Kafka概念类总结
一、kafka定义
是一个分布式的流处理平台(以前是主打发布/订阅模式的消息队列)。
主要有一下三个功能:
1、发布和订阅消息流,这一点和消息队列或者企业消息系统类似
2、以容错的方式存储消息流
3、在消息流产生时处理它们
应用场景:
1.消息系统:解耦生产者和消费者,缓存消息
2.流式处理:1、构建实时的流管道,可靠的在系统和应用之间获取数据 2、构建实时流的应用程序,对数据流进行转换或响应
二、优缺点
优点
1.持久性,可靠性:基于磁盘的数据存储且支持数据备份
2.扩展性:kafka支持横向扩展
3.高吞吐量、低延迟:kafka每秒可以处理几十万条数据,最低延迟几毫秒,每个topic可以分多个partition,由多个consumer group 对partition进行consume操作。
4.容错性:允许集群中节点错误,n个副本允许n-1个节点失败
5.高并发:支持上千个客户端同时读写。
缺点
1.数据是批量发送,并非实时
2.对mqtt协议不支持
3.只支持统一分区内消息有序,无法实现全局有序
4.依赖zookeeper 进行元数据管理
三 kafka名词
broker : 一台服务器就是一个broker,一个集群由多个多个broker组成,一个broker可以容纳多个partition
topic:可以理解为队列,每条发布到kafka集群的消息都有一个类别,这个类别成为topic。(物理上:不同的topic分开存储,逻辑上:一个topic上的消息保存在一个或者多个broker)
parition: 为了实现可扩展性,一个topic可以分布存储到多个broker中,一个topic可以分为多个partition ,每个partition都是有序的队列,kafka只能partition 内有序,不能保证全局有序。
producer:消息生产者,发布消息到kafka
consumer:消息消费者,向kafka broker集群 读取消息的客户端。
consumer group : 消费组,一组消费组由多个不同consumer组成,消费组不同的consumer负责消费一个topic不同partition 数据,一个partition只能由一个消费组内一个consumer消费。消费组是逻辑上一个消息订阅者。
replica : 副本,为了保证集群的高可用。当集群某节点发生故障时,为了保证数据partition不丢失,kafka提供了副本机制,一个topic的不同partition都有若干个副本,分为一个leader和多个follower。
leader: replica中的一个角色,producer和consumer只跟leader交互。一个partition一个leader
follower:负责从leader复制数据
controller : kafka集群中的一个服务器,中来选择leader 和faillover
AR(Assigned Replicas): partition中所有的f副本。
ISR(In-Sync-Replicas): 所有与leader同步程度保持一致的副本
OSR(Out-Sync-Replicas):所有与leader停滞后过多的副本
HW(Hight Watermark): 高水位,标识一个特定的消息偏移量,消费者只能拉到这个offsets 之前的数据
LEO(Log End Offset):标识当前文件最大的ofset,写一条待写入消息的offset
四 consumer和topic
一个group 有多个consumer,这样可以提高consumer消费消息的并发消费能力,同时增强容错性。如果group中的某个consumer失效了,消费的partition就会由其他的consumer自动接管。
一条消息只能被一个不同group 中的其中一个consumer消费,但是一个consumer 能同时消费多个partition的数据。
五 Kafka存储结构
kafka是基于topic分类消息的。
topic是逻辑上的概念,partition是物理上的概念,每个partition都会对应一个log文件,该log文件存储的就是producer生产的数据,producer生产的数据会不断累积加入log末端。
但是为了防止log文件过大,遍历消耗的时间过长,效率低下,kafka采取了分片和索引机制,将partition分为多个segment(段)(分片机制),每一个segment以当前segment存储第一条消息的offset为命名。
索引机制即每个segment会对应有一个"xx.log"和"xx.index"文件,log文件存储大量的数据,index文件则存放大量的索引信息。
例如index其中一条索引文件是 3,497 ,则指的是在同segment的log文件上第三条log消息,该消息的物理偏移量是497
例如图: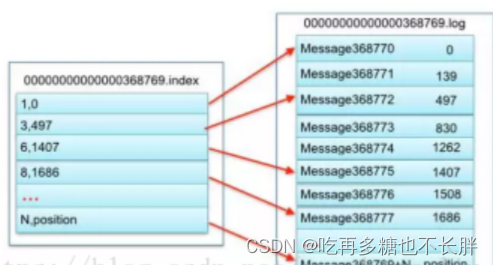
六 Producer
分区partition策略
原因:一个topic由多个partition组成,每个partition可以调整所在的服务器,方便集群横向扩展。(分布式))。2、可以提高并发读写数据,以partition为单位读写数据。
分区原则:分区可以有三种原则将数据分区为producerRecord对象。
1.分区的时候,用直接指明的值作为partition分区名。
2.没有指明partition分区名的时候,但是指明了key,将key的hash值和topic的partition进行取余得到partition值。
3.partition值和key都没有的情况下,kafka会采取sticky partition(黏性分区),随机选择一个分区,并且一直使用该分区,直至该分区的batch已经满了或者该topic已经完成了。
七 Consumer
消费方式
consumer 采用pull(拉)模式从broker拉取数据。
不使用push,推是因为推模式的发送数据 的 速率是由broker决定的,这样当消费者消费速率不一致的时候容易产生拒绝服务和网络拥塞。
但是pull也有缺点,如果kafka没有数据,则消费者可能会一直陷入循环中,返回空值。所以kafka消费数据时候会传入一个时长参数timeout。如果没有数据可供消费的时候,consumer会等待一段时间后再返回,这段时间为timeout。

partition分配consumer策略
rangeAssignor:
默认策略,对于每个topic,设consumer总数为c,partition总数为p,则rangeAssignon会用p/c的结果得出区间值r,以及余数值p%c为m。
然后consumer会根据预设好的member id字典排序,从第一个consumer进行顺序分配,前m个consumer分配连续的(r+1)个partition,后(r-m)个consumer分配连续的r个partition。
即如果不能平分,前面的consumer会被分配多一个partition。
这种策略是尽量平分分配partition的。
roundRobinAssignor
roundRobin是轮询的意思,roundRobinAssignor策略还是先将consumer进行字典排序,然后同时也将partition按字典排序,然后进行轮询分配。
stickyAssignor
略
consumer 消费offset维护
为了防止consumer在消费数据的时候出现断电宕机等意外,方便consumer继续从故障前的位置继续消费数据,所以consumer需要实时记录自己消费到了哪个offset。
kafka0.9前consumer默认将消费offset保存在zookeeper,后面版本后offset数据会保存在kafka内置的topic,_consumer_offsets。
八 数据可靠性和一致性
分区可靠性
每个partition都有一个replica机制进行数据冗余,每一个分区都有leader和follower,所有的读写操作都由leader负责,follower 定期进行复制数据。当leader挂了,follower会进行选举成新的leader。
副本数据同步的可靠性
副本同步策略有两种
1、半数follower完成同步,就发送ACK确认同步, 这样的优点是延迟低,缺点是选举新的leader的时候,容忍n台节点故障,需要2n+1个副本。
2、全部follower完成同步,就发送ACK确认同步,这样优点是选举新leader时,容忍n台节点故障,需要n+1个副本, 缺点是延迟高。
kafka默认是选择第二种,原因:
1、目的都是为了容忍n台节点故障,但是方案一需要2n+1个副本,方案二只要n+1个副本,kafka每个分区都有很大的数据量,方案一造成冗余过多。
2、方案二缺点是网络延迟高,但是网络延迟对kafka影响比较小。
消息发送ACK机制可靠性
producer发送数据给follower的时候,kakfa在producer制定了消息确认机制。可以通过配置来选择发送到分区partition的几个副本中才算成功。
1.ACK=0 最低延迟,partition的leader收到数据还没写入磁盘就发送ack,此时leader发送故障时候,会丢失数据
2.ACK=1 partitiond的全部leader罗盘成功后,才返回ACL,确认数据已发送成功。如果follower同步成功之前发送leader故障,数据可能会丢失。
3.ACK=-1(all):需求等到partition的leader和follower全部落盘后,leader才返回ack说消息发送成功。 当leader发送ack之前leader故障,数据可能回重复。
ISR集合一致性
副本同步策略选择方案二后,leader 会维护一个动态的ISR(in-sync-replica set),意思是跟leader保持一致的集合。
ISR是为了防止全部follower同步数据时,防止有一个follower遭遇故障未及时跟leader同步数据,长时间不发生ACK给leader。
当部署了ISR后,如果follower长时间不同步数据,该follower会被提出ISR集合,leader发送故障时,新leader只会从ISR的节点中选举。
高水位线High water mark 一致性
LEO:每个副本的最大的offset
HW高水位线:每个副本消费者consumer能读取到的最大的offer,也是ISR的最小的LEO。
这两个作用:
1:当follower发生故障时:follower发送故障,会被提出ISR,当follower恢复后,会读取记录的上次consumer读取的HW,然后将log文件里面高于HW的的数据截掉,然后向leader同步,当follower数据追上leader后,就能重新加入ISR.
2:当leader发生故障,会从ISR重新选出Leader,然后为了保持副本的一致性,其他follower会将各自log高于HW的数据截掉。然后从新的leader同步数据
上面第2条只能保持数据一致性,不能保整数据可靠性。
九、exactly one和 at most one 以及at least one
at most one
最多一次,将服务器的ack设置为0,每条生产者数据只会被发送一次,数据传输不会重复数据,但是可能会丢失
at least one
至少一次,服务器的ack设置为-1,可以保证数据传输不会丢失数据,但是可能存在重复数据。
exactly one
0.11版本后,kafka引入幂等性,即无论paoducer发送多少条重复数据,server段只会持久化一条数据。所以是at least on + 幂等性 = exactly one
参数:enable.idempotene 设置为true
十 kafka高效读写数据
顺序写磁盘
kafka 的producer生产数据,要写入log文件中,写入的时候是直接追加文件末端,顺序写入,顺序写入可以省去大量的磁头寻址时间。
零拷贝技术
linux系统依赖底层的senfile()方法实现了内核下数据的零拷贝,将数据直接从磁盘文件复制到网卡设备中,减少内核和用户模式下的上下文切换,大大提升了应用程序的性能。
批量发送
kakfa发送数据不是实时的每条每条的发送,为了节约网络带来的性能开销,kafka会对消息进行批量发送。
通过batch.size调整批量提交的大小,默认16k。当同一分区积压的消息量达到这个值后就会统一发送。
数据压缩
producer段会压缩,broker保持,consumer进行解压。
稀疏索引
index 文件中没有为数据文件中每条message建立索引,而是采取了稀疏存储的方式,每隔一定字节的数据建立一条索引,这也为了避免索引占用过多空间,从而可以将索引文件保留再内存中。
十一 zookeeper在kafka中作用
kafka集群会有一个broker被选举为controller,负责集群的broker上下线工作,以及所有topic的分区副本分配和leader选举工作。
以上的这些工作包括负载均衡,都需要zookeeper进行维护管理。