文章目录
本节已全部更新完成
1.RabbitMq是如何实现消息路由的
1.1 工作流程
RabbitMq:一个基于AMQP协议实现的分布式消息中间件
AMQP的工作机制如下图所示 :

首先生产者把消息发送到RabbitMQ Broker上的Exchange交换机上,Exchange交换机会把收到的消息根据路由规则分发给绑定的队列,最后再把消息投递给订阅了这个队列的消费者从而去完成消息的异步通信。
其中Exchange交换机就可以去定义这个消息的路由规则,将消息去路由到指定的队列,然后队列就是消息的载体,每个消息就可以根据路由规则路由到一个或者多个队列中。
1.2 路由策略
完成RabbitMq路由的核心组件是Exchange交换机,而消息的路由又是由Exchange类型(交换机类型)和Binding决定的。
Binding是表示在队列和交换机之间的一个绑定关系,那么每个绑定关系会存在一个BindingKey,通过这种方式相当于是在Exchange交换机中建立了一个路由关系表,在每个生产者发送消息的时候,需要声明一个RoutingKey(路由键),Exchange拿到RoutingKey之后,根绝RoutingKey和路由表里面的BindingKey进行匹配,而匹配的规则是通过Exchange类型来决定的
在 RabbitMq中默认有四种类型,常用的有三种:
- Direct
- Fanout
- Topic
Direct Exchange
其中Direct叫做直连,也就是完整的匹配方式,他需要Routing Key和Binding Key完全一致,相当于是点对点的发送,原理如下图所示:

如果发生了Routing Key为spring的消息,只有一个队列能接受到消息
Topic Exchange
Topic叫做主题,那么这种方式是通过设置通配符来动态匹配,类似于正则,就是用Routing Key去匹配Binding Key,Binding Key支持两个通配符:
- #号代表0个或多个单词
- *号代表匹配不多不少一个单词
另外Binding Key是用 点隔开两个单词,所以*和#就相当于是正则表达式的一个作用

我们有4个队列绑定到 Topic类型的交换机中,而且使用的是不同的绑定键,如上图所示,那么如果我们发送routing key为“junior.abc.jvm”的消息,那么只有第一个队列可以收到。
如果我们发送routing key为“senior.netty”的消息,那么第二个队列第三个队列都可以收到。
Fanout Exchange
Fanout叫做广播,这种方式是不需要设置Routing key的,而且他会把消息广播给绑定到当前Exchange上的所有队列上,如下图所示:

我们只需要发送消息到Fanout的Exchange上,那么3个队列都会收到消息。
目前主流的分布式中间件有:
- Rabbit Mq
- Kafka
- Rocket Mq
2.谈谈你对时间轮的理解
2.1 什么是时间轮
时间轮:一种用来存储定时任务的环状数组。
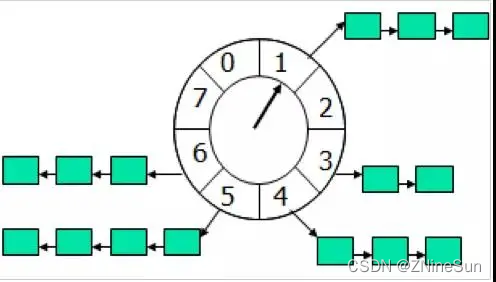
他的工作原理和钟表的表盘类似,他有两个部分组成:
- 环形数组
- 遍历环形数组的指针
首先要定义一个固定长度的环形数组,然后数组的每一个元素代表一个时间刻度,假设每个刻度之间的间隔是1s,那么长度为8s的数组就代表8秒钟。
然后就是需要有一个指针,那么这个指针是按照顺时针的方向,无限的循环这个数组,每隔一个最小的时间单位就前进一个数组的索引,那么这个指针完整的转一圈的话就代表8秒钟,转一圈的话就代表16秒钟,假设从0点0分0秒开始,转一圈之后就到了0点0分9秒
2.2 时间轮的工作原理
环形数组里面的每一个元素,都是用来存储定时任务的容器,当我们向时间轮里添加一个定时任务的时候,我们会根据定时任务的执行时间计算他所存储的数组下标,当然会在某个时间刻度上会存在多个定时任务,那么这个时候就会采用双向链表的方式进行存储。
当我们的指针指向某个数组的时候,就会把这个数组中存储的任务取出来,然后就遍历这个链表,逐个去运行这个链表中的任务
那么如果某个定时任务的执行时间,大于环状数组的长度,一般就可以使用一个圈数来表示该任务的延时执行时间,比如一个第16秒执行的任务,那就意味着这个任务应该在第2圈的数组下标为0的时候去执行。
2.3 时间轮优缺点分析
使用时间轮的方式来管理多个定时任务的好处有很多,我认为有两个比较重要的优点:
- 1.可以减少定时任务添加和删除的时间复杂度,提升性能
- 2.可以保证每次执行定时任务都是o(1)的复杂度,在定时任务执行密集的情况下,性能优势十分明显
当然时间轮也有缺点:对于执行时间非常严格的任务,时间轮不是很合适,因为时间轮算法的精度取决于最小时间单元的粒度,假设以1秒为时间刻度的话,那么小于1s的任务就无法被时间轮调度
同时时间轮算法在很多框架中都有用到,比如说:Dubbo,Netty,Kafka等。
3.什么是幂等?如何解决幂等性问题
3.1 什么是幂等
幂等是一个数学上的概念,而在计算机编程领域中幂等是指一个方法任意多次执行所产生的影响均与一次执行的影响相同。
简单来说:一个逻辑即使被重复执行多次,也不影响最终结果的一致性。
之所以要考虑幂等性问题,主要是因为在网络通讯中有两种行为都有可能导致我们的接口被重复执行:
- 1.用户重复提交或者用户的恶意攻击会导致重复执行
- 2.在分布式系统中,为了去避免数据的丢失,采用的超时重试机制
所以在我的程序设计中对于数据变更操作的接口都要去保证接口的幂等性,而幂等性的核心思想,其实就是保证这个接口的执行结果只影响一次,后续再次调用,也不能对数据产生影响。
所以基于这个需求呢,如何去解决幂等性呢?
3.2 如何解决幂等性问题
解决幂等性问题的方法有很多,下面我分享一下一些常用的解决方案:
- 1.使用数据库的唯一约束来实现幂等。
比如说对于数据插入的场景而言,假设我们要创建一个订单,因为订单号肯定是唯一的,所以如果我们多次去调用数据库的唯一约束,他就会产生异常,从而去避免一个请求创建多个订单的问题。
- 2.使用redis提供的setNX
比如说我们对于MQ的消息的场景,我们要去避免MQ重复消费,从而导致数据多次被修改的问题,可以在接受MQ消息的时候把这个消息通过setNX写入到redis中,一旦这个消息被消费之后,我们就就不会被再次消费
- 3.使用状态机来实现幂等,所谓状态机是指一条数据的完整的运行状态的转化流程
比如说订单的状态,因为他的状态只会向前变更,所以多次修改同一条数据的时候一旦状态发生改变,那么这条数据修改造成的影响也只会发生一次。
除了以上三种方法之外,我们还可以通过token机制或者去增加重表的方法来实现幂等。
但是无论使用何种方法,无非也就是两种思路,要么就是接口只允许调用一次,比如说唯一约束、基于Redis的锁机制,要么就是对数据的影响只会发生一次,比如说悲观锁、乐观锁等等。
4.在秒杀场景中,常见的限流算法有哪些
所谓限流就是指限制流量请求的频次,它主要是在我们的高并发的情况下,用于去保护系统的一种策略,主要是避免在流量高峰的时候导致系统崩溃,从而造成系统不可用的问题。
实现限流的常见算法有4种:
- 计数器限流算法
- 滑动窗口限流算法
- 漏桶限流算法
- 令牌桶限流算法
下面我给大家详细介绍一下每种算法的基本原理
4.1 计数器限流算法
这种算法一般用在单一维度的访问频率限制上
比如说短信验证码每隔60s发送一次,或者说接口的调用次数等等。
他的实现方法十分简单:每调用1次就会加1,处理结束以后就会减1
4.2 滑动窗口限流算法
其本质上也是一种计数器,只不过是通过以时间为维度的可滑动的窗口设计来减少临界值带来的并发超过阈值的问题,那么进行数据统计的时候,我们只需要统计这个窗口内每个时刻的访问量就可以了,比如说Spring Cloud中的Hystrix以及Spring Cloud Alibaba中的Sentinel都是采用滑动窗口来实现的。
4.3 漏桶限流算法
他是一种恒定速率的限流算法,不管他的请求量是多少,服务端的处理效率都是恒定的,比如说基于MQ来实现的生产者和消费者模型其实就是一种漏桶限流算法
4.4 令牌桶限流算法
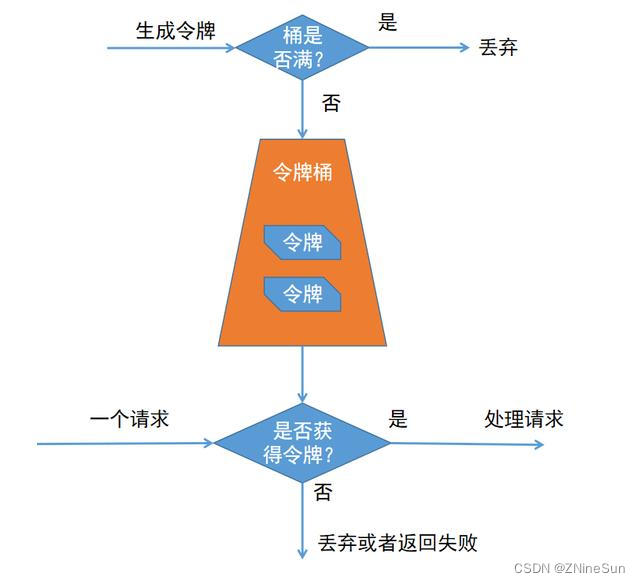
相对于漏桶限流算法来说,他的核心思想是令牌桶以恒定速率去生成令牌,保存到令牌桶里,桶的大小是固定的,当我们的令牌桶满了以后就不会在生成令牌,所以每个客户请求进来以后就必须要到令牌桶中去获取一个令牌才可以访问,否则就会排队等待。
在流量低峰的时候,令牌桶就会出现堆积,因此当出现限流高峰的时候,我们需要有足够多的令牌可以获取,因此令牌桶他能够允许瞬时流量的处理,比如说我们网关层面的限流或者是接口层面的限流都可以使用令牌桶的算法。像Google的Guava和Redssion的限流都是使用了令牌桶的算法。
限流的本质是实现系统的保护,最终选择什么样的算法,一方面取决于统计的精准度,另一方面考虑限流维度和场景的需求。
5.Spring中的Bean是线程安全的吗?
先说一下答案:
其实Spring中的Bean是否线程安全跟Spring本身无关,Spring框架中会提供很多线程安全的的策略,因此Spring容器中的Bean本身也不具备线程安全的特性。
要彻底理解上面这个结论,我们首先要知道Spring中的Bean是从哪里来的,在Spring容器中,除了很多Spring内置的Bean以外,其实其它Bean都是我们自己通过Spring配置来声明的,然后由Spring容器来进行统一的管理和加载。
我们在Spring声明配置中通常会配置以下内容:
- class(全类名)
- id (Bean的唯一标识)
- scope(作用域)
- lazy-init (是否延时加载)
之后呢,Spring容器会根据这些配置的内容,使用对应的策略来进行创建实例,因此Spring容器中的Bean,其实都是根据我们自己写的类来创建的实例。
Spring中的Bean是否线程安全,跟Spring容器无关,只是交给Spring容器托管而已,那么在Spring容器中什么样的Bean会存在线程安全问题呢?
在解答这个问题之前,我们得先回顾一下Spring Bean的作用域。
- prototype(多例Bean)
每次getBean的时候都会创建一个新的对象 - singleton(单例Bean)
在Spring容器中只会存在一个全局共享的实例
根据作用域的定义,多例Bean每次都会创建新的实例,也就是说线程之间不存在Bean共享的问题,因此多例Bean是不存在线程安全问题的。
而单例Bean是所有线程共享一个实例,因此可能会存在线程安全问题。但是呢,单例Bean又分为:
- 无状态Bean
在多线程操作中只会对Bean的成员变量进行查询操作,不会修改成员变量的值,这样的Bean成为无状态Bean,所以无状态的单例Bean不存在线程安全问题。 - 有状态Bean
多线程操作中,如果需要对Bean中的成员变量进行数据更新操作,这种Bean成为有状态Bean,而有状态Bean可能存在线程安全问题。
在Spring中,只有有状态的单例Bean才会存在线程安全问题,我们在使用Spring的过程中经常会使用到有状态的单例Bean,如果我们经常遇到线程安全问题,我们又该如何处理呢?
- 1.修改Bean的作用域,将"singleton"改为"prototype"
- 2.避免定义可变的成员变量
- 3.在类中定义ThreadLocal的成员变量,并将需要的可变成员变量保存在ThreadLocal中,因为ThreadLocal本身就具备线程隔离的特点,这就相当于为每个线程提供了一个独立的变量副本,每个线程呢只需要操作自己的线程变量副本,从而解决线程安全的问题。
6.谈谈你对Spring Bean的理解
回答这个问题,我们可以从三个方面来回答:
- 1.什么是Spring
- 2.定义Spring Bean有哪些方式
- 3.Spring容器是如何加载Bean的
6.1 什么是Spring Bean
Spring Bean是Spring中最基本的组成单元,Spring官方文档对Bean的解释是:
In Spring, the objects that form the backbone of your application and that are managed by the Spring IoC container are called beans. A bean is an object that is instantiated, assembled, and otherwise managed by a Spring IoC container.
翻译过来就是:
在 Spring 中,构成应用程序主干并由 Spring IoC 容器管理的对象称为 bean。bean 是由Spring IoC 容器实例化、组装和管理的对象。
根据官方的定义呢,我们可以提取出来以下信息:
- 1.Bean是对象,一个或多个不限定;
- 2.Bean是托管在Spring中的一个IOC容器中;
- 3.我们的程序是由一个一个的Bean组成的
Spring Bean是通过声明式配置的方式来定义Bean的,所有的Bean是需要前置的依赖或者参数。
Spring启动以后,会解析这些声明好的配置内容,那么我又该如何去定义呢?
6.2 定义Spring Bean有哪些方式
Spring Bean定义它的配置有三种方式:
1.基于XML的方式来配置
这种配置方式主要适用于以下两场景:
- 1.Bean实现类来自第三方的类库,比如DataSource等;
- 2.需要定义命名空间的配置,如:Context,aop,mvc等;
2.基于注解扫描的方式来配置
这种配置方式主要适用于在开发中需要引用类,如Controller、Service、Dao等。
Spring提供了四个注解:
- 1.@Controller,声明为控制层组件的Bean
- 2.@Service,声明为业务逻辑层组件的Bean
- 3.@Repository,声明为数据访问层组件的Bean
- 4.@Component,对组件的层次难以定位的时候使用
3.基于Java类的配置
该方式主要适用于以下两类场景:
- 1.需要通过代码控制对象创建逻辑的场景
- 2.实现零配置,消除XML配置文件的场景
使用基于类的配置需要以下步骤:
- 1.首先在BeanConfiguration类上配置@Configuration注解,表示将BeanConfiguration这样的一个类定义为Bean的元数据
- 2.在方法上使用@Bean注解,这个方法默认就是Bean的名称,那么方法的返回值就是Bean的实例
- 3.通过AnnotationConfigApplicationContext或子类来启动Spring容器,从而加载这些声明好的注解的配置。
6.3 Spring容器是如何加载Bean的
上面我们提到了,无论是基于注解,还是基于xml,或者是基于properties配置文件的方式来来存储对象所需要的一些必要的信息(如对象的属性,方法等),我们将这些创建对象所需要的必要信息称为配置元信息。
Spring会将这些信息都转化为一个叫做BeanDefination的对象。那么BeanDefination中几乎保存了所有的配置文件中声明的内容。而BeanDefination放入一个Map结构中,以beanName作为Key,以BeanDefination对象作为value,之后Spring容器会根据beanName找到对应的BeanDefination,然后再去选择具体的创建策略。
7.Spring为何需要三级缓存解决循环依赖而不是二级缓存
7.1什么是循环依赖
指循环引用,是两个或多个Bean相互之间的持有对方的引用
在代码中,如果有两个或多个Bean之间持有对方的引用的话,Spring就会对它进行一个注入赋值,也就是自动给属性赋值,那么Spring给属性赋值的时候,将会导致死循环。
7.2 哪些情况会出现循环依赖
循环依赖有三种形态:
1.相互依赖

2.三者之间的依赖

3.自我依赖

7.3 Spring如何解决循环依赖
Spring解决循环依赖的方法就是通过三级缓存来实现
- 三级缓存:存放的是一个对象的半成品
- 二级缓存:存放的是一个提前暴露出来的对象
- 一级缓存:存放的是一个完全初始化的对象
当我们构建a的时候,a会作为一个半成品放到三级缓存中,此时发现a中有一个b属性需要注入,这个时候就会去Spring容器中找有没有b属性,如果有b属性就直接拿出来;如果没有,这个时候就会再去初始化b类。
在初始化b时,它和a一样,也要放到三级缓存中,但是呢发现初始化b时需要a属性,此时还是一样会去Spring容器中去找,会发现在三级缓存中有a,于是就把a从三级缓存提前暴露到二级缓存,交给b去做一个注入,这时a注入好了之后,b就可以从三级缓存放到一级缓存了。
同时我们最开始创建b的原因就是a需要这个b,所以说,二级缓存中的a,就拿到了放在一级缓存里的b,这样,Spring就很完美的解决了循环依赖问题。
7.4 Spring中哪些情况下不能 解决循环依赖问题
第一种情况就是多例Bean通过setter方式注入
第二种 情况是构造器注入的Bean
第三种情况是单例的代理Bean通过setter注入
第四种情况是设置了@DependsOn的Bean
8.简述Spring MVC的执行流程
SpringMVC的详细执行流程分为三个阶段:
- 1.配置阶段
- 2.初始化阶段
- 3.运行阶段

8.1 配置阶段
配置阶段主要是完成对xml的配置和注解的配置。
具体步骤如下:
从web.xml开始,配置DispatchServlet的url匹配规则,和Spring主配置文件中的一个加载路径(contextConfigLocation=‘classpath:applicationContext’)。
然后呢,配置注解,比如说@Controller,@Service,@Autowired以及RequestMapping。
8.2 初始化阶段
主要是去加载并解析配置信息以及IOC容器,还有DI操作和HandlerMapping的一个初始化,具体步骤如下:
web容器启动以后会由web容器自动调用DispatchServlet的init()方法,在init()方法中,会初始化IOC容器,IOC容器其实就是一个Map,紧接着根据配置好的扫描包的路径然后扫描出相关的类,并且使用反射对它进行实例化,然后缓存到IOC容器中,缓存之后,Spring容器再次迭代,扫描IOC容器的实例,给需要自动赋值的属性自动赋值。
哪些属性需要自动赋值呢?
比如加了@Autowired的属性
最后在去读取@RequestMapping的注解,获取它请求的URL,然后将URL和Method建立一个一对一的映射关系,并且缓存起来,简单概括下来就是:
缓存在一个Map中,他的key就是url,它的value是Method。
8.3 运行阶段
运行阶段在Spring启动以后,等待用户请求,然后完成内部的调度,并且响应结果。具体步骤如下:
用户在浏览器中输入url之后,web容器会接受到用户的请求,web容器会自动调用doGet()或者doPost()方法,然后从doGet()或者doPost()方法中,可以获得两个对象,分别是request对象和response对象,通过request对象,可以获得用户请求过来的信息,通过response对象,可以往浏览器输出后台响应的结果
根据request中获得的请求url,从HandlerMapping中找到url对应的Method,然后接着利用反射去调用方法,然后将方法的返回结果作为响应结果返回给浏览器。
最后用户就可以看到我们最终的响应结果
9.简述Spring Aop原理
Spring AOP大致分为四个阶段:
- 创建代理对象
- 拦截目标对象
- 调用代理对象阶段
- 调用目标对象阶段
9.1 创建代理对象阶段
在Spring中创建Bean的实例都是从getBean方法开始,在实例创建之后Spring容器会根据AOP的配置去匹配目标类的类名,看目标类是否满足切面规则,如果满足切面规则,就会调用ProxyFactory创建Bean,并且缓存到IOC容器中,然后根据目标对象自动选择不同的代理策略:
- 如果目标类实现了接口,Spring会默认使用JDK Proxy
- 如果目标类没有实现接口,Spring会默认选择Cglib Proxy
当然我们也可以通过配置去强制Spring使用Cglib Proxy
9.2 拦截目标对象阶段
当用户调用目标对象的某个方法的时候,就会被一个叫做AopProxy的对象拦截,那么Spring将所有的调用策略封装到了这个对象中,它默认实现了一个叫做InvocationHandler的接口,也就是调用代理对象的外层拦截器,在这个接口的invoke()方法中,会触发MethodInvaocation的proceed()方法,在proceed()方法中,会按照顺序执行符合AOP规则的拦截器链。
9.3 调用代理对象阶段
Spring Aop拦截链中每个元素都会被命名为MethodInterceptor,也就是切面中的Advice通知,这个通知是可以用来回调的,简单的理解就是生成的代理Bean方法,也就是我们常说的被织入的代码片段,这些被织入的代码片段会在该阶段被执行。
9.4 调用目标对象阶段
MethodInterceptor接口也有一个invoke()方法,那么在MethodInterceptor的invoke()方法中,会触发对目标对象的调用,也就是去反射调用目标对象的方法。
下面说几个重要的名词:
- 代理对象:就是由Spring代理策略生成 的对象
- 目标对象:就是我们自己写的业务代码
- 织入代码:在我们自己写得业务代码中增加的代码片段
- 切面通知:封装织入代码片段的回调方法
- MethodInvocation:负责执行拦截器链,在proceed()方法中去执行
- MethodInterceptor:负责执行织入片段的代码,在Invoke()方法中去执行
10.单线程下HashMap的工作原理
HashMap是基于Hash表对Map接口的实现类,它的特点是访问数据速度快,并且不是按照顺序来遍历。
HashMap提供所有的可选的映射操作,但是不能保证映射的顺序不变,并且允许插入空值和空键,HashMap本身并不是线程安全的,当存在多线程同时写入的时候,可能会导致数据不一致的情况,
10.1 HashMap中的关键属性
要透彻理解HashMap原理,首先我们要对以下几个关键的属性有一个基本的认识
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
transient int size;
transient int modCount;
上面是HashMap的源码片段
- LOAD_FACTOR:负载因子,默认值0.75,表示在扩容前,HashMap空间填满程度的边界
- THRESHOLD:记录HashMap所能够容纳的键值对边界,计算规则是:负载因子*数组长度
- size:用来记录HashMap实际存在的键值对的数量
- modCount:用来记录HashMap内存结构发生变化的次数
- DEFAULT_INITIAL_CAPACITY:HashMap的默认容量值,默认是16
HashMap采用的是数组+链表+红黑树(JDK 1.8)的一个存储结构
HashMap的数组部分称为Hash桶,数组元素保存在一个叫做table的属性中,当链表长度大于8时,链表的数据将会以红黑树的形式进行存储,当链表的长度降到6时,为链表形式存储
每个Node结点保存了用来定位数组索引位置的hash值和key、value以及链表指向的下一个Node结点。
Node类是HashMap的内部类,它实现了Map.Entry接口,他的本质其实可以简单理解成就是一个键值对。
10.2 HashMap的工作原理
当我们向HashMap插入数据时,首先要确定Node在数组中的位置。
如何去确定Node的位置呢?
我们以key为“e”的字符串为例,HashMap首先会调用hasCode()方法,获取key的hashCode值为h,然后对h进行一个高位运算,将h右移16位,取得h的高16位,与h的低16位进行异或运算,最后得到h的值,然后在于table.length-1进行与运算,得道对象的保留位,最终获取数组下标。
其实上面的操作就是求模取余法,但是乘除运算效率比较低,所以才会有上面的位操作运算,最终计算的效果和 h = h a s h C o d e % ( t a b l e . l e n g t h − 1 ) h=hashCode\%(table.length-1) h=hashCode%(table.length−1)这样可以保证数组下标不越界。