前言
 KDD20的paper
KDD20的paper
链接:https://dl.acm.org/doi/pdf/10.1145/3394486.3403392
代码链接:https://github.com/manigalati/usad
一、摘要
在摘要中主要指出了本文的难题引出本文的方法。
原因出自Orange公司的IT系统的自动监测。由于系统的整体的规模和复杂性,随着时间的推移,用于推断正常和异常行为的测量所需的传感器数量急剧增加,使传统的基于专家的监督方法变慢或容易出错。
所以本文提出了一个非监督方法,而前面所说的通过多传感器数据来推断系统正常或异常的问题其实就是多变量时间序列异常检测问题。
最后该方法在五种公共数据集上以及Orange公司提供的真实数据集上进行测试。
二、相关方法
这里文中给出了一些,再加上自己的一些积累,顺便简单总结一些。
基于分布的方法:3-sigma,z-score
基于聚类的方法:kmeans,GMM,DBSCAN等
基于距离的方法:KNN等
基于密度的方法:LOF等
基于分类的方法:Oneclass-SVM等
基于树的方法:iforest等
基于降维的方法:PCA,AE等
基于预测的方法:时序预测之后看差距(这里约等于时序预测的方法)
基于深度学习的方法:DAGMM,LSTM-VAE,VAE等
主要针对多变量时间序列的异常检测深度学习方法:MTAD_GAT,OmniAnomaly,GDN等
文中主要提到一个非常重要的一点,就是算法的性能(使用的硬件资源+运行速度)这个角度,很多算法都没有考虑和测试。当然这两个指标对于一个算法服务化以及响应性能也是十分重要的。
三、 问题定义
这里文章中写了一部分内容(主要涉及很多标准化的公式),这边我直接用简单直接的方式快速阐述一下
一个单变量时间序列肯定很多人都很熟悉了,一般来说是等间隔的序列,故每隔一定的时间有一个数据。
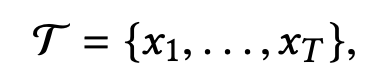
而多变量时间序列就是对应于每一个时刻变成多个维度的序列。
从维度(1, T)->(N, T),其中N代表N个时间序列。
而对于多变量时间序列异常检测,区别于多变量流的异常检测。
前者是 多变量的变化代表某一时刻的整体的异常:比如机器的很多指标出现一个整体或单一的变化代表着机器出现异常。
后者大多代表,时序有很多单一的线,比如有一万多时间序列,每一条时间序列都要检测出对应的异常情况,对于每一条时间序列本质还是单变量时间序列异常检测场景。
更多可以参考论文的描述,很清晰。
四、模型
4.1 基础模型
这里的基础模型就是AE,广泛应用于异常检测场景下,整理简略来说 降维和重构之后来比较和输入的差距,通过与阈值的大小比较来定义是否为异常状态。
训练过程也是计算两者的差距最为训练的目标,也就是loss,一般采用L2 loss也就是均方根loss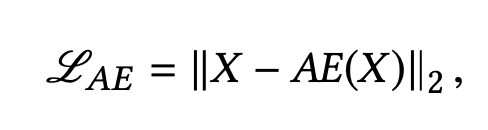
4.2 最终模型
4.2.1 训练方式
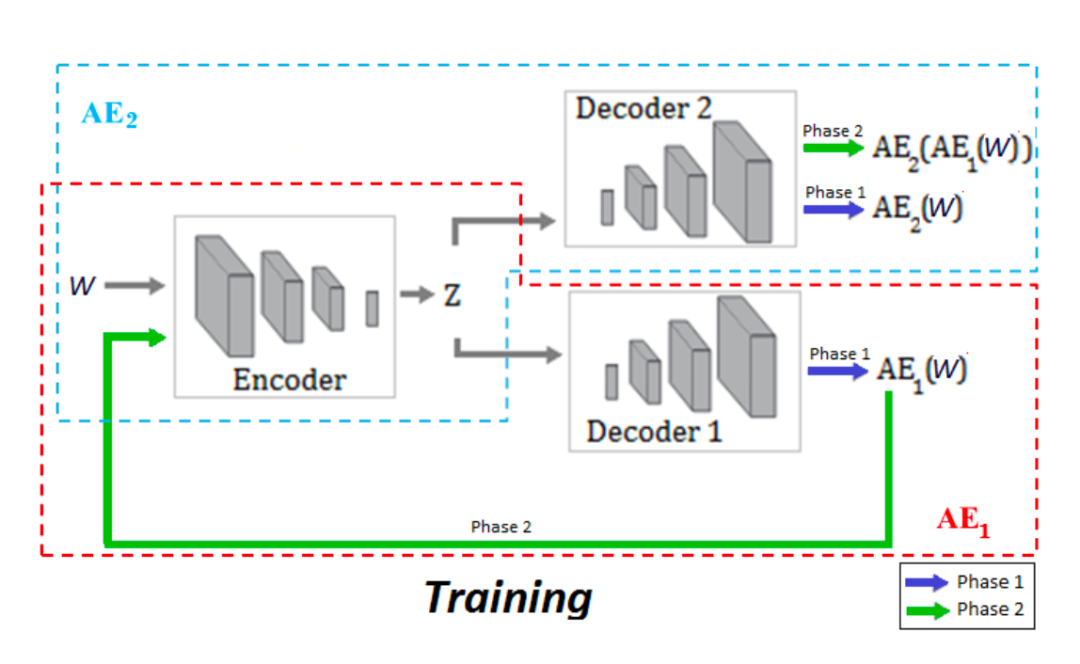 这里引入了,两个decoder,并且借鉴GAN的训练方式,这可能是本文比较大的创新。
这里引入了,两个decoder,并且借鉴GAN的训练方式,这可能是本文比较大的创新。
这里图也画的也很直白与直观。
首先第一步:训练两个AE,使得拥有良好的数据重构能力。
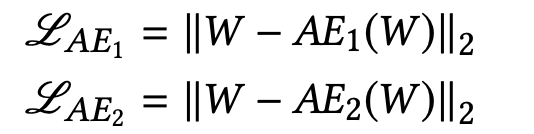
其次第二步:借鉴GAN的训练模式思想,对抗的训练两个网络,即训练AE2能够很好的区别AE1属出的数据的真实与否,通俗点说,就是AE2更好的分辨哪些是真实数据,哪些是AE1重构的数据。用AE1迷惑AE2,所以AE1的目标是最小化AE2(AE1(W))与W的不同,相反AE2想要更好的区别两者,即最大化不同。
总体的loss是这样
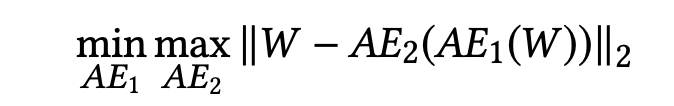
分开即:
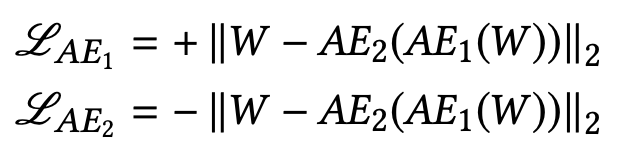
最终将两步骤loss合并,其中n为巡览epoch数:
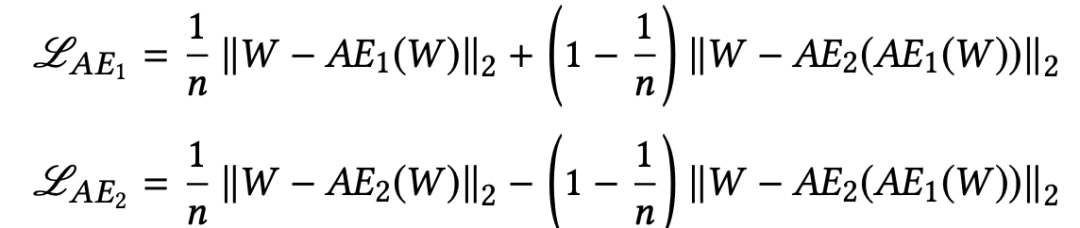
总体的训练步骤如下:

4.2.2 前向推理
异常检测分数定义为:
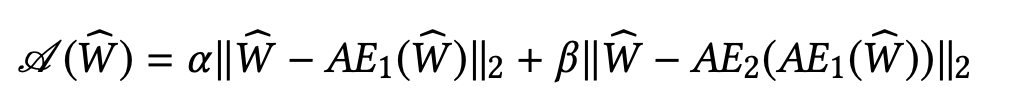 其中两个参数和为1,来权衡false positive 和true positive,最终通过与阈值的比较,来判断是否为异常的实体。
其中两个参数和为1,来权衡false positive 和true positive,最终通过与阈值的比较,来判断是否为异常的实体。

五、实验
5.1 数据集
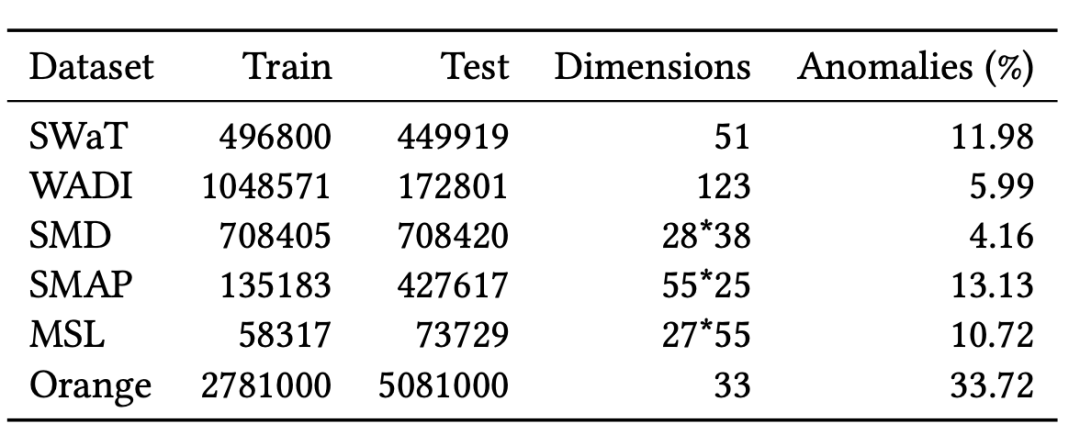
其中前五个为public数据集,最后一个为从Orange公司收集的实际数据集。
数据集详情可见:https://zhuanlan.zhihu.com/p/544335741
5.2 评价指标
依然是采用precision,recall,f1的方式。
不过这里有个小不同,对于异常的定义有两种
label是异常就是异常,针对某一点的实体的状态
label针对于某一个window,如果在一个窗口下有异常出现,我们就认为这一个窗口里面的数据都为异常(这个我个人理解也是通过实际的观察而这么定义的,比如在机器异常中,异常有一定的可持续性,在一个窗口内,如果存在一些异常,有的时候也是异常的情况,而并非只有异常的时间点异常)

对于存在多个实体的数据集,也采用了平均的F1。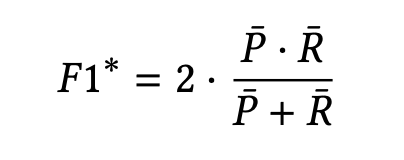
5.3 实验结果
5.3.1 实验
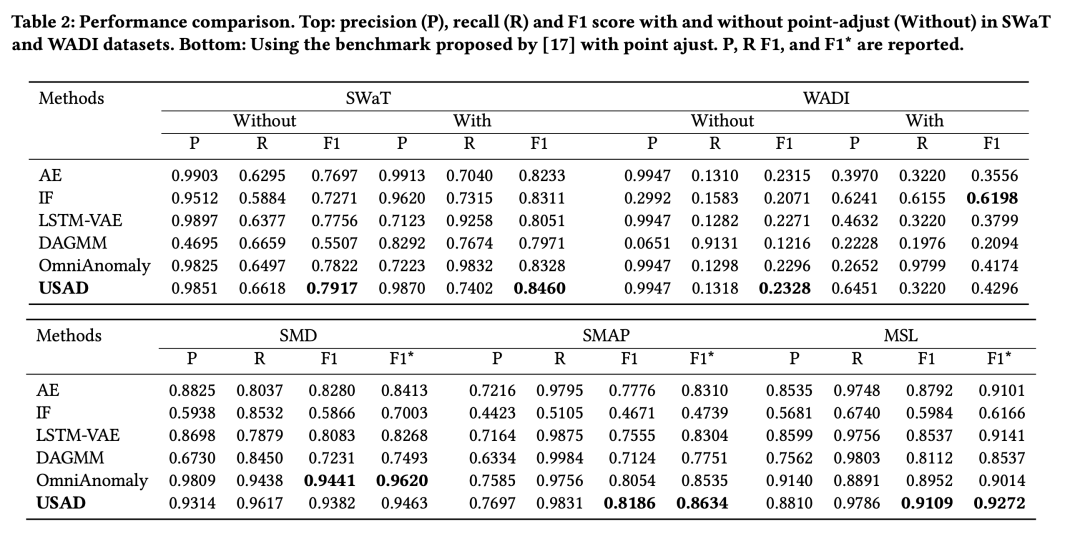
其中without就是前面说的第一种异常定义,with就是基于window的异常定义
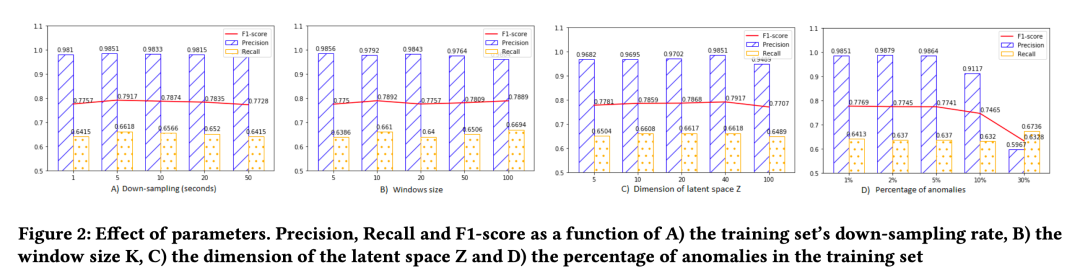
5.3.2 参数实验
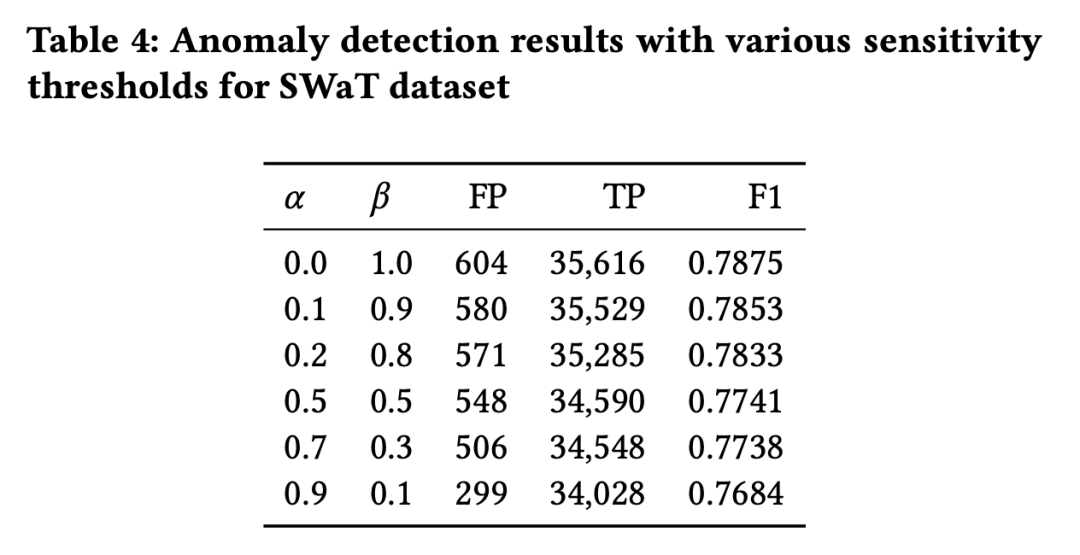
5.3.3 训练速度实验
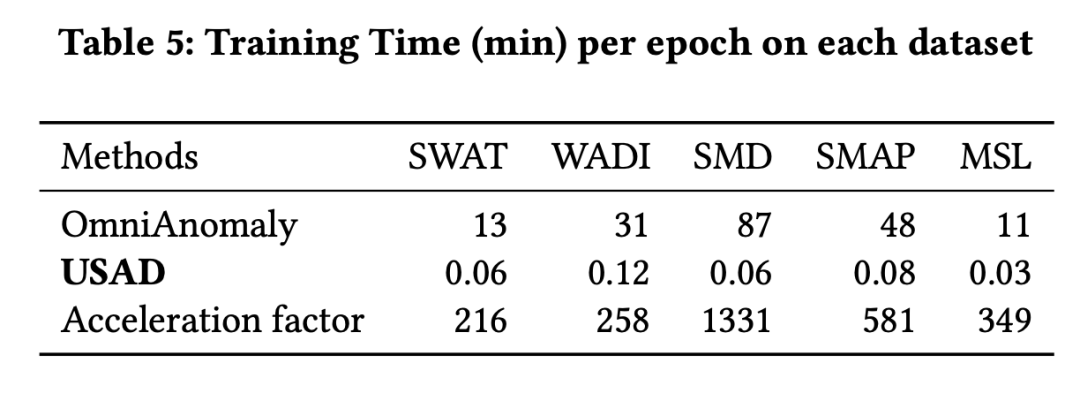 都是在每一个数据集的一个epoch的平均训练时间,在显卡1080Ti上的实验。但是我个人觉得这里应该还可以做一下在大量变量下的前向推理速度的实验,这个响应速度也很关键,以及占用的内存的实验,所耗用的硬件资源也很重要。
都是在每一个数据集的一个epoch的平均训练时间,在显卡1080Ti上的实验。但是我个人觉得这里应该还可以做一下在大量变量下的前向推理速度的实验,这个响应速度也很关键,以及占用的内存的实验,所耗用的硬件资源也很重要。
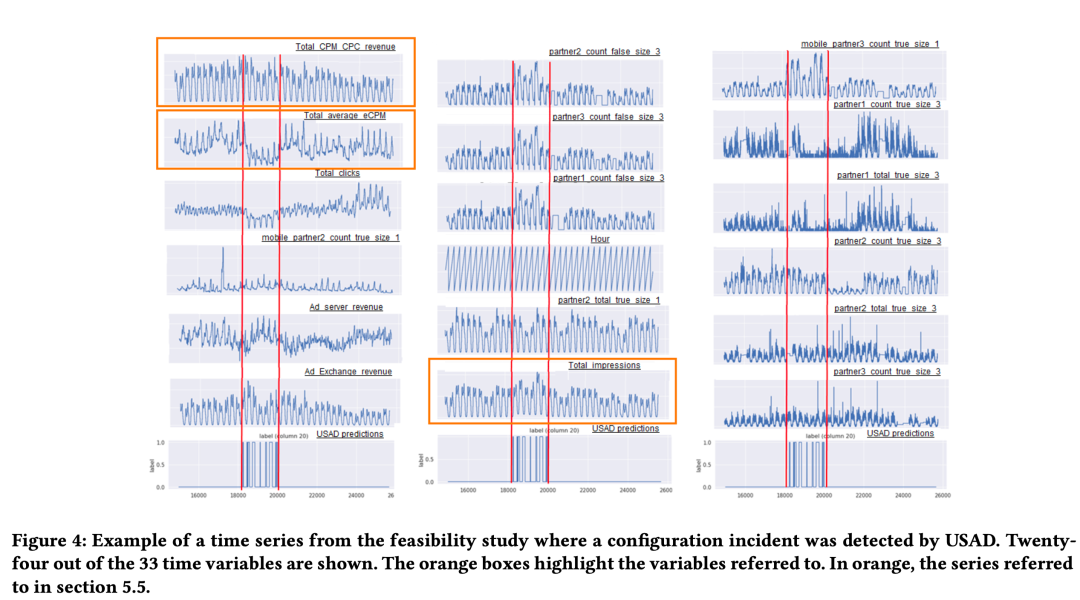
5.3.4 真实数据实验
最后给的可视化的监测事件成功的例子还是蛮不错的,并且指出了在实际工作中用30min解决了人工检查需要24h才解决的异常问题。
六、代码解读
6.1 模型代码
整体来说代码比较简单,不赘述了
import torch
import torch.nn as nn
from utils import *
device = get_default_device()
class Encoder(nn.Module):
def __init__(self, in_size, latent_size):
super().__init__()
self.linear1 = nn.Linear(in_size, int(in_size/2))
self.linear2 = nn.Linear(int(in_size/2), int(in_size/4))
self.linear3 = nn.Linear(int(in_size/4), latent_size)
self.relu = nn.ReLU(True)
def forward(self, w):
out = self.linear1(w)
out = self.relu(out)
out = self.linear2(out)
out = self.relu(out)
out = self.linear3(out)
z = self.relu(out)
return z
class Decoder(nn.Module):
def __init__(self, latent_size, out_size):
super().__init__()
self.linear1 = nn.Linear(latent_size, int(out_size/4))
self.linear2 = nn.Linear(int(out_size/4), int(out_size/2))
self.linear3 = nn.Linear(int(out_size/2), out_size)
self.relu = nn.ReLU(True)
self.sigmoid = nn.Sigmoid()
def forward(self, z):
out = self.linear1(z)
out = self.relu(out)
out = self.linear2(out)
out = self.relu(out)
out = self.linear3(out)
w = self.sigmoid(out)
return w
class UsadModel(nn.Module):
def __init__(self, w_size, z_size):
super().__init__()
self.encoder = Encoder(w_size, z_size)
self.decoder1 = Decoder(z_size, w_size)
self.decoder2 = Decoder(z_size, w_size)
def training_step(self, batch, n):
z = self.encoder(batch)
w1 = self.decoder1(z)
w2 = self.decoder2(z)
w3 = self.decoder2(self.encoder(w1))
loss1 = 1/n*torch.mean((batch-w1)**2)+(1-1/n)*torch.mean((batch-w3)**2)
loss2 = 1/n*torch.mean((batch-w2)**2)-(1-1/n)*torch.mean((batch-w3)**2)
return loss1,loss2
def validation_step(self, batch, n):
z = self.encoder(batch)
w1 = self.decoder1(z)
w2 = self.decoder2(z)
w3 = self.decoder2(self.encoder(w1))
loss1 = 1/n*torch.mean((batch-w1)**2)+(1-1/n)*torch.mean((batch-w3)**2)
loss2 = 1/n*torch.mean((batch-w2)**2)-(1-1/n)*torch.mean((batch-w3)**2)
return {'val_loss1': loss1, 'val_loss2': loss2}
def validation_epoch_end(self, outputs):
batch_losses1 = [x['val_loss1'] for x in outputs]
epoch_loss1 = torch.stack(batch_losses1).mean()
batch_losses2 = [x['val_loss2'] for x in outputs]
epoch_loss2 = torch.stack(batch_losses2).mean()
return {'val_loss1': epoch_loss1.item(), 'val_loss2': epoch_loss2.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], val_loss1: {:.4f}, val_loss2: {:.4f}".format(epoch, result['val_loss1'], result['val_loss2']))
def evaluate(model, val_loader, n):
outputs = [model.validation_step(to_device(batch,device), n) for [batch] in val_loader]
return model.validation_epoch_end(outputs)
def training(epochs, model, train_loader, val_loader, opt_func=torch.optim.Adam):
history = []
optimizer1 = opt_func(list(model.encoder.parameters())+list(model.decoder1.parameters()))
optimizer2 = opt_func(list(model.encoder.parameters())+list(model.decoder2.parameters()))
for epoch in range(epochs):
for [batch] in train_loader:
batch=to_device(batch,device)
#Train AE1
loss1,loss2 = model.training_step(batch,epoch+1)
loss1.backward()
optimizer1.step()
optimizer1.zero_grad()
#Train AE2
loss1,loss2 = model.training_step(batch,epoch+1)
loss2.backward()
optimizer2.step()
optimizer2.zero_grad()
result = evaluate(model, val_loader, epoch+1)
model.epoch_end(epoch, result)
history.append(result)
return history
def testing(model, test_loader, alpha=.5, beta=.5):
results=[]
for [batch] in test_loader:
batch=to_device(batch,device)
w1=model.decoder1(model.encoder(batch))
w2=model.decoder2(model.encoder(w1))
results.append(alpha*torch.mean((batch-w1)**2,axis=1)+beta*torch.mean((batch-w2)**2,axis=1))
return results6.2 实战
这里有个jupyter notebook里面给予了数据集SWaT的链接,如果着急的话可以试一下
https://github.com/manigalati/usad/blob/master/USAD.ipynb
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书