IQR方法
基于四分位数:使用数据的第一四分位数(25%)和第三四分位数(75%)来计算。
对称:相对于中位数对称地考虑上下界。
受极端值影响:如果数据中包含极端值,IQR可能会被拉得很大,导致异常值的检测不够敏感。
MAD方法
基于中位数:只考虑中位数和每个点的偏差。
稳健:对异常值不敏感,特别适合于含有离群点的数据。
非对称:只考虑偏离中位数的绝对偏差,因此不是关于中位数对称的。
优点比较:
对于含有离群点的数据集:MAD通常更优,因为它对异常值的敏感度低。
对于较为对称分布的数据集:IQR可能更优,因为它可以更好地反映数据的分散程度。
缺点比较:
对于含有极端值的数据集:IQR的敏感性可能导致它不如MAD稳健。
对于非对称分布的数据集:MAD可能不如IQR好,因为它可能不会充分反映数据的实际分布。
总结:
IQR方法
基于四分位数:使用数据的第一四分位数(25%)和第三四分位数(75%)来计算。
对称:相对于中位数对称地考虑上下界。
受极端值影响:如果数据中包含极端值,IQR可能会被拉得很大,导致异常值的检测不够敏感。
MAD方法
基于中位数:只考虑中位数和每个点的偏差。
稳健:对异常值不敏感,特别适合于含有离群点的数据。
非对称:只考虑偏离中位数的绝对偏差,因此不是关于中位数对称的。
优点比较:
对于含有离群点的数据集:MAD通常更优,因为它对异常值的敏感度低。
对于较为对称分布的数据集:IQR可能更优,因为它可以更好地反映数据的分散程度。
缺点比较:
对于含有极端值的数据集:IQR的敏感性可能导致它不如MAD稳健。
对于非对称分布的数据集:MAD可能不如IQR好,因为它可能不会充分反映数据的实际分布。
总结:
如果数据集受到极端值的影响较大,或者含有大量的重复值,MAD可能是一个更好的选择。
如果数据分布较为均匀,没有极端的异常值,IQR可能会更有用。
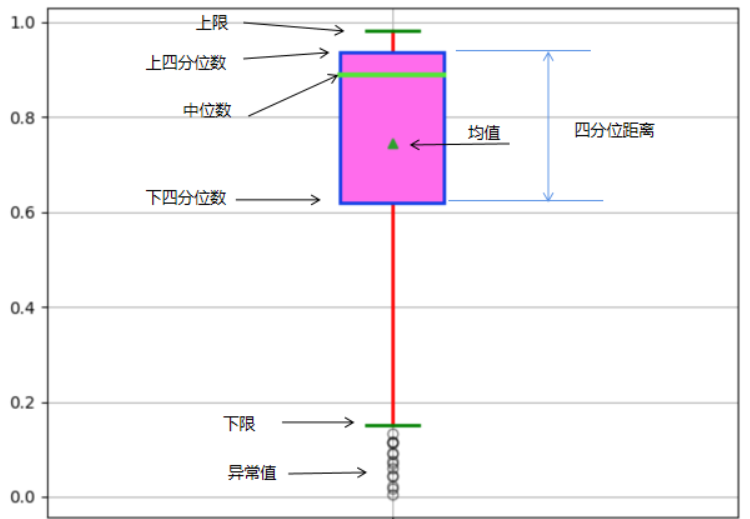
四分位数
一组数据按照从小到大顺序排列后,把该组数据四等分的数,称为四分位数。
第一四分位数 (Q1)、第二四分位数 (Q2,也叫“中位数”)和第三四分位数 (Q3)分别等于该样本中所有数值由小到大排列后第25%、第50%和第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距(interquartile range, IQR)。
偏态
与正态分布相对,指的是非对称分布的偏斜状态。在统计学上,众数和平均数之差可作为分配偏态的指标之一:如平均数大于众数,称为正偏态(或右偏态);相反,则称为负偏态(或左偏态)。
箱形图可以用来观察数据整体的分布情况,利用中位数,25/%分位数,75/%分位数,上边界,下边界等统计量来来描述数据的整体分布情况。通过计算这些统计量,生成一个箱体图,箱体包含了大部分的正常数据,而在箱体上边界和下边界之外的,就是异常数据。
判断数据的偏态和尾重
**对于标准正态分布的大样本,**中位数位于上下四分位数的中央,箱形图的方盒关于中位线对称。中位数越偏离上下四分位数的中心位置,分布偏态性越强。异常值集中在较大值一侧,则分布呈现右偏态;异常值集中在较小值一侧,则分布呈现左偏态。
比较多批数据的形状
箱子的上下限,分别是数据的上四分位数和下四分位数。这意味着箱子包含了50%的数据。因此,箱子的宽度在一定程度上反映了数据的波动程度。箱体越扁说明数据越集中,端线(也就是“须”)越短也说明数据集中。
matplotlib参数详解
plt.boxplot(x, # x:指定要绘制箱图的数据
notch=None, # notch:是否是凹口的形式展现箱线图,默认非凹口
sym=None, # sym:指定异常点的形状,默认为+号显示
vert=None, # vert:是否需要将箱线图垂直摆放,默认垂直摆放
whis=None, # whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差
positions=None, # positions:指定箱线图的位置,默认为[0,1,2…]
widths=None, # widths:指定箱线图的宽度,默认为0.5
patch_artist=None, # patch_artist:是否填充箱体的颜色
meanline=None, # meanline:是否用线的形式表示均值,默认用点来表示
showmeans=None, # showmeans:是否显示均值,默认不显示
showcaps=None, # showcaps:是否显示箱线图顶端和末端的两条线,默认显示
showbox=None, # showbox:是否显示箱线图的箱体,默认显示
showfliers=None, # showfliers:是否显示异常值,默认显示
boxprops=None, # boxprops:设置箱体的属性,如边框色,填充色等
labels=None, # labels:为箱线图添加标签,类似于图例的作用
flierprops=None, # filerprops:设置异常值的属性,如异常点的形状、大小、填充色等
medianprops=None, # medianprops:设置中位数的属性,如线的类型、粗细等
meanprops=None, # meanprops:设置均值的属性,如点的大小、颜色等
capprops=None, # capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等
whiskerprops=None) # whiskerprops:设置须的属性,如颜色、粗细、线的类型等
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(100)
data = np.random.normal(size=(1000,4),loc=0,scale=1)
ax = plt.subplot()
ax.boxplot(data) # 绘图
ax.set_xlim([0,5]) # 设置x轴值的范围 rotation=30
# ax.set_xticks() # 自定义x轴的值
ax.set_xlabel("xlabel") # 设置x轴的标签
ax.set_xticklabels(['A','B','C','D'], rotation=30,fontsize=10) # 设置x轴坐标值的标签 旋转角度 字体大小
ax.set_title("xcy") # 设置图像标题
ax.legend(labels= ['A','B','C','D'],loc='best',) # 增加图例
ax.text(x=0.2 , y=3.5 , s="test" ,fontsize=12) # 增加注
plt.show()
seaborn参数讲解
-
x, y, hue:数据或向量数据中的变量名称
用于绘制长格式数据的输入。 -
data:DataFrame,数组,数组列表
用于绘图的数据集。如果x和y都缺失,那么数据将被视为宽格式。否则数据被视为长格式。 -
order, hue_order:字符串列表
控制分类变量(对应的条形图)的绘制顺序,若缺失则从数据中推断分类变量的顺序。 -
orient:“v”或“h”
控制绘图的方向(垂直或水平)。这通常是从输入变量的 dtype 推断出来的,但是当“分类”变量为数值型或绘制宽格式数据时可用于指定绘图的方向。 -
color:matplotlib颜色
所有元素的颜色,或渐变调色板的种子颜色。 -
palette:调色板名称,列表或字典
用于hue变量的不同级别的颜色。可以从color_palette()得到一些解释,或者将色调级别映射到matplotlib颜色的字典。 -
saturation:float
控制用于绘制颜色的原始饱和度的比例。通常大幅填充在轻微不饱和的颜色下看起来更好,如果您希望绘图颜色与输入颜色规格完美匹配可将其设置为1。 -
width:float
不使用色调嵌套时完整元素的宽度,或主要分组变量一个级别的所有元素的宽度。 -
dodge:bool
使用色调嵌套时,元素是否应沿分类轴移动。 -
fliersize:float
用于表示异常值观察的标记的大小。 -
linewidth:float
构图元素的灰线宽度。 -
whis:float
控制在超过高低四分位数时 IQR (四分位间距)的比例,因此需要延长绘制的触须线段。超出此范围的点将被识别为异常值。 -
notch:boolean
是否使矩形框“凹陷”以指示中位数的置信区间。还可以通过plt.boxplot的一些参数来控制 -
ax:matplotlib轴
绘图时使用的 Axes 轴对象,否则使用当前 Axes 轴对象 -
kwargs:键值映射
其他在绘图时传给plt.boxplot的参数
features_per_row = 25
# 计算需要绘制的行数
num_rows = (data.shape[1] + features_per_row - 1) // features_per_row
# 对于每个25个特征的区间绘制一个箱形图
for i in range(num_rows):
start_col = i * features_per_row
end_col = min(start_col + features_per_row, data.shape[1])
data_long = pd.melt(data.iloc[:, start_col:end_col])
plt.figure(figsize=(12, 6), dpi=300) # 设定每个图的大小
sns.boxplot(x='variable', y='value', data=data_long)
plt.xticks(rotation=90) # 旋转x轴标签
plt.tight_layout()
plt.show()
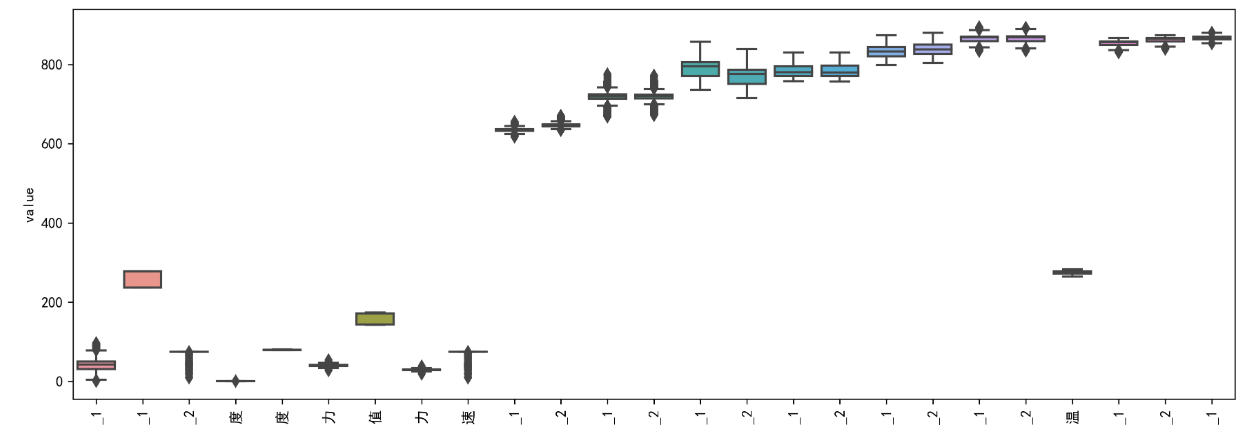
自动识别异常值并删除
IQR版本
for column in df.select_dtypes(include=[np.number]).columns:
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 300 * IQR
upper_bound = Q3 + 300 * IQR
# 确定异常值
outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)]
outlier_values = outliers[column].values
if len(outlier_values)>0:
# 打印结果
print(IQR)
print(f"特征 '{
column}' 的异常值数量: {
len(outlier_values)}")
if len(outlier_values) > 0:
print(f"特征 '{
column}' 的异常值: {
outlier_values}")
else:
print(f"特征 '{
column}' 没有检测到异常值。")
print()
MAD版本
df=data
# 定义一个函数来计算MAD
def mad(data, const=0.6745):
med = np.median(data)
mad = np.median(np.abs(data - med))
return mad if mad != 0 else None
# 初始化一个空的索引列表,用于存储异常值所在的行
outlier_indices = []
# 对DataFrame中的每一列应用MAD方法
for column in df.select_dtypes(include=[np.number]).columns:
median = df[column].median()
mad_value = mad(df[column])
# 只有当MAD值大于0.1时才进行异常值检测
if mad_value and mad_value > 0.1:
# 设置一个异常值阈值,这里使用的是80倍的MAD
threshold = 100 * mad_value
lower_bound = median - threshold
upper_bound = median + threshold
# 确定异常值
outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)]
outlier_values = outliers[column].values
# 如果找到异常值,将它们的索引添加到列表中
if len(outlier_values) > 0:
outlier_indices.extend(outliers.index.tolist())
# 打印结果
print(f"特征 '{
column}' 的MAD值: {
mad_value}")
print(f"特征 '{
column}' 的异常值数量: {
len(outlier_values)}")
print(f"特征 '{
column}' 的异常值: {
outlier_values}")
print()
# 删除异常值所在的行
df_cleaned = df.drop(index=set(outlier_indices))
print(f"删除异常值后的数据行数: {
df_cleaned.shape[0]}")
每文一语
细致入微