【深度学习前沿应用】图像分类Fine-Tuning

作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
前言
1. 什么是预训练-微调模式?
在计算机视觉领域,预训练-微调模式已经沿用了多年,即在大规模图片数据集预训练模型参数,然后将训练好的参数在新的小数据集任务上进行微调,从而产生泛化性能更好的模型。
2. 什么是ResNet?
ResNet为常用的预训练模型之一,其核心操作为卷积与残差连接。卷积层为3×3的滤波器,并遵循两个简单的设计规则:①对于相同的输出特征图尺寸,每层具有相同数量的滤波器;②如果特征图尺寸减半,则滤波器数量加倍,以保持每层的时间复杂度。直接用步长为2的卷积层进行下采样,网络以全局平均池化层和伴随softmax的1000维全连接层结束,其中,卷积层数为34,因此也称为ResNet34(如下图1所示)。
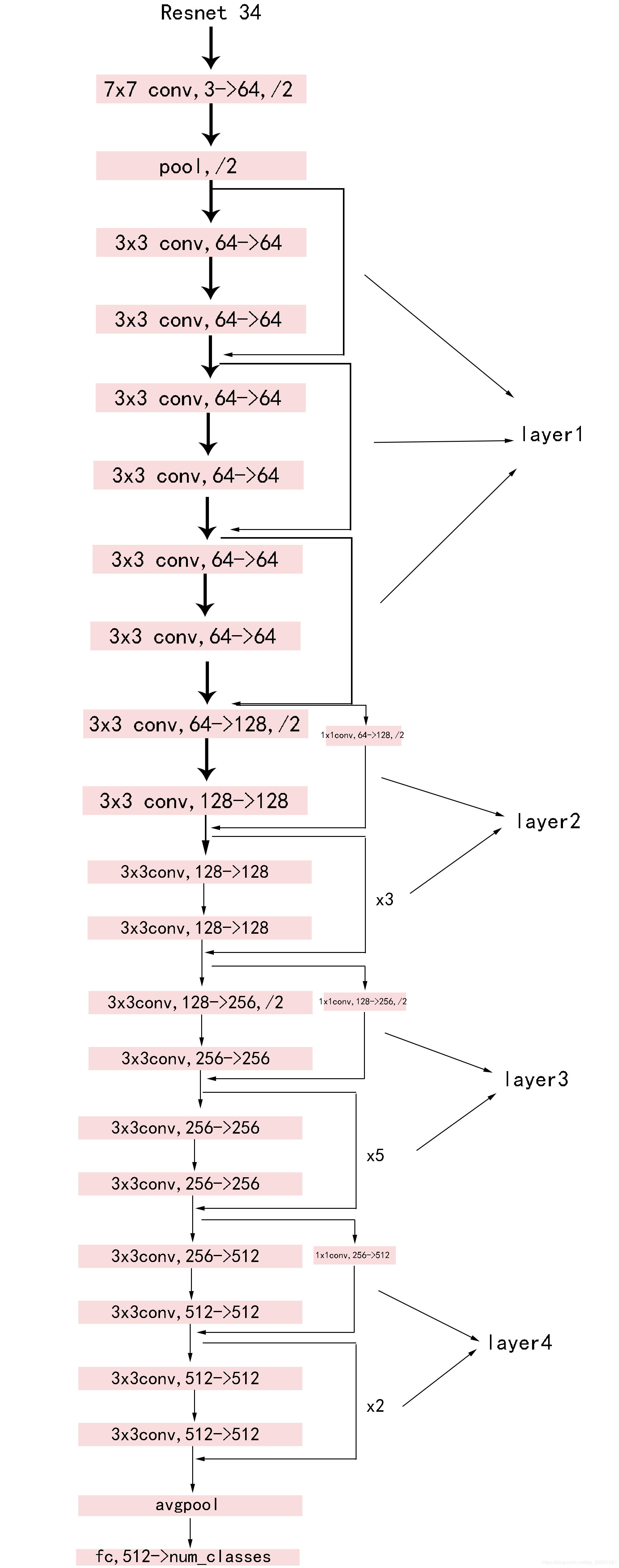
本小节将使用ResNet34预训练-微调框架,实现猫脸12分类。对于给定的猫脸,判断其所属类型。
一、数据加载及预处理
本实验数据集来源于网络开源数据集(https://aistudio.baidu.com/aistudio/datasetdetail/10954),该数据集中包含12类猫图片,总计数据量为2160,部分图片展示如下图1所示。

(一)、数据加载及预处理
首先将该数据集挂载到当前项目中,然后读取数据文件,将数据按照8:2划分为训练集与验证集
- 导入相关包
import os
import time
import os.path as osp
import zipfile
import numpy as np
import paddle
import paddle.nn as nn
import pandas as pd
import paddle.nn.functional as F
from PIL import Image
from paddle.io import Dataset, DataLoader
from paddle.optimizer import Adam
from paddle.vision import Compose, ToTensor, Resize
from paddle.vision.models import resnet34
from paddle.metric import Accuracy
from sklearn.model_selection import StratifiedShuffleSplit
- 将train划分为训练集和验证集
info = pd.read_csv(osp.join('./data', 'train_list.txt'), sep='\t', header=None)
images, labels = info.iloc[:, 0], info.iloc[:, 1]
split = StratifiedShuffleSplit(test_size=0.2)
train_idx, valid_idx = next(split.split(images, labels))
info_tr = info.iloc[train_idx, :]
info_va = info.iloc[valid_idx, :]
info_tr.to_csv('data/train.csv', header=False, index=False)
info_va.to_csv('data/valid.csv', header=False, index=False)
(二)、数据集封装
class CatDataset(Dataset):
train_file = 'cat_12_train.zip'
test_file = 'cat_12_test.zip'
train_label = 'train_list.txt'
def __init__(self, root, mode, transform=None):
super(CatDataset, self).__init__()
self.root = root
self.mode = mode
self.transform = transform
if not osp.isfile(osp.join(root, self.train_file)) or \
not osp.isfile(osp.join(root, self.train_label)) or \
not osp.isfile(osp.join(root, self.test_file)):
raise ValueError('wrong data path')
if not osp.isdir(osp.join(self.root, 'cat_12_train')):
with zipfile.ZipFile(osp.join(root, self.train_file)) as f:
f.extractall(root)
with zipfile.ZipFile(osp.join(root, self.test_file)) as f:
f.extractall(root)
if mode == 'train':
info = pd.read_csv(osp.join(root, 'train_list.txt'), sep='\t', header=None)
self.images = info.iloc[:, 0].to_list()
self.labels = paddle.to_tensor(
info.iloc[:, 1].to_list()
)
elif mode == 'train_':
info = pd.read_csv(osp.join(root, 'train.csv'), header=None)
self.images = info.iloc[:, 0].to_list()
self.labels = paddle.to_tensor(
info.iloc[:, 1].to_list()
)
pass
elif mode == 'valid_':
info = pd.read_csv(osp.join(root, 'valid.csv'), header=None)
self.images = info.iloc[:, 0].to_list()
self.labels = paddle.to_tensor(
info.iloc[:, 1].to_list()
)
else:
images = os.listdir(os.path.join(root, 'cat_12_test'))
self.images = ['cat_12_test/'+image for image in images]
self.labels = None
def __getitem__(self, idx):
image = Image.open(osp.join(self.root, self.images[idx]))
if image.mode != 'RGB':
image = image.convert('RGB')
if self.transform is not None:
image = self.transform(image)
if self.mode == 'test':
return image,
else:
label = self.labels[idx]
return image, label
def __len__(self):
return len(self.images)
(三)、样本分类与统计
paddle.set_device('gpu' if paddle.is_compiled_with_cuda() else 'cpu')
transform = Compose([
Resize([224, 224]),
ToTensor()
])
train_ds = CatDataset('./data', 'train_', transform)
valid_ds = CatDataset('./data', 'valid_', transform)
train_dl = DataLoader(train_ds, batch_size=64, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size=64, shuffle=False)
print('训练集样本数:',train_ds.__len__())
print('验证集样本数:',valid_ds.__len__())
二、预训练模型加载
paddle,vision是飞桨在视觉领域的高层API,内部封装了常用的数据集以及常用预测训练模型,如LeNet、VGG系列、ResNet系列及MobileNet系列等。本实验使用resnet34为例,演示如何进行图像分类的微调。
准备好数据集之后,加载预训练模型,调用net=resnet34(pretrained=True),设置参数pretrained为True,便可使用预训练好的参数,否则,需要从头开始训练参数(首次加载预训练参数时需要从相关专业网络中下载):
加载预训练模型,并设置类别数目为12(猫的分类)
net = resnet34(pretrained=True, num_classes=12)
三、模型微调
加载好预训练的模型之后,定义模型的优化器、评价指标等,输入领域数据,执行微调:
(一)、定义优化器
optimizer = Adam(
parameters=net.parameters(),
learning_rate=1e-5
)
(二)、定义损失函数
loss_fn = nn.CrossEntropyLoss()
(三)、定义准确率评价指标
metric_fn = Accuracy()
(四)、微调20轮
for epoch in range(20):
t0 = time.time()
net.train()
for data, label in train_dl:
logit = net(data)
loss = loss_fn(logit, label.astype('int64'))
optimizer.clear_grad()
loss.backward()
optimizer.step()
# 验证
net.eval()
loss_tr = 0.
for data, label in train_dl:
logit = net(data)
label = label.astype('int64')
loss_tr += loss_fn(logit, label).cpu().numpy()[0]
loss_tr /= len(train_dl)
loss_va = 0.
for data, label in valid_dl:
label = label.astype('int64')
logit = net(data)
loss_va += loss_fn(logit, label).cpu().numpy()[0]
metric_fn.update(
metric_fn.compute(logit, label)
)
loss_va /= len(valid_dl)
acc_va = metric_fn.accumulate()
metric_fn.reset()
t = time.time() - t0
print('[Epoch {:3d} {:.2f}s] train loss({:.4f}); valid loss({:.4f}), acc({:.2f})'
.format(epoch, t, loss_tr, loss_va, acc_va))
训练过程部分输出如下图2所示:

四、模型预测
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
def show_image(file_name):
img = mpimg.imread('data/'+file_name)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.show()
test_ds = CatDataset('./data', mode='test', transform=transform)
test_dl = DataLoader(test_ds, batch_size=32, shuffle=False)
test_pred = []
with paddle.no_grad():
for data, in test_dl:
logit = net(data)
pred = paddle.argmax(
F.softmax(logit, axis=-1),
axis=-1
)
test_pred.append(pred.cpu().numpy())
test_pred = np.concatenate(test_pred, axis=0)
for image, pred in zip(test_ds.images, test_pred.astype(np.int)):
img = mpimg.imread('data/'+image)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.show()
print('图片路径:%s, 图片预测类型:%d\n' % (image.split('/')[1], pred))
预测结果部分输出如下图3、4、5、6所示




总结
本系列文章内容为根据清华社出版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~
