点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在CVer微信公众号后台回复:YoloCureSeg,可以下载本论文pdf和代码
本文作者丨林立,唐晓颖

01
导 语
医学影像与计算机辅助诊断(MICAD)国际会议今天给大家介绍的是来自南方科技大学唐晓颖教授团队联合香港大学Kenneth K. Y. Wong教授团队,在MedIA(Medical Image Analysis, 医学图像分析)杂志发表的最新论文“YoloCurvSeg: You only label one noisy skeleton for vessel-style curvilinear structure segmentation”。
弱监督学习(Weakly-supervised learning, WSL)通过采用稀疏粒度(即点、框、涂鸦)监督来训练语义分割网络,可以很大程度缓解数据标注成本与模型性能之间的矛盾,并已经在图像分割领域展现出良好的性能。然而,由于监督信号有限,这仍然是一项非常具有挑战性的任务,特别是在只有少量标记样本可用的情况下。此外,现有的WSL分割方法几乎都是针对星形结构(如器官等)设计的,这些结构与血管、神经等曲线结构有很大的不同。本文提出了一种新的稀疏标注曲线结构分割框架YoloCurvSeg。
YoloCurvSeg是一个基于图像合成的框架。具体而言,框架中的背景生成器通过修复(inpainting)经过膨胀处理后的的噪声骨架标注来提取与真实分布非常相似的图像背景。然后将提取的背景图像与基于空间殖民算法的前景生成器随机生成的模拟曲线结构相结合,经过多层逐块(patch-wise)对比学习合成器进行前、背景的融合。通过这种方法,可以得到同时具有图像和曲线结构分割标签的合成数据集,而标注成本是只需要一个或几个有噪声的骨架注释。最后,使用生成的数据集和可能存在的无标记真实图像数据集训练分割器。本文提出的方法在四个公开可用的数据集(OCTA500, CORN, DRIVE和CHASEDB1)上进行了评估,结果表明YoloCurvSeg大幅度优于最先进的WSL分割方法。仅使用一个噪声骨架注释(标注像素个数分别为原数据集全监督标签的0.14%,0.03%,1.40%和0.65%)的条件下,YoloCurvSeg在每个数据集上实现了超过97%全监督性能。代码和数据集已逐步在 https://github.com/llmir/YoloCurvSeg 上公开。
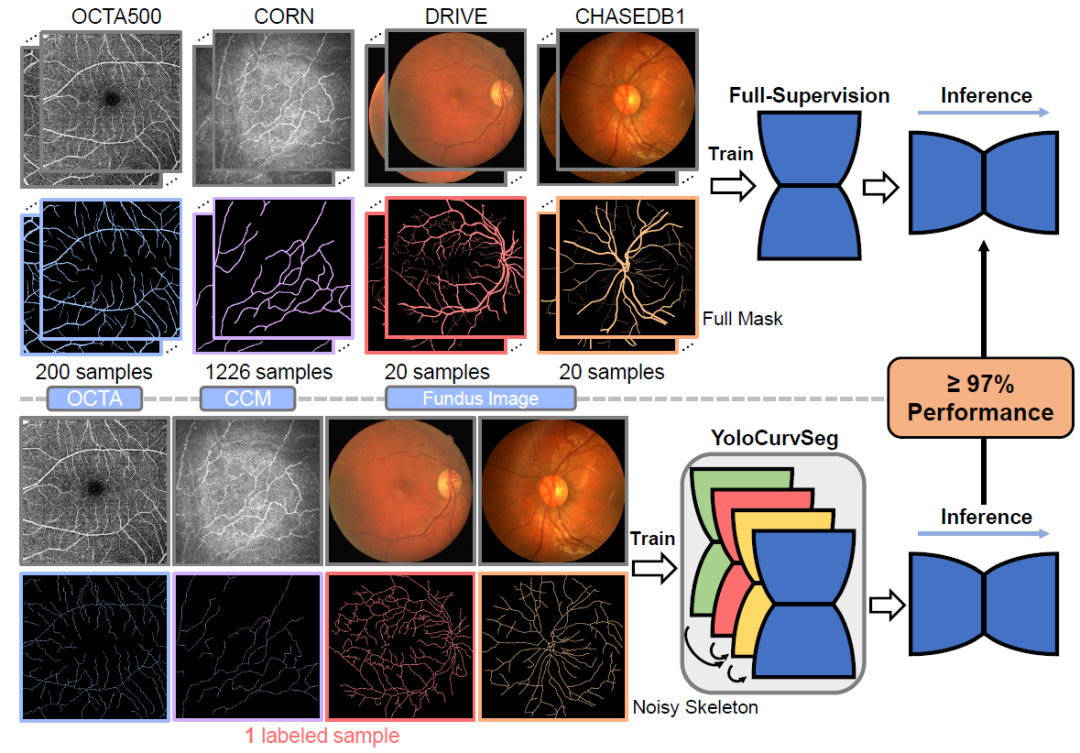
图1. YoloCurvSeg仅使用一个有噪声的骨架注释,在四个代表性数据集上实现了97%以上的全监督性能,这意味着医生可以大大节省标记时间,并且仍然获得令人满意的分割结果。
02
研究内容
曲线结构是细长、弯曲、多尺度的结构,通常呈树状,常见于自然图像(如裂缝和航路图)和生物医学图像(如血管、神经和细胞膜等)。这些曲线结构的自动精确分割在计算机视觉和生物医学图像分析中都具有重要意义。例如,道路测绘是自动驾驶和城市规划的先决条件。在生物医学领域,研究表明,特定曲线解剖结构(如视网膜血管和角膜神经纤维)的形态和拓扑结构与各种疾病的存在或严重程度高度相关,如高血压、小动脉硬化、角膜炎、年龄相关性黄斑变性、糖尿病性视网膜病变等。得益于深度学习技术的发展,已经提出了许多对模型架构进行复杂设计或添加额外拓扑约束损失的工作,但基本是在全监督的范式下,需要大规模的良好标注的数据集。然而,收集和标记具有完整注释的大规模数据集非常昂贵和耗时的,特别是对于医学图像,因为它们的注释需要专家知识和临床经验。此外,曲线结构的注释更具挑战性,因为曲线结构细长,多尺度,形状复杂,细节精细,标注单样本曲线结构的时间成本往往数倍甚至数十倍于普通器官或结构。
最近,研究者在降低深度学习模型训练的标注成本方面做了很多努力。例如,半监督学习(SSL)通过将有限数量的带注释的数据与大量未标记的数据相结合来训练模型。虽然有效,但大多数最先进的SSL方法仍然需要大约5%-30%的准确和精确标记的数据来实现大约85%-95%的完全监督性能,这在标记曲线结构时仍然不够划算,而且仍然很耗时。弱监督学习(WSL)试图通过执行稀疏粒度(即点、潦草、边界框)监督,从另一个角度缓解标注问题,并获得了很好的性能。但绝大多数的WSL方法仍然需要对整个数据集(或很大一部分)进行稀疏标记,并且它们是在相对简单的结构(例如,心脏结构或腹部器官)上设计和验证,其假设和先验可能不适用于复杂结构(例如,曲线结构)。
为了解决上述问题,我们提出了一种新的用于曲线结构的WSL分割框架,即YoloCurvSeg。对于曲线结构,标签噪声/错误是不可避免的,一个好的分割方法应该是噪声容忍的。因此,YoloCurvSeg不是只利用标注的像素进行监督,而是通过图像合成巧妙地将弱监督问题转化为全监督或半监督问题。它采用训练好的inpainting网络作为背景生成器,根据可用性选取一个(或多个)噪声骨架,并将其膨胀作为inpainting蒙版,以获得与真实分布紧密匹配的背景。然后对提取的背景进行增强,并与基于空间殖民算法的前景生成器生成的随机仿真曲线相结合,通过多层逐块对比学习合成器从中获得合成数据集。最后,分割器使用合成数据集和未标记数据集(如果可用)执行从粗到精的两阶段分割。其主体框架如图2:
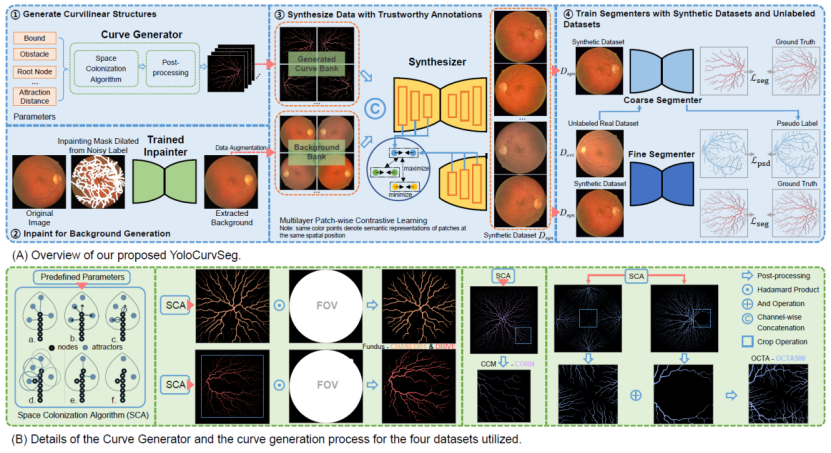
图2. 上图:我们提出的YoloCurvSeg框架,它包括四个主要组件:基于空间殖民算法的曲线生成器,背景生成器,基于多层逐块对比前景-背景融合的合成器,以及两阶段粗到细分割器。下图:曲线生成器的详细信息以及所使用的四个数据集的曲线生成过程。
在多个不同模态的医学图像数据集上实验表明,本工作所提出方法具有以下优势:
(1)图像合成性能优越,可以合成多种与真实曲线结构医学图像数据集分布对齐的合成数据集。图3中可视化了代表性的样本。我们还将合成数据集的强度(直方图)分布与真实数据集进行了对比,如图4所示,在背景和前景方面,合成数据集与真实图像具有很高的强度相似性。从图5的t-SNE可视化来看,合成数据集与真实数据集总体上是一致的,并且混合得很好。
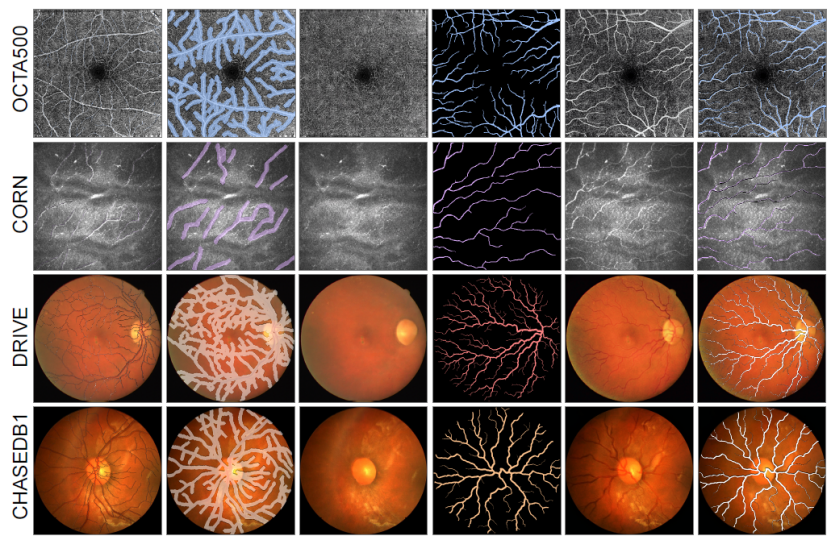
图3. YoloCurvSeg合成数据的可视化。从左到右分别是原始图像叠加含噪骨架标签、膨胀的inpainting蒙版、提取的背景、生成的前景、合成的图像以及合成图像叠加生成的前景。
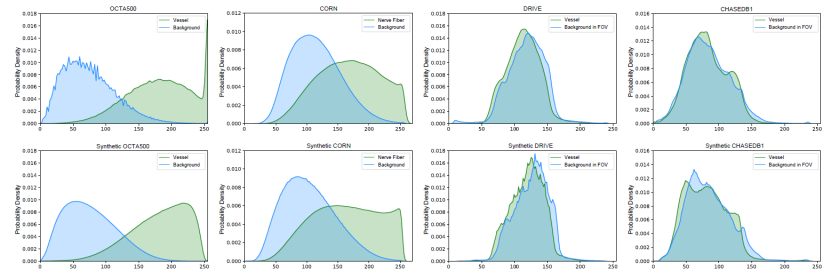
图4. 四个数据集的直方图,包括真实数据(上)和相应的合成数据(下)。
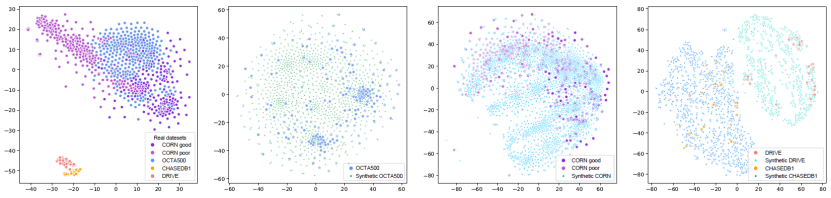
图5. 4个真实和合成数据集的t-SNE可视化。CORN good和CORN poor分别表示CORN的高质量图像子集和低质量子集。
(2)与主流和最先进的弱监督分割方法和噪声标签学习方法的对比中取得大幅度的性能领先。无论是在标注了整个数据集还是单个样本的设定下,YoloCurvSeg均取得可用的、接近全监督的性能表现,在四个数据集上的多个指标(包括DSC、ASSD等)相对次优方法均取得显著提升,量化结果和可视化结果分别展示在表3-5和图6中。
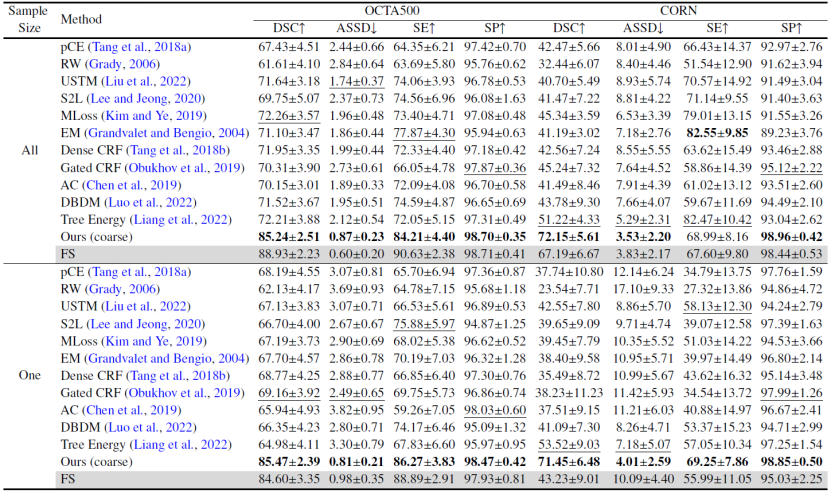
表3. 与现有WSL方法在OCTA500和CORN数据集上的比较。最好的结果用粗体突出显示,次好的结果用下划线突出显示。FS表示全监督学习。
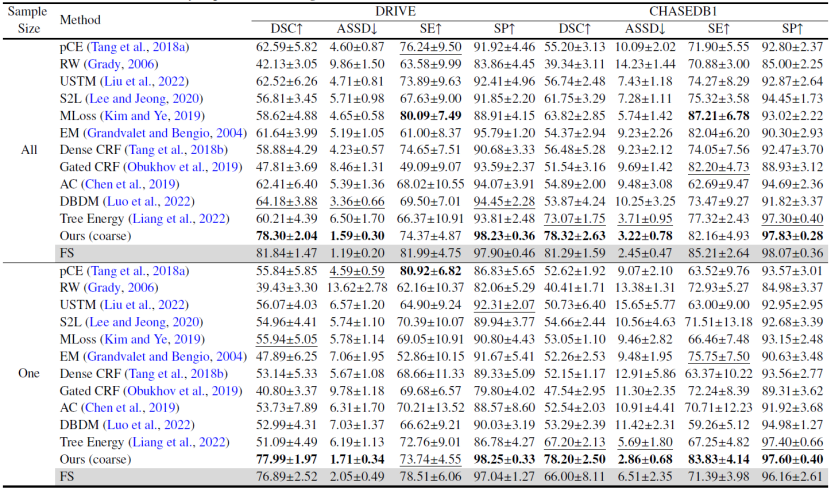
表4. 与现有WSL方法在DRIVE和CHASEDB1数据集上的比较。最好的结果用粗体突出显示,次好的结果用下划线突出显示。FS表示全监督学习。
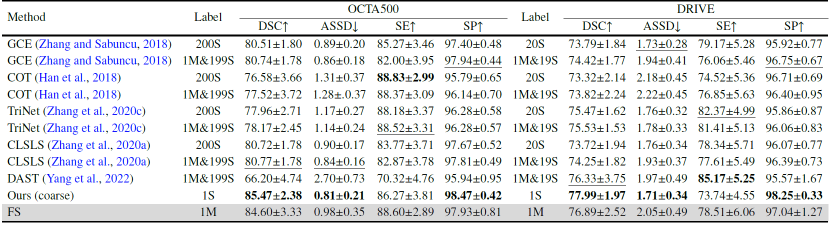
表5. 与噪声标签学习方法在OCTA500和DRIVE上的比较。M和S分别表示全掩模和噪声骨架。FS表示全监督学习。最好的结果用粗体突出显示,次好的结果用下划线突出显示。
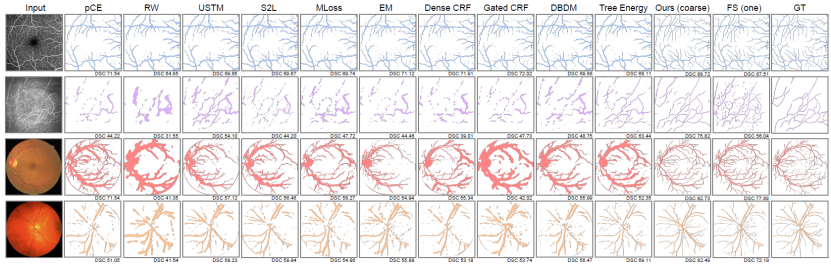
图6. 我们的粗分割器(未进行无标注真实数据的额外训练)和其他SOTA WSL方法在单个标注设置下的代表性结果的定性可视化对比。
(3)所提出的框架具有噪声鲁棒性、样本不敏感性和易于扩展到其他各种曲线结构。为了验证YoloCurvSeg对选定的单个稀疏标记样本的鲁棒性,我们从每个数据集中随机选择10个样本,并将其性能与在相同样本上训练的完全监督模型进行比较。如图7所示,YoloCurvSeg在几乎所有情况下都超过了完全监督,并且提供了与图像/注释质量解耦的高度稳定的性能,尽管如此,完全监督模型的性能会产生很大的波动。除了稳健性,YoloCurvSeg的预测也有较小的方差。这两个方面都表明,YoloCurvSeg对样本不敏感,可以降低选择错误样本进行标记的风险。
为了研究噪声骨架的完整性对分割性能的影响,我们对骨架进行了部分擦除分析实验。由于眼底图像中小血管与背景对比度较低,眼底图像很可能缺少/遗漏标注。因此,我们从DRIVE数据集中选择两个样本,并擦除一些小血管的噪声骨架标签,如图8所示。具体来说,我们在25号和38号样本上分别删除了12.55%和9.66%的标注区域。从图中,我们可以清楚地看到噪声骨架上的擦除区域以及对提取的背景图像和合成图像的影响。在具有完整噪声骨架注释的两个样本上,分割模型的性能指标(DSC, ASSD)分别为(77.99,1.71)和(77.74,1.59)。在擦除部分噪声骨架并合成相应的新训练集后,分割模型的性能指标为(78.06,1.83)和(78.11,1.40),擦除前后的波动较小,表明了所提方法的鲁棒性。
同时,为了进一步证明提出方法的可扩展性,我们对x射线冠状动脉造影数据集(即DCA1)进行了额外的合成和分割验证分析。合成和分割结果均证明了方法在该数据集上的成功迁移。其他类似的和潜在可迁移的场景包括细胞膜、裂缝、道路(航拍图像)和叶脉分割等。
最后,为了更好地说明我们的方法在实际临床场景中节省时间的优势,我们在图10中绘制了所有评估方法(包括所有WSL方法、NLL方法和YoloCurvSeg)在单样本和全样本条件下的分割性能和标注时间成本。我们的方法在所有四个任务中以最低的标注时间成本(< 0.3%的FS)实现了最高的分割性能(≥97%的FS)。
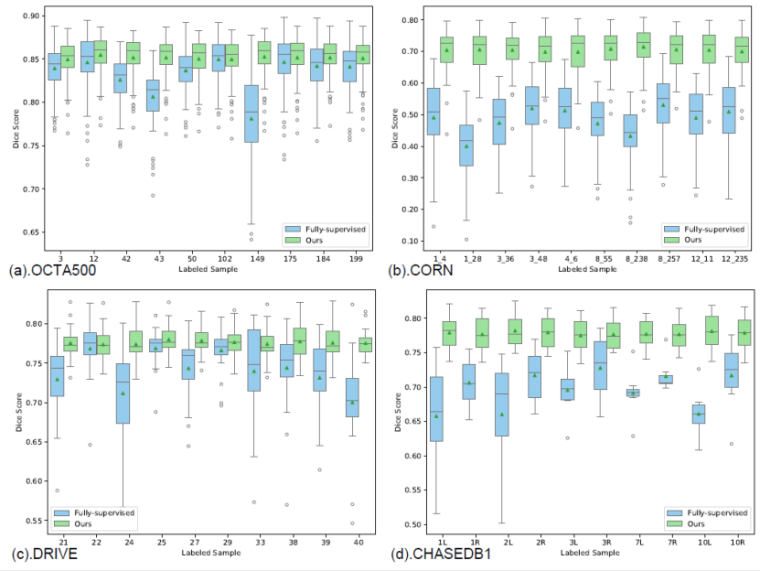
图7. YoloCurvSeg(粗略阶段)在单样本设定下给定不同样本及其标注的性能。
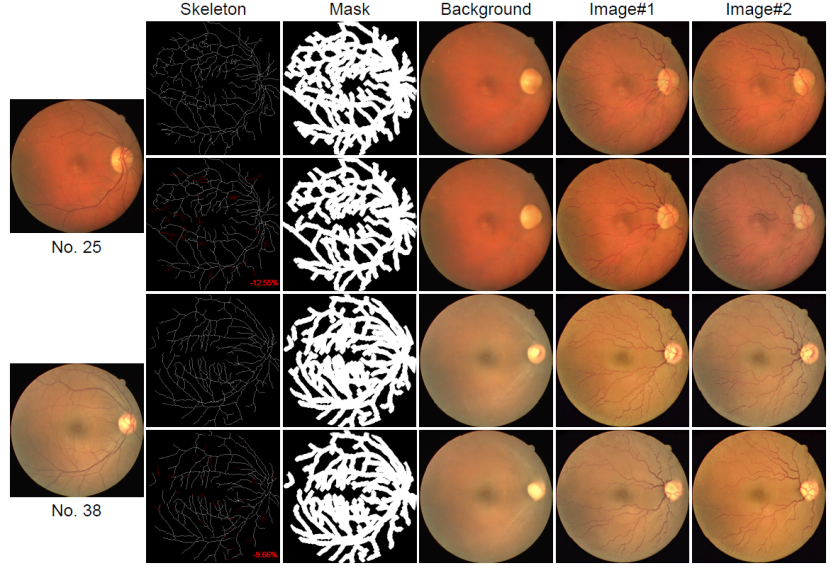
图8. 遗漏标注敏感度相关实验图。对来自DRIVE数据集的两个代表性样本进行了inpainting掩模、提取背景和合成图像的可视化,这些样本在噪声骨架标签中具有不同程度的完整性。在每个噪声骨架中,红色表示缺失/擦除部分,红色数字表示遗漏的百分比。

图9. DCA1数据集合成数据的可视化。从左到右分别是原始图像、全监督标签、噪声骨架、提取的背景和两个合成样本图像。
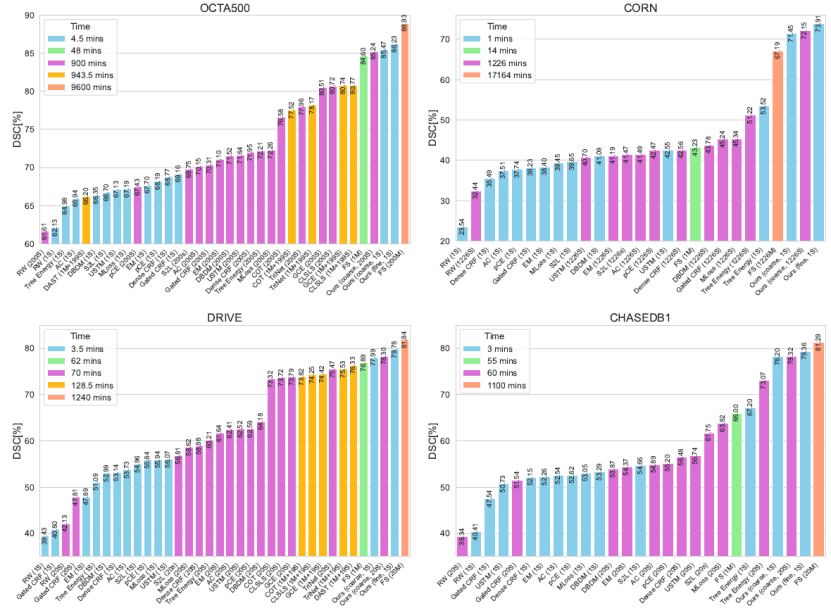
图10. 性能-标注成本权衡图。所有弱监督分割和噪声标签学习方法以及单样本及全样本完全监督(FS)设置下的分割精度(DSC)与标注时间可视化。括号中表示使用的标签数量和类型,M和S分别代表全监督标签和噪声骨架。
03
作者简介
通讯作者简介
唐晓颖,南方科技大学助理教授、副研究员、博士生导师,深圳市海外高层次引进人才、深圳市优青,国家重点研发计划课题、国家重点研发计划青年科学家项目、国家自然科学基金面上项目、国家自然科学基金青年项目等项目负责人,MICCAI本地主席/领域主席/分会场主席,Neural Networks期刊副主编,IEEE高级会员等。主要从事医学影像分析、AI辅助诊断、计算机视觉等领域的研究。发表SCI期刊论文58篇(JCR一区34篇)、长篇学术会议论文90篇、书本章节2篇。
第一作者简介
林立,香港大学、南方科技大学联培博士研究生,研究方向为医学图像处理与分析、数据高效学习、联邦学习等。在唐晓颖教授和Kenneth K. Y. Wong教授的指导下,在医学影像权威期刊MedIA、IEEE TMI及相关领域知名会议ICCV、MICCAI、MIDL、ISBI等发表论文20余篇。
04
基金资助
该工作得到深圳市基础研究计划项目JCYJ20190809120205578;国家自然科学基金62071210;深圳市科技计划项目RCYX20210609103056042;深圳市基础研究计划项目JCYJ20200925153847004;深圳市科技创新委员会项目KCXFZ2020122117340001的资助。
05
相关链接
Github链接:
https://github.com/llmir/YoloCurvSeg
文章链接:https://www.sciencedirect.com/science/article/abs/pii/S1361841523001974
https://arxiv.org/abs/2212.05566
在CVer微信公众号后台回复:YoloCureSeg,可以下载本论文pdf和代码
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集医疗影像和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-医疗影像或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球▲点击上方卡片,关注CVer公众号