数字图像与机器视觉基础补充(2)
编译环境:Jupyter Notebook (Anaconda3)
调用的包:matplotlib,cv2
文章目录
一、将彩色图像转换为灰度图像
先看原图:

1. OpenCV方式
1.1 直接以灰度图片读取
使用函数cv2.imread()读取图像。该映像应位于工作目录中,或者应提供完整的映像路径。
第二个参数是一个标志,用于指定应读取图像的方式。
cv2.IMREAD_COLOR:加载彩色图像。图像的任何透明度都将被忽略。这是默认标志。
cv2.IMREAD_GRAYSCALE:以灰度模式加载图像
cv2.IMREAD_UNCHANGED:加载图像,包括alpha通道
这里有个小细节
除了这三个标志,您可以分别简单地分别传递整数1、0或-1。
源码:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('d:/IDE/Python38_Resource/Images/pathfinder.jpg',0) #直接以灰度图片读取
img_1 = cv.imread('d:/IDE/Python38_Resource/Images/pathfinder.jpg',cv.IMREAD_GRAYSCALE)
#控制窗口大小
cv.namedWindow('readgray',0)
cv.imshow('readgray',img)
cv.namedWindow('readgray2',0)
cv.imshow('readgray2',img_1)
cv.waitKey(0)
#显示图像
titles = [u'readway1', u'readway2']
images = [img, img_1]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.show()
效果图:
1.2 彩色图片转灰度图
通过cvtColor库将其转为灰度
源码:
import cv2 as cv
img = cv.imread('d:/IDE/Python38_Resource/Images/pathfinder.jpg',1)
img_1 = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
cv.namedWindow('gray',0)
cv.namedWindow('colour',0)
cv.imshow('gray',img_1)
cv.imshow('colour',img)
cv.waitKey(0)
b,g,r = cv2.split(img) #这个地方将图像拆分,把彩色图像分为3个颜色
plt.figure(figsize=(10,8))
color = [b,g,r]
img_2 = cv2.merge([r,g,b]) #这个地方我把bgr格式的图片转成了rgb,然后显示的时候会变成正常的彩色
#显示图像
titles = [u'colour', u'gray']
images = [img_2, img_1]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.show()
效果图:
1.3 分离RGB三个通道得到三个通道的灰度图
源码:
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('d:/IDE/Python38_Resource/Images/pathfinder.jpg',1)
#cv2.imread读取图片格式是BGR
b,g,r = cv.split(img) #这个地方将图像拆分,把彩色图像分为3个颜色
plt.figure(figsize=(10,8))
color = [b,g,r]
img_2 = cv.merge([r,g,b]) #这个地方我把bgr格式的图片转成了rgb,然后显示的时候会变成正常的彩色
for i in range(3):
plt.subplot(2,2,i+1)
plt.imshow(color[i],'gray')
plt.subplot(2,2,4)
plt.imshow(img_2)
plt.savefig('./三通道灰度.png')
plt.show()

2. 非OpenCV方式
2.1 最大值法
灰度化后的R,G,B得值等于转化前3个值中最大的一个,即:
R=G=B=max(R,G,B)
源码:
import cv2
def gray_max_rgb(inputimagepath,windowname,outimagepath):
img = cv2.imread(inputimagepath)#读取图像,返回的是一个装有每一个像素点的bgr值的三维矩阵
gray_max_rgb_image = img.copy()#复制图像,用于后面保存灰度化后的图像bgr值矩阵
img_shape = img.shape#返回一位数组(高,宽,3)获得原始图像的长宽以及颜色通道数,一般彩色的颜色通道为3,黑白为1
for i in range(img_shape[0]):#按行读取图片的像素bgr
for j in range(img_shape[1]):#对每一行按照列进行每一个像素格子进行读取
gray_max_rgb_image[i,j] = max(img[i,j][0],img[i,j][1],img[i,j][2])#求灰度值
print(gray_max_rgb_image)
cv2.namedWindow(windowname,0) #控制显示图片窗口的名字
cv2.imshow(windowname, gray_max_rgb_image)#显示灰度化后的图像
#cv2.imwrite(outimagepath, gray_max_rgb_image) # 保存当前灰度值处理过后的文件
cv2.waitKey(0)#等待操作
cv2.destroyAllWindows()#关闭显示图像的窗口
def main():
inputimagepath = "colorful_lena.jpg"
windowname = "gray_max_rgb"
outimagepath = "gray_max_rgb.jpg"
gray_max_rgb('d:/IDE/Python38_Resource/Images/pathfinder.jpg','MAX','d:/IDE/Python38_Resource/Images/')
if __name__ == '__main__':
main()
效果图:

2.2 平均值法
灰度化后R,G,B的值为转化前R,G,B的平均值。即:
R=G=B=(R+G+B)/3
源码:
#平均值法进行图像灰度化
import cv2
def gray_mean_rgb(inputimagepath,windowname,outimagepath):
img = cv2.imread(inputimagepath)
gray_mean_rgb_image = img.copy()
img_shape = img.shape
for i in range(img_shape[0]):
for j in range(img_shape[1]):
gray_mean_rgb_image[i,j] = (int(img[i,j][0])+int(img[i,j][1])+int(img[i,j][2]))/3
print(gray_mean_rgb_image)
cv2.namedWindow(windowname) #控制显示图片窗口的名字
cv2.imshow(windowname, gray_mean_rgb_image)#显示灰度化后的图像
cv2.imwrite(outimagepath, gray_mean_rgb_image) # 保存当前灰度值处理过后的文件
cv2.waitKey()#等待操作
cv2.destroyAllWindows()#关闭显示图像的窗口
def main():
inputimagepath = "colorful_lena.jpg"
windowname = "gray_mean_rgb"
outimagepath = "gray_mean_rgb.jpg"
gray_mean_rgb(inputimagepath,windowname,outimagepath)
if __name__ == '__main__':
main()
效果图:
二、将彩色图像(RGB)转为HSV、HSI 格式
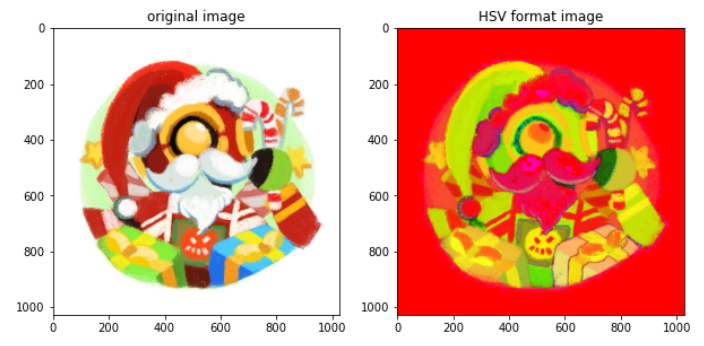
1. RGB转HSV
HSV是另一种颜色空间,其中H代表色相 , S代表饱和度 , V代表Value 。
色相代表颜色。 从0度到360度的角度。
| 角度 | 颜色 |
|---|---|
| 0-60 | 红 |
| 60-120 | 黄色 |
| 120-180 | 绿色 |
| 180-240 | 青色 |
| 240-300 | 蓝色 |
| 300-360 | 品红 |
饱和度:它指示颜色空间中的灰色范围。 范围是0到100%。 有时,该值是从0到1计算的。当值为“ 0”时 ,颜色为灰色;当值为**“ 1”时** ,颜色为原色。
值是颜色的亮度,并随颜色饱和度而变化。 范围是0到100%。 当值为**“ 0”时** ,颜色空间将完全为黑色。 随着该值的增加,色彩空间的亮度会提高并显示各种颜色。
在此程序中,我们将使用OpenCV-python(cv2)模块的三个功能。 我们先来看一下它们的语法和说明:
1)imread():
它以图像文件的绝对路径/相对路径作为参数,并返回其对应的图像矩阵。
2)imshow():
它以窗口名称和图像矩阵为参数,以便在具有指定窗口名称的显示窗口中显示图像。
3)cv2.cvtColor():
它需要图像矩阵和用于将颜色空间从一种颜色空间更改为另一种颜色的标志(在这种情况下,我们使用BGR2HSV颜色空间转换),并返回新转换的图像矩阵。
源码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
#这个函数跟本次实验的本质没有什么关系
#只是为了方便显示和记录在matplotlib上才写的
#如果没有这个函数,matplotlib上会显示成其他颜色。
def realimage(img):
b,g,r = cv2.split(img) #这个地方将图像拆分,把彩色图像分为3个颜色
plt.figure(figsize=(10,8))
color = [b,g,r]
img_2 = cv2.merge([r,g,b]) #这个地方我把bgr格式的图片转成了rgb,然后显示的时候会变成正常的彩色
return img_2
if __name__ == '__main__':
img = cv2.imread(r'd:/IDE/Python38_Resource/Images/pathfinder.jpg')
HSV_img = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
cv2.imshow('HSV format image',HSV_img)
cv2.waitKey(0)
img = realimage(img)
HSV_img = realimage(HSV_img)
titles = [u'original image', u'HSV format image']
images = [img, HSV_img]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i])
plt.title(titles[i])
plt.show()
效果图:
2. RGB转HSI
cv2.cvtColor函数封装了各种颜色空间之间的转换,唯独没有RGB与HSI之间的转换,网上查来查去也只有C++或MATLAB版本的,自己要用到python里,所以就写写python版本的。
HSI颜色模型是一个满足计算机数字化颜色管理需要的高度抽象模拟的数学模型。HIS模型是从人的视觉系统出发,直接使用颜色三要素–色调(Hue)、饱和度(Saturation)和亮度(Intensity,有时也翻译作密度或灰度)来描述颜色。
RGB向HSI模型的转换是由一个基于笛卡尔直角坐标系的单位立方体向基于圆柱极坐标的双锥体的转换。基本要求是将RGB中的亮度因素分离,通常将色调和饱和度统称为色度,用来表示颜色的类别与深浅程度。在图中圆锥中间的横截面圆就是色度圆,而圆锥向上或向下延伸的便是亮度分量的表示。
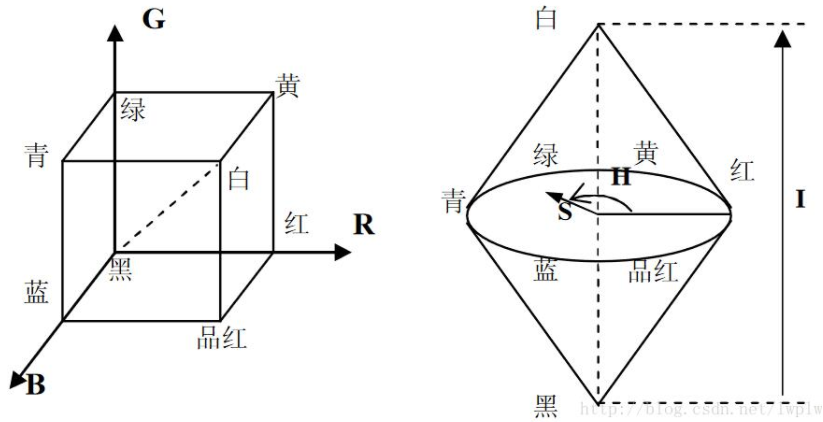
从RGB空间到HSI空间的转换有多种方法,这里仅说明最为经典的几何推导法。RGB与HSI之间的转换关系为:
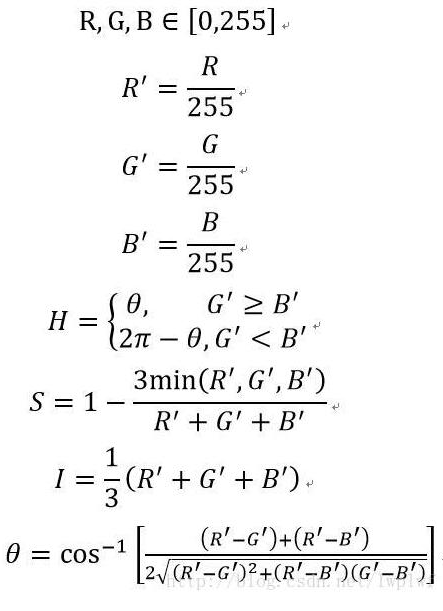
源码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
def rgbtohsi(rgb_lwpImg):
rows = int(rgb_lwpImg.shape[0])
cols = int(rgb_lwpImg.shape[1])
b, g, r = cv2.split(rgb_lwpImg)
# 归一化到[0,1]
b = b / 255.0
g = g / 255.0
r = r / 255.0
hsi_lwpImg = rgb_lwpImg.copy()
H, S, I = cv2.split(hsi_lwpImg)
for i in range(rows):
for j in range(cols):
num = 0.5 * ((r[i, j]-g[i, j])+(r[i, j]-b[i, j]))
den = np.sqrt((r[i, j]-g[i, j])**2+(r[i, j]-b[i, j])*(g[i, j]-b[i, j]))
theta = float(np.arccos(num/den))
if den == 0:
H = 0
elif b[i, j] <= g[i, j]:
H = theta
else:
H = 2*3.14169265 - theta
min_RGB = min(min(b[i, j], g[i, j]), r[i, j])
sum = b[i, j]+g[i, j]+r[i, j]
if sum == 0:
S = 0
else:
S = 1 - 3*min_RGB/sum
H = H/(2*3.14159265)
I = sum/3.0
# 输出HSI图像,扩充到255以方便显示,一般H分量在[0,2pi]之间,S和I在[0,1]之间
hsi_lwpImg[i, j, 0] = H*255
hsi_lwpImg[i, j, 1] = S*255
hsi_lwpImg[i, j, 2] = I*255
return hsi_lwpImg
def realimage(img):
b,g,r = cv2.split(img) #这个地方将图像拆分,把彩色图像分为3个颜色
plt.figure(figsize=(10,8))
color = [b,g,r]
img_2 = cv2.merge([r,g,b]) #这个地方我把bgr格式的图片转成了rgb,然后显示的时候会变成正常的彩色
return img_2
if __name__ == '__main__':
rgb_lwpImg = cv2.imread("d:/IDE/Python38_Resource/Images/pathfinder.jpg")
hsi_lwpImg = rgbtohsi(rgb_lwpImg)
cv2.imshow('rgb_lwpImg', rgb_lwpImg)
cv2.imshow('hsi_lwpImg', hsi_lwpImg)
key = cv2.waitKey(0) & 0xFF
if key == ord('q'):
cv2.destroyAllWindows()
hsi_lwpImg = realimage(hsi_lwpImg)
rgb_lwpImg = realimage(rgb_lwpImg)
titles = [u'RGB_Img', u'HSI_Img']
images = [rgb_lwpImg, hsi_lwpImg]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i])
plt.title(titles[i])
plt.show()
效果图:
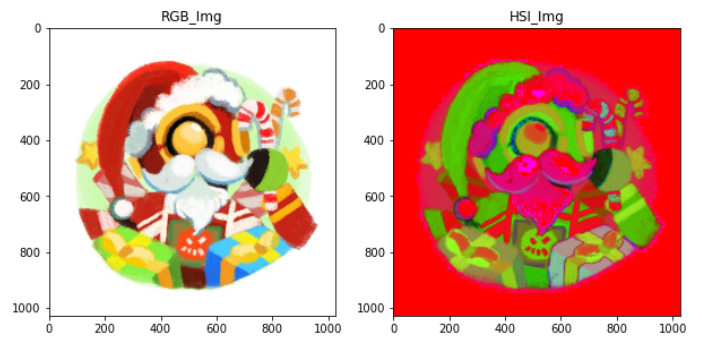
看得出来这里的绿色比HSV的更深一点
三、利用OpenCV+Python将车牌数字分割为单个的字符图片
1. 实现原理
车牌号检测大致分为以下四步:
1.车辆图像获取
2.车牌定位
3.车牌字符分割
4.车牌字符识别
实现原理:
-
车牌定位
-
利用canny将二值化后的图片进行边缘检测
-
多次进行开运算与闭运算消除小块区域,保留大块区域
-
利用cvv2.rectangle选取矩形框,定位车牌位置
-
-
字符分割
- 采用cv2.grabCut方法,将图像分割成前景与背景
- 二值化图片后进行字符分割
- 通过判断每一行每一列的黑白像素的位置定位字符
-
代码步骤
1.灰度转换:将彩色图片转换为灰度图像,常见的R=G=B=像素平均值。
2.高斯平滑和中值滤波:去除噪声。
3.Sobel算子:提取图像边缘轮廓,X方向和Y方向平方和开跟。
4.二值化处理:图像转换为黑白两色,通常像素大于127设置为255,小于设置为0。
5.膨胀和细化:放大图像轮廓,转换为一个个区域,这些区域内包含车牌。
6.通过算法选择合适的车牌位置,通常将较小的区域过滤掉或寻找蓝色底的区域。
7.标注车牌位置
8.图像切割和识别
2. 代码实现
资源文件准备:
-
将所有车牌集中到一个目录下面,并设置输出路径
-
确保所有资源文件,目录名称不包含中文,否则会出现
AttributeError错误
源码:
import cv2
import numpy as np
import os
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
# 用空图片补齐
for i in range(rows):
tmp = cols - len(imgArray[i])
for j in range(tmp):
img = np.zeros((imgArray[0][0].shape[0], imgArray[0][0].shape[1]), dtype='uint8')
imgArray[i].append(img)
# 判断维数
if rows>=2:
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
else:
width = imgArray[0].shape[1]
height = imgArray[0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2:
imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
# 分割结果输出路径
output_dir = "D:\\IDE\\Python38_Resource\\Images\\licence plate\\plate output\\"
# 车牌路径
file_path="D:\\IDE\\Python38_Resource\\Images\\licence plate\\"
# 读取所有车牌
cars = os.listdir(file_path)
cars.sort()
# 循环操作每一张车牌
for car in cars:
# 读取图片
print("正在处理"+file_path+car)
src = cv2.imread(file_path+car)
img = src.copy()
# 预处理去除螺丝点
cv2.circle(img, (145, 20), 10, (255, 0, 0), thickness=-1)
cv2.circle(img, (430, 20), 10, (255, 0, 0), thickness=-1)
cv2.circle(img, (145, 170), 10, (255, 0, 0), thickness=-1)
cv2.circle(img, (430, 170), 10, (255, 0, 0), thickness=-1)
cv2.circle(img, (180, 90), 10, (255, 0, 0), thickness=-1)
# 转灰度
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
adaptive_thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 333, 1)
# 闭运算
kernel = np.ones((5, 5), int)
morphologyEx = cv2.morphologyEx(adaptive_thresh, cv2.MORPH_CLOSE, kernel)
# 找边界
contours, hierarchy = cv2.findContours(morphologyEx, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 画边界
img_1 = img.copy()
cv2.drawContours(img_1, contours, -1, (0, 0, 0), -1)
imgStack = stackImages(0.7, ([src, img, gray], [adaptive_thresh, morphologyEx, img_1]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
# 转灰度为了方便切割
gray_1 = cv2.cvtColor(img_1, cv2.COLOR_BGR2GRAY)
# 每一列的白色数量
white = []
# 每一列的黑色数量
black = []
# 区域高度取决于图片高
height = gray_1.shape[0]
# 区域宽度取决于图片宽
width = gray_1.shape[1]
# 最大白色数量
white_max = 0
# 最大黑色数量
black_max = 0
# 计算每一列的黑白色像素总和
for i in range(width):
s = 0 # 这一列白色总数
t = 0 # 这一列黑色总数
for j in range(height):
if gray_1[j][i] == 255:
s += 1
if gray_1[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
# 找到右边界
def find_end(start):
end = start + 1
for m in range(start + 1, width - 1):
# 基本全黑的列视为边界
if black[m] >= black_max * 0.95: # 0.95这个参数请多调整,对应下面的0.05
end = m
break
return end
# 临时变量
n = 1
# 起始位置
start = 1
# 结束位置
end = 2
# 分割结果数量
num=0
# 分割结果
res = []
# 保存分割结果路径,以图片名命名
output_path= output_dir + car.split('.')[0]
if not os.path.exists(output_path):
os.makedirs(output_path)
# 从左边网右边遍历
while n < width - 2:
n += 1
# 找到白色即为确定起始地址
# 不可以直接 white[n] > white_max
if white[n] > 0.05 * white_max:
start = n
# 找到结束坐标
end = find_end(start)
# 下一个的起始地址
n = end
# 确保找到的是符合要求的,过小不是车牌号
if end - start > 10:
# 分割
char = gray_1[1:height, start - 5:end + 5]
# 保存分割结果到文件
cv2.imwrite(output_path+'/' + str(num) + '.jpg',char)
num+=1
# 重新绘制大小
char = cv2.resize(char, (300, 300), interpolation=cv2.INTER_CUBIC)
# 添加到结果集合
res.append(char)
# cv2.imshow("imgStack", char)
# cv2.waitKey(0)
# 构造结果元祖方便结果展示
res2 = (res[:2], res[2:4], res[4:6], res[6:])
# 显示结果
imgStack = stackImages(0.5, res2)
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
处理过程:
已其中一个车牌为例

螺纹与边框之类的干扰图形被去掉得很干净。

在展示了切割效果后保存在指定文件里:
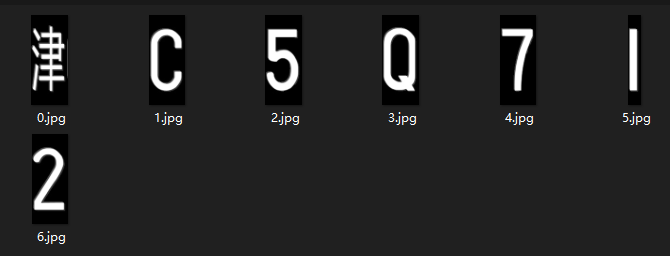
四、总结
在python中利用opencv或其他手段得颜色转换,可以从图片中切割出想要得部分。
五、参考文章
有情怀的机械男:【图像处理】——图像的灰度化处理(Python实现三种方法——最大值法、平均值法、加权均值法、gamma校正)
cumt30111: 在Python中使用OpenCV将RGB格式的图像转换为HSV格式的图像
六、源代码
https://github.com/Wattson1128/Artificial-Intelligence-Machine-Learning