本文介绍的论文题目是:《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》
论文下载地址是:Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
本文是谷歌工业风论文的新作,介绍了在大规模推荐系统中使用双塔模型来做召回的一些经验,值得细细品读。本文仅对文章内容做一个简单介绍,更多细节建议阅读原论文。
1、背景
大规模推荐系统一般分为两阶段,即召回和排序阶段,本文重点关注召回阶段。
给定{用户,上下文,物品}的三元组,一个通用的方法首先是分别计算{用户,上下文} 和 {物品} 的向量表示,然后通过一定的方式如点积来计算二者的匹配得分。这种基于表示学习的方法通常面临两个方面的挑战:
1)工业界中物品的数量十分巨大。
2)通过收集用户反馈得到的数据集十分稀疏,导致模型对于长尾物品的预测具有很大的方差,同时也面临着物品冷启动的问题。
工业界现有的推荐系统都需要从一个超大规模的候选集中拉取item进行打分排序。解决数据稀疏和指数级候选集分布的一种通常做法是从item的内容特征中学习出item的稠密表示。这里很自然地就想到了工业界大名鼎鼎且应用广泛的双塔神经网络结构,其中的一塔就是从丰富的item内容特征中学习到item的表示。
工业界目前训练双塔结构一般是通过随机mini-batch的方式来优化损失函数。这种训练方式存在的一个显著问题就是in-batch loss会因为随机采样偏差而导致模型效果不好,尤其是当样本分布出现明显倾斜的时候。我们提出了一种全新的算法,可以从流式数据中预估item的频率。通过理论分析和实验,新算法有能力在不知道候选集全部的词典情况下做出无偏差的估计并且可以自适应候选集分布的变化。在Youtube线上的实验也证明了该算法的有效性。
我们考虑一种通用的推荐问题设定:给定一系列query和候选集,目标就是在给定query的情况下返回最相关的一个候选子集。针对这里的query和候选集中的item,都可以用各自的特征向量来进行表示。在个性化推荐场景中,则是用户user和会话的上下文context构成这里的query侧。
都知道Youtube的推荐架构主要分为两个阶段:召回和排序。而本文则主要聚焦于新增一路如下图所示的双塔召回。query侧的塔是由大量的用户观看历史形成的user features以及共同的seed features构成,候选集侧的塔则是由视频特征构成。训练样本的Label则是由用户的点击和播放时长加权得到。
模型架构
近几年来,随着深度学习的发展,双塔模型常用来用做召回阶段的模型,双塔模型的一般结构如下:
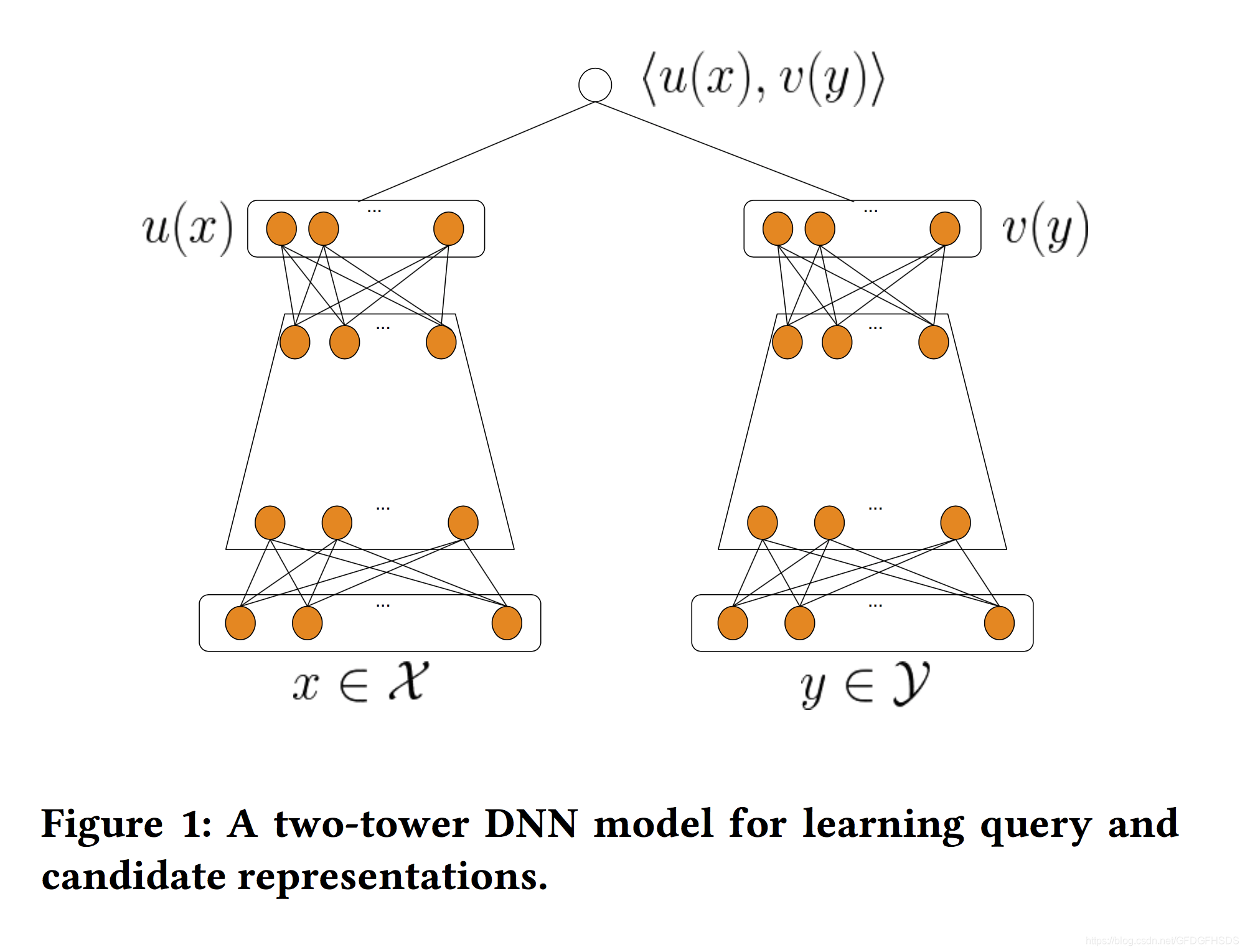
可以看到,双塔模型两侧分别对{用户,上下文} 和 {物品} 进行建模,并在最后一层计算二者的内积。对于每一个正样本,需要随机采样一些负样本,当物品数量十分巨大的时候,上述结构的双塔模型很难得到充分训练。
那么如何对双塔模型进行一定的改进呢?本文主要提出了以下两个要点:通过batch softmax optimization来提升训练效率和通过streaming frequency estimation来修正sampling bias。
2、模型介绍
2.1 batch softmax optimization
假设训练集包含T条,物品数量为M:
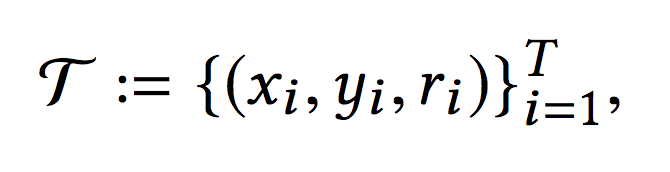
x包括了用户特征和上下文特征,y则是物品特征,r是对应的label,x和y经过双塔模型得到对应的向量表示,分别记作u(x,θ)和v(y,θ),并通过内积得到二者的相似性得分:
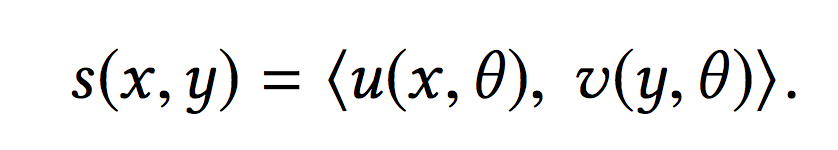
那么给定一个x,从M个物品中选择对应y的概率可以经由下面的softmax方程得到:
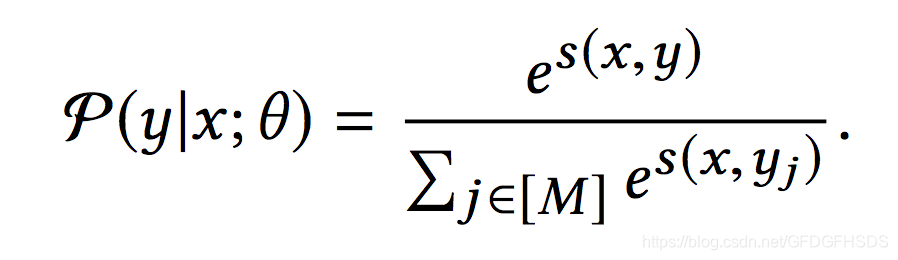
损失函数如下
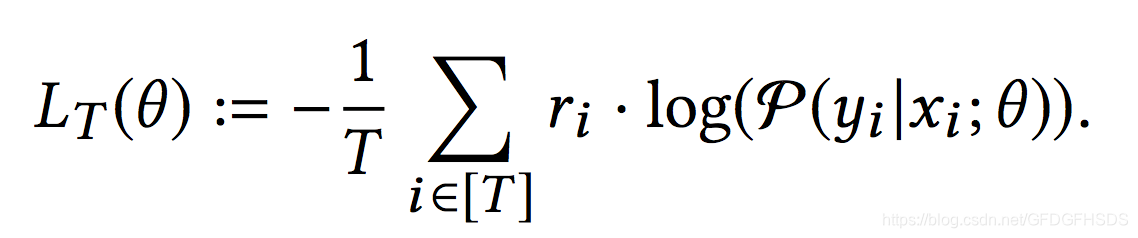
上述的做法相当于把该样本中的y作为正样本,其余所有的物品当作负样本。但是当M非常巨大时,使用所有的物品来计算softmax方程并不是十分合适。一种通用的做法是通过随机mini-batch的方式来优化损失函数。假设一个包含B条数据的mini-batch,那么对于任意一条数据,softmax计算公式如下:
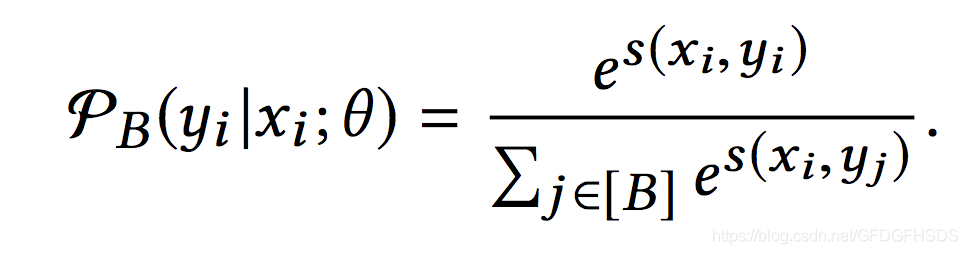
这种做法相当于把一个batch中此条数据之外物品当作负样本。但是这种做法存在的缺点就是会因为随机采样偏差而导致模型效果不好。对于热门物品来说,由于采样到的概率非常高,当作负样本的次数也会相应变多,热门物品会被“过度惩罚”。因此基于如下的公式对于x和y的评分进行一定程度的修正:
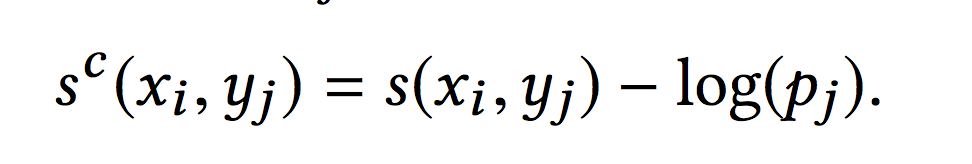
上式中,pj代表第j条样本对应的物品yj被一个mini-batch采样到的概率,这在下一节会详细介绍。
那么此时,softmax计算公式变为:
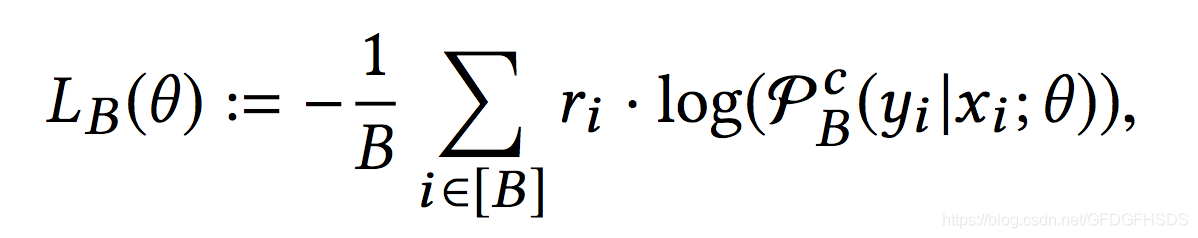
而batch的损失函数计算如下:
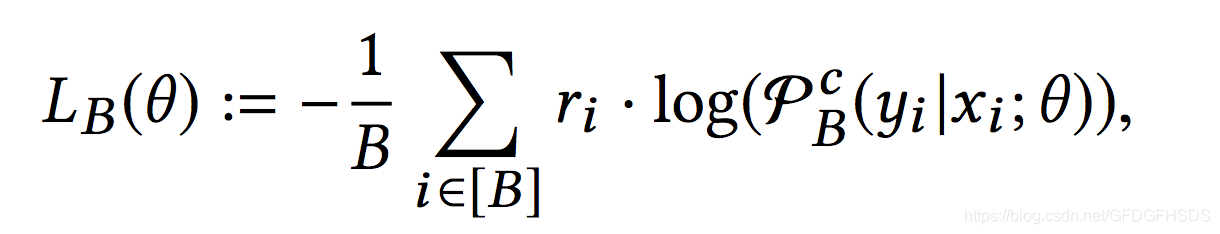
序列式训练
Youtube的训练数据按天依次产生,训练数据以streaming的方式喂给分布式训练集群。这样模型就可以自动学习并适应最新数据分布的变化。训练算法如下图所示,当收到一个batch的训练样本时,首先针对候选集的item进行采样概率预测,然后根据预测的采样概率构建损失函数,最后迭代训练即可。
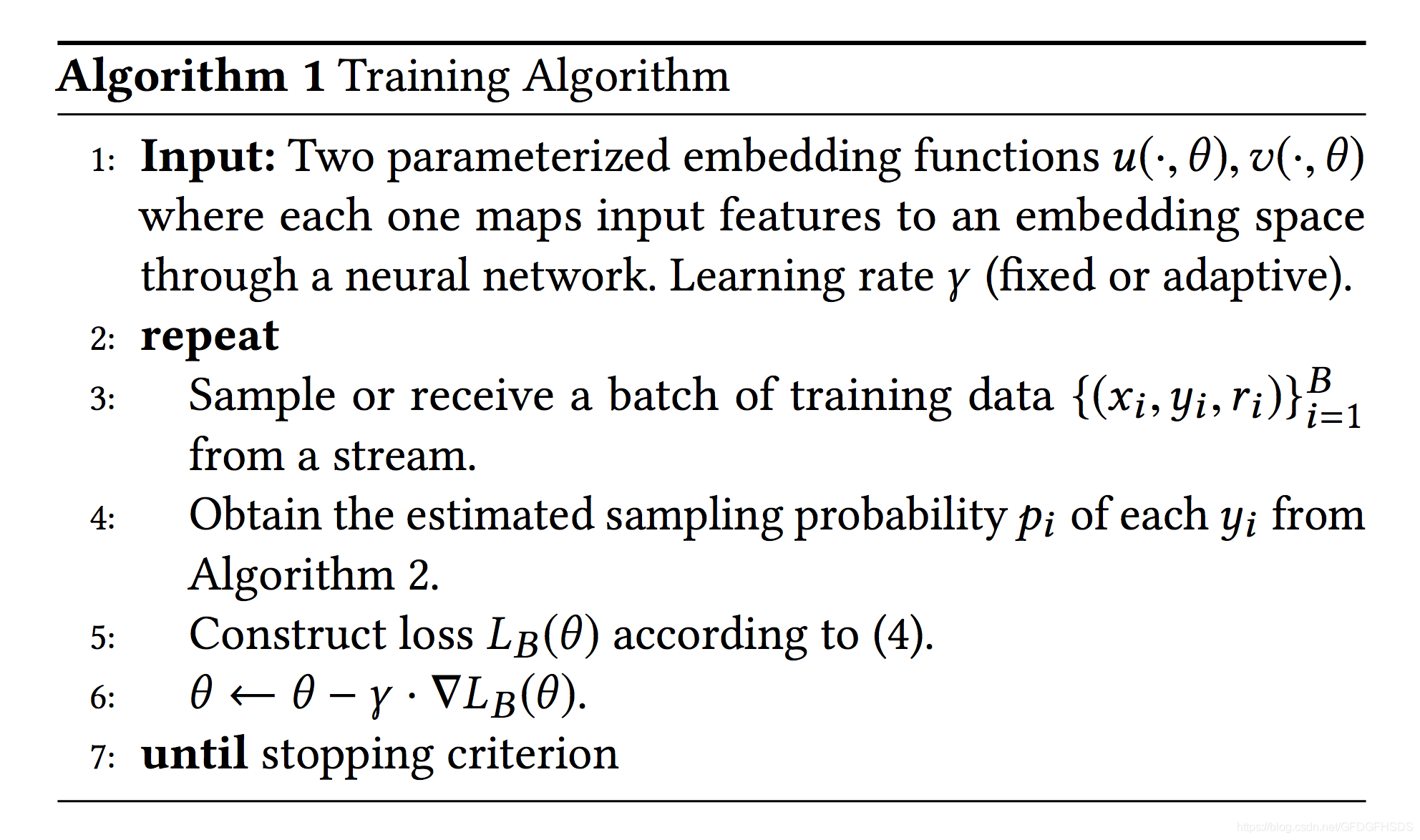
上图中采样概率的预估算法,就是我们下一节要介绍的内容。
2.2 streaming frequency estimation
由于youtube中不断会有新物品出现,那么使用固定长度的词表不太合适,因此采用hash的方式来对物品的采样概率进行更新。
具体来说,假设有一个散列地址大小为H的hash函数h,对物品ID进行映射。同时使用两个长度为H的数组A和B,通过h(y)来得到其在数组A和B中下标。
那么,A[h(y)]记录上一次物品y被采样到的训练时刻,B[h(y)]记录物品y采样的预估频率(这里频率的意思是预估每过多少步可以被采样到一次,那么倒数就是预估被采样到的概率)。当第t步物品y被采样到,基于如下的公式更新B[h(y)]:
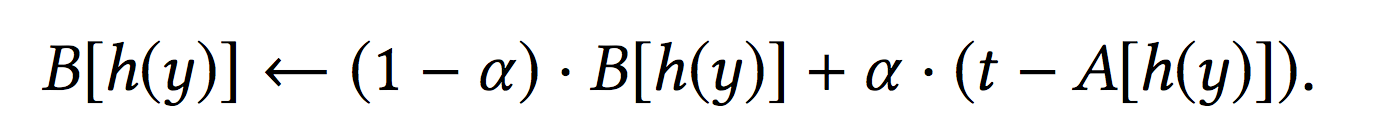
而A[h(y)]则被赋予当前的训练步骤t。当训练完成时,预估的物品y的采样概率是1/B[h(y)]。
流式频率预估的算法如下图所示。由于候选集item的词典不是固定的,时刻都会有新的item产生。因此这里针对item使用hash函数做了一个映射。针对一个指定的候选item y,A表示 y 被采样最近一次步骤,B则表示 y 的预估频率。一旦候选item y在迭代步骤 t 中出现,即可以按照下面迭代公式更新B。
既然是hash过程,当H<M时,就会存在冲突的情况。冲突的情况会导致B[h(y)]较小,因为t-A[h(y)]会较小。从而导致采样概率预估过高。这里的改进方案是使用multiple hashings。即使用多组hash方程和数组A和B。当训练完成时使用最大的一个B[h(y)]去计算采样概率。具体过程如下:

2.3 Nearest Neighbor Search
文中还介绍了双塔模型在使用时两点工业经验。
1)对两侧输出的embedding进行L2标准化,如:
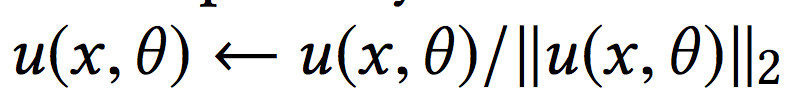
2)对于内积计算的结果,除以一个固定的超参:
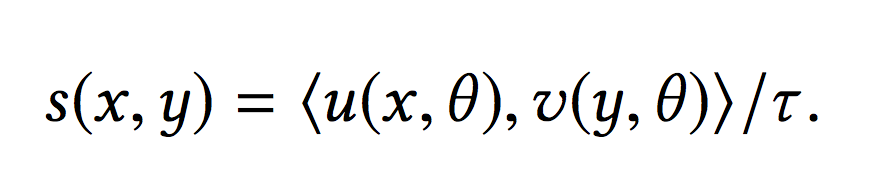
除以超参的效果如下,可以看到softmax的效果更加明显: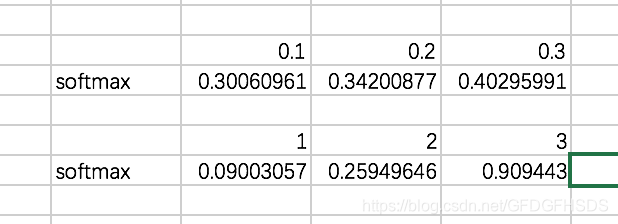
超参的设定可以通过实验结果的召回率或者精确率进行微调。
3、双塔模型应用于Youtube推荐
双塔模型应用于Youtube视频推荐的框架如下:
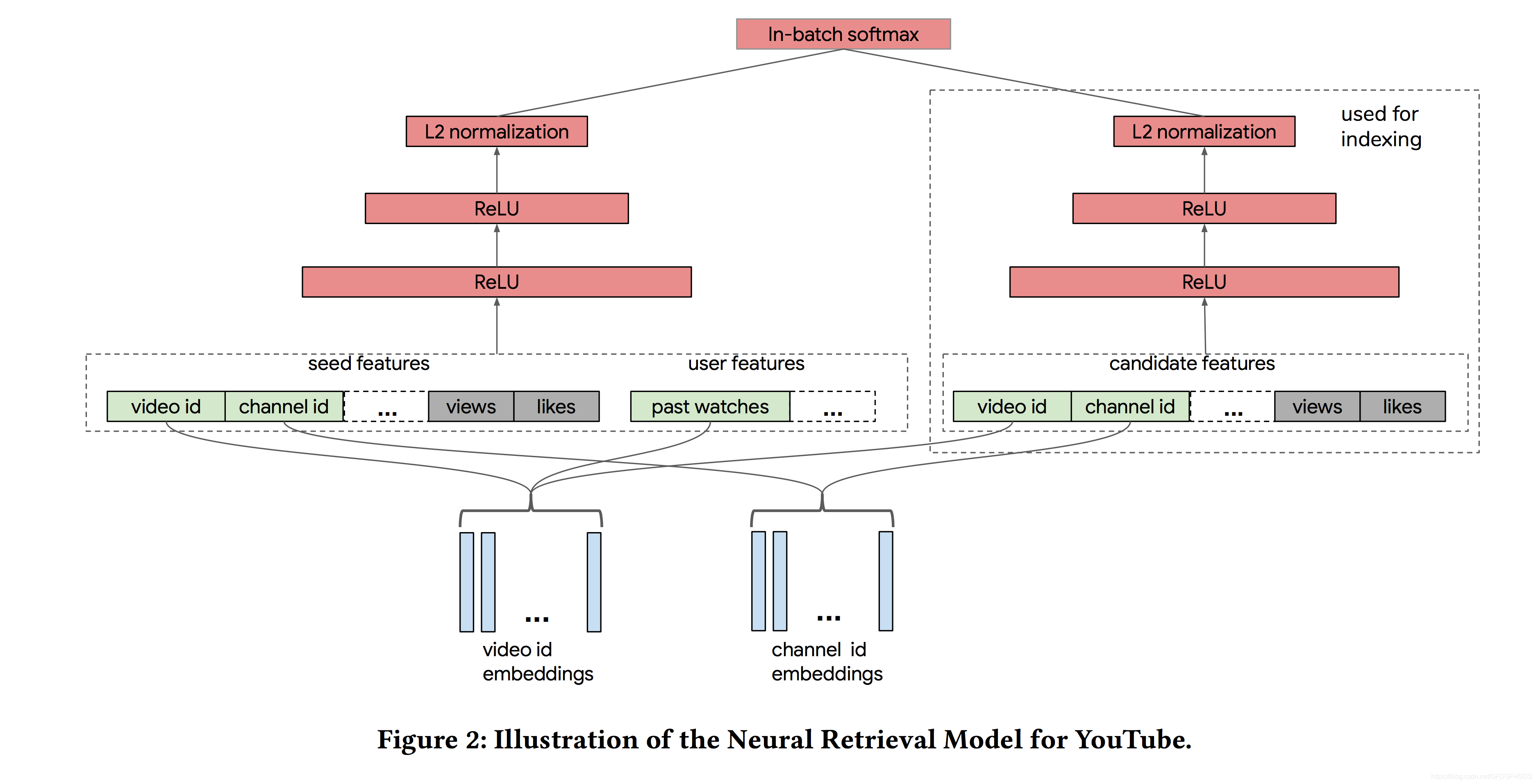
**训练Label:**这里训练集Label并不是点击即为1,未点击为0。而是当一个视频被点击但是观看时长非常短时,label同样是0。当视频被完整看完时,label才是1。
**视频侧特征:**视频侧包含的特征既有类别特征如视频ID、频道ID,也有连续特征。类别特征中有分为单值类别特征和多值类别特征,对于多值类别特征,采用对embedding加权平均的方式得到最终的embedding。
**用户侧特征:**用户侧特征主要是基于用户的历史观看记录来捕获用户的兴趣。比如使用用户最近观看过的k个视频的embedding的平均值。对于类别特征,embedding在模型的两侧是共享的。
**实时更新:**模型基于Tensorflow实现,并且进行了分布式实现。同时,模型会进行天级别更新。
索引和模型预估
如下图所示,索引pipe分为三个阶段:候选集生成,embedding预测和embedding索引。
上述序列式训练生成的双塔模型会定期地保存成为SavedModel并与线上的预测模型保持同步。对于索引库里的所有候选item,可以使用双塔模型的候选集侧的塔生成item的embedding;然后再通过基于树或者量化hash的方式来建立索引。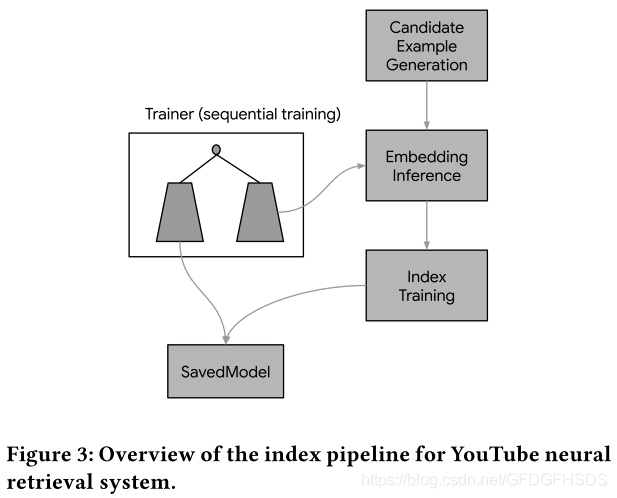
4、实验结果
接下来,看一下几个关键的实验结果。
4.1 频率预估实验
对于实验设置,这里共有M个物品,每个物品的真实出现概率为qi,所有qi的和为1。在前一万步,qi正比于i2,在后一万步,qi正比于(M-1-i)2。如果每次采样B个物品,那么每个物品被采样到的概率为pi=qi * B,并作为label。而预测的概率则是刚才介绍的公式1/B[h(y)],二者通过MAE计算误差。
使用不同的alpha来更新B,结果如下:
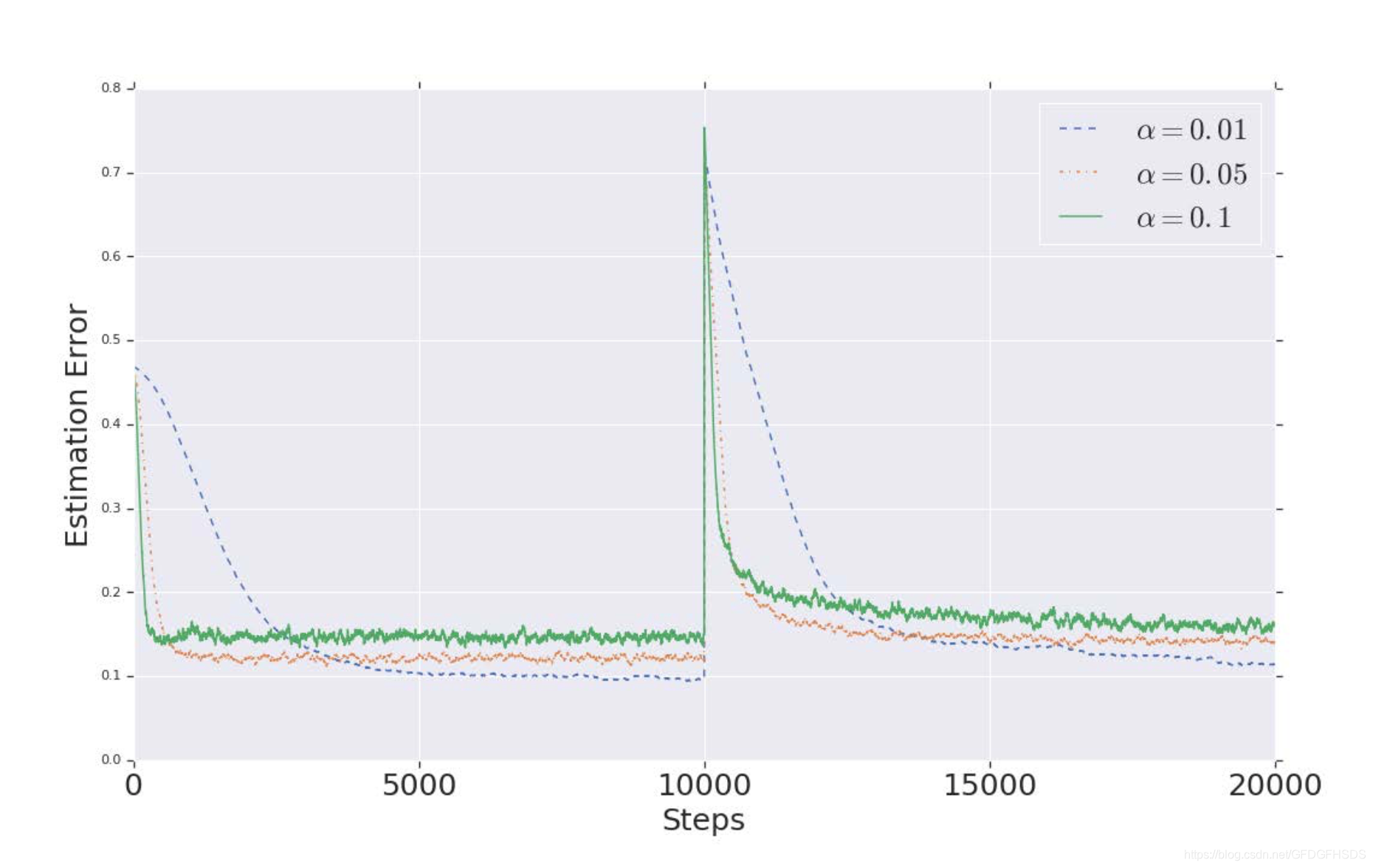
可以看到,当alpha越来越小时,随着训练步数的增加,误差是越来越小的。
当使用不同数量的Hash方程时,误差如下:
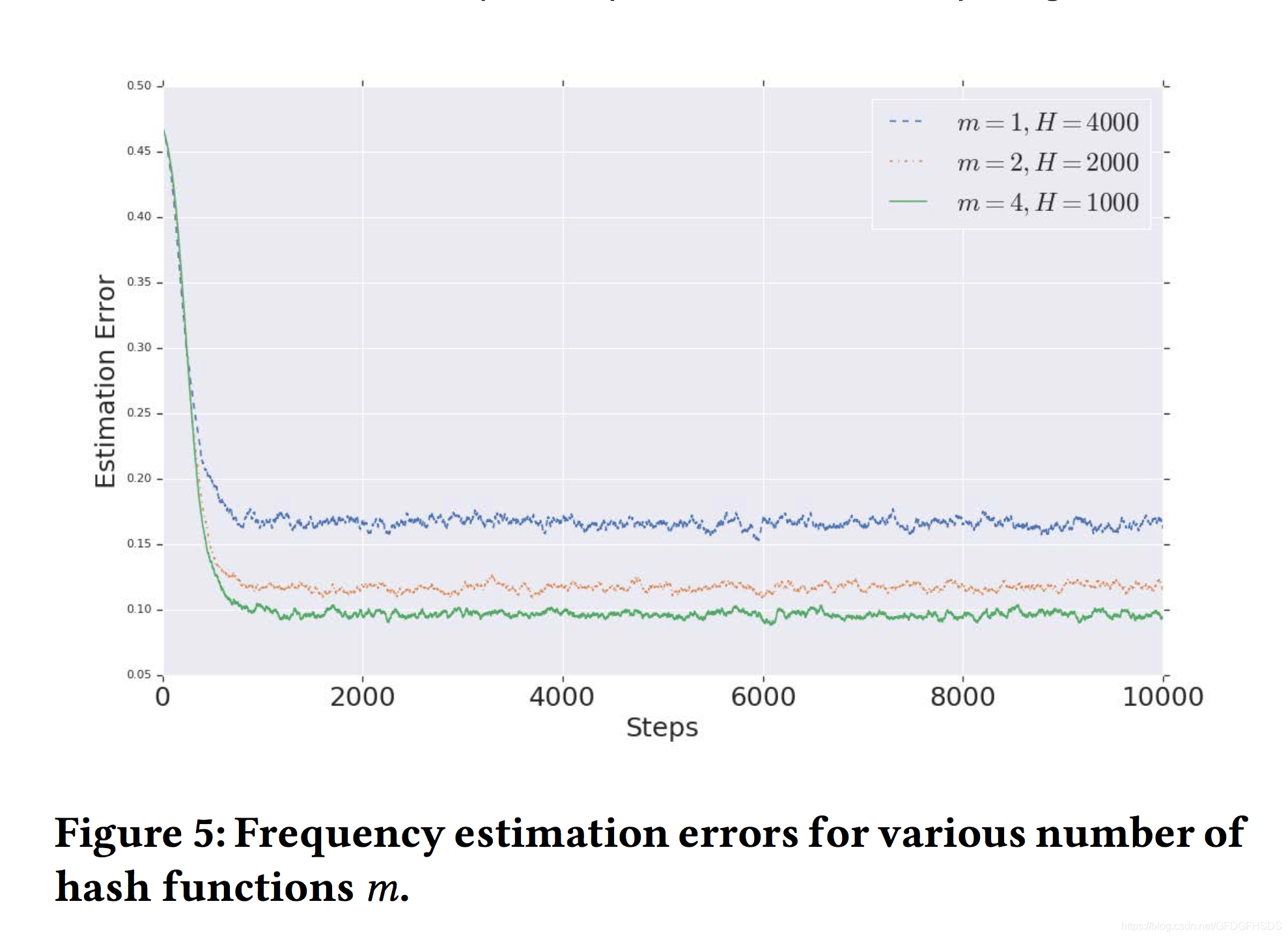
可以看到,使用更多的Hash方程数量,误差越小。
4.2 Youtube离线&在线实验
在youtube数据集上进行离线训练,结果如下:
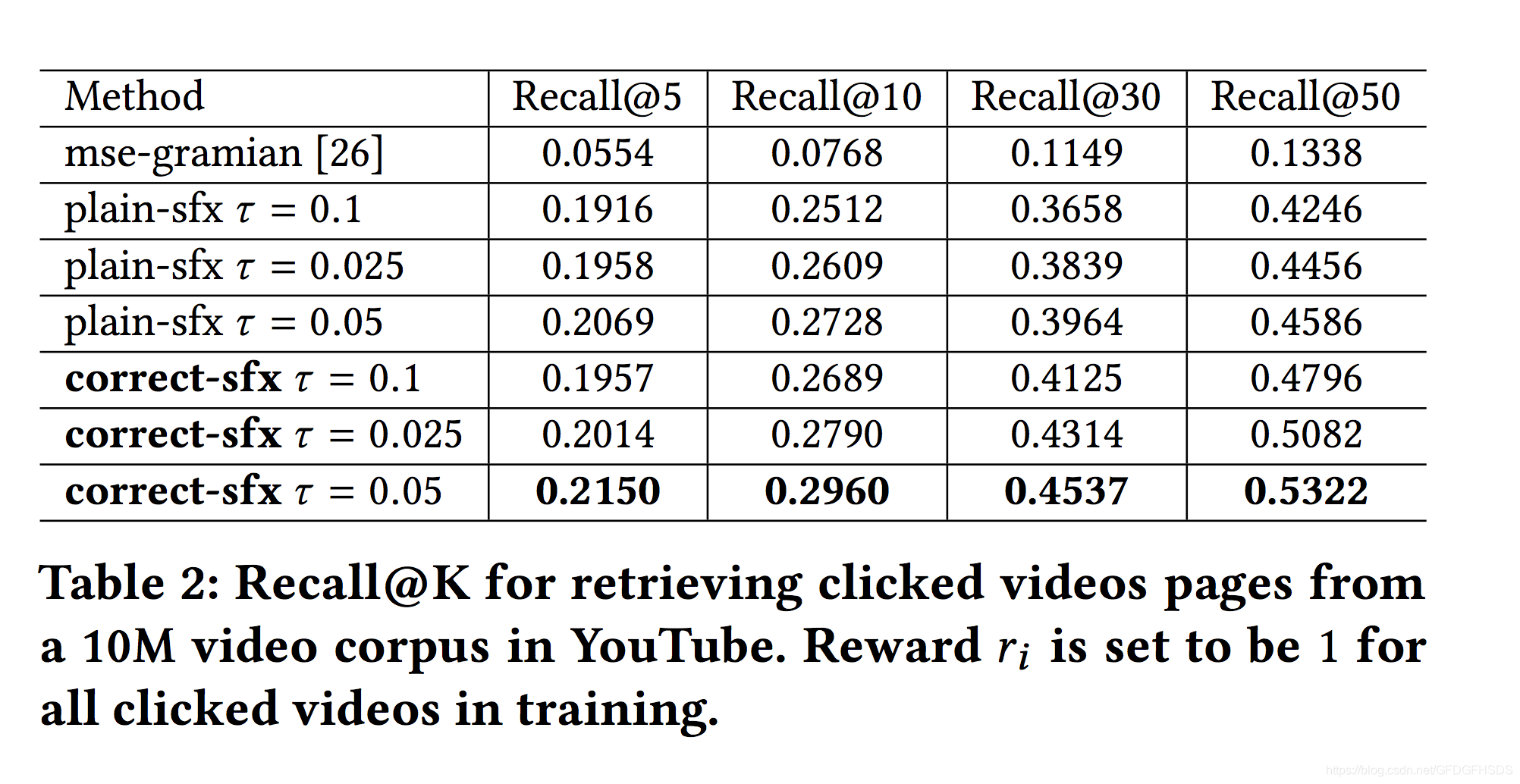
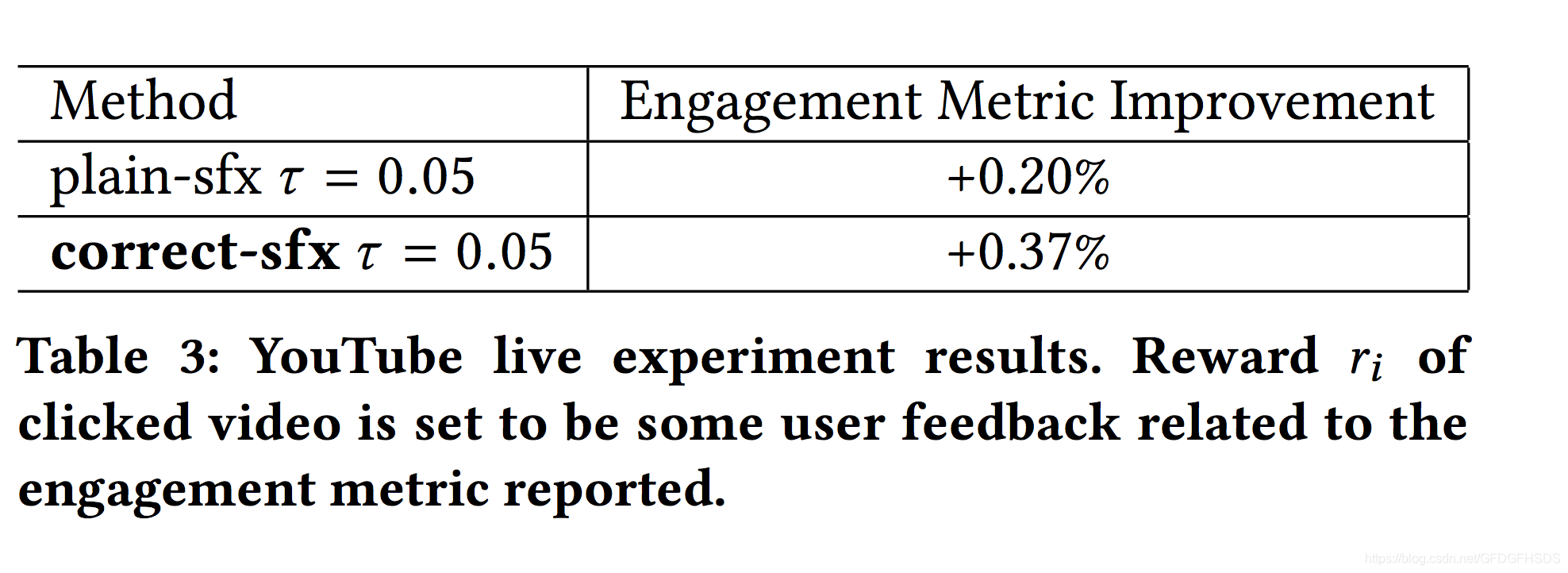
上图中,plain-sfx表示不通过概率对采样偏差进行修正,correct-sfx表示修正采样偏差,可以看到修正后效果更为显著。线上结果同样如此:
为了评估所提出算法框架的有效性,我们进行了在item频率预估上的仿真实验、Wikipedia上的检索实验以及Youtube上的实验。这里我们主要关注于在Youtube线上的实验。
模型结构采用上面介绍的结构,针对共同的输入特征,相应的Embedding在query和item的两个塔之间是共享的。双塔均使用三层DNN网络1024 x 512 x 128。

5、总结
本文作为一篇工业实战类型的推荐文章,详细介绍了双塔模型在使用时的一些小技巧,一起简单来回顾下:
1)使用batch softmax optimization来训练模型。
2)使用frequency estimation来修正采样偏差,修正方法基于Multiple Hashings。
3)线上应用时使用hash等技术来提高检索效率。
4)对两侧得到的Embedding进行正则化。
5)通过对得到的内积除以一个超参数,使得softmax结果更加明显。
