前言
虽然现在互联网项目很少能看到存储过程的身影了,而且阿里开发手册 也明文规定禁止使用存储过程,但是有不少小伙伴进入企业 工作后,尤其是一些银行、金融、保险 和一些很老的项目里,还是用到了大量的存储过程,就比较容易懵。但是,不用担心,这篇文章带你玩转存储过程,从此不再畏惧远古项目…
一、什么是存储过程
简单来说,存储过程就是一个SQL语句集,调用一次可执行多条SQL语句,或者 可以将存储过程比作一个Java中的方法,可以传递参数,然后返回结果。调用存储过程就相当于在调用一个方法。
二、环境准备
创建数据库并且建立student表,插入几条数据
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`name` varchar(32) DEFAULT '' COMMENT '用户名称',
`age` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT '' COMMENT '用户地址',
`delete_flag` int(1) DEFAULT '0' COMMENT '是否删除',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
INSERT INTO `student` VALUES ('1', '张超', '18', '上海', '0', '2022-09-03 18:47:30');
INSERT INTO `student` VALUES ('2', '杨俞', '16', '北京', '0', '2022-09-03 18:48:05');
INSERT INTO `student` VALUES ('3', '李腾', '17', '香港', '0', '2022-09-03 18:48:27');
三、存储过程的基本语法
1、创建、调用、查看、删除
①创建
create procedure 存储过程名称([ 参数列表 ])
begin
---SQL语句
end;
测试创建,创建完之后则可在函数里看见我们创建的存储过程
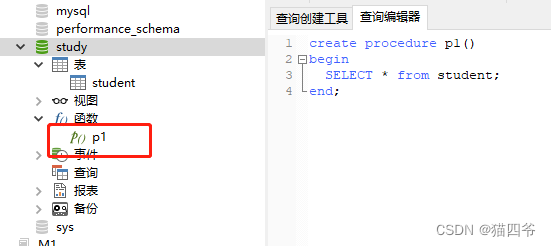
②调用
CALL 名称 ([ 参数 ]);
调用测试
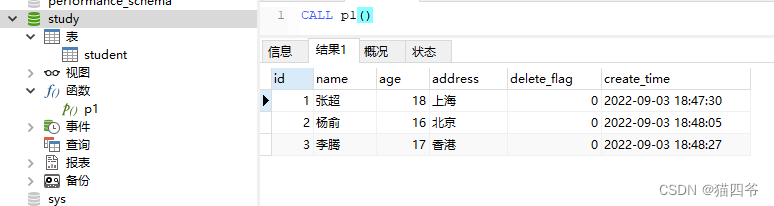
③查看
查看某个具体数据库中的存储过程信息
SELECT * from information_schema.ROUTINES WHERE ROUTINE_SCHEMA="数据库名称"

因为上面那种方式查看不到具体的存储过程中的语句,所以我们也可以换种方式查看存储过程中的详细语句
show create procedure 存储过程名称;
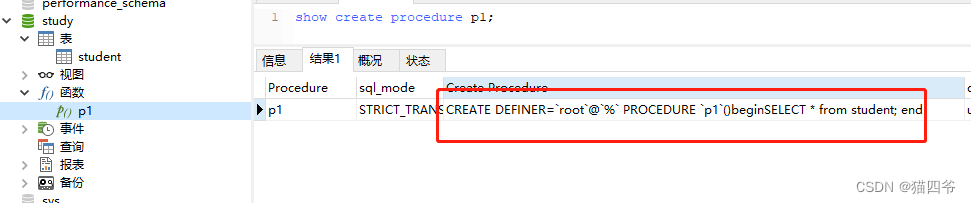
④删除
drop procedure [if exists] 存储过程名称;
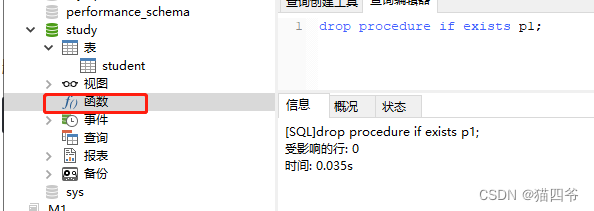
补充
如果我们在命令行中创建存储过程
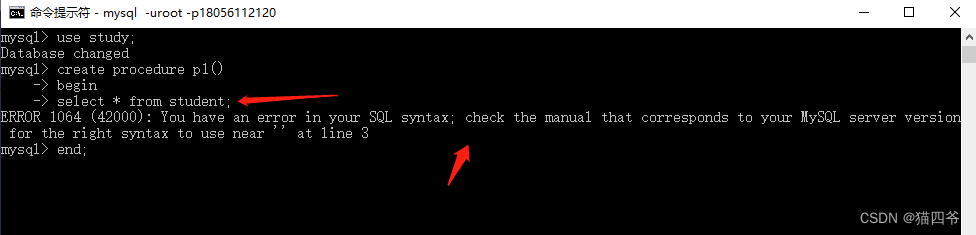
会发现报错,因为命令行的形式会以 " ; " 符号表示命令的结束,所以并不能构成一个完成的存储过程语句。我们可以使用 关键字 delimiter $$ 来指定SQL的结束符
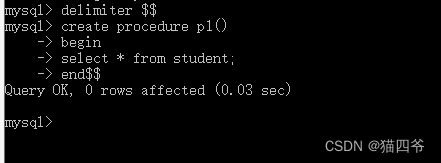
delimiter $$
测试
delimiter $$
create procedure p1()
begin
select * from student;
end$$
会发现 创建成功
2、系统变量
系统变量: 是MySQL服务器提供,不是用户定义的,属于服务器层面,分为全局变量(GLOBAL)、会话变量(SESSION)。
查看系统变量
show [session|global] variables; --查看所有系统变量
show [session|global] variables like '......' --可以通过like模糊匹配的方式查找变量
select @@[session|global].系统变量名; --查询指定变量的值
查看事务相关的变量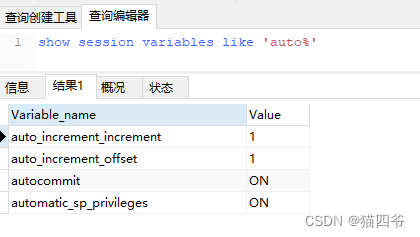
设置指定系统变量
set [session|global] 系统变量名 = 值;
set @@[session|global] 系统变量名 = 值;
如果不指定 级别,那么就默认是 session级别的变量
设置autocommit变量的值为0
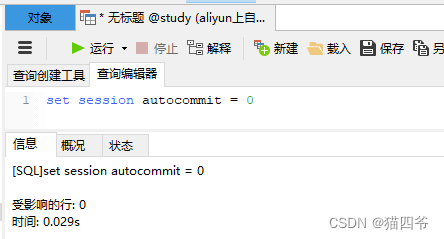
注意:就算将全局变量的值进行了修改, 重启了MySQL服务器后,全局变量的值还是会变成原来的默认值。
3、用户自定义变量
用户自定义变量: 是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用"@变量名" 使用就可以。其作用域为当前会话。
赋值
推荐使用 “ := ” ,因为mysql中比较符号也是“=”。
set @变量名=expr[,@变量名=expr]...
set @变量名 :=expr[,@变量名=expr]...
或者查询的时候声明
select @变量名 :=expr [,@变量名 :=expr]...
select 字段名 into @变量名 from 表名
使用
select @变量名;
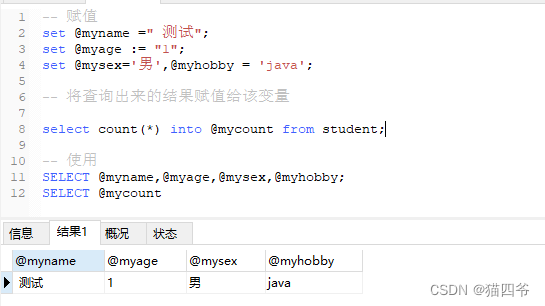
注意: 用户自定义的变量无需对其进行声明或初始化,可以在用的时候声明或者复制,直接使用一个未声明或初始化的变量 获取到的值只不过为NULL而已,并不会报错。
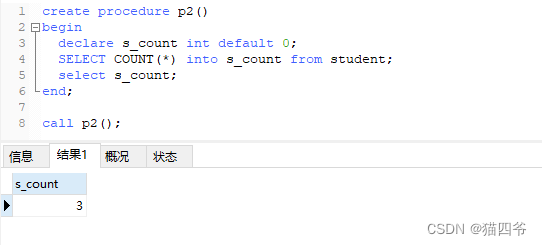
4、局部变量
局部变量: 是根据需要定义在局部生效的变量,在访问之前,需要declare声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的 begin … end块。
声明
declare 变量名 变量类型 [default]
变量的类型就是数据库字段的类型 :
int 、bigint、char、varchar、date、time 等。
赋值
set 变量名 = 值;
set 变量名 :=值
select 字段名 into 变量名 from 表名...
5、if 判断
语法
if 条件 then
...
elseif 条件2 then --可选
...
else --可选
...
end if;
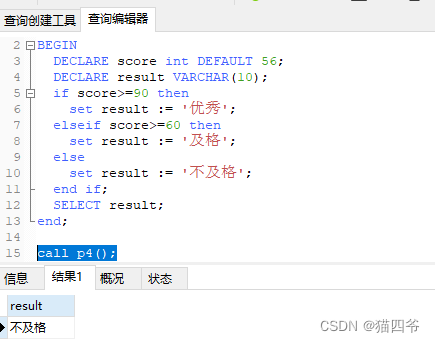
现在有一个需求
– 使用if语句实现
根据定义的score变量,判断当前分数对应的分数等级。
score>=90 ,优秀
score>=60, 且 score<90,及格
score < 60,不及格
6、存储过程的参数
| 类型 | 含义 |
|---|---|
| in | 该类型参数作为输入,也就是需要调用时传入值 |
| out | 该参数作为输出,也就是该参数可以作为返回值 |
| inout | 该参数作为输入参数,也可以作为输出参数 |
语法:
create procedure 存储过程([in/out/inout 参数名 参数类型])
beign
--SQL语句
end;
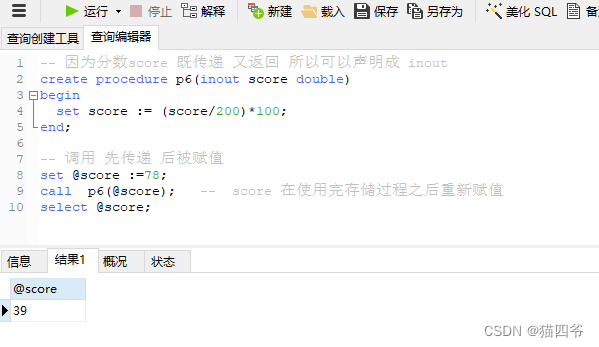
依旧是一个分数需求
根据传入参数score,判定当前分数的等级并返回
score>=90 ,优秀
score》=60 ,且 score <90 及格
score < 60 ,不及格
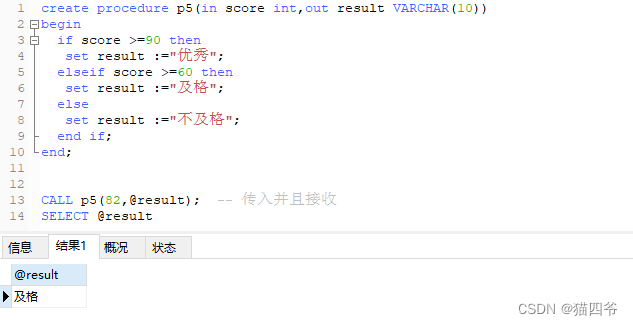
传入一个参数 这个分数为200分值换算成百分制
7、case语句
语法一、
case 变量值
when 值 then 语句1...
[when 值 then 语句2... ]
[else 语句3...]
end case;
语法二、
case
when 条件语句 then 语句...
[when 条件语句 then 语句 ...]
[else 语句...]
end case;
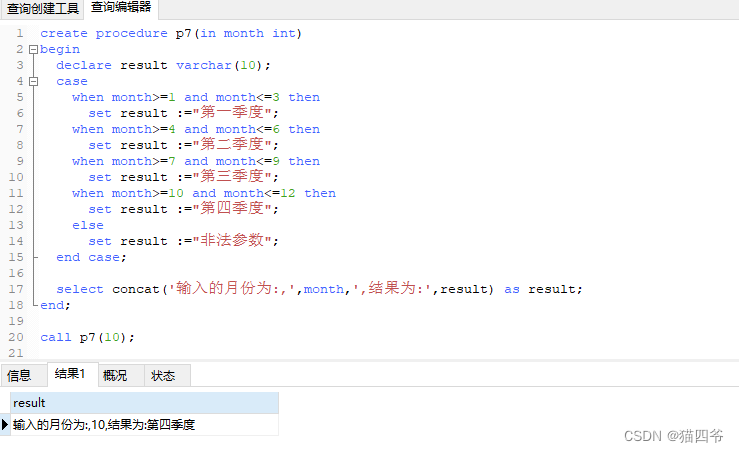
现在有一个需求
根据传入的月份,判定该月份为第几季度(要求采用case结构)
1-3月份,为第一季度
4-6月份,为第二季度
7-9月份,为第三季度
10-12月份,为第四季度
8、while循环
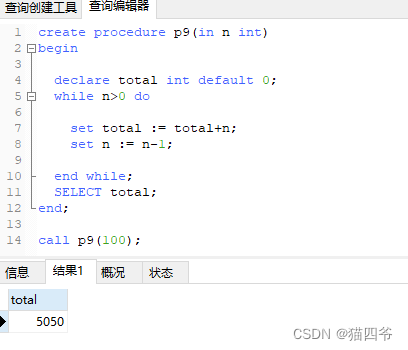
while: while循环是有条件的循环控制语句。满足条件后,再执行循环体中的SQL语句。
语法:
-- 先判断条件为ture,则执行逻辑,否则,不执行逻辑
while 条件 do
SQL逻辑...
end while;
传入一个值n,计算从1累加到n的值
9、repeat循环
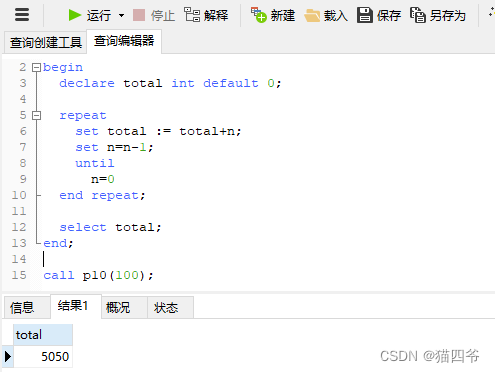
repeat: repeat是当满足条件时推出循环。
语法:
-- 先执行一次逻辑,然后判断条件是否满足,如果满足则退出。如果不满足,则进行下一次循环
repeat
SQL逻辑...
until 条件
end repeat;
依旧是传入一个n值然后计算从1到n
10、loop循环
loop: 如果不在SQL逻辑中增加退出循环的条件,那么它就是一个死循环。loop可以配合以下两种语句使用:
- leave:配合循环使用 退出循环。
- iterate:必须用来循环中,跳出本次循环,直接执行下一次循环
语法
[begin_label]:loop
SQL逻辑
end loop [end_label];
leave label; -- 退出指定标记的循环体
iterate label; --直接进入下一次循环
依旧是传递n,然后计算1到n的 累计值
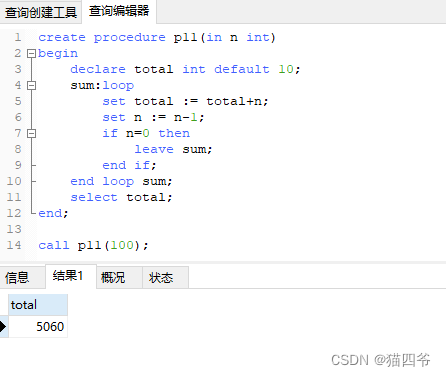
传递n值,然后累计从1到n之间的偶数值
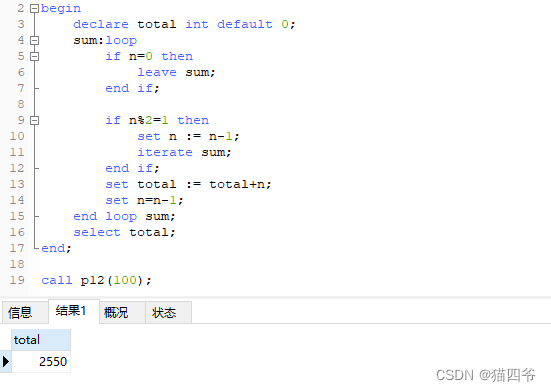
11、游标
游标: 是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理,游标的使用包括游标的声明、open、fetch和close。
声明游标
declare 游标名称 cursor for 查询语句;
打开游标(在使用游标之前必须要打开游标)
open 游标名称;
获取游标记录
fetch 游标名称 into 变量[,变量];
关闭游标
close 游标名称;
需求
根据传递的s_age参数值,查询学生student表中所有年龄小于等于s_age的学生 姓名(name) 地址(address),并将学生的姓名和地址插入到所创建的一张新表中(id,name,address)。
逻辑分析:
1、先查询到数据结果集 然后保存到游标
2、创建一个新表 ,然后开启游标
3、获取游标中的结果集
4、将获取到的记录插入进新表中
5、关闭游标
具体代码:
create procedure p13(in s_age int)
begin
declare sname varchar(10);
declare saddress varchar(100);
-- 声明游标并将查询的结果集封装进游标
declare s_cursor cursor for select name,address from student where age<=s_age ;
drop table if exists s_address;
create table if not exists s_address(
id bigint primary key auto_increment,
name varchar(10),
address varchar(100)
);
-- 开启游标
open s_cursor;
-- 循环遍历集合
while true do
-- 将游标中的记录 赋值给 声明的变量、每循环一次 都会获取到游标的下一条记录
fetch s_cursor into sname,saddress;
insert into s_address (name,address) value (sname,saddress);
end while;
-- 关闭游标
close s_cursor;
end;
call p13(20);
会发现有个错误
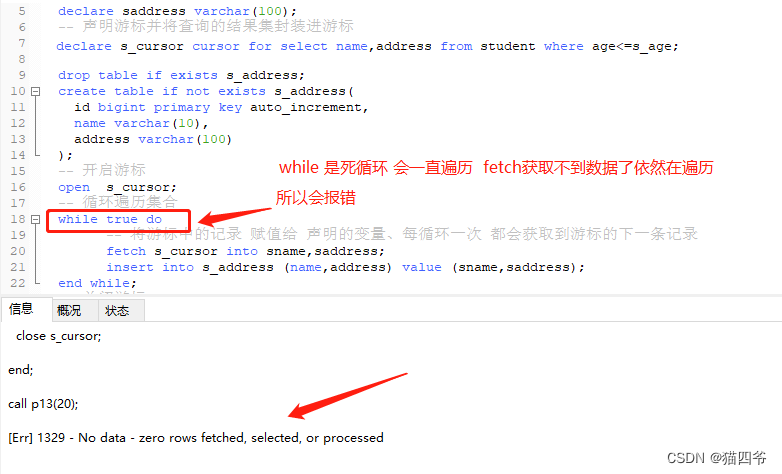
这是因为我们没有一个退出循环的程序,所以会出错,那么下一节我们来解决这个错误.
12、条件处理程序
条件处理程序(Handler): 定义在 流程控制结构执行过程中遇到问题时相应的 处理程序,就是在流程语句中,我们什么时候触发这个处理程序,触发后执行什么样的动作;
语法:
declare handler_action handler for condition_value[,condition_value]... statement;
-- 对应的值如下所示
handler_action
continue:继续执行当且语句
exit:终止执行当前程序
condition_value
sqlstate 'sqlstate_value(状态码)'
sqlwarning: 所有以01开头的sqlstate代码的简写
not found: 所有以02开头的sqlstate代码的简写
sqlexception: 所有没有sqlwarning或not found 捕获的 sqlstate代码的简写
这么说比较抽象 我们用条件处理程序解决上节 游标遍历 的问题
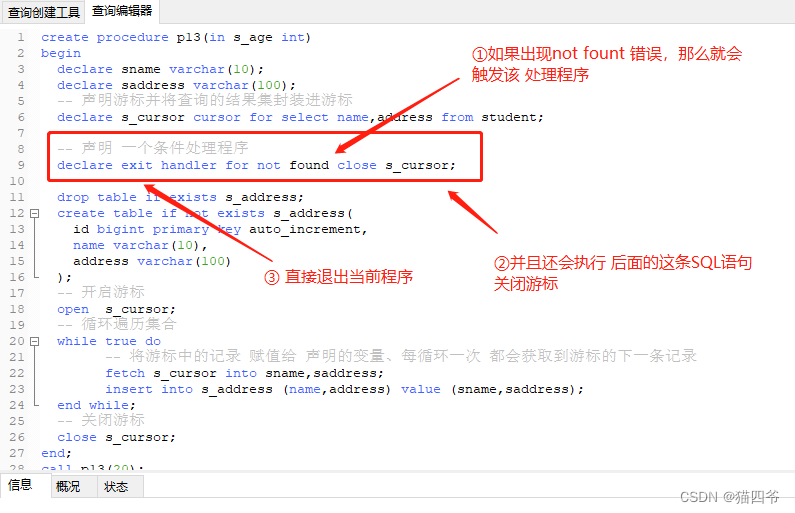
那么,一旦没有遍历到数据后,那么就会报错,但是报错会被 处理程序 给捕获到,然后触发 处理程序,关闭游标,退出当前数据。
(其实就像 Java中的 try…catch…语句语句一样)
当然,如果想对具体产生 的 状态码进行捕获,所有报错产生的状态码,我们可以根据MySQL的官方文档来进行对照查看
https://dev.mysql.com/doc/mysql-errors/8.0/en/server-error-reference.html
当然,我们也可以换一种思路。
补充:
create procedure p16(in s_age int)
begin
declare sname varchar(10);
declare saddress varchar(100);
declare num int default 0;
declare s_cursor cursor for select name,address from student where age<=s_age;
drop table if exists s_address;
create table if not exists s_address(
id bigint primary key auto_increment,
name varchar(10),
address varchar(100)
);
-- 我们可以直接拿到一份 所查询数据的数量
select count(*) into num from student WHERE age<=s_age;
open s_cursor;
while num>0 do
fetch s_cursor into sname,saddress;
insert into s_address (name,address) value (sname,saddress);
set num=num-1;
end while;
close s_cursor;
end;
call p13(20);
完美运行,也无报错。
四、存储函数
存储函数: 其实也很简单,存储函数是有返回值的存储过程,而且存储函数的参数只能是 in 类型.
语法:
create function 存储函数名称([参数列表])
returns type [可选参数 characteristic ...]
begin
-- SQL语句
return ...;
end;
-- type
type : 用来声明返回值的类型,int,bigint,
-- characteristic 参数说明:
1、deterministic : 相同的输入参数总是产生相同的结果。
2、no sql : 不包含SQL语句。
3、reads sql data : 包含读取数据的语句,但不包含写入数据的语句。
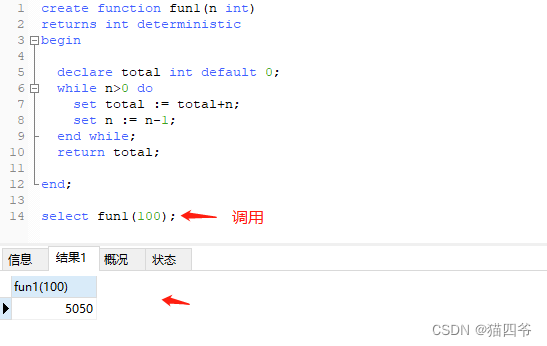
需求: 依旧是 传入n值 ,累计 1到n的值
create function fun1(n int)
returns int deterministic
begin
declare total int default 0;
while n>0 do
set total := total+n;
set n := n-1;
end while;
return total;
end;
五、后记
生活明朗,万物可爱,人间值得,未来可期。