5.11.redis cluster实验: 多master写入、读写分离、高可用性
redis cluster,提供了多个master,数据可以分布式存储在多个master上; 每个master都带有slave,自动就做读写分离; 某个master如果出现故障,就会自动将其slave切换成master,达到高可用。
5.11.1. 多master的写入-海量数据的分布式存储原理
多master的写入,能实现海量数据分布式存储。
在redis cluster写入数据的时候,可以将请求发送到任意一个master上去执行。
当执行写入set key1 value1的时候,每个master都会计算key1对应的CRC16值,并对16384个hash slot取模,找到key1对应的hash slot,然后找到对应的master,如果对应的master就是自己,自己就做写入操作,如果不在此master上,就会给client返回一个moved error,并告诉client到哪个master上去执行这条写入的命令,如下:
[root@cache01 data]# redis-cli -h 192.168.75.187 -p 7001
192.168.75.187:7001>
192.168.75.187:7001> set key1 value1
(error) MOVED 9189 192.168.75.187:7002
192.168.75.187:7001>
我们到192.168.75.187服务器上,启动7002端口的master
[root@cache01 data]# redis-cli -h 192.168.75.187 -p 7002
192.168.75.187:7002> set key1 value1
OK
192.168.75.187:7002>
什么叫做多master的写入,就是每条数据只能存在于一个master上,不同的master负责存储不同的数据,分布式的数据存储200w条数据,10个master,每个master就负责存储20w条数据。
牵涉到海量数据,就会涉及到大数据,同时就会涉及到分布式。
大型的java系统架构,或者大数据系统架构,一般都专注分布式,与分布式有关的技术有:
1、分布式存储hadoop hdfs。
2、分布式资源调度hadoop yarn。
3、分布式计算hadoop mapreduce/hive。
4、分布式的nosql数据库hbase。
5、分布式协调zookeeper。
6、分布式通用计算引擎spark。
7、分布式实时计算引擎storm。
8、搜索引擎elasticsearch
elasticsearch建立索引的时候,先写内存缓存,每秒钟把数据刷入os cache,接下来再每隔一定时间fsync到磁盘。elasticsearch,建立索引时也会根据doc id/routing value,去路由到某个节点去执行。而redis cluster,可以写到任意master,任意master计算key的hash slot以后,告诉client,重定向到其他mater去执行。elasticsearch与redis cluster 的分布式调度是相似的,并且分布式的相关技术,如hadoop,spark,storm里面很多核心的思想都是类似的。
5.11.2. 实验一:不同master与其slave读写分离
在这个redis cluster中,如果你要在slave读取数据,需要使用redis-cli -c 启动,然后发送readonly指令,再读取数据 get key1.
[root@cache01 data]# redis-cli -c -h 192.168.75.187 -p 7001
192.168.75.187:7001> get key1
-> Redirected to slot [9189] located at 192.168.75.187:7002
"value1"
192.168.75.187:7002>
使用redis-cli -c 命令启动后,redis cluster 就会根据key自动进行底层的重定向的操作,以上,get key1命令,就重定向到192.168.75.187:7002服务器上获取数据 。
以下,set key2 value2 命令,就重定向到192.168.75.187:7003服务器上进行写操作。
192.168.75.187:7002> set key2 value2
-> Redirected to slot [4998] located at 192.168.75.187:7003
OK
192.168.75.187:7003>
对redis cluster做读写分离的时候,会发现有一定的限制性,默认情况下,redis cluster的核心理念:
-
主要是用slave做高可用的,每个master挂一两个slave,主要功能是:
-
做数据的热备;
-
master故障时的主备切换,实现高可用的。
-
-
redis cluster默认是不支持slave节点读或者写的,跟我们手动基于replication搭建的主从架构不一样。
为什么redis cluster默认不支持slave节点的读或写?
redis cluster的主从架构,如果做读写分离,会很复杂,jedis客户端对redis cluster的读写分离支持不太好,它默认就是读和写都到master上去执行,如果你要让最流行的jedis做redis cluster的读写分离的访问,那可能还得自己修改一点jedis的源码,成本比较高,自己基于jedis,封装一下,自己做一个redis cluster的读写分离的访问api。
读写分离,是为了什么,主要是因为要建立一主多从的架构,才能横向任意扩展slave node,去支撑更大的读吞吐量,而redis cluster的架构下,master是可以任意扩展的,如果要支撑更大的读吞吐量,或者写吞吐量,都可以直接对master进行横向扩展,这样就可以实现支撑更高的读吞吐的效果,跟之前使用redis replication扩容slave,效果是一样的。
5.11.3. 实验二:master与的slave自动切换
实验自动故障切换 -> 高可用性
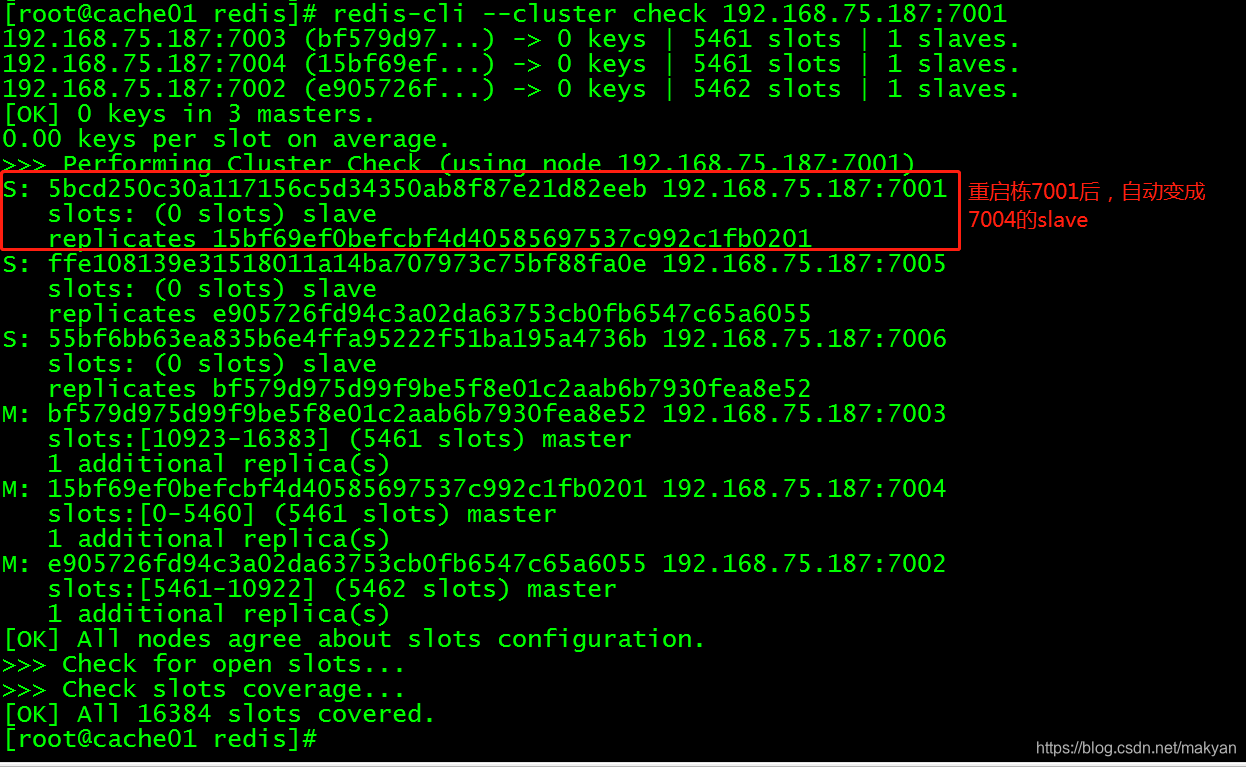
[root@cache01 redis]# redis-cli --cluster check 192.168.75.187:7001
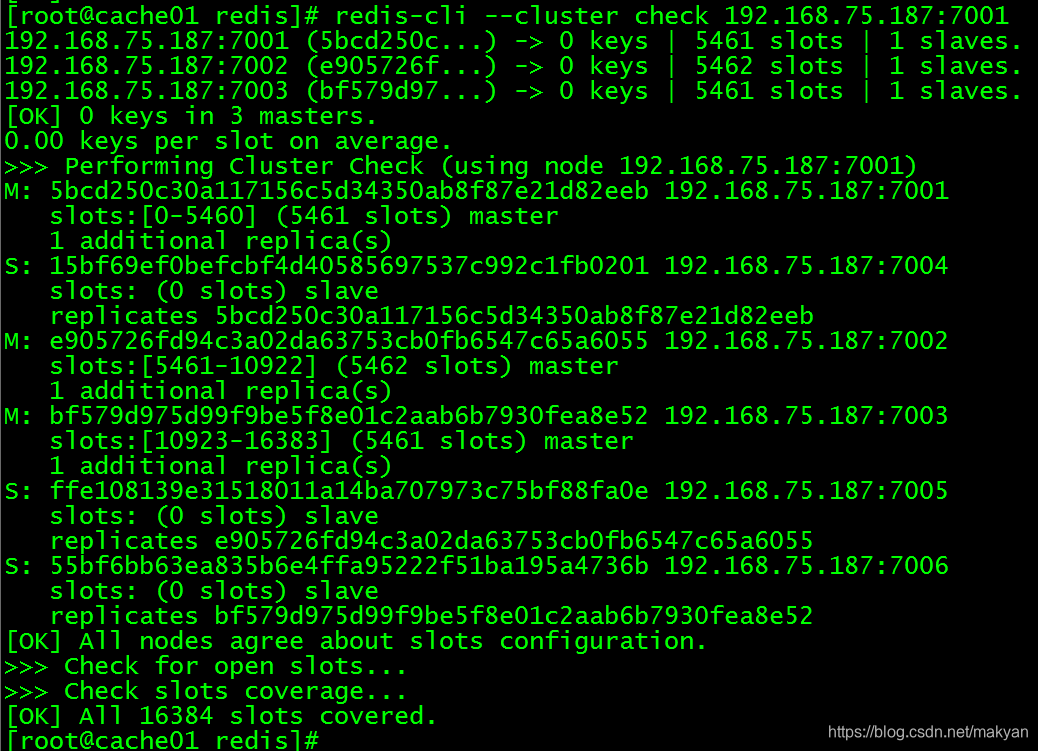
redis集群检测发现,redis master 192.168.75.187:7001 对应的 redis slave是:192.168.75.187:7004,我们将192.168.75.187:7001杀掉,看它对应的slave能不能自动切换成master。

192.168.75.187:7004已经自动切换成master。
再试着把187:7001给重新启动,恢复过来,自动作为slave挂载到了19:7004上面去。