1、编码问题
计算机只能处理数字,即二进制。如果要处理文本,就必须先把文本转换为数字才能处理,最早的计算机在设计时采用8 bit 为一个字节,所以以一个字节能表示的最大整数为255.如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示65535,四个字节等等。
由于计算机是美国发明的,因此最早的只有127个字母被编码到计算机里,也就是大小写英文字母,数字和一些符号,这个编码表被称为ASCII编码。
要处理中文,显然一个字节是不够的,至少需要两个字节,而且不能和ASCII编码冲突,所以中国制定了GB2312编码,用来把中文编进去。
可以想象,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到EUC-kr里,各国有各国的标准,就不可避免地出现冲突,结果就是,再多语言混合的文本中就会显示乱码。
Unicode应运而生,Unicode把所有语言都统一到一套编码里,这样就不会有乱码问题了。
Unicode标准在不断发展,最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要四个字节)。现在操作系统和大多数编程语言都直接支持Unicode。
统一成Unicode之后,乱码问题解决了,但是写的文本基本上全是英文时,用Unicode编码比ASCII编码多一倍存储空间,在存储和传输上十分不划算。
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码,UTF-8编码把一个Unicode字符根据不同的数字大小编码成1~6个字节,常用的英文字母被编码成1个字节,汉子通常是3个字节,只有很生僻的字符才会被编码成4~6个字节。如果要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
UTF-8编码还有一个额外的好处,就是ASCII编码实际上可以看成是UTF-8编码的一部分,所以只支持ASCII编程的大量历史遗留软件可以在UTF-8编码下继续工作。
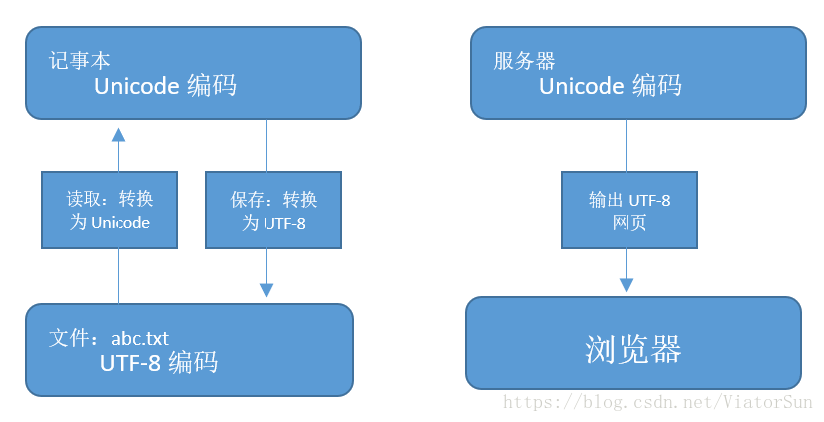
在现在计算机系统通用的字符编码工作方式:在计算机内存中,同意使用Unicode编码,当需要保存到硬盘或需要传输时,可以转换为UTF-8编码。
用记事本编辑时,从文件读取的UTF-8字符被转换为Unicode字符到内存;编辑完成后,保存时再把Unicode转换为UTF-8保存到文件;浏览网页时,服务器会把动态生成的Unicode内容转换为UTF-8在传输到浏览器;我们经常看到很多网页的源代码上有类似的的信息,表示该网页用的是UTF-8编码。
Python3的默认编码为Unicode,可以识别中文字符。也就是说,Python 3的字符串支持多语言,而Python 2中默认的编码格式是ASCII,在没修改编码格式时无法正确输出中文,在读取中文时会报错,Python 2使用中文的语法是在字符串前面加上前缀 u。
默认情况下,Python文件使用UTF-8字符编码,UTF-8是ASCII的超集,可以完全表达每种语言中的所有字符。通常Python文件的扩展名为.py,不过在一些UNIX类系统上,有些Python应用程序没有扩展名,Python GUI程序的扩展名则为.pyw。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码,申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码。
Python 3的字符串使用Unicode,直接支持多语言。
当str和bytes互相转换时,需要指定编码,最常用的编码是UTF-8。
但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅使用UTF-8编码。
格式化字符串的时候,可以用Python的交互式环境测试,方便快捷。
2、字符串的基本格式
创建字符串很简单,使用 ’ ’ 或 ” ” 创建字符串。不过字符串是不可变的,所以字符串做不了分片赋值,输出结果显示str类型的对象不支持更改。
”’ ”’或 “”” “”“用于创建多行字符串;
所有标准序列操作(索引、分片、成员资格、求长度、取最小值和最大值等)对字符串同样适用。
可以使用str()将其他格式的序列或数字转换为字符串
>>>field = ‘just do it’
>>>field[-3:]
‘it’
>>>field[-3:] = now
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
field[-3:]='now'
TypeError: 'str' object does not support item assignment3、字符串方法
字符串可以使用操作符“+”,但功能和数学中不一样,它会进行拼接操作,即将前后两个字符首尾连接起来。输出的字符紧紧挨着,如果想让字符串之间有空格,可以建一个空字符变量插在相应的字符串之间,让字符串隔开,或者在字符串中加入相应的空格。
注:
以下所有方法中原字符串均未改变,如需改变需赋值给原字符串。
| 方法 | 描述 |
|---|---|
| str() | 将其他格式序列转换为字符串 |
| decode() | 将十六进制字符转换为字节 |
| encode() | 解码 |
| replace() | str.replace(old,new,max)把字符串中的old(旧字符串)替换成new(新字符串); 此语法中str代表指定检索的字符串;old代表将替换的子字符串;new代表新字符串,max为可选字符串,替换次数不超过max个。当不指定第三个参数时,所有匹配字符都替换;指定第三个字符时,替换从左往右进行,替换次数不超过指定次数 |
| capitalize() | 将字符串中的首个字母转换为大写 |
| upper() | 该方法不需要参数。用于将字符串中的小写字母转换为大写字母.如果想要编写“不区分大小写”的代码,就会使用upper()方法。如果想要在一个字符串中查找某个子字符串并忽略大小写,也可以使用upper()方法 |
| lower() | 该方法不需要参数,lower()方法用于将字符串中所有大写字符转换成小写。注:有时类似于lower()这样的字符串方法并不能如我们所愿进行工作。对于英语英文字符串,lower()方法在处理时一点问题都没有,但是对于非英文字符串,lower()方法在处理时可能不如我们的预期 |
| startswith(obj) | 判断字符串是否是以子字符串开头,返回值为True或False |
| endswith(obj) | 判断字符串是否是以子字符串结尾,返回值为True或False |
| isnumeric() | 判断字符串是否为数字,返回值为True或False |
| isalpha() | 判断字符串是否为字母,返回值为True或False |
| split() | str.split(st = ‘’ , num = string.count(str))。通过指定分隔符对字符串进行切片,如果参数num有指定值,就只分隔num个子字符串。用来将字符串分隔成列表。st代表分隔符,默认将整体转换为一个整体元素;num代表分隔次数,默认全部分隔 。如果不提供分隔符,程序会把所有空格作为分隔符。若指定分隔次数,则从左往右检索和分隔符匹配的字符,分隔次数不超过指定次数;若不指定分隔次数,则所有匹配的字符都会被分隔 |
| join() | ‘:’.join(list)用于将列表中的元素以指定字符连接成一个新字符串 |
| format() | 格式化字符串 |
| find() | find()方法用于检测字符串中是否包含字符串str。如果指定beg(开始)和(结束)范围,就检查是否包含在指定范围内。如果包含子字符串,就返回开始的索引值;否则返回-1。其中str代表指定检索的字符串,beg代表开始索引,默认为0;end代表结束索引,默认为字符串的长度。返回结果为子串所在位置的最左端索引,如果没有找到,就返回-1。注:字符串的find()方法返回的不是布尔值,就返回对象的索引值。如果返回0,就表示在索引0处找到了子字符串,find()方法还可以接受参数,用于表示起始点和结束点。可以通过使用起始值和终止值查找指定的范围内是否存在指定字符串 |
| swapcase() | 用于对字符串的大小写字母进行转换,将字符串中大写转换为小写、小写转换为大写。该方法不需要参数。返回结果为大小写字母转换后生成的新字符串 |
4、转义字符
| 转义字符 | 描述 | 转义字符 | 描述 |
|---|---|---|---|
| r’ ‘ | 原始字符串 | b’ ‘ | ASCII码字符串 |
| \ | 续行符 | \n | 换行 |
| \ | 反斜杠符号 | \r | 回车 |
| \’ | 单引号 | \t | 横向制表符 |
| \” | 双引号 | \v | 纵向制表符 |
| \a | 响铃 | \0 | 空字符 |
| \b | 退格(Backspace) | \ooo | 给定八进制的字符 |
| \e | 转义 | \xhh | 十六进制,yy代表字符,如\x0a代表换行 |
| \f | 换页 | \other | 其他字符以普通格式输出 |
如果不希望在字符串中出现的\当做转义字符,可以在字符串 ‘ ’前加上r:r ‘’,以声明字符串中的\不是转义字符。r的原词为raw。
5、占位符
| 转义字符 | 描述 |
|---|---|
| 占位符 | 替换内容 |
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
6、ython字符串运算符
下表实例变量a值为字符串 “Hello”,b变量值为 “Python”:
| 操作符 | 描述 |
|---|---|
| + | 字符串连接 |
| * | 重复输出字符串 |
| [] | 通过索引获取字符串中字符 |
| [ : ] | 截取字符串中的一部分 |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法 |
| % | 格式字符串 |
7、字符串格式化
1)百分号格式化
>>>print(‘hello , %s’ % ‘world’)
hello world
>>>print(‘小智今年%s 岁了’ %10)
小智今年10岁了%左边放置了一个待格式化的字符串,右边放置的是希望格式化的值,格式化的值可以是一个字符串或数字。
格式化字符串的 %s 部分称为转换说明符,标记了需要放置转换值的位置,通用术语为占位符。可以想象成在学校上自习,用一个物品在一个位置上,其他人便知道位置被占了,而我们需要去自习的时候,直接到自己占好的位置坐下即可。这里可以把 %s 当做我们使用占位置的物品,我们相当于 后面% 右面的值。
%s 的s表示的百分号后面的值会被格式化为字符串,s指的是str。如果不是字符串,就会使用str将其转换为字符串。这种方式对大多数数值都有效。
字符串格式化符号
| 符号 | 描述 | 符号 | 描述 |
|---|---|---|---|
| %c | 格式化字符及ASCII码 | %f | 格式化浮点数字,可指定精度值 |
| %s | 格式化字符串 | %e | 用科学计数法格式化浮点数 |
| %d | 格式化整数 | %E | 同%e,用科学计数法格式化浮点数 |
| %u | 格式化无符号整型 | %g | %f和%e的简写 |
| %o | 格式化无符号八进制数 | %G | %f和%E的简写 |
| %x | 格式化无符号十六进制数 | %p | 用十六进制数格式化变量的地址 |
| %X | 格式化无符号十六进制数(大写) |
格式化操作符辅助指令
| 符号 | 描述 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
<sp> |
在正数前面显示空格 |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%’输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
>>>print(‘小智今年 %s 岁了’ % 10)
小智今年10岁了
>>>print(‘小智今年 %s 岁了’ % 10)
小智今年10岁了由操作可知,整数既可以使用%s也可以使用%d进行格式化
如果要格式化实数(浮点数)就可以使用%f进行格式化
>>>print(‘圆周率PI的值是:%f ’ % 3.14)
圆周率PI的值是:3.140000输出结果中有很多小数,但传入的值只有两位小数,解决这个问题可以使用 %f 格式化符号,在Python中,使用%f时,若不指定精度,则默认输出小数点后六位。
>>>print(‘圆周率PI的值是: %.2f ’ % 3.14)
圆周率PI的值是:3.14
>>>print(‘小智的识别能力比去年提高了: %.2f %% ’ % 1.23)
小智的识别能力比去年提高了:1.23%在Python中,字符串中的百分号是转换说明符,如果要输出% ,就需要格式化字符%,从而需要使用%% ,使用这种方式操作的功能类似:
>>>print(‘输出百分号: %s ’ % ‘%’)
输出百分号:%2)字符串格式化元组
格式化操作的右操作可以是任何元素。如果是元组或映射类型(如:字典),那么字符串格式化将会有所不同。
如果右操作是元组,其中每一个元素都会被单独格式化,每个值都需要一个对应的转换说明符。
在有多个占位符的字符串中,可以使用元祖传入多个格式化值。如果需要转换的元组作为转换表达式的一部分存在,就必须将它拥圆括号括起来,否则会出错。
>>>print(‘今年是%s年,中国女排获得本届奥运会%s,中国获得%d枚金牌’ % (‘2016’,’冠军’ ,26))
今年是2016年,中国女排获得本届奥运会冠军,中国获得26枚金牌
>>>print(‘今年是%s年,中国女排获得本届奥运会%s,中国获得%d枚金牌’ % ‘2016’,’冠军’ ,26)
Traceback (most recent call last):
File “<pyshell#13>”, line 1, in <module>
print(‘今年是%s年,中国女排获得本届奥运会%s,中国获得%d枚金牌’ % ‘2016’,’冠军’,26)
TypeError: not enough arguments for format string如果使用列表或其他序列代替元组,序列就会被解释为一个值,只有元组和字典可以格式一个以上的值。
下面介绍基本转换说明符。
注意:这些项的顺序都是至关重要的。
- %字符:标记转换说明符开始;
- 转换标志(可选):-表示对齐;+表示在转换值之前要加上正负号;“”(空白字符)表示正数之前保留空格;0表示转换值位数不够时0填充;
- 最小字段宽度(可选):转换后的字符串至少应该具有该值指定的宽度。如果是*,宽度就会从值元组中读出;
- 点( . )后跟精度值(可选):如果转换的是实数,精度值表示出现在小数点后的位数,如果转换的是字符串,该数字就表示最大字段宽度;如果是*,精度就会从元祖中读出;
1. 简单转换
>>>(‘圆周率PI的值为:%.2f’ % 3.14)
圆周率PI的值为:3.14
>>>print(‘石油价格为每桶:$ %d ’ % 96)
石油价格为每桶:$96简单转换只需要写出转换类型,使用起来较简单
2.字段宽度和精度
转换说明符包括字段宽度和精度。字段宽度是转换后的值所保留的最小字符个数,精度是数字转换结果中应该包含的小数位数或字符串转换后的值所能包含的最大字符个数。
>>>print(‘圆周率PI的值为:%10f’ % 3.141593) #字段宽度为10
圆周率PI的值为:3.141593 #字符串宽度为10,被字符串占据8个,剩余2个空格
>>>print(‘保留两位小数 ,圆周率PI的值为:%10.2f’ % 3.141593) #字段宽度为10
保留两位小数,圆周率PI的值为:3.14 #字符串宽度为10,被字符串占据4个,剩余6个空格
>>>print(‘保留两位小数 ,圆周率PI的值为:%.2f’ % 3.141593)
保留两位小数,圆周率PI的值为:3.14 #输出,没有字段宽度参数
>>>print(‘字符串精度获取: %.5s’ % ( ‘hello world’ )) #打印出字符串前5个字符
字符串精度获取:hello字段宽度和精度都是整数,并通过点号( . )分隔。两个都是可选参数,如果给出精度,就必须包含点号。
>>>print(‘从元组中获取字符串精度: %*.* s ’ % (10,5, ‘hello world’))
从元组中获取字符串精度: hello #输出字符串宽度为10,精度为5
>>>print(‘从元组中获取字符串精度: %.*s ’ % (5, ‘hello world’))
从元组中获取字符串精度:hello # 输出精度为5可以使用 * (星号)作为字符串宽度和精度(或两者都用*),数值会从元组中读取。
3.符号、对齐和0填充
>>>print(‘圆周率PI的值为:% 010.2f ’ %3.141593)
圆周率PI的值为:00000003.14这样子的结果我们称之为“标表”。在字段宽度和精度之前可以放置一个“标表”,可以是零、加号、减号或空格。零表示用0进行填充。