点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> OCR技术交流群
转载自:CSIG文档图像分析与识别专委会

本文简要介绍TPAMI 2022录用论文"Arbitrary Shape Text Detection via Segmentation with Probability Maps"的主要工作。该文提出了一个基于概率分布图的任意形状文本实例分割和检测方法。本文设计了一个Sigmoid Alpha Function (SAF)函数来建模一个像素属于文本像素的概率和到标注边界距离的关系。我们可以选取一组合适的分布来覆盖任意非确定性的分布。一个迭代模型被用来隐式地学习一组分布之间的映射关系,通过迭代的方法逐步生成概率分布图。最后,区域生长算法处理这一组概率分布图,从而完整地重建出精确的文本实例区域。
一、研究背景
任意形状文本检测是一项具有挑战性的任务,这是由于多变的方向或形状,悬殊的大小和宽高比,以及不精确的标注等因素导致的。由于基于实例分割的方法[1][2]能够很容易地适应各种不同形状的文本,因此近年来受到了广泛关注。目前,基于分割思路来解决任意形状文本检测的方法[1][2][3]大多依赖对图片像素进行二分类(Text/no-text)得到的置信度分布图。然而,文本图像精确的像素级标注是非常困难的,现有的场景文本检测数据集大多只提供粗粒度的边界标注,这些供粗粒度的边界标注内总是存在大量背景噪声像素。但是现有的检测方法[3]往往选择了忽略这个问题,从而简单地认为粗粒度的边界标注内的像素都是文本像素。这也导致了通过学习得到的置信度分布图不那么令人满意,常常包含许多的噪声和缺陷,从而极大的限制了模型的实际分割效果。
对于文本检测来说,粗粒度的边界标注通常是落在背景区域的。由于标注的偏差,标注的边界究竟包含的多少的背景区域,是难以准确的衡量的。但是可以知道的是,标注边界内的像素,距离标注边界越近,那么它是背景像素的概率就越大。从现有一些基于分割的文本检测方法得到的置信度分布图,我们也可以看出对于同一个文本实例,置信度的分布大概呈现从中到边界递减的规律。基于此观察,这篇论文提出了一个概率分布图的文本检测方法,用于准确分割文本实例。
二、方法介绍
现有基于分割的文本检测方法直接使用粗粒度的边界标注来监督网络学习Text/no-text置信度分布图,从而导致实际分割效果不理想,常常包含许多的噪声和缺陷。针对这一问题,这篇论文提出了一个基于概率分布图的任意形状文本实例分割和检测方法。具体来说,本文设计了一个Sigmoid Alpha Function (SAF)函数来建模一个像素它属于文本像素的概率和它到标注边界距离的关系。但实际上,很难用单一的分布来描述这种非确定性的关系。然而,SAF允许通过设置不同的超参数alpha来生成不同的分布。因此,我们可以选取一组合适的分布来覆盖任意非确定性的分布。一个迭代模型被用来隐式地学习一组分布之间的映射关系,通过迭代的方法来逐步生成这一组概率分布图。最后,一些简单的区域生长算法,被用来处理这一组概率分布图,从而完整地重建出精确的文本实例区域。
2.1 模型的架构
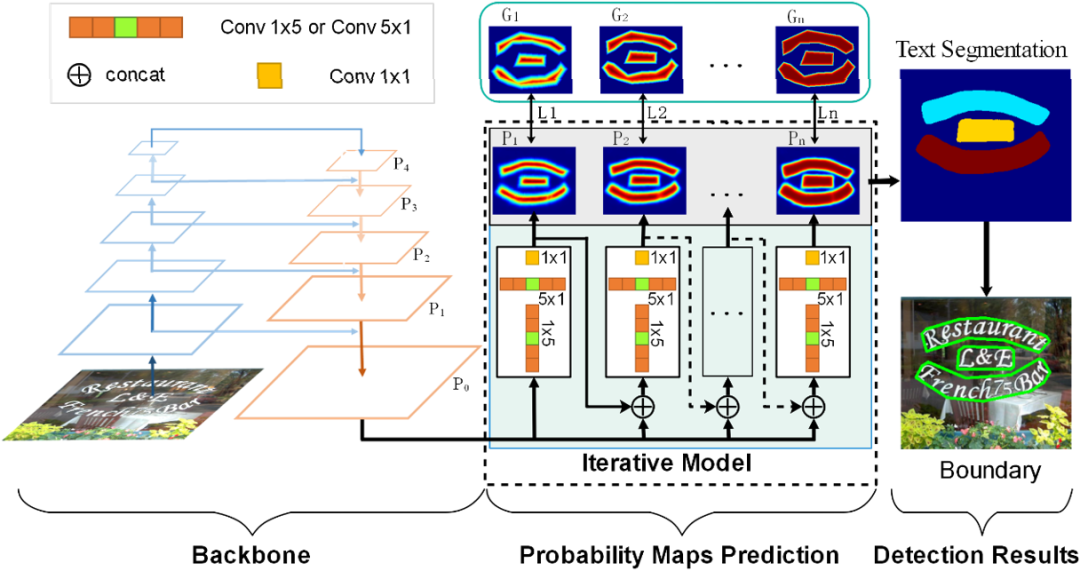
图1网络整体框架
图1 是文章提出的网络的整体框架,它包含一个类似特征金字塔结构的骨干网络和一个迭代模型。迭代模型由非对称卷积组成的,用来隐式的学习和建模不同概率分布之间的映射关系,并迭代的产生一组概率分布。最后,通过将区域生长算法(例如:渐进式扩张算法[3], 分水岭算法[4])应用在这一组概率分布图上来分割出不同的文本实例。
2.2 Sigmoid Alpha Function (SAF)函数
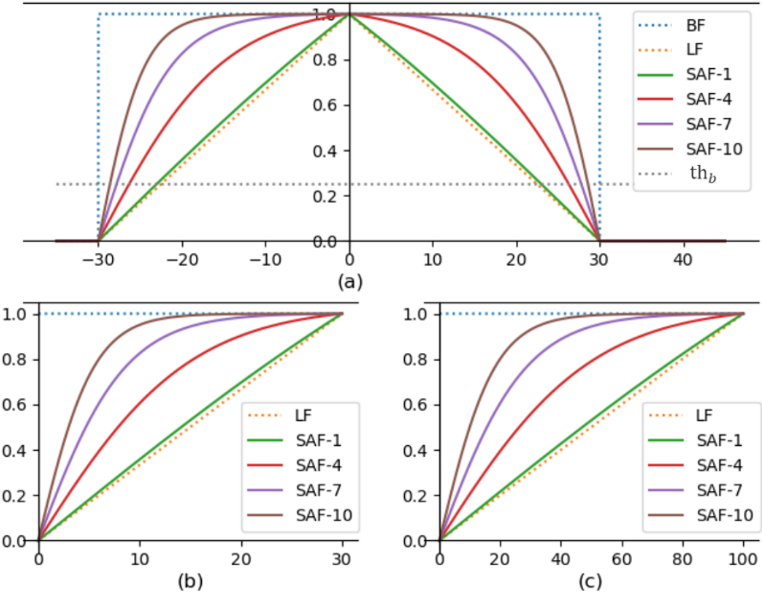
图2 Sigmoid Alpha Function
这篇论文基于像素到标注边界之间的距离构建了一个概率分布图来描述边界内像素属于文本的概率分布。为了建立像素概率与边界距离之间的映射关系,文章提出了一种基于Sigmoid函数的变体函数Sigmoid Alpha Function (SAF)。SAF函数可以将距离值映射到范围[0,1],映射后的值可以被视为像素的概率值。于是,这篇文章采用SAF函数将像素到标注边界之间的距离映射为某种概率分布,即将距离图(Distance Map)映射为概率图(Probability Map)。Sigmoid Alpha Function (SAF) 函数定义如下:
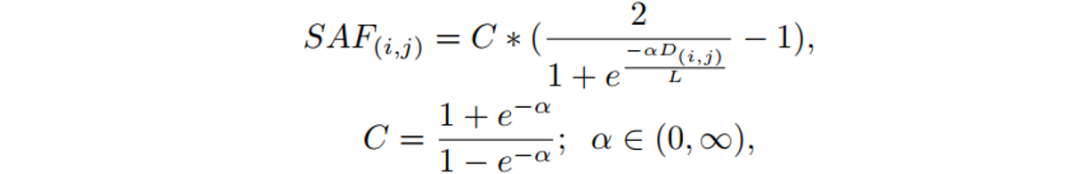
其中,D(i, j)是从像素(i, j)到边界的最短距离; L表示该文本实例的的尺寸,定义为:
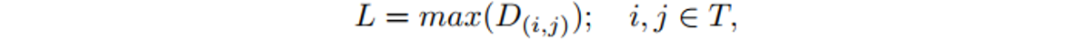
SAF生成的不同概率分布曲线, 如图2所示。SAF函数有两种极端情况,分别对应着LF和BF:
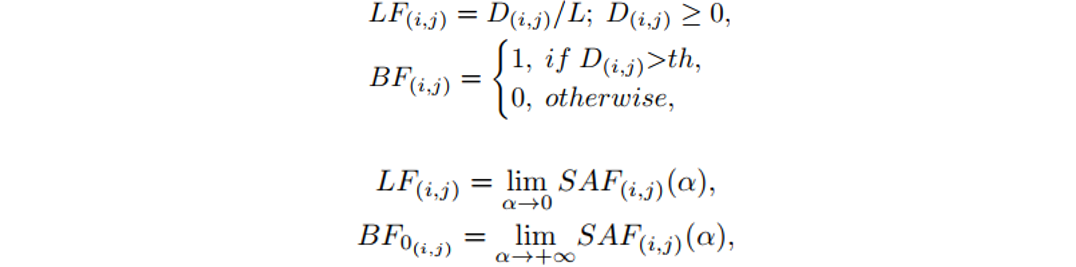
其中,LF对应着距离图(Distance Map)的线性归一化,而BF是距离图(Distance Map)的二值归一化。其中BF所对应的二值图,也被用来当作文本图像像素二分类(Text/no-text)的真值。图3是使用SAF来生成概率分布图的真值过程。
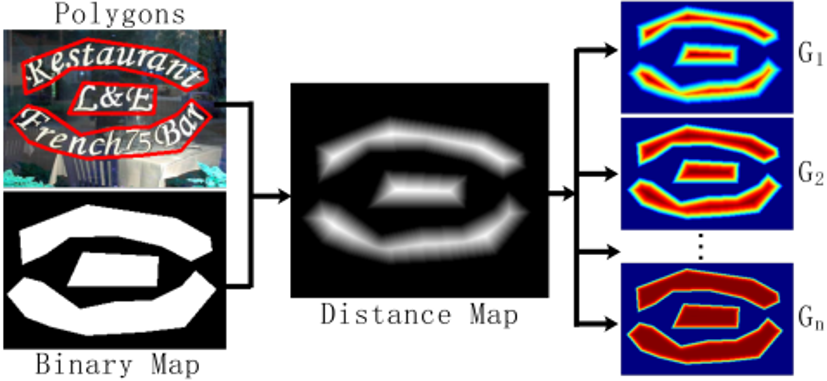
图3概率分布图的真值生成过程
2.3 迭代模型
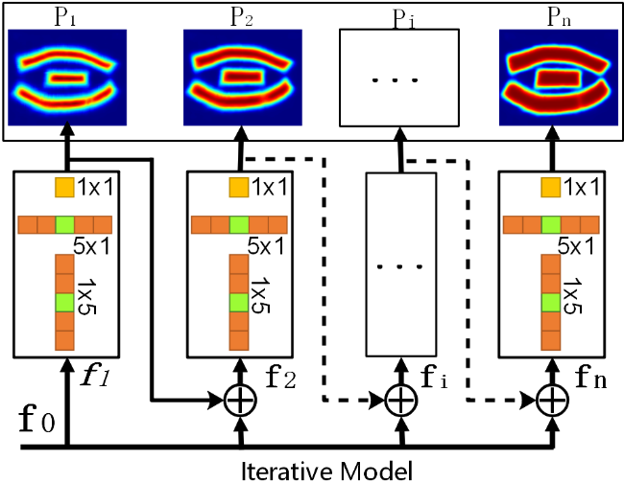
图4迭代模型的结构
如图4所示,迭代模型由非对称卷积组成的多个模块(Block)组,用来隐式的学习和建模不同概率分布之间的映射关系。当从骨干网络获得16个通道的融合特征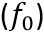 后,即将其送入迭代模型的第一个迭代层,产生第一个概率分布
后,即将其送入迭代模型的第一个迭代层,产生第一个概率分布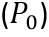 。然后,融合特征
。然后,融合特征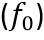 和概率分布
和概率分布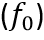 会一起送入第二个迭代层,来生成第二个概率分布
会一起送入第二个迭代层,来生成第二个概率分布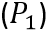 。反复执行次迭代过程,就可以得到所有的概率分布图
。反复执行次迭代过程,就可以得到所有的概率分布图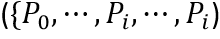 。因此迭代模型的可表示为以下形式:
。因此迭代模型的可表示为以下形式:
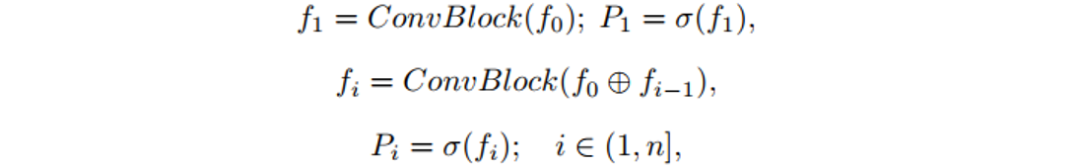
其中“⊕” 指Cancat操作;σ(∙)表示Sigmoid激活函数;ConvBlock由一组不对称卷积组成(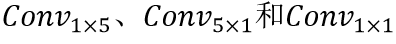 );n表示迭代次数。
);n表示迭代次数。
2.4 优化损失
由于这篇论文只需要预测概率分布图,因此采用了MSE作为模型优化的损失,损失函数如下:
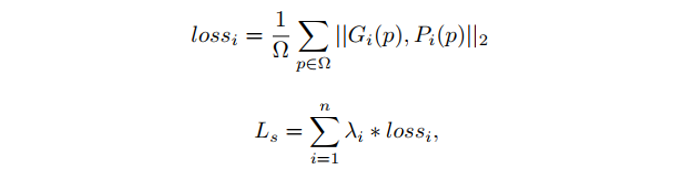
其中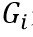 是概率图的第i个概率分布的真值,
是概率图的第i个概率分布的真值, 是第i个预测的概率分布图,
是第i个预测的概率分布图, 采用了等权重的设置,因此均设置为了1.0。
采用了等权重的设置,因此均设置为了1.0。
三、实验结果
图 5 迭代次数和α值对检测结果的影响
本文的控制参数α从一个等差数列中取值,等差数列形式如下:
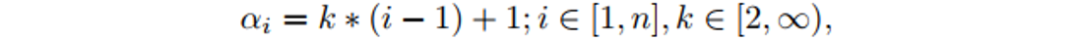
其中,k是α的取值间隔,i对应着迭代次数。为了有足够的信息来重建文本实例,最小迭代次数为。为了所生成的概率分布之间相互存较大差异,最小的取值间隔为2。迭代次数和α值对检测结果的影响如图5所示,迭代次数为4时,检测结果基本达到了最佳效果,合适的取值间隔,可以进一步减少迭代次数。
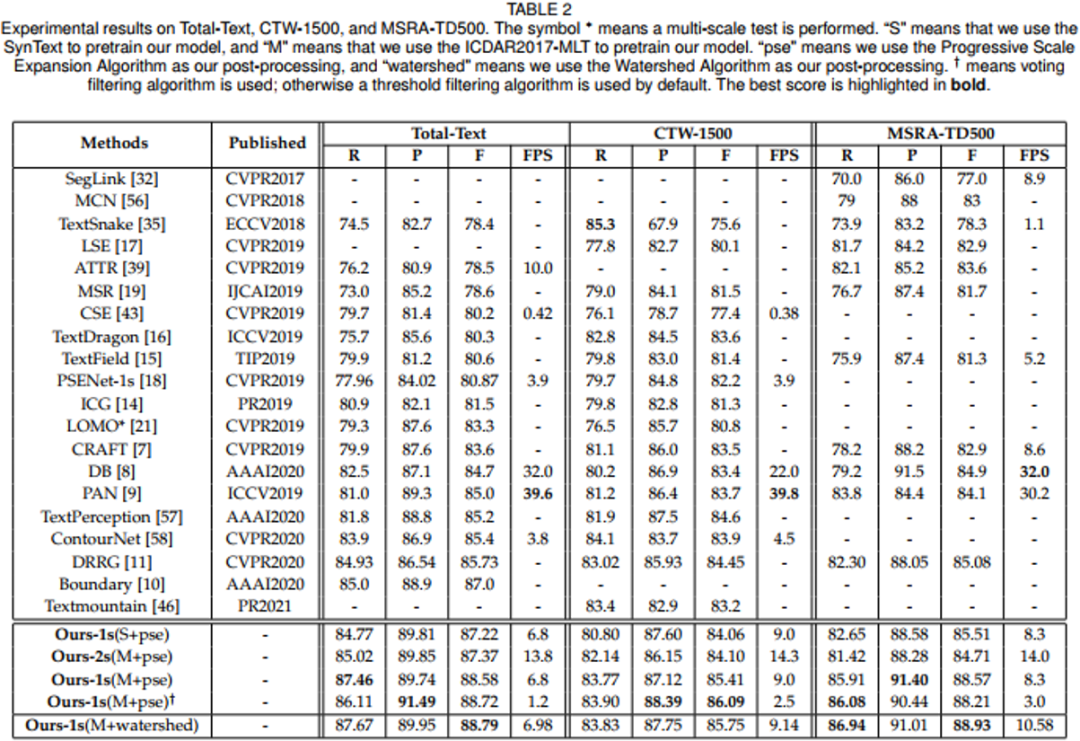
从表2来看,该文的方法在曲形文本数据集(Total-Text和CTW1500)以及多语言长文本数据集(MSRA-TD500)上都取得了非常好的检测效果。而且,本文提出的方法在使用不同后处理算法时,取得了相当的实验效果,说明该方法并不依赖于单一的后处理算法。
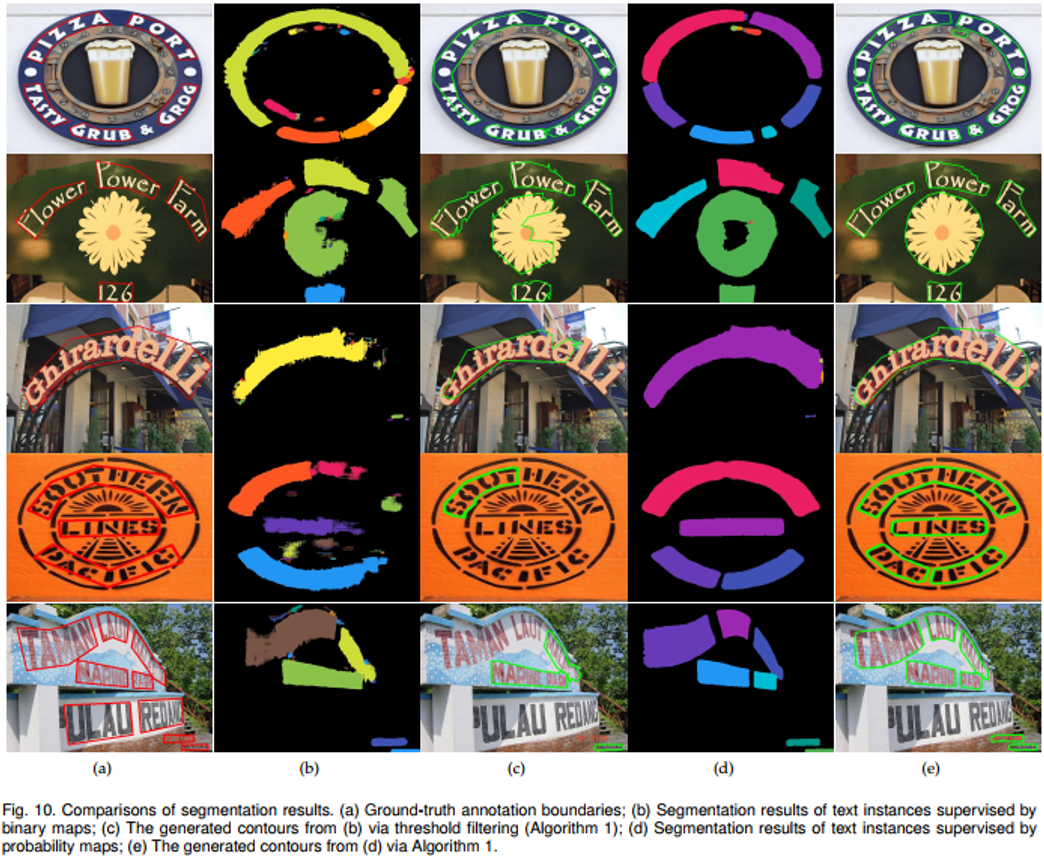
图10展示了一些本文方法的文本实例分割的结果和传统的用二值图作监督的文本实例分割方法所得到的分割结果的对比。可以看出,本文方法得到的分割结果,噪声和瑕疵更少,因此可以取得更好的检测效果。
四、相关资源
论文连接:https://ieeexplore.ieee.org/document/9779460
代码连接:https://github.com/GXYM/TextPMs
参考文献
[1] M. Liao, Z. Wan, C. Yao, K. Chen, and X. Bai, “Real-time scene text detection with differentiable binarization,” in AAAI, 2020, pp. 11 474–11 481.
[2] W. Wang, E. Xie, X. Song, Y. Zang, W. Wang, T. Lu, G. Yu, and C. Shen, “Efficient and accurate arbitrary-shaped text detection with pixel aggregation network,” in ICCV, 2019, pp. 8439–8448.
[3] W. Wang, E. Xie, X. Li, W. Hou, T. Lu, G. Yu, and S. Shao, “Shape robust text detection with progressive scale expansion network,” in CVPR, 2019, pp. 9336–9345.
[4] Hans Bandemer, Friedrich Hulsch, Arndt Lehmann, “Watershed Algorithm Adapted to Functions on Grids”, J. Inf. Process. Cybern. 22(10/11): 553-564 (1986)
[5] Y. Zhu and J. Du, “Textmountain: Accurate scene text detection via instance segmentation,” Pattern Recognit., vol. 110, p. 107336, 2021.
原文作者:Shi-Xue Zhang, Xiaobin Zhu*, Lei Chen, Jie-Bo Hou, Xu-Cheng Yin
撰稿:张世学 编排:高 学
审校:连宙辉 发布:金连文
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看