染同一网格多次 GPU Instancing
也就是GPU一次性渲染同一个网格多次,每次材质相同但缩放、位置、颜色等属性不同。
参考
猴子也能看懂的渲染管线(Render Pipeline) - 知乎 (zhihu.com)
《Real-Time Rendering 3rd》提炼总结-毛星云
《fundamentals of computer graphics 5th》PDF-提取码:b0u5
《Unity Shader入门精要》-冯乐乐
另外分享一个能找到大部分英文书籍的网站:Library | Compilers: Principles, Techniques, and Tools