1. Borg
Borg是谷歌内部的大规模集群管理系统,负责对谷歌内部很多核心服务的调度和管理。Borg的目的是让用户能够不必操心资源管理的问题,让他们专注于自己的核心业务,并且做到跨多个数据中心的资源利用率最大化。
Borg主要由BorgMaster、Borglet、borgcfg和Scheduler组成,如下图所示
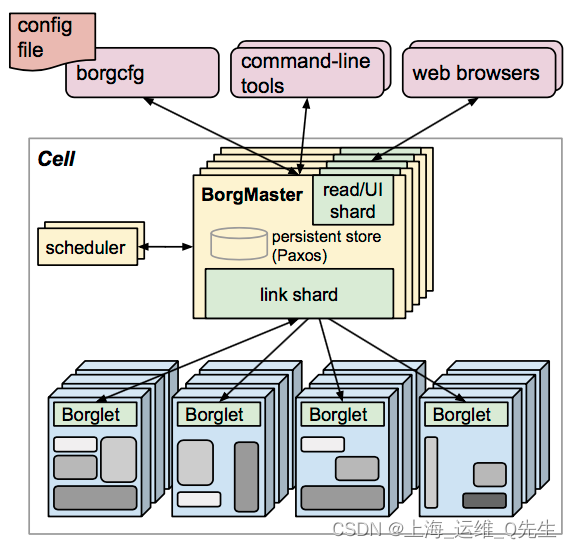
- BorgMaster是整个集群的大脑,负责维护整个集群的状态,并将数据持久化到Paxos存储中;
- Scheduer负责任务的调度,根据应用的特点将其调度到具体的机器上去;
- Borglet负责真正运行任务(在容器中);
- borgcfg是Borg的命令行工具,用于跟Borg系统交互,一般通过一个配置文件来提交任务。
2. Kubernetes架构
Kubernetes借鉴了Borg的设计理念,比如Pod、Service、Labels和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,如下图所示
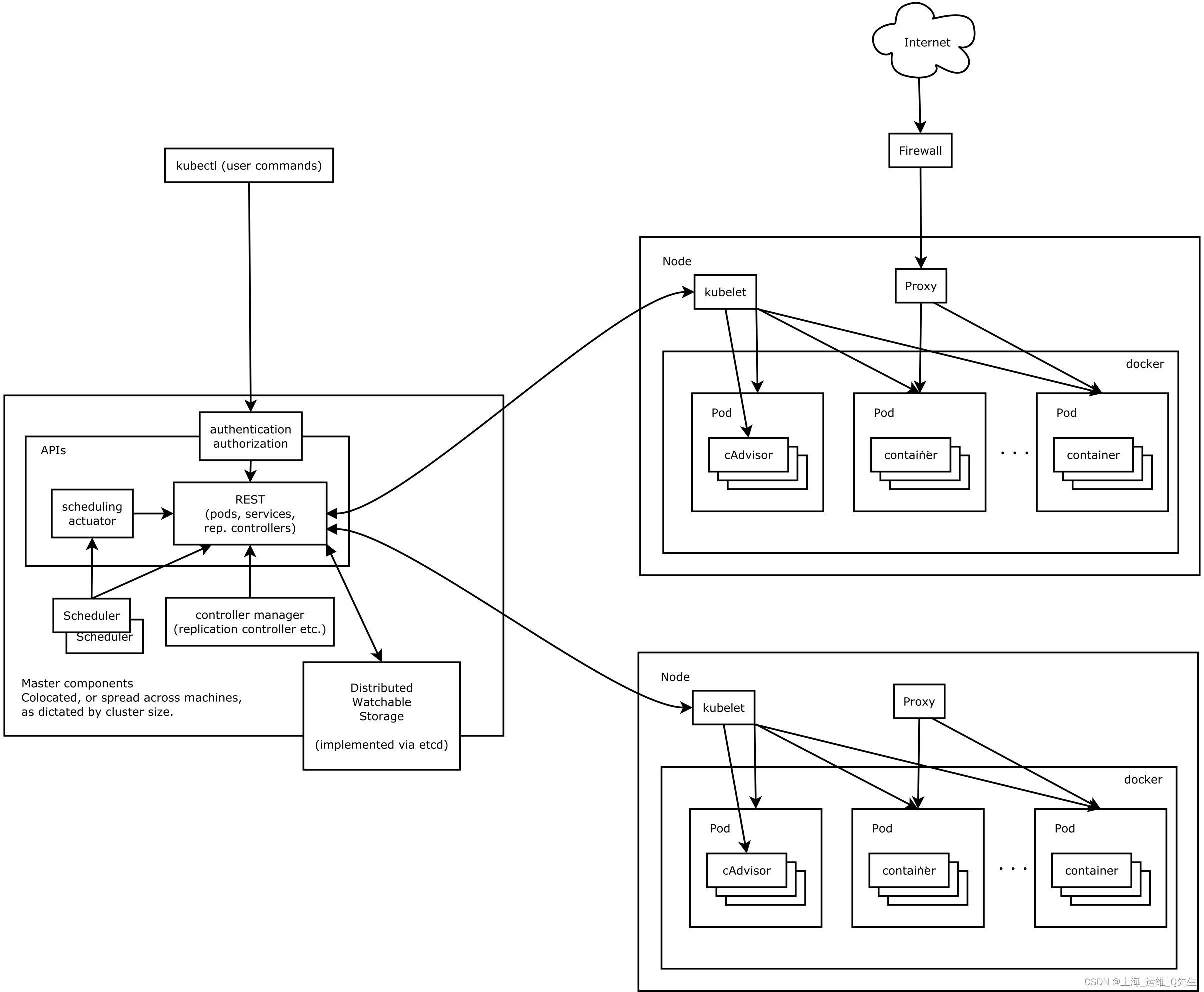
Kubernetes主要由以下几个核心组件组成:
- etcd保存了整个集群的状态;
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的Add-ons:
- kube-dns负责为整个集群提供DNS服务
- Ingress Controller为服务提供外网入口
- Heapster提供资源监控
- Dashboard提供GUI
- Federation提供跨可用区的集群
- Fluentd-elasticsearch提供集群日志采集、存储与查询
2. API设计原则
- 所有API应该是声明式的.(只需要指定关键的元素)类似yaml
对应的是命令式的(需要将参数一一列出)类似docker run - API对象是彼此互补且可组合的
一个工作需要多个api互相协作组合完成 - 高层API以操作意图为基础设计
- 低层API根据高层API的控制需求设计
- 尽量避免简单封装,不要有在外部API无法显示知道内部隐藏的机制
- API操作复杂度与对象数量成正比
- API对象状态不能依赖网络的连接状态
- 尽量避免让操作依赖于全局状态,因为在分布式系统中保持全局状态同步是非常困难的.
3. API对象
- 资源对象
Pod,ReplicaSet,ReplicationController,Deployment
StatefulSet,DaemonSet,Job,CronJob,HorizontalPodAutoscaling
Node,Namespace,Service,Ingress,Label,CustomResourceDefinition - 存储对象
Volume,PersistentVolume,Secret,ConfigMap - 策略对象
SecurityContext,ResourceQuota,LimitRange - 身份对象
ServiceAccount(用户),Role(权限),ClusterRole(集群角色)
- cordon和uncordon
容器将不再被调度到该节点
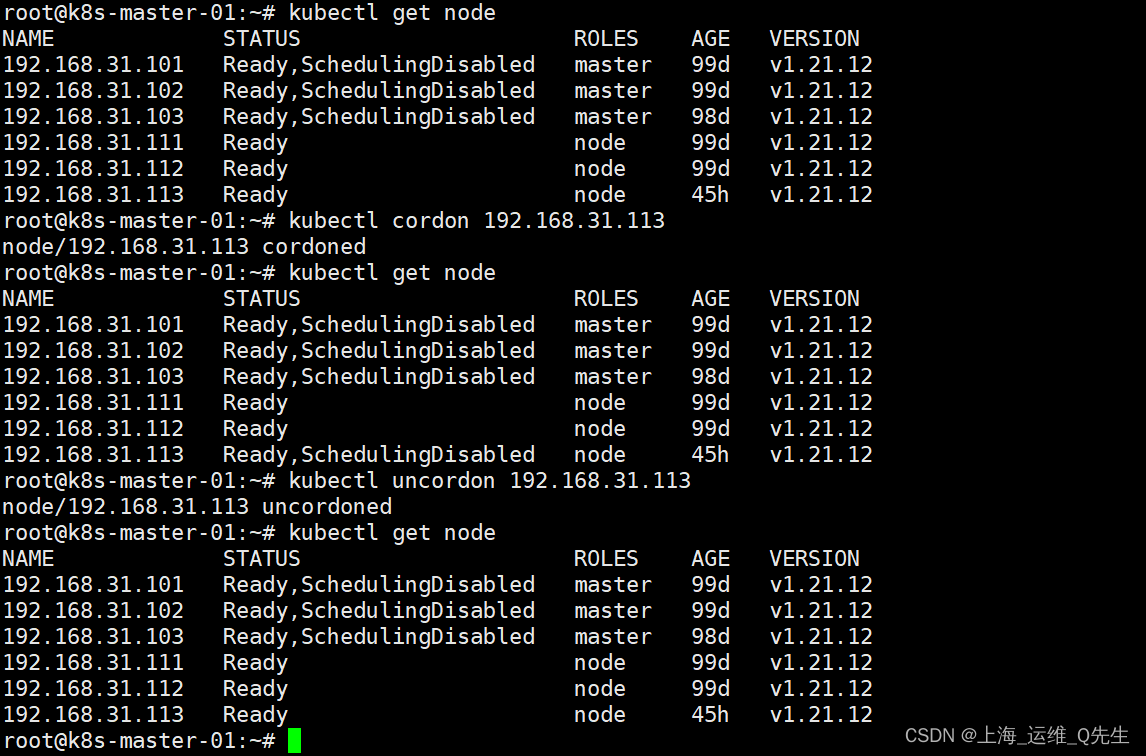
- drain
容器将被从该节点驱逐并在其他节点创建 - taint
给节点打污点,反亲和. 和LABEL的亲和正好相反
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: ng-deploy-80
template:
metadata:
labels:
app: ng-deploy-80
spec:
containers:
- name: ng-deploy-80
image: nginx:1.14.2
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ng-deploy-80
spec:
ports:
- name: http
port: 81 # service pod
targetPort: 80 # pod服务监听的端口
nodePort: 30012 # node节点通过api-proxy监听的端口
protocol: TCP
type: NodePort
selector:
app: ng-deploy-80
- spec 是期望状态
- status是实际状态
4. Pod
概述:
- Pod是K8s中最小单元
- 一个pod中可以运行1个或者多个容器
- 运行多个容器的话,这些容器是一起被调度的
- Pod的生命周期是短暂的,不会自愈,用完就销毁的实体.
- 一般我们是通过Controller来创建和管理Pod.
4.1 Pod的声明周期
- 初始化容器
- 启动前操作
- 就绪探针
- 存活探针
- 删除pod操作
5. 探针
- livenessProbe 存活探针
检测应用发生故障时使用,不能提供服务,超时等检测失败重启pod - readinessProbe 就绪探针
检测pod启动之后应用是否就绪,是否可以提供服务检查成功,pod才开始接收流量
6. 控制器
-
Replication Controller 第一代pod副本控制器,用来维持副本数.匹配目的时只能用= 和!=匹配
控制器直接管理副本
apiVersion: v1
kind: ReplicationController
metadata:
name: ng-rc
spec:
replicas: 2
selector:
app: ng-rc-80
#app1: ng-rc-81
template:
metadata:
labels:
app: ng-rc-80
#app1: ng-rc-81
spec:
containers:
- name: ng-rc-80
image: nginx
ports:
- containerPort: 80
-
ReplicaSet 第二代pod副本控制器,用来维持副本数.对选择器支持selector还支持in notin
控制器直接管理副本
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
spec:
replicas: 2
selector:
matchExpressions:
- {
key: app, operator: In, values: [ng-rs-80,ng-rs-81]}
template:
metadata:
labels:
app: ng-rs-80
spec:
containers:
- name: ng-rs-80
image: nginx
ports:
- containerPort: 80
-
Deployment 第三代pod副本控制器 比rs更高一级的控制器,还支持滚动升级和回滚
deployment会另外再创建一个rs,容器数量由deployment的rs负责创建和回收
创建新的版本,会在pod创建完回收老的pod,但rs不会被回收,用作今后的回滚
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
#app: ng-deploy-80 #rc
matchLabels: #rs or deployment
app: ng-deploy-80
# matchExpressions:
# - {key: app, operator: In, values: [ng-deploy-80,ng-rs-81]}
template:
metadata:
labels:
app: ng-deploy-80
spec:
containers:
- name: ng-deploy-80
image: nginx
ports:
- containerPort: 80
Deployment创建的pod名字由3部分组成
例如:nginx-deployment-6b9f6c7549-dtr2z
第一部分是nginx-deployment由控制器的metadata的name决定
metadata:
name: nginx-deployment
第二部分6b9f6c7549是生成随机rs的名字
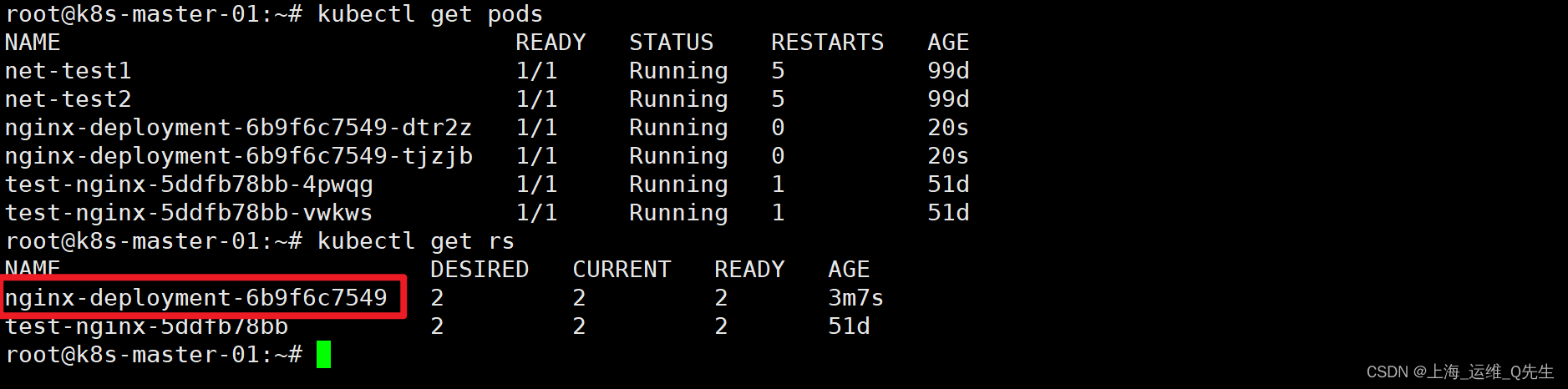
7. Service
- ExternalName 把K8S以外的服务暴露给内部使用
- ClusterIP 只能通过k8s内部访问,外部访问不到
- NodePort 通过node暴露给外部使用,内部访问service也可以
- LoadBalancer 公有云使用,把公有云的负载均衡作为服务访问入口
为什么使用Service
Pod重建之后IP会发生变化,这样pod之间的访问就会发生异常
Service解耦了服务和应用
kube-proxy有三种调度模式:
userspace: k8s1.1之前
iptables: 1.2-k8s1.11之前
ipvs: k8s1.11之后,如果没有开启ipvs就会自动降级到iptables