点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

在CVer微信公众号后台回复:MUS,可以下载本论文pdf
MUS-CDB: Mixed Uncertainty Sampling with Class Distribution Balancing for Active Annotation in Aerial Object Detection
文章链接:
https://ieeexplore.ieee.org/document/10158738
主页: https://dongl-group.github.io
引言:
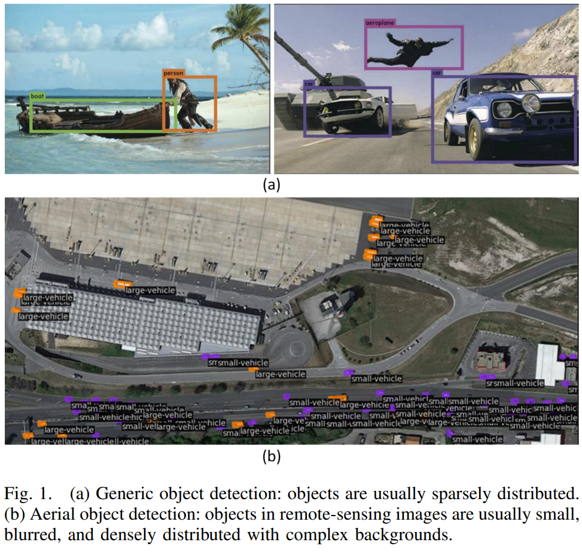
现有的遥感目标检测模型通常依赖于大量的标记训练数据,然而由于遥感场景中物体密度较高,因此手工标注所需的时间和金钱成本非常昂贵。主动学习通过有选择地查询信息丰富和代表性的未标记样本,有效降低了数据标注成本。然而,现有的主动学习方法主要适用于类别平衡设置和基于图像查询的通用物体检测任务,而在遥感目标检测场景中,由于存在长尾类分布和密集小物体,这些方法并不太适用。如图1所示,相较于通用场景下的物体分布,航空遥感图像中的目标通常呈现较小、模糊的特点,并且在复杂背景中密集分布。
在本文中,我们提出了一种新颖的遥感目标检测主动学习方法,旨在有效降低成本。具体而言,在物体采样中考虑了对象级和图像级的信息性,以避免冗余和短视的查询。此外,还结合了一个易于使用的类平衡准则,以支持少数类对象,缓解模型训练中的长尾类分布问题。我们进一步设计了一个训练损失,来挖掘未标记图像区域中的潜在知识。
方法:
使用主动学习进行遥感目标检测旨在通过从大型未标记数据集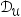 中选择信息量丰富的样本来降低标注成本,从而训练一个性能良好的检测器
中选择信息量丰富的样本来降低标注成本,从而训练一个性能良好的检测器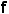 。该问题由三组数据定义:用于初始化模型的小型完全标记集
。该问题由三组数据定义:用于初始化模型的小型完全标记集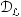 ,用于数据选择的大型未标记集
,用于数据选择的大型未标记集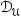 ,以及通过主动学习方法采样的部分标记集
,以及通过主动学习方法采样的部分标记集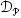 。为了使用最小的标记成本来训练一个性能良好的检测器
。为了使用最小的标记成本来训练一个性能良好的检测器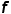 ,我们使用采样函数从
,我们使用采样函数从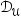 中选择信息最丰富的样本进行标注,标注后的图片加入
中选择信息最丰富的样本进行标注,标注后的图片加入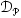 。我们设计了两个模块来进行经济高效的采样:混合不确定性采样模块(MUS)和类别分布平衡采样(CDB)。方法的整体框架如图2所示。
。我们设计了两个模块来进行经济高效的采样:混合不确定性采样模块(MUS)和类别分布平衡采样(CDB)。方法的整体框架如图2所示。
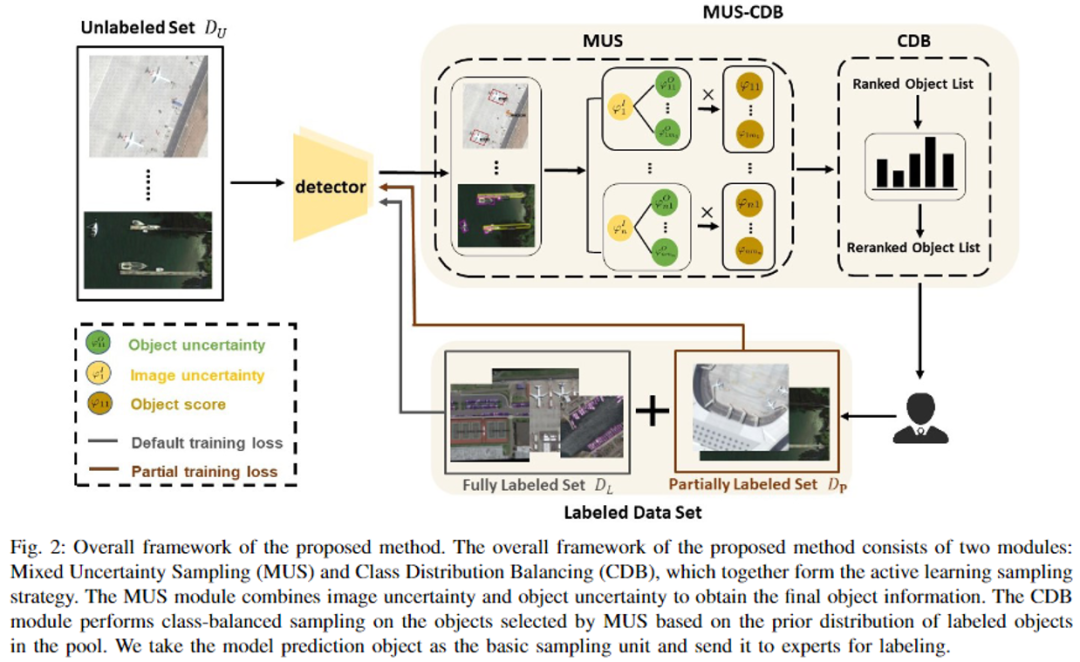
混合不确定性采样:
现有的基于对象的采样方法主要考虑预测框本身的信息,即类别不确定性或回归不确定性,但忽视了图像的空间信息和语义结构。为了解决这个问题,我们提出考虑图像和对象的不确定性,即结合全局和局部信息以进行更全面的数据评估。
关于图像不确定性,如果一张图像中有许多预测对象具有较高的不确定性,那么应该优先选择该图像进行采样。为此,我们评估并聚合模型预测的不确定性值以表示整个图像的不确定性值。具体而言,对于给定的图像 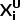 ,图像不确定性
,图像不确定性 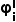 的表达式如下所示:
的表达式如下所示:
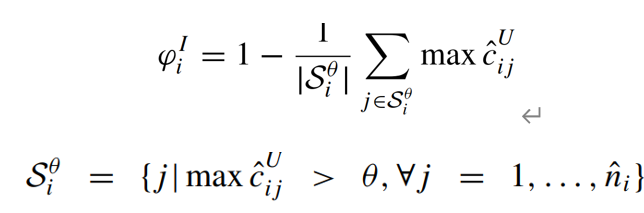
其中, 表示集合中元素的数量,
表示集合中元素的数量,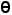 是分数阈值。图像不确定性值
是分数阈值。图像不确定性值 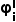 是通过计算图像中边界框的平均置信度得到的。只有置信度大于阈值
是通过计算图像中边界框的平均置信度得到的。只有置信度大于阈值 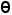 的边界框被用于计算平均置信度。当图像中存在许多置信度较低的预测边界框时,
的边界框被用于计算平均置信度。当图像中存在许多置信度较低的预测边界框时,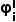 值会较高。这是因为图像中包含了难以区分的对象,导致预测结果不一致且置信度较低。因此,具有较高
值会较高。这是因为图像中包含了难以区分的对象,导致预测结果不一致且置信度较低。因此,具有较高 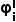 值的图像更有可能包含罕见模式的有用信息,也就更适合进行选择。
值的图像更有可能包含罕见模式的有用信息,也就更适合进行选择。
关于对象不确定性,为了在查询中考虑对象级别的信息,我们使用熵来评估每个预测边界框的不确定性。具体而言,对象不确定性 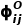 的计算如下所示:
的计算如下所示:
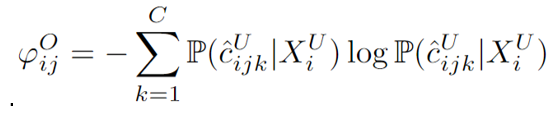
其中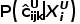 是图像
是图像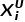 中第
中第 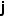 个边界框在类别
个边界框在类别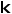 上的预测概率。
上的预测概率。
接下来,我们将图像不确定性 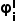 和对象不确定性
和对象不确定性 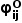 结合起来,得到最终的对象信息分数
结合起来,得到最终的对象信息分数  。
。
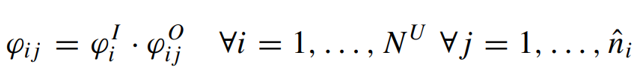
类别分布平衡采样:
遥感数据存在类别不平衡的问题,其中罕见类别对模型性能产生严重损害。为了解决这个问题,我们提出了一种在主动查询过程中强调低频类别的采样方法。具体而言,我们首先统计标记数据集中的类别分布情况,然后确定标记数据集中的罕见类别。设 表示类别
表示类别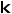 对应的对象数量,其中
对应的对象数量,其中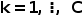 。我们的目标是在采样阶段通过对每个类别施加与
。我们的目标是在采样阶段通过对每个类别施加与 成反比的偏好
成反比的偏好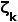 ,来更多地查询罕见的类别对象。采样偏好
,来更多地查询罕见的类别对象。采样偏好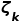 的计算方式如下:
的计算方式如下:
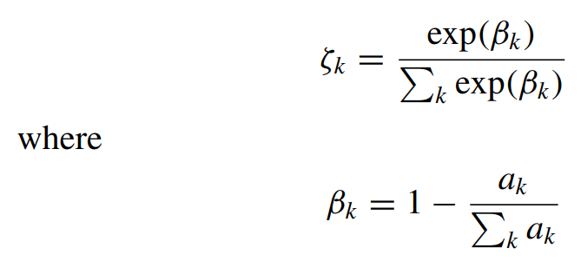
首先,根据ak值,我们计算标记集中每个类别的分布概率。然后,我们取其倒数得到类别权重βk,用于采样过程中的权重调整。接下来,我们使用Softmax函数计算采样期间预期的类别分布。通过这种方式,我们能够为不同的类别设定偏好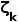 ,并在选择阶段有选择性地查询罕见类别对象,以提高模型的性能和准确性。
,并在选择阶段有选择性地查询罕见类别对象,以提高模型的性能和准确性。
处理部分标记图像:
为了应对模型训练过程中存在一些数据集完全标记,而另一些图像数据集仅部分标记的情况,我们采用了不同的训练损失函数来处理这两个集合。对于完全标记的数据集,我们沿用了检测器的默认训练损失函数;而对于部分标记的数据集,我们则采用了自定义的损失函数,以有效地挖掘图像中未标记区域的潜在知识。
具体来说,部分标记的图像在模型训练时会给分类损失中的负样本损失引入噪声,因为图像中的某些对象可能没有被标记并被视为负样本。为了解决这个问题,我们提出了一种自适应权重损失函数,用来处理分类损失中的负样本损失。该方法基于每个负样本的预测背景分数来调整其对应的分类损失权重。这种方法可以有效地抑制模型对于具有低背景分数的负样本(通常是前景对象)的分类损失。 定义如下:
定义如下:
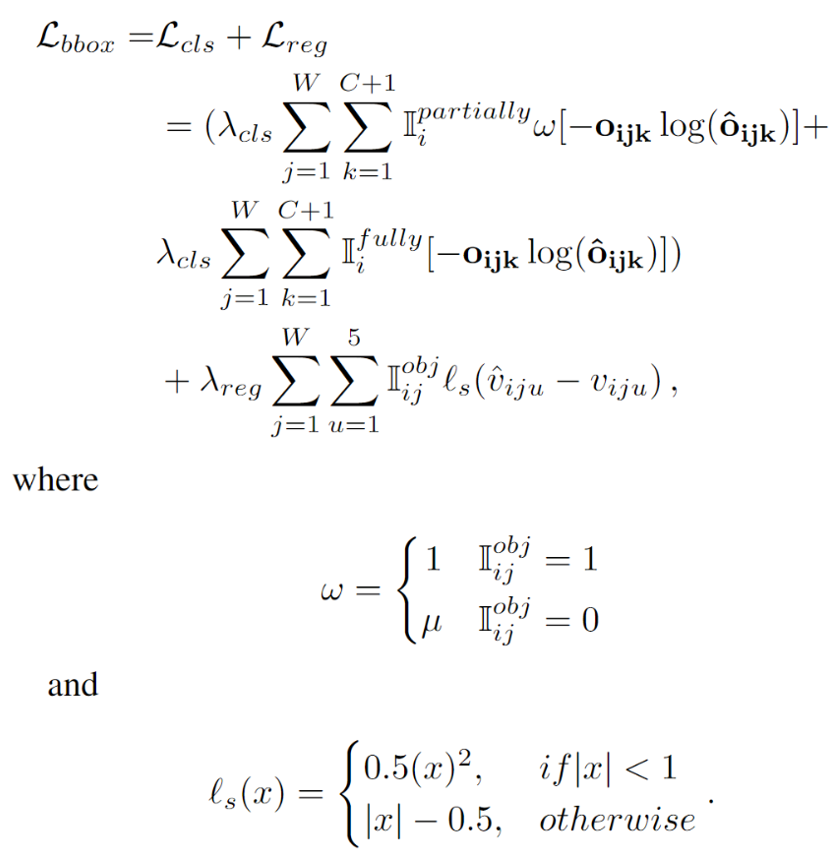
 包含分类损失(前两项)和框回归损失(最后一项)。其中,i和j是一个小批量中图像和区域提案的索引,W代表着参与训练的区域提案数。
包含分类损失(前两项)和框回归损失(最后一项)。其中,i和j是一个小批量中图像和区域提案的索引,W代表着参与训练的区域提案数。 和
和  是指示函数,用于表示图像是否是部分标记或完全标记。
是指示函数,用于表示图像是否是部分标记或完全标记。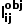 用于表示区域提案是否是正样本(即包含对象)。为了实现稳健的学习,引入了参数
用于表示区域提案是否是正样本(即包含对象)。为了实现稳健的学习,引入了参数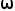 来降低背景对象的分类损失权重。
来降低背景对象的分类损失权重。
实验:
1、与其他主动学习方法比较
我们在四个遥感检测器(包括两个单阶段遥感检测器:KLD和SASM,以及两个双阶段遥感检测器:ReDet和Oriented R-CNN)以及两个数据集(DOTA-v1.0和DOTA-v2.0)上进行了性能比较。我们使用mAP作为比较指标。实验结果如表I所示。通过在多个检测器上进行的实验证明了所提出的MUS-CDB方法的有效性和通用性。该方法可以轻松地集成到各种目标检测框架中,并有助于提高不同应用中的目标检测模型性能。

熵采样仅在采样过程中考虑目标级别的信息,而混合不确定性采样则综合考虑目标级别和图像级别的信息。为了验证混合采样的有效性,我们进行了两种采样方法的性能比较。
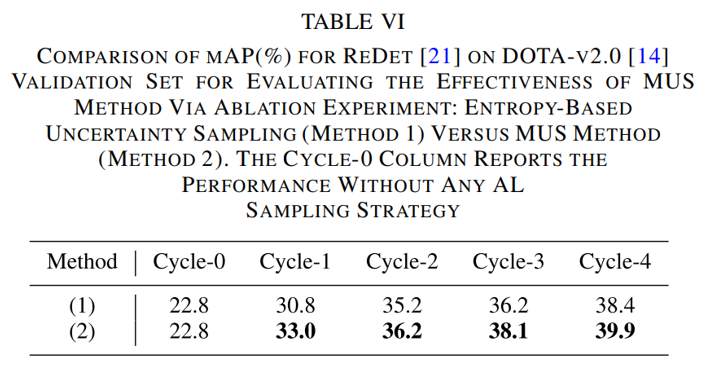
2、消融实验
为了证明我们提出的两个采样模块的有效性,我们进行了如下的消融实验。可以看到不确定性采样(MUS)和类别分布平衡采样(DUS)两个模块都可以有效提升模型性能。两者结合的二阶段采样可以更好的平衡采样结果的多样性和代表性。

我们还做消融实验证明了自适应损失函数的有效性。(1)代表使用默认的损失函数,(2)代表使用提出的改进损失。
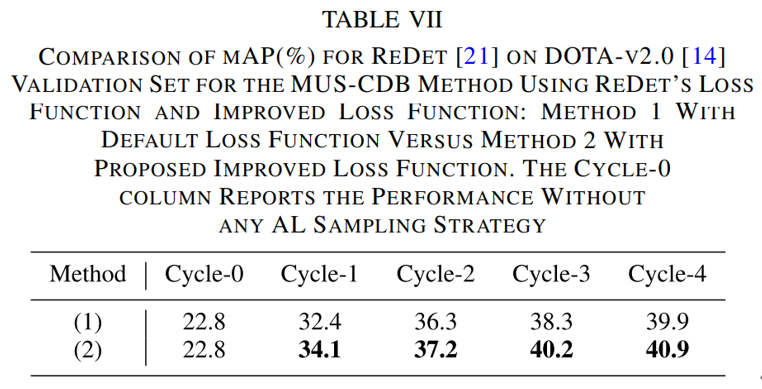
结论:
在本文中,我们提出了一种名为MUS-CDB的基于对象的主动学习方法,旨在减轻遥感目标检测数据注释所带来的巨大负担。我们在采样过程中设计了一种基于图像和对象的混合不确定性采样模块,以选择信息最丰富的实例进行标注。考虑到遥感图像数据集中的长尾问题,我们在采样过程中引入了类别偏好的策略,以促进所选对象的多样性。此外,我们还提出了一种针对部分标记数据的有效训练方法,以充分利用主动查询所获取的知识。
在CVer微信公众号后台回复:MUS,可以下载本论文pdf
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和遥感图像交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者遥感图像 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者遥感图像+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看