实验一
首先写一下下面这个.py
caffe_root = './caffe/' # this file should be run from {caffe_root}/examples (otherwise change this line)
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
caffe.set_device(0)
caffe.set_mode_gpu()
import numpy as np
from pylab import *
#matplotlib inline
import tempfile
# Helper function for deprocessing preprocessed images, e.g., for display.
def deprocess_net_image(image):
image = image.copy() # don't modify destructively
image = image[::-1] # BGR -> RGB
image = image.transpose(1, 2, 0) # CHW -> HWC
image += [123, 117, 104] # (approximately) undo mean subtraction
# clamp values in [0, 255]
image[image < 0], image[image > 255] = 0, 255
# round and cast from float32 to uint8
image = np.round(image)
image = np.require(image, dtype=np.uint8)
return image
接着运行下面三条命令下载数据。
sudo ./data/ilsvrc12/get_ilsvrc_aux.sh
sudo ./scripts/download_model_binary.py models/bvlc_reference_caffene
sudo python ./examples/finetune_flickr_style/assemble_data.py \
--workers=-1 --seed=1701 \
--images=2000 --label=5注意,我这里的话,运行第三条命令出错。
我们需要把assemble_data.py改成如下
#!/usr/bin/env python3
"""
Form a subset of the Flickr Style data, download images to dirname, and write
Caffe ImagesDataLayer training file.
"""
import os
import urllib
import hashlib
import argparse
import numpy as np
import pandas as pd
from skimage import io
import multiprocessing
import socket
# Flickr returns a special image if the request is unavailable.
MISSING_IMAGE_SHA1 = '6a92790b1c2a301c6e7ddef645dca1f53ea97ac2'
example_dirname = os.path.abspath(os.path.dirname(__file__))
caffe_dirname = os.path.abspath(os.path.join(example_dirname, '../..'))
training_dirname = os.path.join(caffe_dirname, 'data/flickr_style')
def download_image(args_tuple):
"For use with multiprocessing map. Returns filename on fail."
try:
url, filename = args_tuple
if not os.path.exists(filename):
urllib.urlretrieve(url, filename)
with open(filename) as f:
assert hashlib.sha1(f.read()).hexdigest() != MISSING_IMAGE_SHA1
test_read_image = io.imread(filename)
return True
except KeyboardInterrupt:
raise Exception() # multiprocessing doesn't catch keyboard exceptions
except:
return False
def mydownload_image(args_tuple):
"For use with multiprocessing map. Returns filename on fail."
try:
url, filename = args_tuple
if not os.path.exists(filename):
urllib.urlretrieve(url, filename)
with open(filename) as f:
assert hashlib.sha1(f.read()).hexdigest() != MISSING_IMAGE_SHA1
test_read_image = io.imread(filename)
return True
except KeyboardInterrupt:
raise Exception() # multiprocessing doesn't catch keyboard exceptions
except:
return False
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='Download a subset of Flickr Style to a directory')
parser.add_argument(
'-s', '--seed', type=int, default=0,
help="random seed")
parser.add_argument(
'-i', '--images', type=int, default=-1,
help="number of images to use (-1 for all [default])",
)
parser.add_argument(
'-w', '--workers', type=int, default=-1,
help="num workers used to download images. -x uses (all - x) cores [-1 default]."
)
parser.add_argument(
'-l', '--labels', type=int, default=0,
help="if set to a positive value, only sample images from the first number of labels."
)
args = parser.parse_args()
np.random.seed(args.seed)
# Read data, shuffle order, and subsample.
csv_filename = os.path.join(example_dirname, 'flickr_style.csv.gz')
df = pd.read_csv(csv_filename, index_col=0, compression='gzip')
df = df.iloc[np.random.permutation(df.shape[0])]
if args.labels > 0:
df = df.loc[df['label'] < args.labels]
if args.images > 0 and args.images < df.shape[0]:
df = df.iloc[:args.images]
# Make directory for images and get local filenames.
if training_dirname is None:
training_dirname = os.path.join(caffe_dirname, 'data/flickr_style')
images_dirname = os.path.join(training_dirname, 'images')
if not os.path.exists(images_dirname):
os.makedirs(images_dirname)
df['image_filename'] = [
os.path.join(images_dirname, _.split('/')[-1]) for _ in df['image_url']
]
# Download images.
num_workers = args.workers
if num_workers <= 0:
num_workers = multiprocessing.cpu_count() + num_workers
print('Downloading {} images with {} workers...'.format(
df.shape[0], num_workers))
#pool = multiprocessing.Pool(processes=num_workers)
map_args = zip(df['image_url'], df['image_filename'])
#results = pool.map(download_image, map_args)
socket.setdefaulttimeout(6)
results = []
for item in map_args:
value = mydownload_image(item)
results.append(value)
if value == False:
print 'Download False'
else:
print 'Download Success'
# Only keep rows with valid images, and write out training file lists.
print len(results)
df = df[results]
for split in ['train', 'test']:
split_df = df[df['_split'] == split]
filename = os.path.join(training_dirname, '{}.txt'.format(split))
split_df[['image_filename', 'label']].to_csv(
filename, sep=' ', header=None, index=None)
print('Writing train/val for {} successfully downloaded images.'.format(
df.shape[0])) 这些要下好久的- -。。。
full_dataset = False
if full_dataset:
NUM_STYLE_IMAGES = NUM_STYLE_LABELS = -1
else:
NUM_STYLE_IMAGES = 2000
NUM_STYLE_LABELS = 5
import os
weights = os.path.join(caffe_root, 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel')
assert os.path.exists(weights)
# Load ImageNet labels to imagenet_labels
imagenet_label_file = caffe_root + 'data/ilsvrc12/synset_words.txt'
imagenet_labels = list(np.loadtxt(imagenet_label_file, str, delimiter='\t'))
assert len(imagenet_labels) == 1000
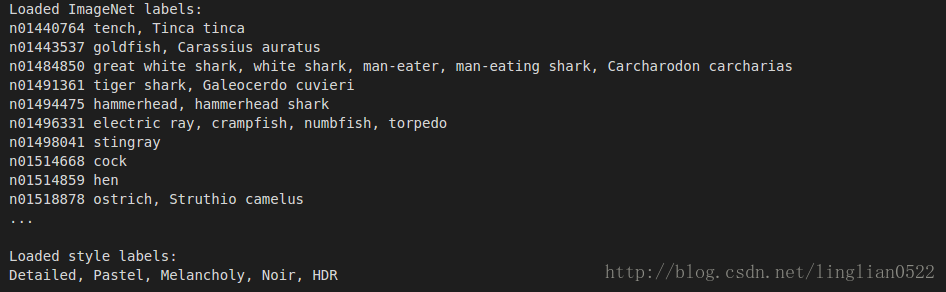
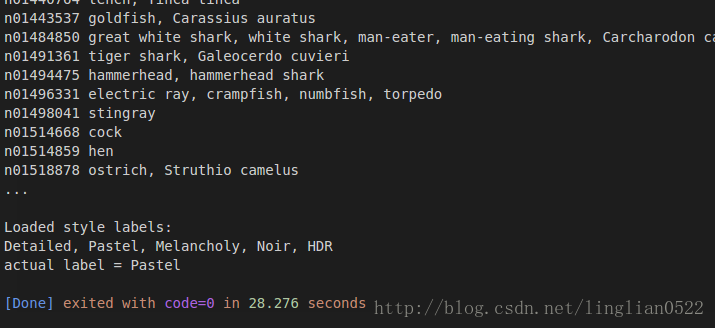
print 'Loaded ImageNet labels:\n', '\n'.join(imagenet_labels[:10] + ['...'])
# Load style labels to style_labels
style_label_file = caffe_root + 'examples/finetune_flickr_style/style_names.txt'
style_labels = list(np.loadtxt(style_label_file, str, delimiter='\n'))
if NUM_STYLE_LABELS > 0:
style_labels = style_labels[:NUM_STYLE_LABELS]
print '\nLoaded style labels:\n', ', '.join(style_labels)
接着运行下面的代码
caffe_root = './caffe/' # this file should be run from {caffe_root}/examples (otherwise change this line)
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
caffe.set_device(0)
caffe.set_mode_gpu()
import numpy as np
from pylab import *
#matplotlib inline
import tempfile
# Helper function for deprocessing preprocessed images, e.g., for display.
def deprocess_net_image(image):
image = image.copy() # don't modify destructively
image = image[::-1] # BGR -> RGB
image = image.transpose(1, 2, 0) # CHW -> HWC
image += [123, 117, 104] # (approximately) undo mean subtraction
# clamp values in [0, 255]
image[image < 0], image[image > 255] = 0, 255
# round and cast from float32 to uint8
image = np.round(image)
image = np.require(image, dtype=np.uint8)
return image
full_dataset = False
if full_dataset:
NUM_STYLE_IMAGES = NUM_STYLE_LABELS = -1
else:
NUM_STYLE_IMAGES = 2000
NUM_STYLE_LABELS = 5
import os
weights = os.path.join(caffe_root, 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel')
assert os.path.exists(weights)
# Load ImageNet labels to imagenet_labels
imagenet_label_file = caffe_root + 'data/ilsvrc12/synset_words.txt'
imagenet_labels = list(np.loadtxt(imagenet_label_file, str, delimiter='\t'))
assert len(imagenet_labels) == 1000
print 'Loaded ImageNet labels:\n', '\n'.join(imagenet_labels[:10] + ['...'])
# Load style labels to style_labels
style_label_file = caffe_root + 'examples/finetune_flickr_style/style_names.txt'
style_labels = list(np.loadtxt(style_label_file, str, delimiter='\n'))
if NUM_STYLE_LABELS > 0:
style_labels = style_labels[:NUM_STYLE_LABELS]
print '\nLoaded style labels:\n', ', '.join(style_labels)
from caffe import layers as L
from caffe import params as P
weight_param = dict(lr_mult=1, decay_mult=1)
bias_param = dict(lr_mult=2, decay_mult=0)
learned_param = [weight_param, bias_param]
frozen_param = [dict(lr_mult=0)] * 2
def conv_relu(bottom, ks, nout, stride=1, pad=0, group=1,
param=learned_param,
weight_filler=dict(type='gaussian', std=0.01),
bias_filler=dict(type='constant', value=0.1)):
conv = L.Convolution(bottom, kernel_size=ks, stride=stride,
num_output=nout, pad=pad, group=group,
param=param, weight_filler=weight_filler,
bias_filler=bias_filler)
return conv, L.ReLU(conv, in_place=True)
def fc_relu(bottom, nout, param=learned_param,
weight_filler=dict(type='gaussian', std=0.005),
bias_filler=dict(type='constant', value=0.1)):
fc = L.InnerProduct(bottom, num_output=nout, param=param,
weight_filler=weight_filler,
bias_filler=bias_filler)
return fc, L.ReLU(fc, in_place=True)
def max_pool(bottom, ks, stride=1):
return L.Pooling(bottom, pool=P.Pooling.MAX, kernel_size=ks, stride=stride)
def caffenet(data, label=None, train=True, num_classes=1000,
classifier_name='fc8', learn_all=False):
"""Returns a NetSpec specifying CaffeNet, following the original proto text
specification (./models/bvlc_reference_caffenet/train_val.prototxt)."""
n = caffe.NetSpec()
n.data = data
param = learned_param if learn_all else frozen_param
n.conv1, n.relu1 = conv_relu(n.data, 11, 96, stride=4, param=param)
n.pool1 = max_pool(n.relu1, 3, stride=2)
n.norm1 = L.LRN(n.pool1, local_size=5, alpha=1e-4, beta=0.75)
n.conv2, n.relu2 = conv_relu(n.norm1, 5, 256, pad=2, group=2, param=param)
n.pool2 = max_pool(n.relu2, 3, stride=2)
n.norm2 = L.LRN(n.pool2, local_size=5, alpha=1e-4, beta=0.75)
n.conv3, n.relu3 = conv_relu(n.norm2, 3, 384, pad=1, param=param)
n.conv4, n.relu4 = conv_relu(n.relu3, 3, 384, pad=1, group=2, param=param)
n.conv5, n.relu5 = conv_relu(n.relu4, 3, 256, pad=1, group=2, param=param)
n.pool5 = max_pool(n.relu5, 3, stride=2)
n.fc6, n.relu6 = fc_relu(n.pool5, 4096, param=param)
if train:
n.drop6 = fc7input = L.Dropout(n.relu6, in_place=True)
else:
fc7input = n.relu6
n.fc7, n.relu7 = fc_relu(fc7input, 4096, param=param)
if train:
n.drop7 = fc8input = L.Dropout(n.relu7, in_place=True)
else:
fc8input = n.relu7
# always learn fc8 (param=learned_param)
fc8 = L.InnerProduct(fc8input, num_output=num_classes, param=learned_param)
# give fc8 the name specified by argument `classifier_name`
n.__setattr__(classifier_name, fc8)
if not train:
n.probs = L.Softmax(fc8)
if label is not None:
n.label = label
n.loss = L.SoftmaxWithLoss(fc8, n.label)
n.acc = L.Accuracy(fc8, n.label)
# write the net to a temporary file and return its filename
with tempfile.NamedTemporaryFile(delete=False) as f:
f.write(str(n.to_proto()))
return f.name
dummy_data = L.DummyData(shape=dict(dim=[1, 3, 227, 227]))
imagenet_net_filename = caffenet(data=dummy_data, train=False)
imagenet_net = caffe.Net(imagenet_net_filename, weights, caffe.TEST)
def style_net(train=True, learn_all=False, subset=None):
if subset is None:
subset = 'train' if train else 'test'
source = caffe_root + 'data/flickr_style/%s.txt' % subset
transform_param = dict(mirror=train, crop_size=227,
mean_file=caffe_root + 'data/ilsvrc12/imagenet_mean.binaryproto')
style_data, style_label = L.ImageData(
transform_param=transform_param, source=source,
batch_size=50, new_height=256, new_width=256, ntop=2)
return caffenet(data=style_data, label=style_label, train=train,
num_classes=NUM_STYLE_LABELS,
classifier_name='fc8_flickr',
learn_all=learn_all)
untrained_style_net = caffe.Net(style_net(train=False, subset='train'),
weights, caffe.TEST)
untrained_style_net.forward()
style_data_batch = untrained_style_net.blobs['data'].data.copy()
style_label_batch = np.array(untrained_style_net.blobs['label'].data, dtype=np.int32)
def disp_preds(net, image, labels, k=5, name='ImageNet'):
input_blob = net.blobs['data']
net.blobs['data'].data[0, ...] = image
probs = net.forward(start='conv1')['probs'][0]
top_k = (-probs).argsort()[:k]
print 'top %d predicted %s labels =' % (k, name)
print '\n'.join('\t(%d) %5.2f%% %s' % (i+1, 100*probs[p], labels[p])
for i, p in enumerate(top_k))
def disp_imagenet_preds(net, image):
disp_preds(net, image, imagenet_labels, name='ImageNet')
def disp_style_preds(net, image):
disp_preds(net, image, style_labels, name='style')
batch_index = 8
image = style_data_batch[batch_index]
plt.imshow(deprocess_net_image(image))
print 'actual label =', style_labels[style_label_batch[batch_index]]
plt.show()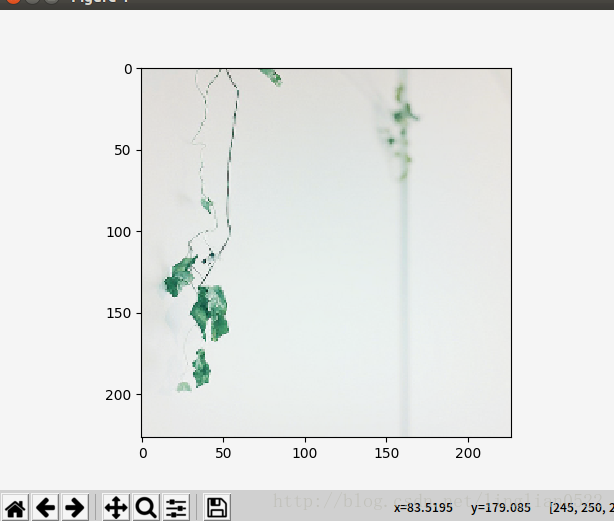
disp_imagenet_preds(imagenet_net, image)
disp_style_preds(untrained_style_net, image)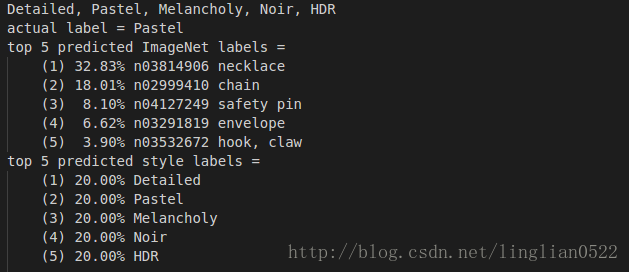
实验二
运行下面代码
import numpy as np
import matplotlib.pyplot as plt
#matplotlib inline
# Make sure that caffe is on the python path:
caffe_root = '/home/lol/dl/caffe/' # this file is expected to be in {caffe_root}/examples
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
# configure plotting
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Load the net, list its data and params, and filter an example image.
caffe.set_mode_cpu()
net = caffe.Net(caffe_root + 'examples/net_surgery/conv.prototxt', caffe.TEST)
print("blobs {}\nparams {}".format(net.blobs.keys(), net.params.keys()))
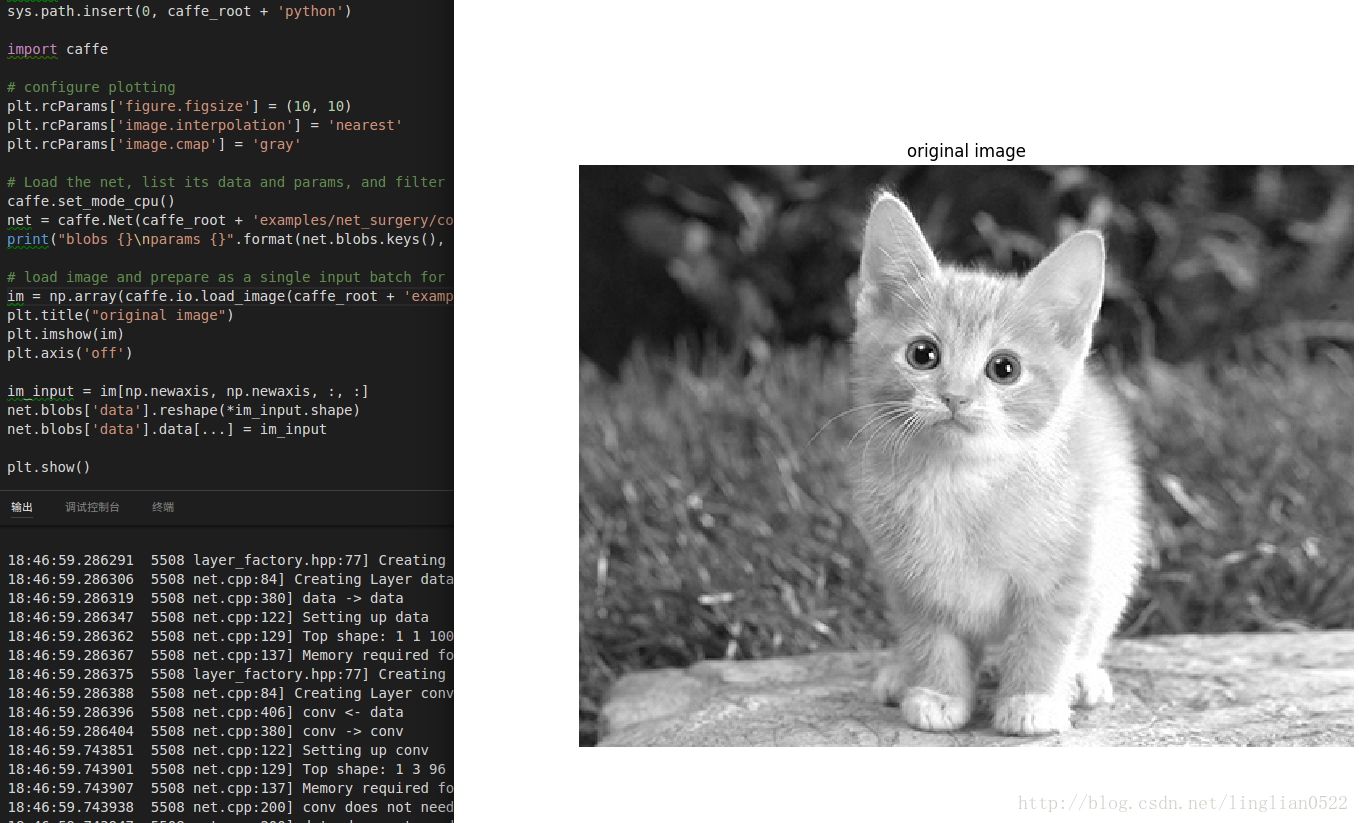
# load image and prepare as a single input batch for Caffe
im = np.array(caffe.io.load_image(caffe_root + 'examples/images/cat_gray.jpg', color=False)).squeeze()
plt.title("original image")
plt.imshow(im)
plt.axis('off')
im_input = im[np.newaxis, np.newaxis, :, :]
net.blobs['data'].reshape(*im_input.shape)
net.blobs['data'].data[...] = im_input
plt.show()
def show_filters(net):
net.forward()
plt.figure()
filt_min, filt_max = net.blobs['conv'].data.min(), net.blobs['conv'].data.max()
for i in range(3):
plt.subplot(1,4,i+2)
plt.title("filter #{} output".format(i))
plt.imshow(net.blobs['conv'].data[0, i], vmin=filt_min, vmax=filt_max)
plt.tight_layout()
plt.axis('off')
plt.show()
# filter the image with initial
show_filters(net)
# pick first filter output
conv0 = net.blobs['conv'].data[0, 0]
print("pre-surgery output mean {:.2f}".format(conv0.mean()))
# set first filter bias to 1
net.params['conv'][1].data[0] = 1.
net.forward()
print("post-surgery output mean {:.2f}".format(conv0.mean()))
ksize = net.params['conv'][0].data.shape[2:]
# make Gaussian blur
sigma = 1.
y, x = np.mgrid[-ksize[0]//2 + 1:ksize[0]//2 + 1, -ksize[1]//2 + 1:ksize[1]//2 + 1]
g = np.exp(-((x**2 + y**2)/(2.0*sigma**2)))
gaussian = (g / g.sum()).astype(np.float32)
net.params['conv'][0].data[0] = gaussian
# make Sobel operator for edge detection
net.params['conv'][0].data[1:] = 0.
sobel = np.array((-1, -2, -1, 0, 0, 0, 1, 2, 1), dtype=np.float32).reshape((3,3))
net.params['conv'][0].data[1, 0, 1:-1, 1:-1] = sobel # horizontal
net.params['conv'][0].data[2, 0, 1:-1, 1:-1] = sobel.T # vertical
show_filters(net)
接着运行下面命令
diff net_surgery/bvlc_caffenet_full_conv.prototxt ../models/bvlc_reference_caffenet/deploy.prototxt
# Load the original network and extract the fully connected layers' parameters.
net = caffe.Net(caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt',
caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel',
caffe.TEST)
params = ['fc6', 'fc7', 'fc8']
# fc_params = {name: (weights, biases)}
fc_params = {pr: (net.params[pr][0].data, net.params[pr][1].data) for pr in params}
for fc in params:
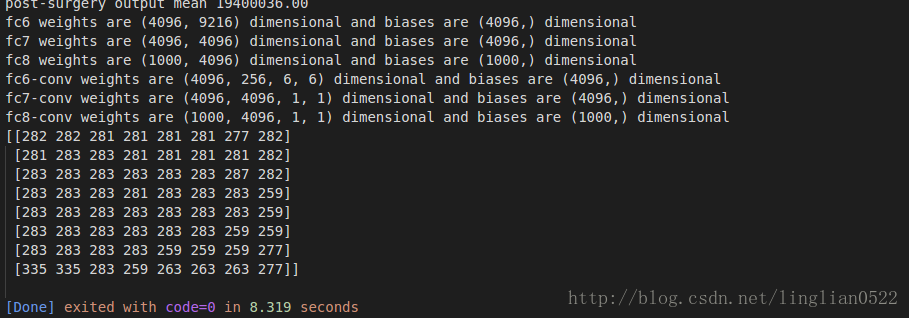
print '{} weights are {} dimensional and biases are {} dimensional'.format(fc, fc_params[fc][0].shape, fc_params[fc][1].shape)
# Load the fully convolutional network to transplant the parameters.
net_full_conv = caffe.Net(caffe_root + 'examples/net_surgery/bvlc_caffenet_full_conv.prototxt',
caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel',
caffe.TEST)
params_full_conv = ['fc6-conv', 'fc7-conv', 'fc8-conv']
# conv_params = {name: (weights, biases)}
conv_params = {pr: (net_full_conv.params[pr][0].data, net_full_conv.params[pr][1].data) for pr in params_full_conv}
for conv in params_full_conv:
print '{} weights are {} dimensional and biases are {} dimensional'.format(conv, conv_params[conv][0].shape, conv_params[conv][1].shape)
for pr, pr_conv in zip(params, params_full_conv):
conv_params[pr_conv][0].flat = fc_params[pr][0].flat # flat unrolls the arrays
conv_params[pr_conv][1][...] = fc_params[pr][1]
net_full_conv.save(caffe_root + '/examples/net_surgery/bvlc_caffenet_full_conv.caffemodel')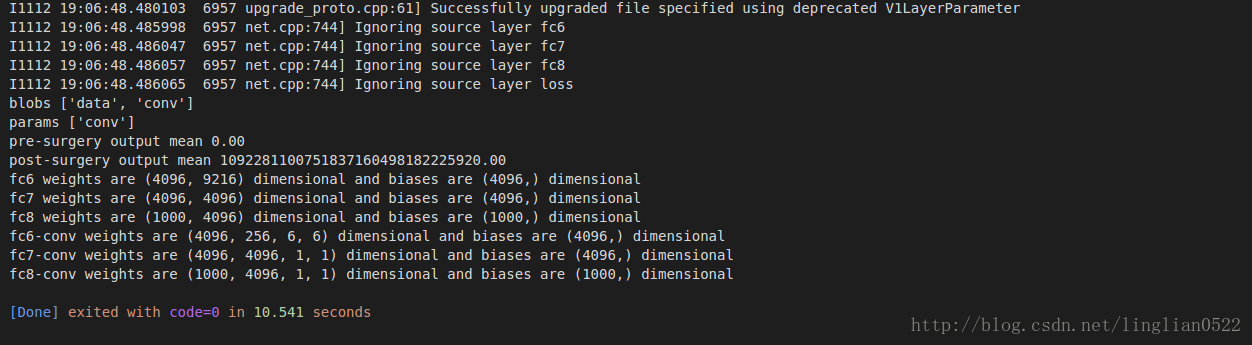
import numpy as np
import matplotlib.pyplot as plt
# load input and configure preprocessing
im = caffe.io.load_image(caffe_root + 'examples/images/cat.jpg')
transformer = caffe.io.Transformer({'data': net_full_conv.blobs['data'].data.shape})
transformer.set_mean('data', np.load(caffe_root + 'examples/../python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1))
transformer.set_transpose('data', (2,0,1))
transformer.set_channel_swap('data', (2,1,0))
transformer.set_raw_scale('data', 255.0)
# make classification map by forward and print prediction indices at each location
out = net_full_conv.forward_all(data=np.asarray([transformer.preprocess('data', im)]))
print out['prob'][0].argmax(axis=0)
# show net input and confidence map (probability of the top prediction at each location)
plt.subplot(1, 2, 1)
plt.imshow(transformer.deprocess('data', net_full_conv.blobs['data'].data[0]))
plt.subplot(1, 2, 2)
plt.imshow(out['prob'][0,281])