文章目录
一、DSSM模型

1.1 DSSM模型架构
这里不按原论文出牌,从推荐系统角度:
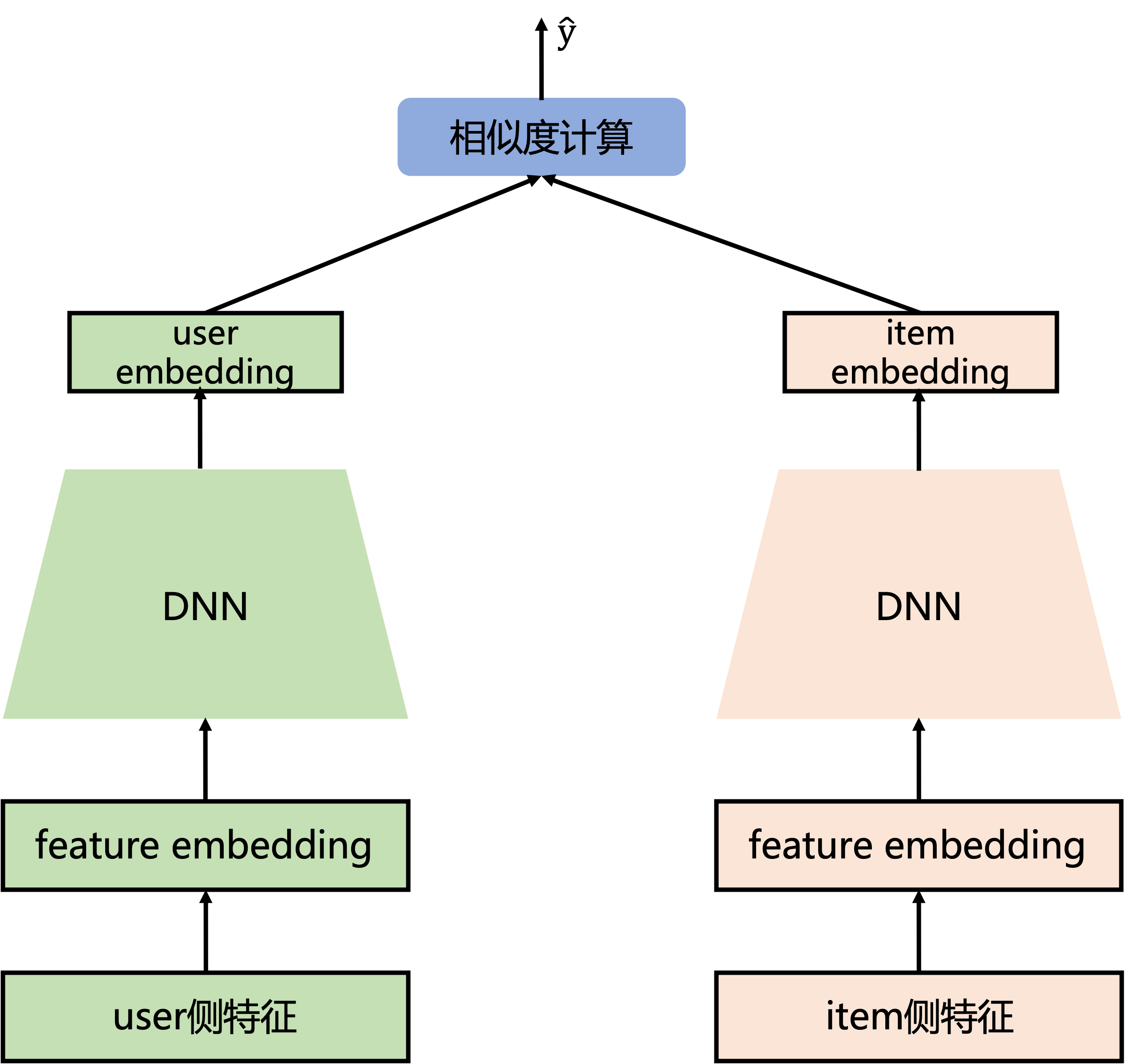
双塔模型结构简单,一个user塔,另一个item塔,两边的DNN机构最后一层(全连接层)隐藏单元个数相同,保证user embedding和item embedding维度相同,后面相似度计算(如cos内积计算),损失函数使用二分类交叉熵损失函数。DSSM模型无法像deepFM一样使用user和item的交叉特征。
业界推荐系统常用多路召回(如CF召回、语义向量召回等,其中DSSM也是语义向量召回的其中一种),DSSM离线训练和普通的DNN训练相同。某baidu大佬有言:精排是特征的艺术,召回是样本的艺术。
- DSSM召回的样本中:
- 正样本就是曝光给用户并且用户点击的item;
- 负样本:常见错误是直接使用曝光并且没被user点击的item,但是会导致SSB(sample selection bias)样本选择偏差问题——因为召回在线时时从全量候选item中召回,而不是从有曝光的item中召回。
DSSM原始论文里的做法:只有正样本, 记为 D + D^{+} D+, 对于用户 u 1 u_{1} u1, 其正样本就是其点击过的 item, 负样本则是随机从 D + D^{+} D+(不包含 u 1 u_{1} u1 点击过的item) 中随机选择4个item作为负样本。
1.2 模型原理

二、负样本构造的6个常用方法
2.1 曝光未点击数据
如果只用这个,会导致BBS问题,也要看场景。
2.2 全局随机选择负例
从原始的全局物料库中,随机抽取作为召回或者粗排的负样本。
2.3 Batch内随机选择负例
训练时在同一个batch中,在除了正例之外的其他item,选择构造负例,一定程度解决SSB问题。
2.4 曝光数据中随机选择负例
2.5 基于Popularity随机选择负例
越流行的item,如果没被用户点击看过,则更可能对于该用户来说是一个真实的负例。
2.6 基于Hard选择负例
可以参考Airbnb筛选Hard负例的尝试(hard例给模型带来的loss和信息多)。
三、DSSM在工业界常用的原因
3.1 论文的实验细节
- 将准备好的数据集分为两部分(训练集和验证集),且没有交叉
- DNN网络使用三个隐藏层结构,第一层是word hashing 层,大约30K个节点,第二、第三层有300个节点,输出层128个节点
- 网络权重初始化使其符合分布,其中、分别表示输入和输出单元数
- 实验对比,分层预训练并没有比直接训练效果好
- 优化算法采用的是随机梯度下降(SGD)
- 训练的批大小 batch-size=1024
- 前向和反向传播过程中单个批样本迭代次数 epochs=20
- 实验评估指标为NDCG,同时结合t-test和p-value,进行分析,使结果更严谨
3.1 DSSM召回在线infer
- DSSM工业界应用广泛,双塔模型中,训练好的后user侧塔和item侧塔没依赖关系。当然缺点就是user侧和item侧特征无法特征交叉,某团也因此改进成A Dual Augmented Two-tower Model for Online Large-scale
Recommendation。 - 离线训练模型越短(更新越快)越好,同时在线infer也不能太慢。
- DSSM也可以用于粗排,从多路召回后的候选item中粗排;负样本和精排的负样本相同。
百度的DSSM部署情况:非常成熟好用的基建,从日志收集传输、特征抽取框架、模型训练部署框架、embedding向量存储、在线infer等非常齐全。所以我们在线部署DSSM的时候选择了比较奢侈的方法:item侧塔和user侧塔都部署到线上,有个server会每间隔几个小时就请求item塔,计算出全量item的embedding向量,然后存储更新。当每个用户请求到达时,会请求user塔计算出user的embedding向量,然后拿着这个user向量去做item库里做ANN检索选出相似度最大的topX个ietm。关于ANN检索技术比较有很多,比如:kd树、Annoy、HNSW等,Facebook开源了ANN库FAISS,国内很多公司在用,百度则有自己的一套ANN检索框架。
四、DSSM的变种
Reference
[1] 推荐系统中不得不说的 DSSM 双塔模型
[2] 推荐系统(十一)DSSM双塔模型
[3] 推荐系统召回中 dssm 和 fm 各自的主要优劣势
[4] [美团]面向大规模推荐系统的双重增强双塔模型
[5] 张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它
[6] DSSM模型
[7] 全民K歌内容挖掘与召回
[8] 推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)
[9] https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf