
文 | QvQ
对于开放域检索式QA系统而言,其本质是计算question和doc的本文相似度,而作为老生常谈的文本相似度问题,有监督方法的性能历来是要好于无监督算法的。
今天要介绍的文章,反其道而行之,不仅采用了无监督算法,而且将由question计算doc的检索任务转为由doc反推question的任务,并取得了多个任务上的SOTA。
论文题目:
Questions Are All You Need to Train a Dense Passage Retriever
论文链接:
https://arxiv.org/pdf/2206.10658.pdf
 1.前言
1.前言
当前检索模型下层多采用大型PLM作为热启,上层接特定任务,通过大量有监督数据进行有finetune最小化对比损失,这种检索器是开放领域任务(如Open QA)模型中的核心组件。
在本文中,我们引入了一种基于无监督语料库级auto-encoding的无监督方法———ART(Autoencoding-based Retriever Training )。ART的关键思想是将检索到的文档作为原始question的噪声表示,将对question重构概率作为一种去噪的方式,当“噪声”越来越少的时,检索精度也就越来越高。
 2.方法
2.方法
2.1 问题定义
对于开放域检索问题,给定一个问题,任务是从大量的候选文档中中选择一个包含答案的小集合。
目标:以零样本学习的方式训练检索器,即不使用标注的question-doc对,也能检索出相关文档来回答问题。
2.2 双编码器
对于检索器,采用了经典的双塔结构,即对和分别编码:
表示文本序列的通用集合,表示由离散符号组成的词汇表,为隐层embeddings向量空间,然后将问题文档对的检索得分定义为它们的内积:
为编码器参数,之后选择内积得分最大的top-k文档,并记录为。
两个编码均使用的是以BERT tokenization为输入的transformer结构输出得到。同时为了获得原始question和doc的embeddings层(用于对question重构),新增了一个forward结构。将embeddings层与最后一层的[CLS] token一同作为编码输入。
2.3 零样本学习
通过使用预训练语言模型(PLM)来获得一个检索文档对的相关性得分的估计。为了满足零样本学习范式,使用大规模生成式PLM来计算doc在该question为条件时的得分似然。
其中可以通过利用teacher-forcing对question token的条件自回归生成来更好地近似。更正式的写法是:
402 Payment Required
为PLM的参数,是一个常数,与文档无关。表示问题token的数量。是简单地根据贝叶斯变换得来,可以认为doc的先验是均匀分布的。此时,。
我们假设使用计算相关性得分是准确的,因为它需要对所有问题和文档标记进行deep cross-attention。在大型PLM中,cross-attention具有很强的推理能力。另一方面,结合teacher-forcing,模型需要理解问题中的每个token,从而得到更好的对score进行估计。
输入文档包含title和content两部分,对文档的title和content进行concat并由[SEP]标记进行分隔。为了有效兼容PLM,促使其能生成原始question,在文档最后附加了一条简单的自然语言指令“请根据这段文字写一个问题”。
2.4 训练算法
我们唯一的假设是提供一系列query和候选文档作为输入。在训练过程中,只更新检索器的权重,而PLM不再参与finetune。
训练算法包括五个核心步骤,如下图所示。前四个步骤在每次训练迭代中执行,而最后一个步骤每几百次迭代执行一次。
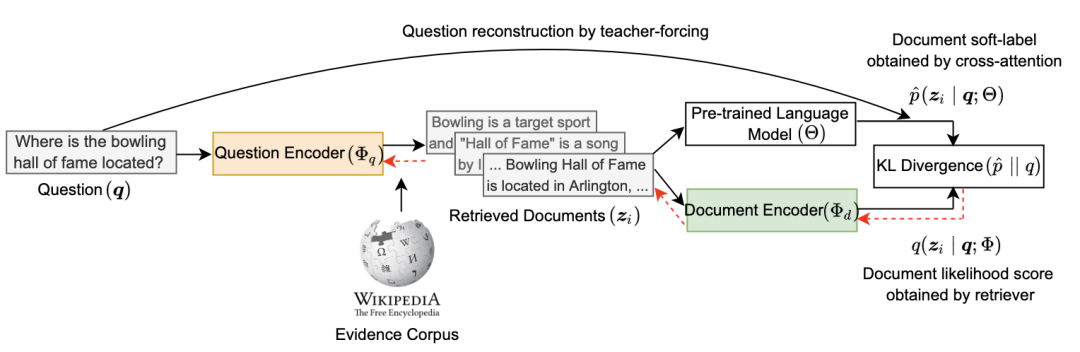
Step 1:检索Top-k文档
为了快速检索,我们使用初始doc编码器参数预计算候选doc的embeddings表示。同理,对于给定一个问题,我们使用当前的问题编码器参数计算隐层embeddings表示,然后根据检索top-K文档。
然后,我们对这top-k文档采用更新完之后最新的doc编码器参数来计算一个新的得分:
402 Payment Required
Step 2:计算似然估计
对于所有候选文档,对得分进行softmax归一化:
402 Payment Required
τ为温度系数。但是计算这个得分是相当复杂的,需要对所有的文档计算其隐层表示。因此作者为定义了一个新的分布来计算其似然估计。
ττ
可以看到,这个分布为全部候选文档的子集,作者将这个新的分布称之为学生分布(student distribution.):假设top-K之外的文档贡献了很小的概率质量(probability mas),因此只在分母中对所有检索到的文档(即top-k文档)求和。
虽然这种近似会导致对top-K文档的得分似然存在一个有偏计算,但Eq.3仅需处理更少的候选文档,实践也表明它在实践中工作得很好。
Step 3:相关性得分估计
使用一个大型)来计算中所有文档的相关性得分,计算方案即采用2.3节公式所示,同时这里需要使用teacher-forcing的计算doc下对question token的条件概率得分。然后,将softmax应用于该分数来定义一个新的教师分布:
402 Payment Required
Step 4:定义与优化
此时,我们有学生分布(由检索器计算)和教师分布(由PLM获得)两个分布,那么这两个分布有什么关系呢?可以看到,这两个分布都表示对top-k文档得分分布的估计,这两个分布越接近则说明说明越收敛,那么只要通过最小化教师分布和学生分布之间的KL散度损失来训练检索器,就可以保证loss逐步减小,直至收敛。
ττ
直观上,优化KL散度是通过将question与doc的相关性分数作为soft-label,使得检索器的文档似然分数与PLM的文档相关性分数形成统一。
Step 5:更新文档embeddings
在训练过程中,会同时更新问题编码器和文档编码器的参数。在训练初期,预计算文档的embeddings使用的是初始检索器参数,这可能会影响之后迭代过程中的top-K文档检索。
为了防止滞后现象,在训练过程中每过500 steps,利用最新的文档编码器参数来重计算文档的embeddings。
 3.实验
3.实验
3.1零样本段落检索
对于开放域检索任务,文中对比了SQuAD-Open、TriviaQA、NQ-Open和WebQ四个数据集的实验结果,并在两种模式下训练ART。
模式一:使用训练集中的question为每个数据集训练一个单独的检索器。
模式二:为了检验ART训练对不同问题类型的鲁棒性,我们将来自所有四个数据集的问题结合起来训练一个单一检索器,我们称之为ART-multi。由于训练过程中不需要对question-文档段落标记label,故称之为零样本段落检索。
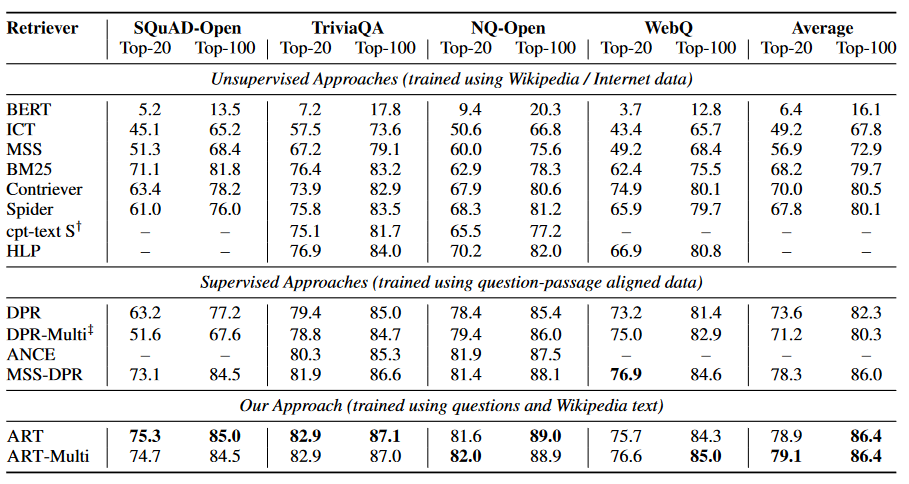
对测试集的数据集检索精度分别为top-20和top-100,同时对比了有关无监督和有监督模型的训练详细。如上图所示,ART同时超过了当前无监督和有监督模型的性能。
3.2样本影响
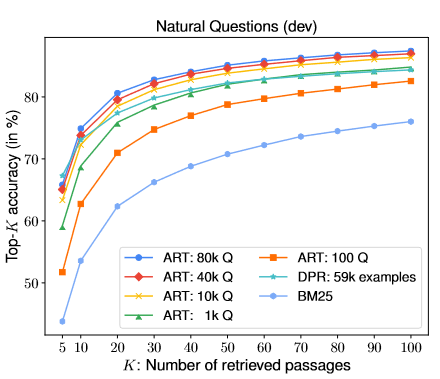
为了衡量样本数量对于ART的影响,我们从NQ-Open训练问题中随机选择不同数量的问题训练模型,并计算其在验证集的top-K精度。
这些结果如图2所示,我们还包括BM25和DPR的结果以供比较。可以看到成绩随着题目的增加而增加,直到大约10k题之后提升就不那么明显了。
3.3模型迁移能力
在之前的实验中,训练集和测试集都是从相同的基础分布中抽样的问题,我们将这种设置称为分布内训练(in-distribution training)。
然而,仅训练领域内同分布的question在实践证明并不总是可行的。相反,在现有的问题集合上训练的模型必须在新的数据集上评估,这种设置我们称为 分布外(OOD,out-of-distribution)迁移能力。
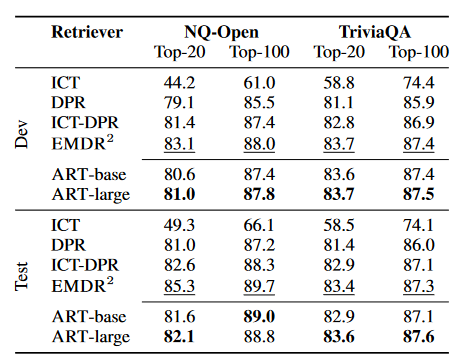
如图所示为ART在大规模检索时top-20和top-100精度表现。最佳监督结果下划线显示,而最佳非监督结果以粗体突出显示。可以看到,ART在模型迁移能力上略低于最新的EMDR有监督模型,但整体还是有不俗的表现。
 4.回顾 & 小结
4.回顾 & 小结
本文提出了一种无监督自回归模型的训练算法,借助PLM计算question-doc的相关性得分作为soft-label,拟合检索器从当前doc重构query的条件概率分布。依据贝叶斯变换,将两个问题转化为对同一分布的近似描述。
其实可以看到,整个训练过程中检索出的top-k文档是作为潜在优化变量的。回想一下,PLM被冻结了,它的参数没有更新。而PLM的输出被用来训练双编码器,以保证重构问题q的对数似然是最大的。
此时,在实际在训练过程的表现为:对双编码器的不断优化使得对于给定问题q逐渐选择出最佳文档,因为最大化目标的唯一方法是在给定输入q的情况下选择最相关的 。
这种在与结果在交互过程中通过学习策略以达成回报最大化很类似强化学习思路,在搜索、QA领域确实是一种比较新颖的尝试。
同时在搜索场景下,无监督数据更是取之不尽用之不竭,甚至还有自带用户反馈的弱监督数据。我们有充分理由相信,在工业界中此算法还有更进一步的空间!
萌屋作者:乐乐QvQ。
硕士毕业于中国科学院大学,前ACM校队队长,区域赛金牌。竞赛混子,Kaggle两金一银,国内外各大NLP、大数据竞赛Top10。校招拿下国内外数十家大厂offer,超过半数的SSP。目前在百度大搜担任搜索算法工程师。知乎ID:QvQ
作品推荐:
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群