1. 字符串驻留机制
- 在Python中,字符串是基本数据类型,是一个不可变的字符序列
- 仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
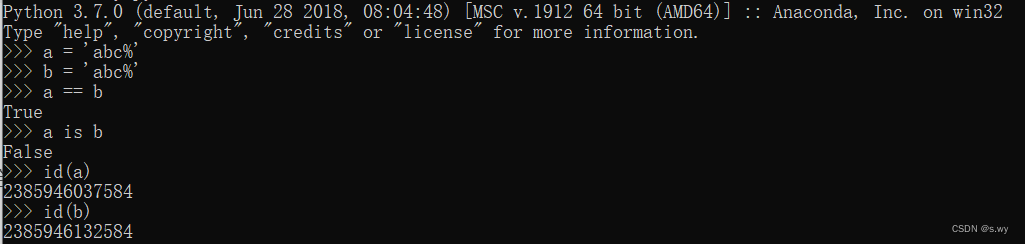
a = 'python'
b = "python"
c = '''python'''
print(id(a), id(b), id(c))

驻留机制的几种情况:(交互模式下)
- 字符串的长度为0或1时
- 符合标志符的字符串(只有字母数字和_组合才可以,如abc%就不行,因为有%)
- 字符串只在编译时进行驻留,而非运行时
- [-5, 256]之间的整数数字
a = 'abc'
b = 'a' + 'bc'
c = ''.join(['ab', 'c'])
print(a, b, c)
print(a is b, a is c)
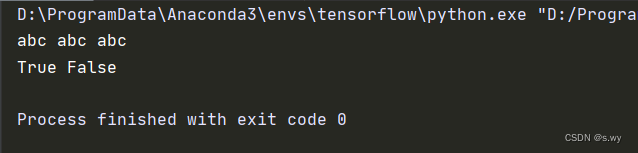
代码中a与b相同,a与c不相同,原因是b 在编译期间就完成了字符串拼接,而c需要到运行期间执行join()方法完成拼接,需要开辟新的空间存储,所以a与c不同。
驻留机制优缺点
- 避免频繁创建和销毁,提升效率和节约内存
- 拼接字符串使建议使用str类型的join方法,而不是+,因为join()方法是先计算出所有字符串的长度,然后再拷贝,只new一次对象,效率比’+'效率高
2. 字符串常用操作
2.1 查询
| 方法 | 说明 |
|---|---|
| index() | 查找子串第一次出现的位置,如果不存在时,抛出ValueError |
| rindex() | 查找子串最后一次出现的位置,如果不存在时,抛出ValueError |
| find() | 查找子串第一次出现的位置,如果不存在时,则返回-1 |
| rfind() | 查找子串最后一次出现的位置,如果不存在时,则返回-1 |
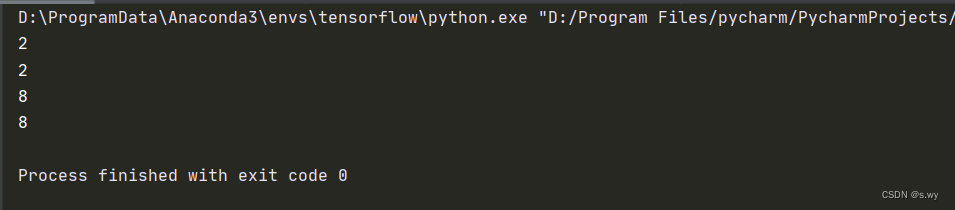
s = 'hello,hello'
print(s.index('llo'))
print(s.find('llo'))
print(s.rindex('llo'))
print(s.rfind('llo'))
2.2 大小写转换
| 方法 | 说明 |
|---|---|
| upper() | 转成大写字母 |
| lower() | 转成小写字母 |
| swapcase() | 小写字母转大写,大写字母转小写 |
| capitalize() | 第一个字符转大写,其余字符转小写 |
| title() | 每个单词第一个字符转大写,其余字符转小写 |
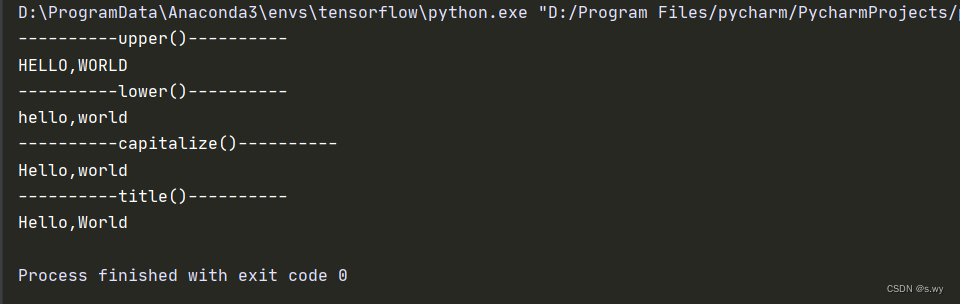
s = 'hElLo,wOrLd'
print('----------upper()----------')
a = s.upper()
print(a)
print('----------lower()----------')
a = s.lower()
print(a)
print('----------capitalize()----------')
a = s.capitalize()
print(a)
print('----------title()----------')
a = s.title()
print(a)
2.3 对齐操作
| 方法 | 说明 |
|---|---|
| center() | 居中对其,第一个参数指定宽度,第二个参数指定填充符 |
| ljust() | 左对齐,第一个参数指定宽度,第二个参数指定填充符 |
| rjust | 右对齐,第一个参数指定宽度,第二个参数指定填充符 |
| zfill | 右对齐,左边用0填充,只有一个接受宽度的参数 |
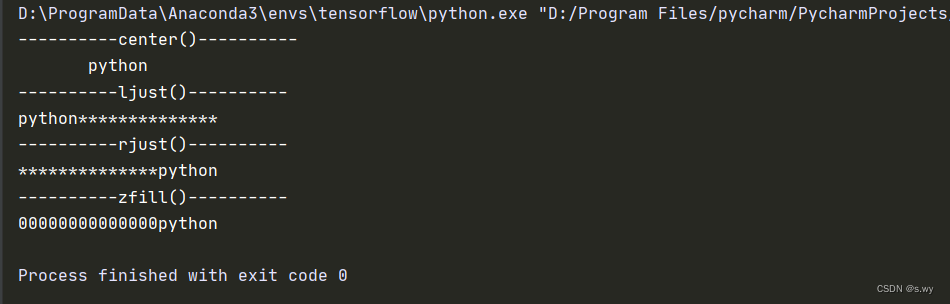
s = 'python'
print('----------center()----------')
print(s.center(20))
s = 'python'
print('----------ljust()----------')
print(s.ljust(20, '*'))
s = 'python'
print('----------rjust()----------')
print(s.rjust(20, '*'))
s = 'python'
print('----------zfill()----------')
print(s.zfill(20))
2.4 分割操作
| 方法 | 说明 |
|---|---|
| split() | 从左边开始分割,默认以空格字符拆分,返回一个列表 |
| rsplit() | 从右边开始分割,默认以空格字符拆分,返回一个列表 |
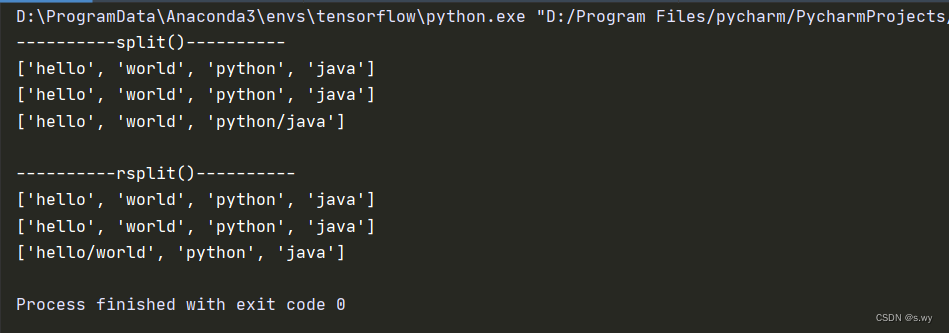
print('----------split()----------')
s = 'hello world python java'
lst = s.split()
print(lst)
s = 'hello/world/python/java'
lst = s.split(sep = '/')
print(lst)
s = 'hello/world/python/java'
lst = s.split(sep = '/', maxsplit=2)
print(lst)
print('\n----------rsplit()----------')
s = 'hello world python java'
lst = s.rsplit()
print(lst)
s = 'hello/world/python/java'
lst = s.rsplit(sep = '/')
print(lst)
s = 'hello/world/python/java'
lst = s.rsplit(sep = '/', maxsplit=2)
print(lst)
2.5 判断字符串
| 方法 | 说明 |
|---|---|
| isidentifier() | 判断指定字符串是不是合法的标识符 |
| isspace() | 判断指定字符串是否全部由空白字符组成(回车、换行、水平制表符) |
| isalpha() | 判断指定字符串是否全部由字母组成 |
| isdecimal() | 判断指定字符串是否全部由十进制的数字组成 |
| isnumeric() | 判断指定字符串是否全部由数字组成 |
| isalnum() | 判断指定字符串是否全部由字母和数字组成 |
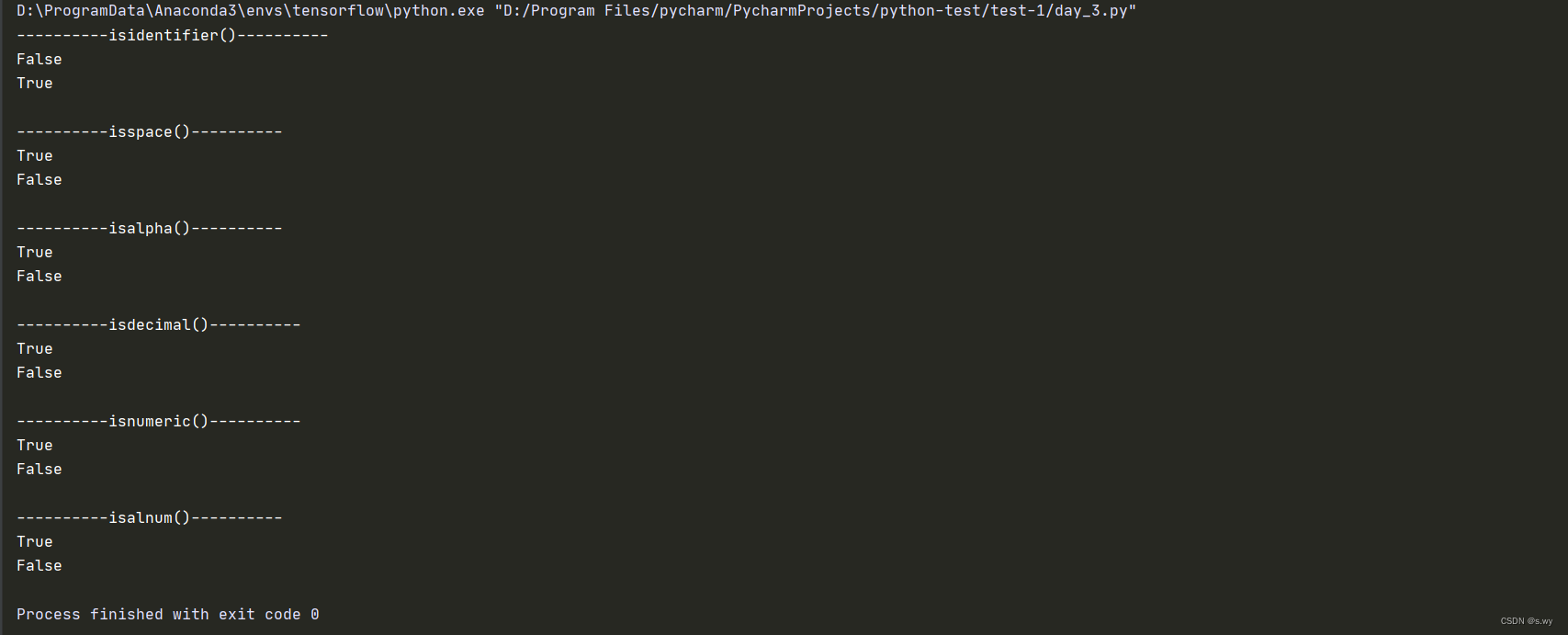
print('----------isidentifier()----------')
print('hello,python'.isidentifier())
print('hello_python'.isidentifier())
print('\n----------isspace()----------')
print(' '.isspace())
print(', '.isspace())
print('\n----------isalpha()----------')
print('hello'.isalpha())
print('hello,python'.isalpha())
print('\n----------isdecimal()----------')
print('123'.isdecimal())
print('123.90'.isdecimal())
print('\n----------isnumeric()----------')
print('123'.isnumeric())
print('123_90'.isnumeric())
print('\n----------isalnum()----------')
print('123abc'.isalnum())
print('123%abc'.isalnum())
3. 字符串的比较
- 比较运算符:>,>=,<,<=,==,!=
- 先比较两个字符串的第一个字符,相等则比较下一个字符,依次比较下去,直到两个字符不相等时,返回结果,后续字符串不再被比较
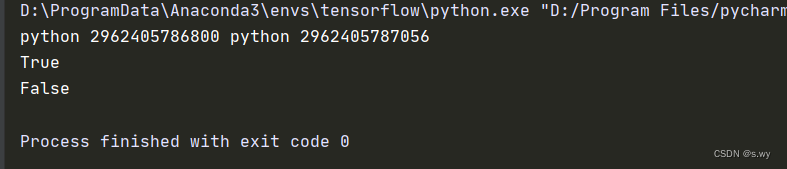
a = 'python'
b = ''.join(['py','thon'])
print(a, id(a), b, id(b))
print(a == b) # 比较值
print(a is b) # 比较内存地址
4. 字符串切片操作
- 字符串是不可变类型,不具备增、删、改等操作
- 切片将产生新的对象
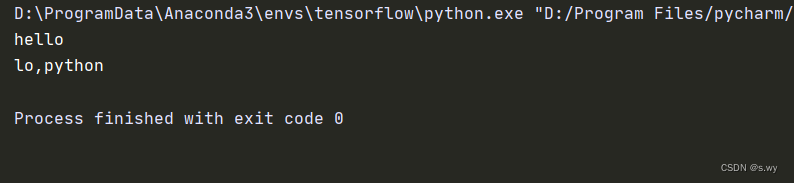
s = 'hello,python'
s1 = s[:5] # [0, 5)
print(s1)
s2 = s[3:] #[3, 末尾)
print(s2)
5. 格式化字符串
%作为占位符
| % | 说明 |
|---|---|
| %s | 字符串 |
| %i或%d | 整数 |
| %f | 浮点数 |
print('name: %s, age: %d' % ('swy', 23))
{}作占位符
print('name: {0}, age: {1}'.format('swy', 23))
name = 'swy'
age = 23
print(f'name: {
name}, age: {
age}')
精度
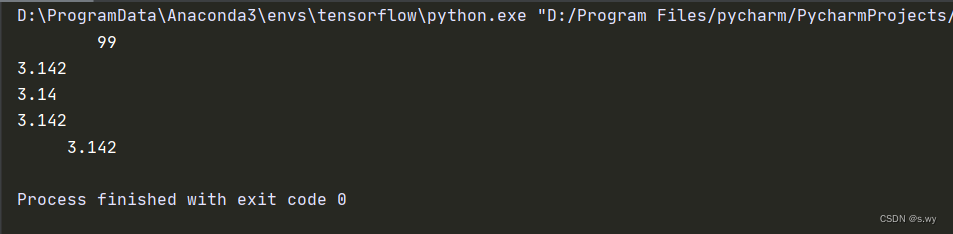
print('%10d' % 99) # 10表示宽度
print('%.3f' % 3.14159265) # 保留三位小数
print('{:.3}'.format(3.14159265)) # 3表示一共三位数
print('{:.3f}'.format(3.14159265)) # 3表示三位小数
print('{:10.3f}'.format(3.14159265)) # 宽度为10,3表示三位小数
6. 字符串的编码转换
- **编码:**将字符串转换为二进制数据(bytes)
- **解码:**将bytes类型的数据转换成字符串类型
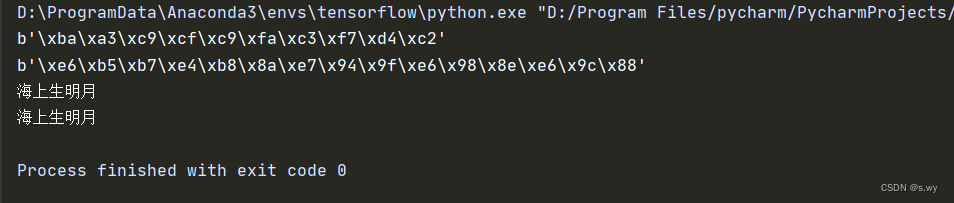
# 编码
s = '海上生明月'
print(s.encode(encoding='GBK'))
print(s.encode(encoding='UTF-8'))
# 解码
byte = b'\xba\xa3\xc9\xcf\xc9\xfa\xc3\xf7\xd4\xc2'
print(byte.decode(encoding='GBK'))
byte = b'\xe6\xb5\xb7\xe4\xb8\x8a\xe7\x94\x9f\xe6\x98\x8e\xe6\x9c\x88'
print(byte.decode(encoding='UTF-8'))