字符串
字符串的创建和访问方法与列表和元组一样,当然也可以进行分片
字符串与元组一样,一旦定下来就不能直接进行修改,只能间接进行修改,例如分片的方法
>>> str1 = "I love python" >>> str1[:6] 'I love' >>> str1[5] 'e' >>> str1[:6] + "love" + str1[6:] 'I lovelove python' >>> str1 'I love python' >>>
这种通过拼接旧字符串的各个部分得到新字符串的方式并不是真正意义上改变原始字符串,原来的字符串还在,只是变量指向了新的字符串(旧的字符串一旦失去变量的引用,就会被python的垃圾回收机制释放掉)
1.各种内置的方法
>>> dir(str) ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
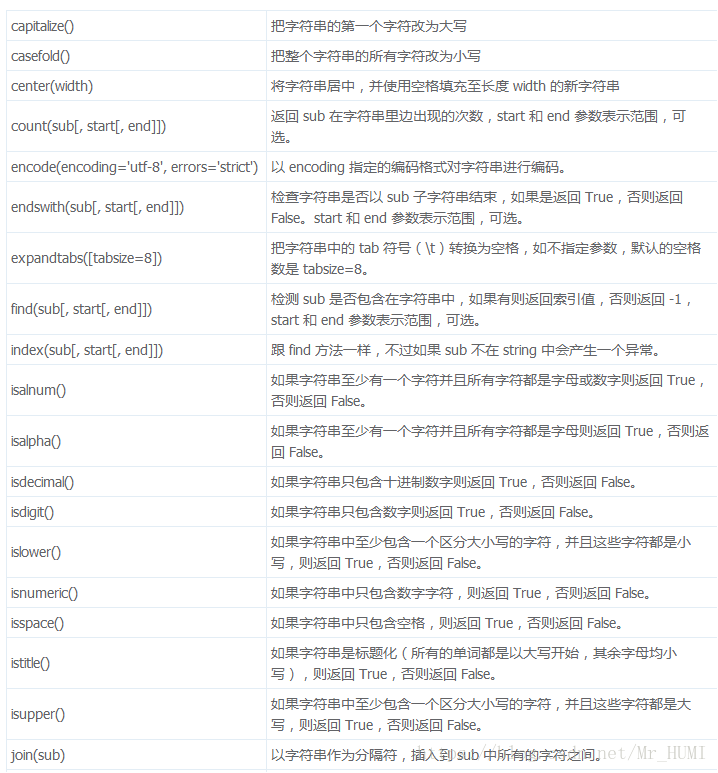
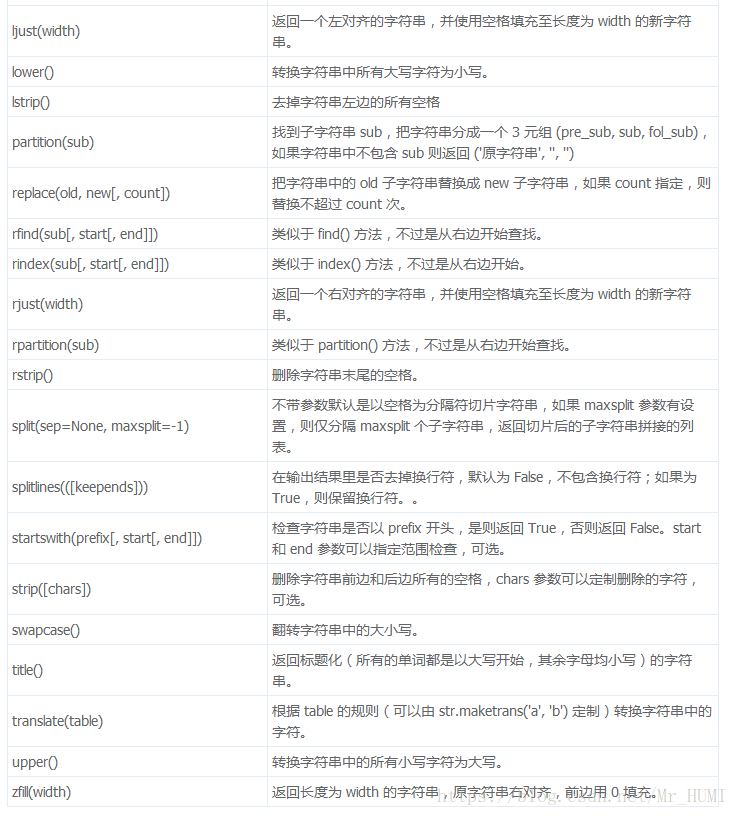
常用的字符串方法:
#casefold()方法:将字符串的所有字符变为小写
>>> str1 = "HELLO" >>> str1.casefold() 'hello' >>>
#count(sub[,start[,end]]):查找sub子字符串出现的次数,可选参数
>>> str1 = "AbcABCabCabcABCabc"
>>> str1.count('ab',0,15)
2
#find(sub[,start[,end]]):查找某个子字符串在该字符串中的位置
>>> str1 = "I love python"
>>> str1.find("love")
2
>>> str1.find("good")
-1
>>> str1.find("python")
7
>>> str1.index("good")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>>
find()方法找到了就返回第一个字符的索引值,如果没找到,则返回-1
index()方法,如果没找到,会抛出异常(可以进行捕获)
#join(sub):以字符串为分隔符,插入到sub字符串中所有的字符之间
>>> "x".join("Hello")
'Hxexlxlxo'
>>> '_'.join('Hello')
'H_e_l_l_o'
连接符+也可以进行字符串拼接,但是非常低效率,加号也会引起内存复制以及垃圾回收操作,对于大量字符串拼接,用join()
#replace(old,new[,count]):替换指定的字符串
>>> str1 = "I love you"
>>> str1.replace("you","everyone")
'I love everyone'
#split(sep=None,maxsplit=-1):跟join相反,split用于拆分字符串
>>> str2 = " ".join(['I','love','you'])
>>> str2
'I love you'
>>> str2.split()
['I', 'love', 'you']
>>> str3 = '_'.join("python")
>>> str3
'p_y_t_h_o_n'
>>> str3.split("_")
['p', 'y', 't', 'h', 'o', 'n']
>>>
作业题:
1.如何定义一个跨越多行的字符串?
① 使用"""内容""" ② 不换行使用\n ③ 换行时使用\ ④整体是元组,换行后,每一行都是一个字符串
2.三引号字符串的作用
三引号字符串的不赋值的情况下,用作跨行注释
3.file1 = open('C:\windows\temp\readme.txt', 'r') 表示以只读方式打开“C:\windows\temp\readme.txt”这个文本文件,这个语句会报错
因为字符串中出现了\t \r等符号,因此会报错
修改方法:file1 = open(r'C:\windows\temp\readme.txt', 'r'),使用原始字符串即可
4.将str1 = 'i2sl54ovvvb4e3bpery32t56h;$o43nsft67o0co99'还原成有意义的字符串
>>> str1 = 'i2sl54ovvvb4e3bpery32t56h;$o43nsft67o0co99' >>> str1[::3] 'ilovepythontoo' >>>
5.写一个密码安全性检测的代码
symbol = r'''~!@#$%^&*()_+-=*{}[]\|'";:?,.<>.?<>'''
alpha = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
number = "0123456789"
password = input("请输入密码:")
length = len(password)
while (password.isspace() or length == 0):
print("密码输入格式错误")
password = inptu("请重新输入密码")
if length <= 8:
level_length = 1
elif 8 < length <16:
level_length = 2
else:
level_length = 3
level_con = 0
#判断是否存在数字
for each in password:
if each in number:
level_con += 1
break
#判断是否存在字母
for each in password:
if each in alpha:
level_con += 1
break
#判断是否存在特殊符号
for each in password:
if each in symbol:
level_con += 1
break
#打印安全级别
while True:
if level_length == 1 or level_con == 1:
print('密码安全级别低')
elif level_length == 2 or level_con == 2:
print('密码安全级别中')
elif level_length == 3 or level_con == 3:
print('密码安全级别高')
break