版权声明: https://blog.csdn.net/JENREY/article/details/84205838
1、Kubernetes介绍

2、k8s的架构
架构图

架构是master/node的主从架构
master:API Server ,Scheduler,Controller-Manager (这三个是组件,也是守护进程)
node:kubelet,docker,kube-proxy
- API Server:负责接收请求,解析请求,处理请求。
- Scheduler:调度器,调度容器创建的请求,负责去观测每一个node之上总共可用的CPU,RAM和存储资源并根据用户所请求创建容器的资源量(因为在k8s上我们可以设定容器的资源上限和资源下限我们成为资源请求量),调度器就是根据容器的最低需求,来进行评估,哪一个节点最合适。因此k8s设定了一个两级调度的方式来完成调度,第一步先做预选(先评估一下到底有多少个是符合这个容器运行需求的节点,比如有三个)。第二步要做优选,从这三者中在选择一个最佳适配,到底哪个是最佳取决于调度算法当中的优选算法来决定的。
- kubelet:集群代理,用于能够与master通信的,接收master和调度过来的各种任务由他来执行的我们称为集群代理,是保证容器始终处于健康运行状态的软件。简单来讲API Server把任务编排以后由Scheduler来调度,Scheduler的调度结果由kubelet来执行。比如启动pod、在本地上管理pod健康、创建存储卷等等都由kubelet来执行,但是kubelet本身并不能运行容器,他最多就能接收任务,并在本机上试图启动容器,运行容器就需要容器引擎来运行,最流行的引擎就是docke,是用于pod中的容器的而创建的。
- 控制器:是用来不断的监听他所管理的每一个容器是否是健康的,一旦发现不健康,控制器就负责向MasterServer发请求再调度重新启动一个。k8s支持很多类型的控制器,控制容器自身健康的只是一种,他还有其他的控制器。我们以后就不能在k8s上称呼容器了,因为k8s最小运行地单元是pod。
- Controller-Manager:控制器管理器,负责监控每一个控制器是健康的,他本身是高可用的,是冗余的。假如Master是三个节点,那么Master每一个上面都有一个控制器管理器,大家都在的时候这三个控制器管理器只有一个正常工作,他是主节点,其他都是做冗余的。
- pod:是k8s的最小运行地单元。其可以理解为容器的外壳,给容器做了一层抽象的封装,pod是k8s系统之上最小的调度的逻辑单元,他的内部主要是用来放容器的,pod有一个工作特点:一个pod内可以包含多个容器,多个容器共享同一个底层的网络命名空间Net(网络设备、网络栈、端口等),UTS(主机名和域名)和IPC(信号量、消息队列和共享内存)三个网络名称空间,另外三个互相隔离User、MNT、PID是互相隔离的。所以说pod对外更像是一个模拟虚拟机,而且同一个pod下的容器还共享存储卷,存储卷就不在属于容器而属于pod。各个node主要是运行pod的,一般说一个pod只放一个容器,除非容器之间有非常紧密的关系需要放在同一个pod中,通常我们他们中的一个容器为主容器,其他的容器是辅助这个主容器中的应用程序完成更多功能来实现的。其他的辅助容器也成为 边车。我们为pod打上标签,用标签来识别pod,能让控制器或者是人能够基于标签的值来识别出pod的,比如我们创建了4个nginx pod,我们可以给每一个pod上加上一个标签叫app这个叫key,他的值都等于nginx,当我们想挑出来这些pod的时候就找key是app的并且值是nginx的就ok了。标签不是pod独有的,因为k8s是restfull风格的api,几乎所有被操纵的目标都是对象,几乎所有的对象都可以拥有标签,可以用标签选择器操作。
- Label select:标签选择器,根据标签来过滤符合条件的资源对象的机制,把感兴趣的pod挑出来的组件。
- kube-proxy:管理server,关于这个的详解请点击kubernetes 简介:kube-proxy 和 service
- etcd:是一个开源的、分布式的键值对数据存储系统,提供共享配置、服务的注册和发现。etcd与zookeeper相比算是轻量级系统,两者的一致性协议也一样,etcd的raft协议比zookeeper的paxos简单;他要是宕机了整个集群也就宕机了,所以要高可用,一个端口用于集群内通信,一个端口用于向客户端提供服务
- CNI:容器网络接口,是k8s的外部接入的网络服务解决方案,能遵循CNI开发的这个服务那么就能作为k8s的网络解决方案来使用,事实上这些解决方式可以以插件的方式托管在集群之上。常见的有 flannel:网络配置。calico:网络配置,网络策略。canel等
Pod分为两类:
- 自主式pod:自我管理的。没法实现全局进行调度。
- 控制器管理的pod:(我们建议使用这种)正是由于控制器的设计,pod才被成为有生命周期的对象。
Pod的常用控制器:
- ReplicationController:副本控制器,多退少补。
- ReplicaSet:副本集控制器,他不直接使用他有个声明式更新的控制器Deployment来管理。
- Deployment:(我们用的最多)只能负责管理那些无状态的应用,还支持二级控制器叫HPA(HorizontalPodAutoscaler:水平pod自动伸缩控制器)
- StatefulSet:有状态副本集,负责管理那些有状态的应用
- DaemonSet:我们需要在每一个node上运行一个副本而不是随意运行还需要DaemonSet
- job:要运行作业
- Ctonjob:周期性任务化作业
集群的附件:
- DNS
k8s集群的三种网络:


3、k8s的安装部署
k8s的两种常见部署方案
- 传统的部署方式:让k8s自己的相关组件统统运行为系统级的守护进程,这包括master节点上的四个组件,以及每个node节点上的三个组件,都运行为系统级守护进程,但是这种安装方式每一组都需要我们手动解决,包括做证书等等,而安装过程也需要我们手动解决,编辑配置文件也需要手动解决,他的配置过程繁琐而复杂,一般第一次部署需要一天左右的时间能调通。
- kubeadm:这个工具是k8s官方的集群部署管理工具,实现一种自我管理的方式把k8s自己也部署为pod,至少核心组件部署为pod,包括master和各node所在内的所有节点,我们还需要手动安装和部署,但是只需要部署kubelet和docker就行了。因为docker是运行容器的引擎,kubelet是负责能运行pod化容器的核心组件。那么每一个节点都装上kubelet和docker,也就意味着,运行容器及运行pod的基础环境我们已经准备好了。在此基础之上我们能够实现把master的相关四个组件统统运行为pod,就是直接托管在k8s之上,而后把每个node节点上的余下的组件叫kube-proxy也运行为pod,那整个集群就跑起来了。要注意以上说的这些pod都是静态pod(static pod,不受k8s的管理,只不过运行为pod的形式而已)而不是我们之前讲过的能够接受k8s自身管理的pod。我们的flannel也是需要托管的,每一个节点包括master和各node节点还需要部署flannel,以支撑他们部署的pod资源彼此之间能够互相通信的。但是这个flannel的的确确是托管在k8s集群之上的附件,他不像前面那几个都是静态的pod,都是动态的由k8s自身管理的pod。
k8s的安装部署
进入k8s官网:点我去官网

点击进入releases,我们去下载把master和node分开组织的包,按下图红框所示

无论master还是node用的都是server端的东西就是Server Binaries
上述这种都是属于安装的第一种运行为系统级守护进程的方式。
我们采用下述的方式进行安装:
进入阿里云镜像库点我进入


但是发现里面没有程序包,我们就拷贝一下页面地址,使用yum install就可以安装了
yum install https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
记得要关闭防火墙和ipv6
配置yum仓库
下图均为在master上的操作
- 先配置docker的仓库


不用进行修改了
- 配置kubernetes的仓库
![]()
写入下图的内容

其中的baseurl的值是下图所示

其中的gpgkey的值是下图所示

然后运行yum repolist命令

然后通过scp发送给node1和node2节点

- 下面开始在master节点进行安装:



kubectl是apiServer的命令行客户端
出现下图表示安装完成

- 启动docker的服务:
![]()
加入下图所示内容


可以看到下图所示信息

- 启动kubelet:
先查看都安装生成了哪些文件
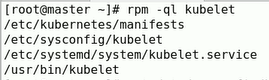
清单目录/etc/bubernetes/manifests
配置文件/etc/sysconfig/kubelet
主程序/usr/bin/kubelet