1. 准备工作

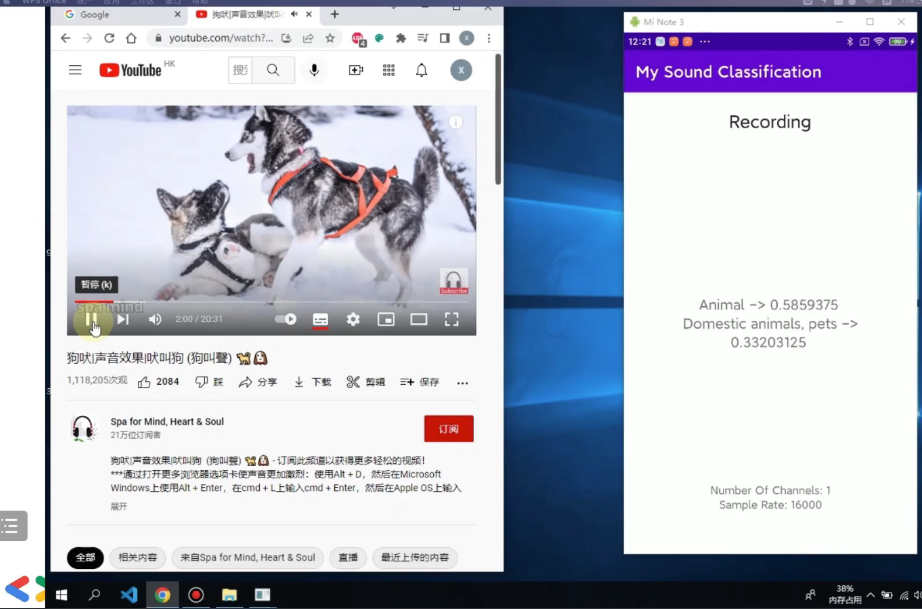
实现效果:
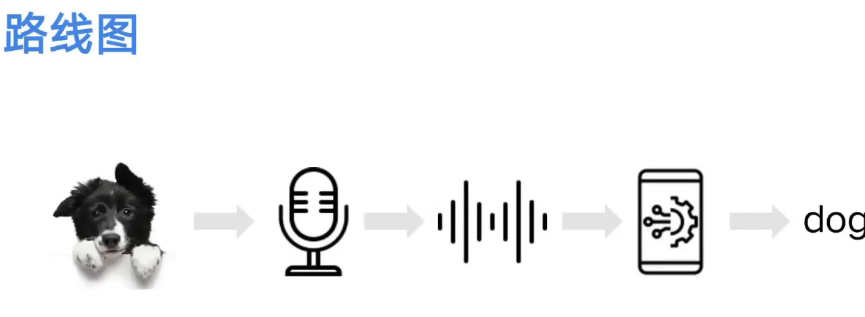
整体流程:
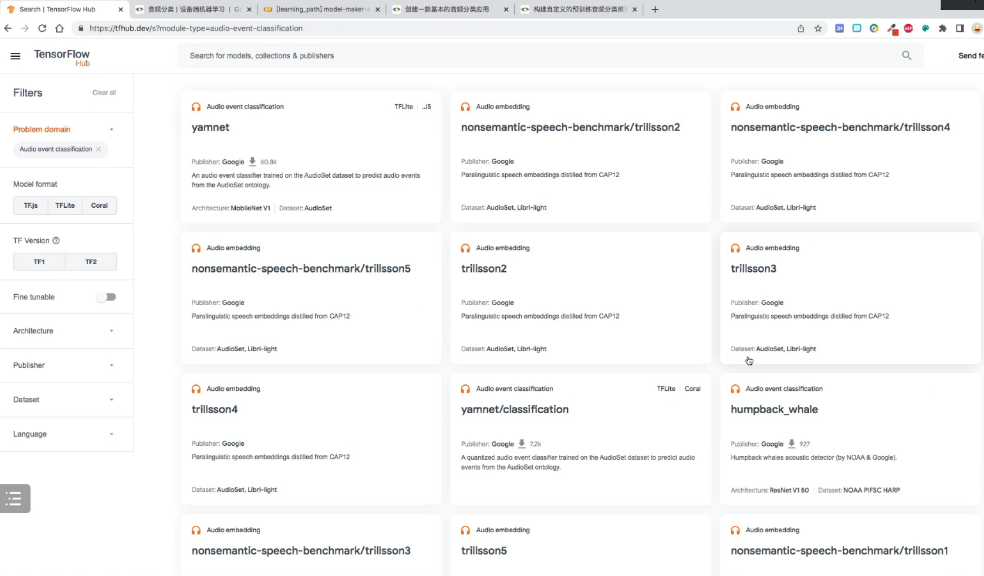
1. 获取模型
- 获取训练好的模型 : 通过从Tensorflow Hub (https://tfhub.dev/)上获取训练好的模型,
- 自定义模型:适用于自己任务的分类模型。
1.2 yamnet 网络模型
其中 yamnet 网络模型,包含两种:
一种是 float32 , 另外一种是 int8;
量化部分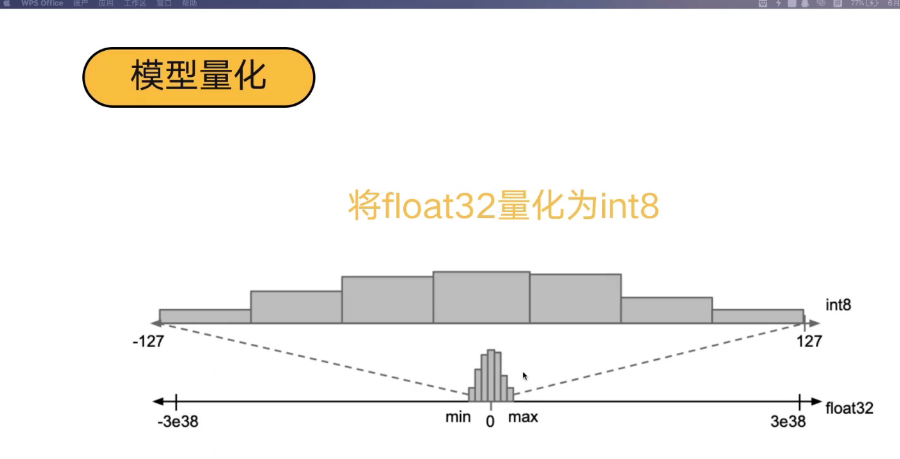
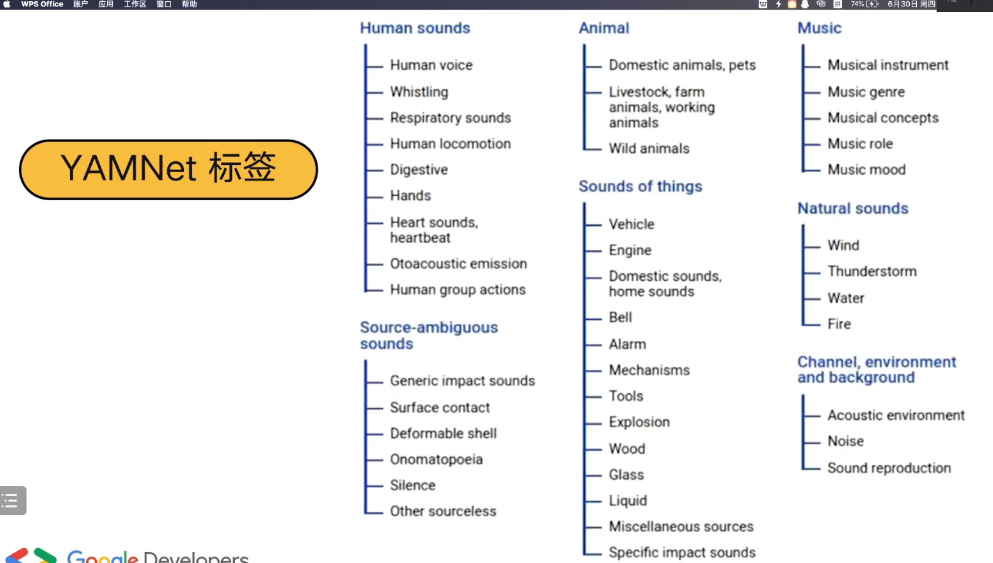
1.3 YAMNet 音频识别的种类
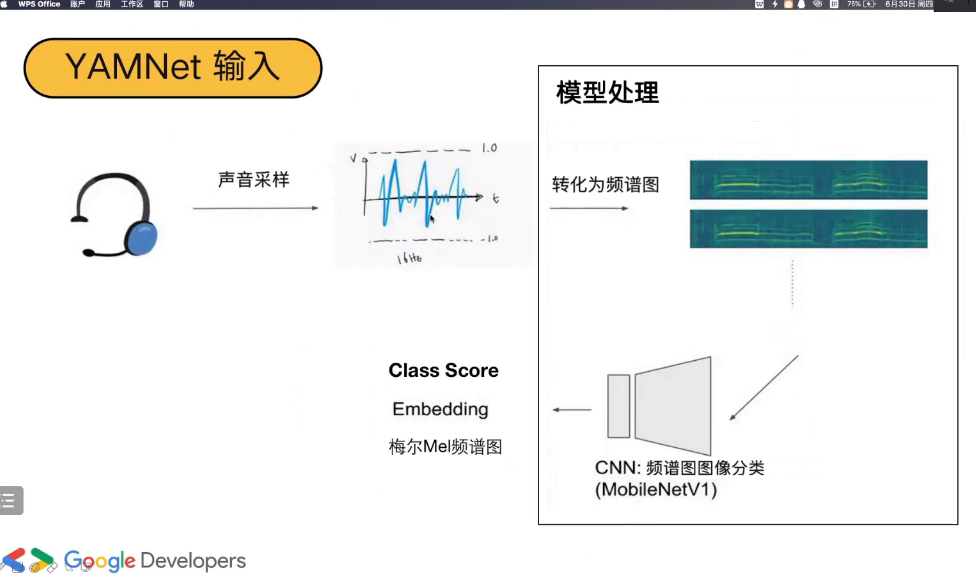
1.4 yamNet 工作流程
声音信号,经过采样。 对音频转化为频谱图;
2. 模型加载到Android- 工程中:
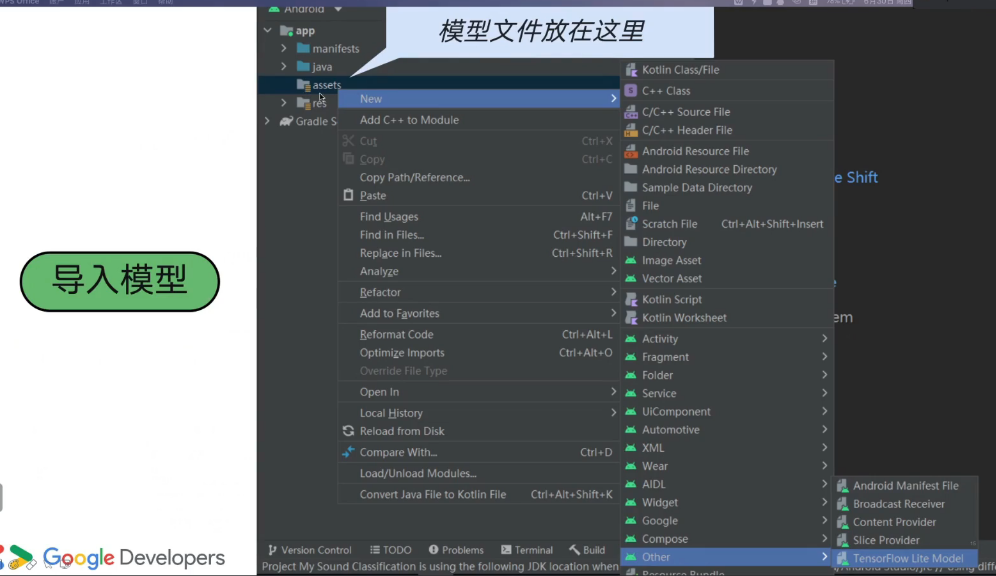
-
导入模型

-
模型使用指引
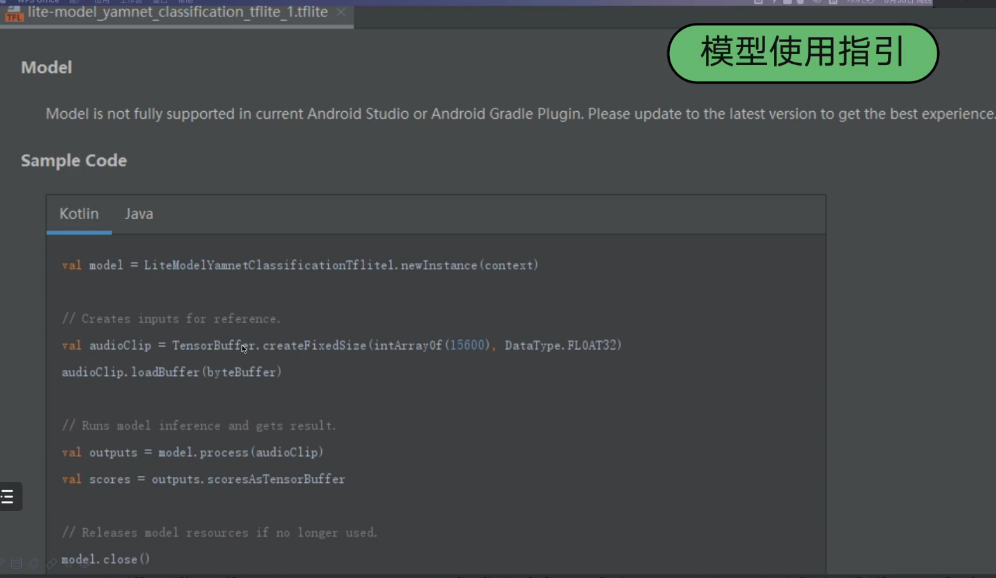
- 训练模型的参数规则
- 使用模型
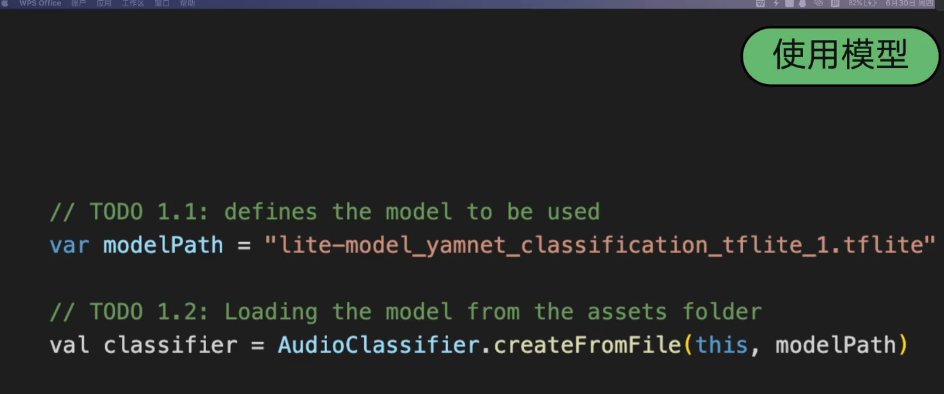
3. 音频的录制与导入
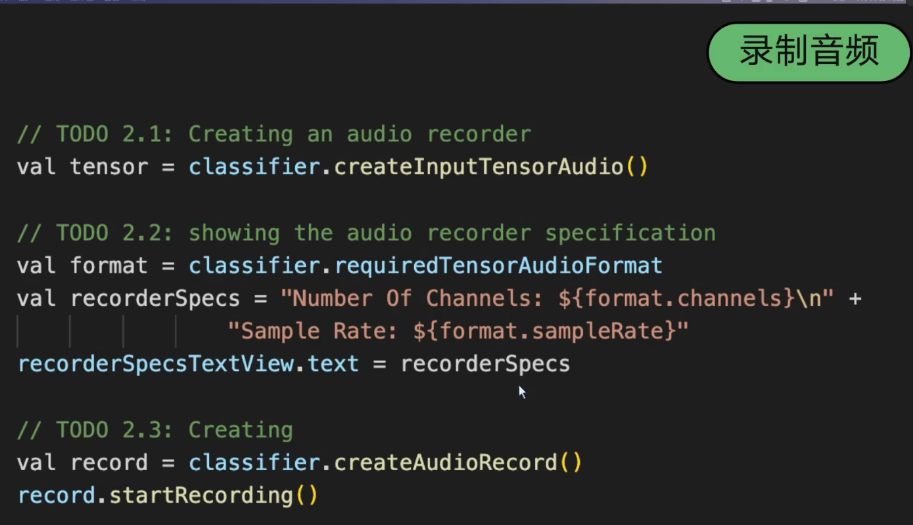
3.1. 录制音频

3.2. 设置音频的采样率与通道数
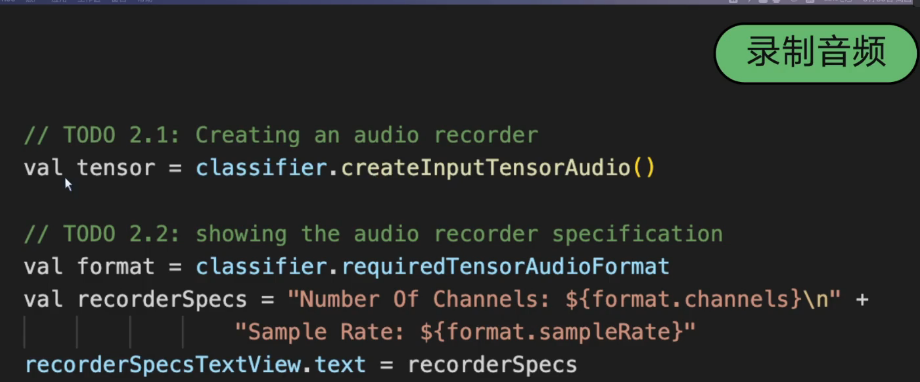
3.3. metadata, 模型的规格设置
附加在Lite 模型上的一组与推演过程本身无关的的描述信息。
包括以下几种:
- 模型支持的输入类型
- 模型支持的输出类型
- 模型附加的文件
- 数据归一化参数
- 模型量化参数
3.4 音频的基础参数

3.5 录制音频的方法调用
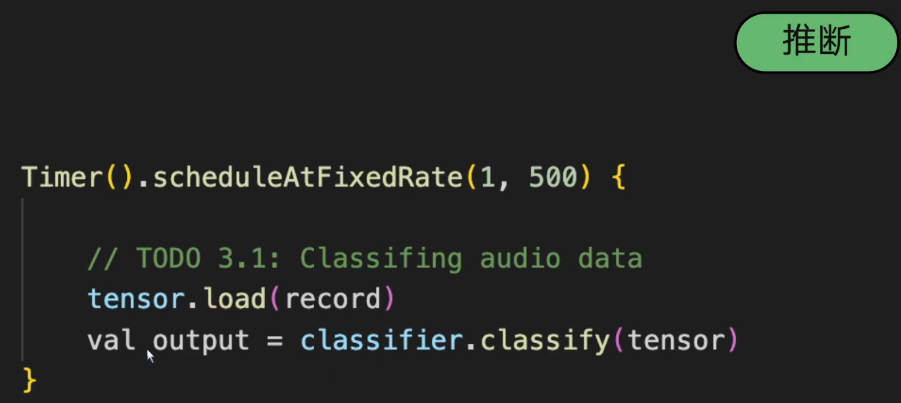
3.6 模型推理
每间隔 500 个时间单位推理一次;
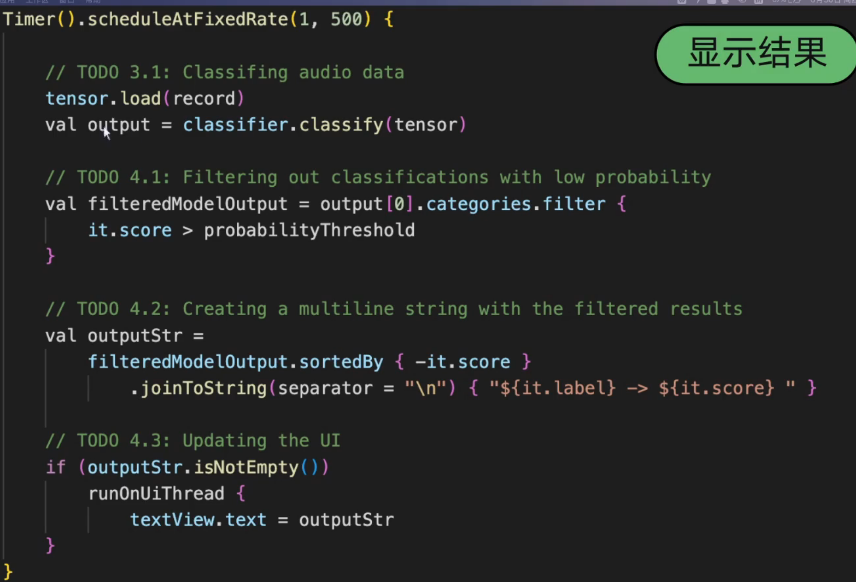
3.7 显示结果
3.8 小结
- 在TensorFlow Hub 中查找模型
- 在 Android 工程中加载模型
- 使用模型处理 Android 的输入与输出
4. 自定义的模型分类
本节 主要介绍:
01 如何自定义音频分类模型
02 如何在 Android 工程中加载自定义模型
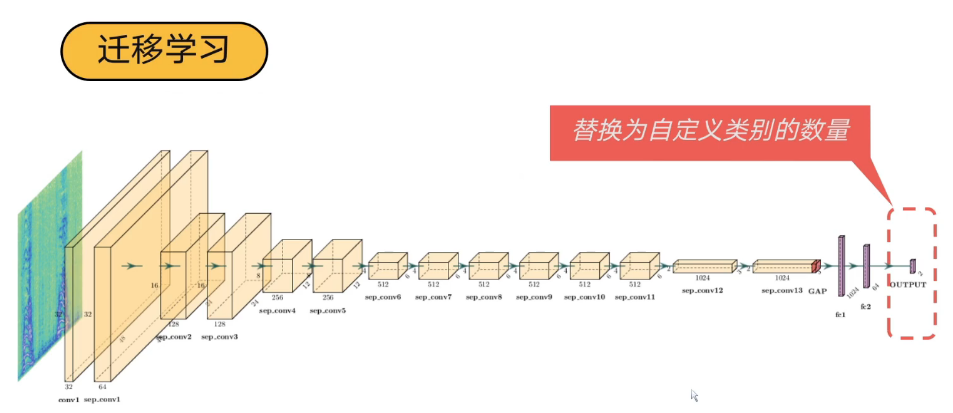
4.1 迁移学习
使用原始模型, 更改最后网络的输出;
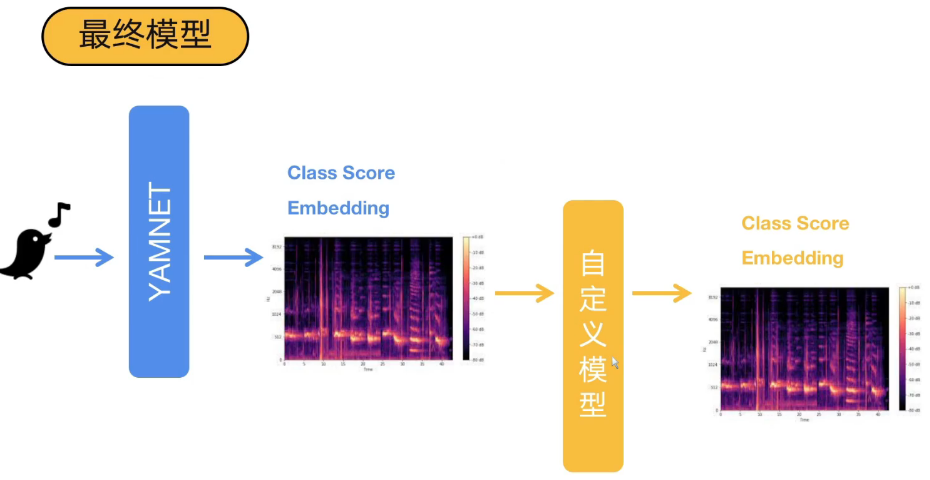
4.2 YamNet 模型的输入与输出
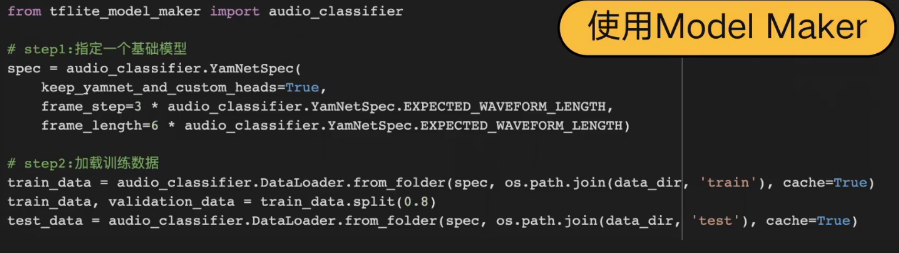
4.3 Model_maker 的调用
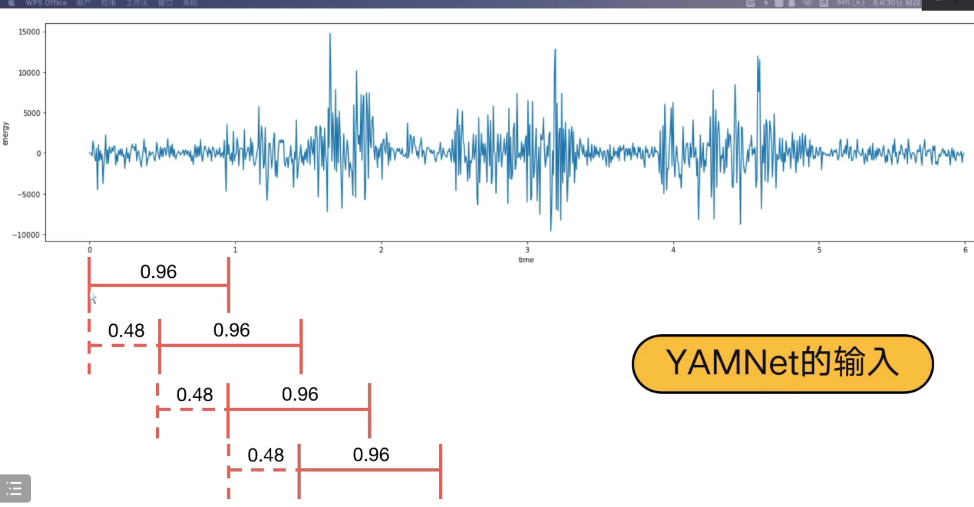
4.4 音频的分帧
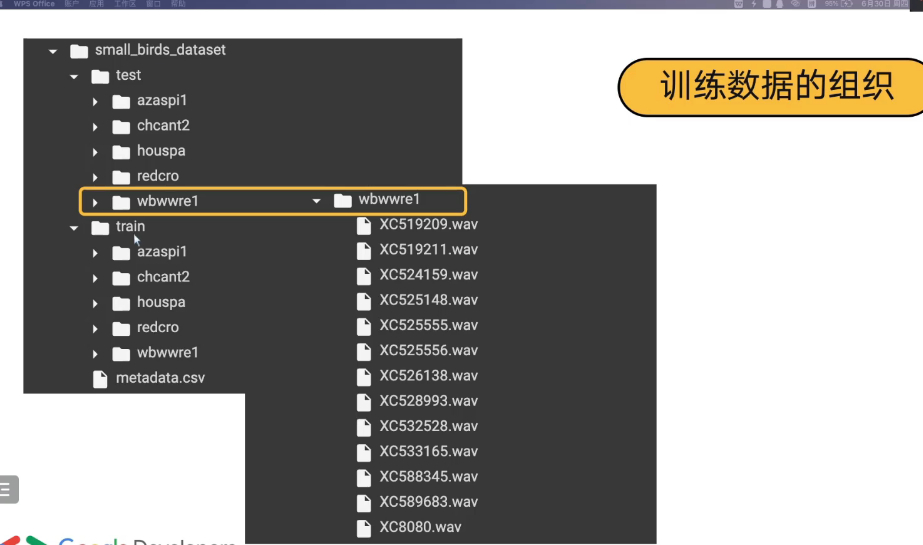
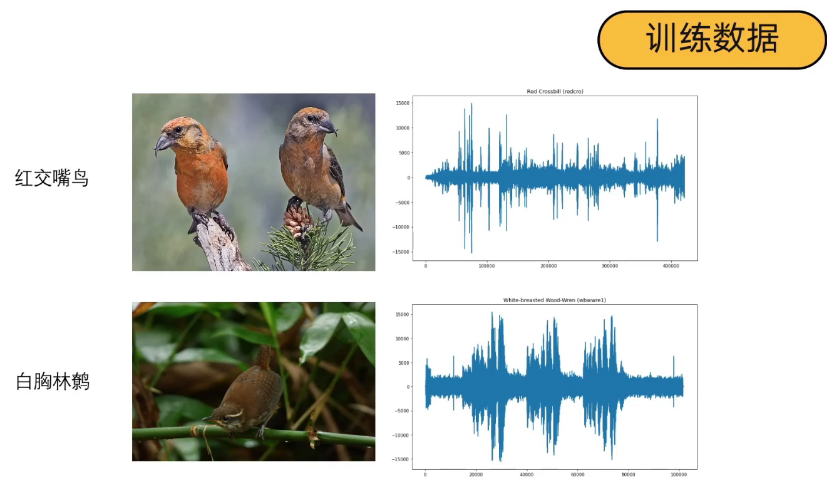
4.5 数据集设置
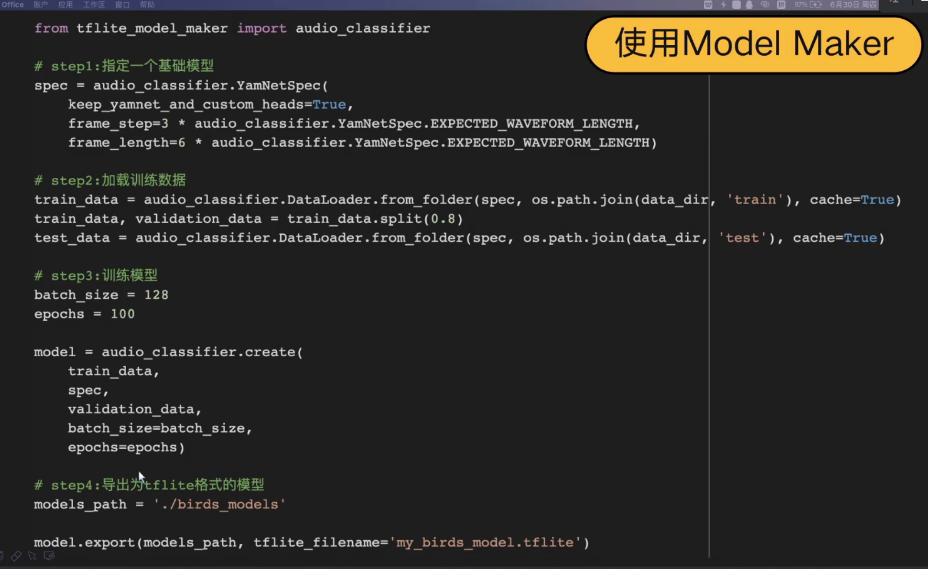
4.6 Model Maker 的调用步骤
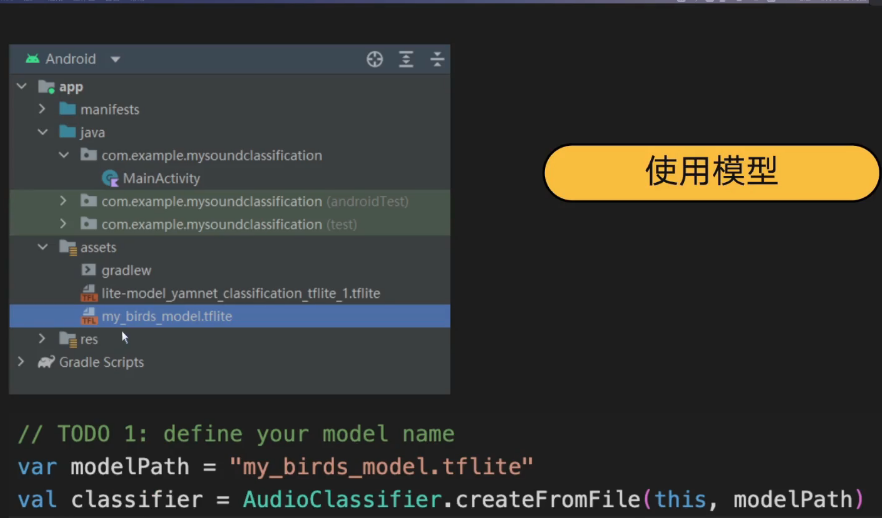
4.7 使用模型
4.8 结果分析
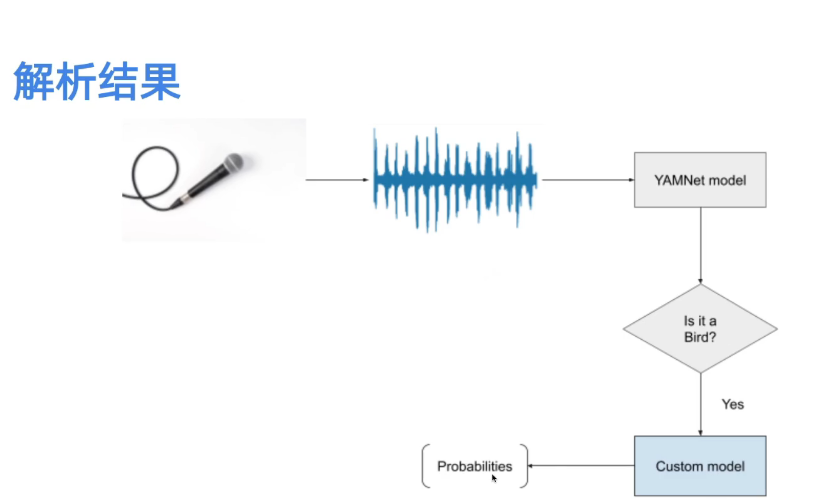
工作流程,
- 通过 YamNet 先判断输入的音频是何种大类类的音频;
- 在确定属于该大类的情况下, 将特征再次 输入到 自定义的另一个模型该大类下,细分出 多个小类;
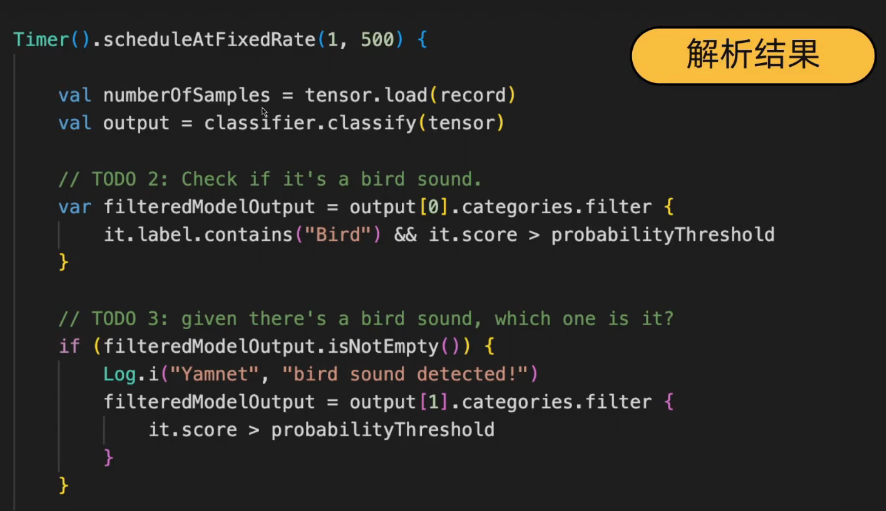
代码分析
5. 性能的优化
5.1 获取更多的数据集

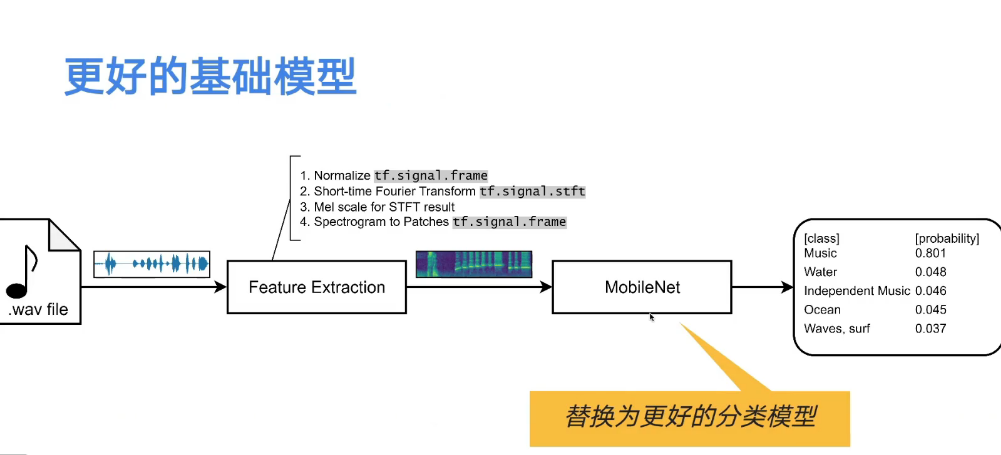
5.2 使用更优解的模型
5.3 自定义数据集的录制规格
以下规格, 适配于yamNet 模型, 从而使得该模型发挥的更好

6. 参考资料
6.1 

音频的分类, 分两步走:
先进行二分类的任务,
比如先通过二分类,先判断是否为该大类A,
然后,再通过在该大类下, 对音频的进行细分各个小类;
