点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:蔡彦成(源:知乎,已授权)| 编辑:CVer公众号
https://zhuanlan.zhihu.com/p/652557366
大家好!我是蔡彦成https://cademic.html,目前是即将入学的剑桥大学一年级博士生。
我很高兴向大家介绍我于复旦大学陈涛老师组完成的第一作者研究工作Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-free One-Stage Detectors,该文章已经被顶级期刊IEEE Transactions on Image Processing (T-IP)接收。

文章链接:
https://ieeexplore.ieee.org/document/10231122
在CVer公众号后台回复:BFDA,可下载本论文pdf
在进行跨域目标检测和行人检测任务时,研究人员针对诸如 Faster RCNN 等双阶段检测器,提出了许多有效的算法框架,例如实例级特征对齐等。然而,从实际应用的角度来看,像 YOLOv5 这样的单阶段检测器具备更快的处理速度。然而,由于单阶段检测器实例级特征难以获得,其跨域对齐存在前景-背景错误对齐问题,即【源域图像中的前景特征与目标域图像中的背景特征被错误地对齐】或【源域背景与目标域前景被错误地对齐】。下图展示了前景-背景错误对齐问题。
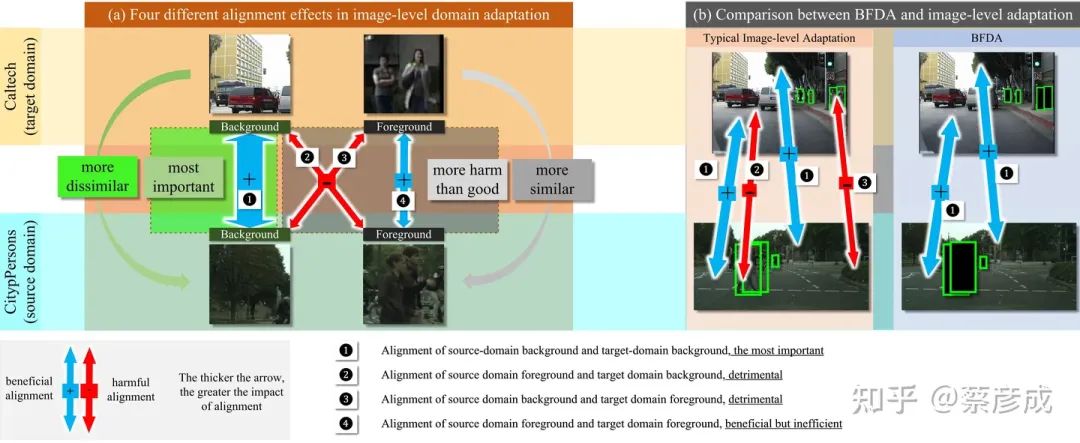
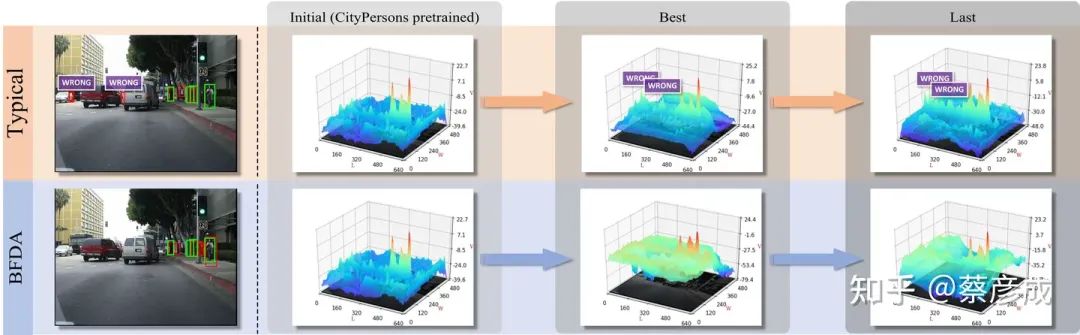
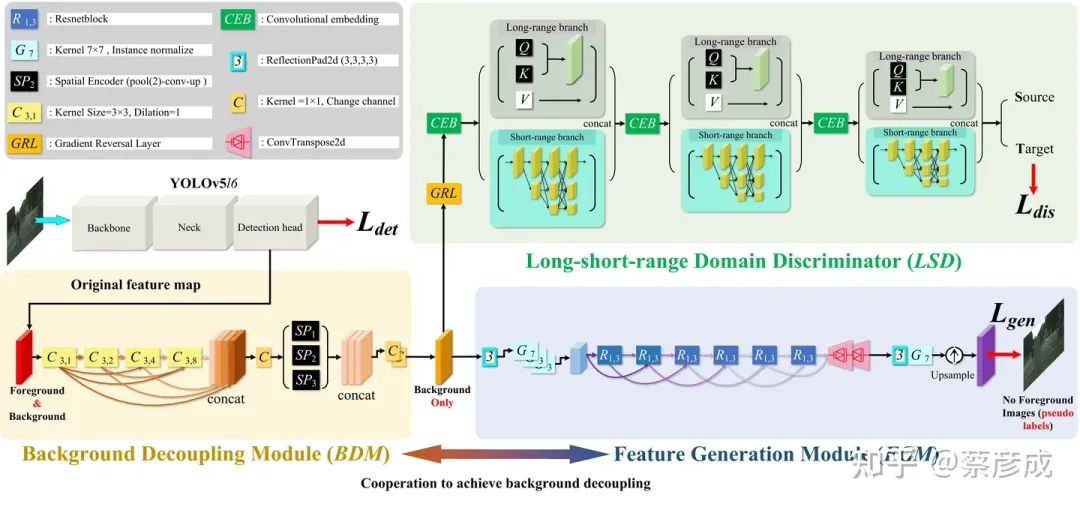
为了解决这一问题,我们系统地分析了前景和背景在图像级跨域对齐中的重要性,并认识到在图像级跨域对齐中,背景起着更为关键的作用。因此,本文提出了一种新颖的框架,即背景聚焦分布对齐(Background-Focused Distribution Alignment,BFDA),来训练域自适应的单阶段行人检测器。具体来说,BFDA 首先将背景特征与整个图像特征图解耦,然后通过一种长短程域判别器将它们进行对齐。
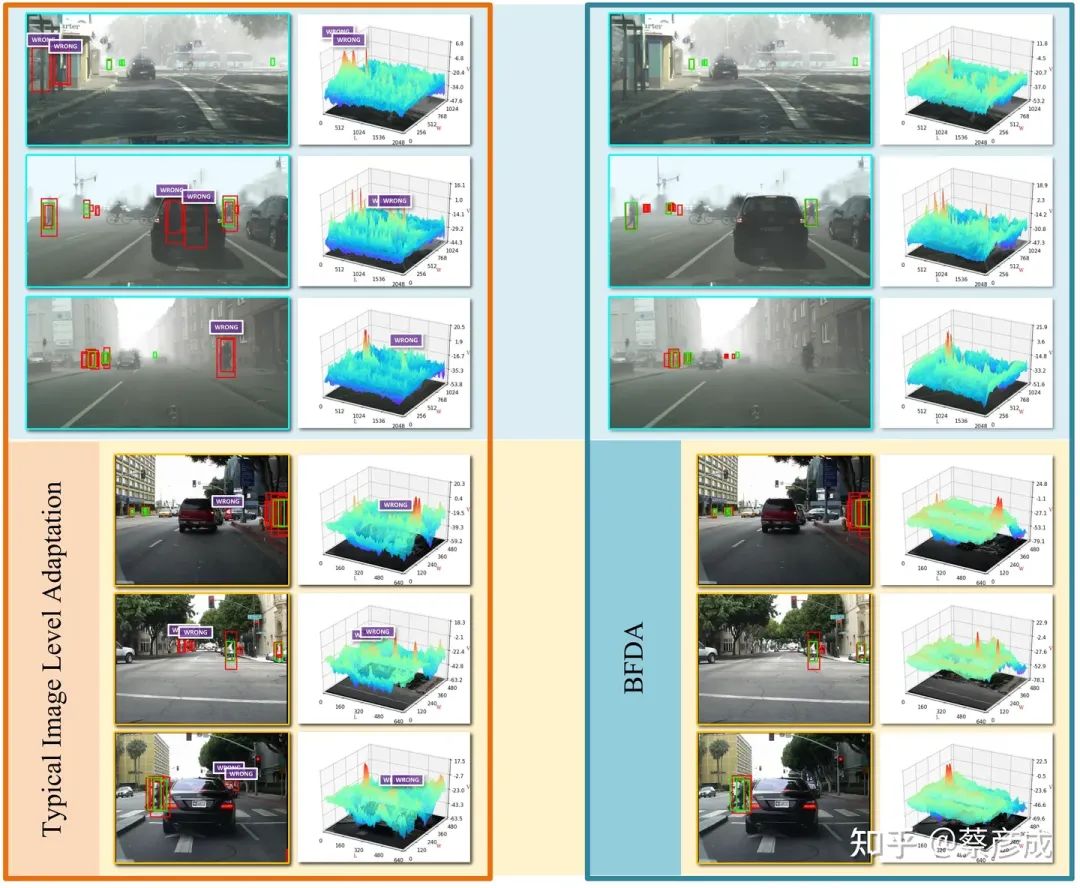
大量实验表明,与主流领域适应技术相比,BFDA 显著增强了单阶段和双阶段检测器的跨域行人检测性能。此外,通过采用高效的单阶段检测器(YOLOv5),BFDA在NVIDIA Tesla V100上可以达到217.4 FPS(640×480像素)(是现有框架FPS的7~12倍),这对于实际应用具有非常重要的意义。
我们的贡献总结如下:
(1)我们的研究揭示了单阶段行人检测器在执行图像级特征对齐时所面临的前景-背景特征错误对齐问题。此外,我们发现在实现跨域行人检测时,确保背景特征的域间一致性是至关重要但未被充分重视的方面。据我们所知,我们是第一个提出在跨域检测中专注于背景对齐的研究。
(2)我们提出了一种新的背景聚焦跨域行人检测框架,包括三个关键模块:背景解耦模块(BDM)、特征生成模块(FGM)和基于并行Transformer-CNN的长短程域鉴别器(LSD)。这一框架通过将背景特征从原始特征图中解耦,实现了纯背景特征对齐,从而有效缓解了前景-背景特征不匹配问题。
(3)我们使用BFDA在跨域行人检测上进行了实验,结果表明所提出的BFDA在单阶段检测器YOLOv5上能够实现最先进的性能。
非常感谢我的共同作者们的贡献:
Bo Zhang, Baopu Li, Tao Chen, Hongliang Yan, Jingdong Zhang, Jiahao Xu
在CVer公众号后台回复:BFDA,可下载本论文pdf
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集图像分割和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-图像分割或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看