目录
Prophet算法概述
Prophet由facebook开源的基于python和R语言的数据预测工具,基于时间和变量值结合时间序列分解和机器学习的拟合来做的;可以解决大部分的实际场景中的对单项值的预测,也可以用于时间序列数据的异常值检测以及缺失值填充;
一般会把时间序列拆分成几个部分,分别是s(t)季节项:表示周期项,或者称为季节项,一般以周者年为单位;趋势项g(t):表示时间序列在非周期上面的变化趋势;假期项h(t):表示在当天是否存在节假日;剩余项εt:表示误差项或者称为剩余项;
Prophet算法就是通过拟合这几项,最后把它们累加起来就得到时间序列的预测值;
Prophet算法实战
Prophet需要导入包
from fbprophet import Prophet
import pandas as pd
import numpy as np
import warnings
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
mpl.rcParams['axes.unicode_minus']=False #用来正常显示负号
warnings.filterwarnings('ignore')模型需要导入的数据格式如下图,数据列名要保持一致,时间列为ds,对应数据为y;

加入假期分量,时间可以根据实际需求适当扩展,代码部分如下:
#端午假期
duanwu = pd.DataFrame({
'holiday': 'duanwu',
'ds':pd.date_range('2022-06-01', periods =7 , freq = 'D')})
#中秋假期
zhongqiu = pd.DataFrame({
'holiday': 'zhongqiu',
'ds':pd.date_range('2022-09-08', periods =7 , freq = 'D')})
#国庆
guoqing = pd.DataFrame({
'holiday':'guoqing',
'ds':pd.date_range('2022-09-28', periods =11 , freq = 'D'),
})
#元旦
yuandan = pd.DataFrame({
'holiday': 'yuandan',
'ds': pd.date_range('2022-12-29', periods =7 , freq = 'D'),
})
#春节假期
chunjie = pd.DataFrame({
'holiday': 'chunjie',
'ds':pd.date_range('2023-01-19', periods =11 , freq = 'D')})
#合并假期数据
holidays = pd.concat((chunjie,duanwu,zhongqiu,yuandan,guoqing))模型训练、预测以及输出结果,0.95的置信区间;
m = Prophet(
holidays=holidays,
yearly_seasonality=8,
weekly_seasonality=8,
daily_seasonality=20,
changepoint_prior_scale=0.04,
growth='linear',
interval_width = 0.95
)
#指定节假日参数,
#对过去数据进行训练
m.fit(df)
forecast = m.predict(df)
forecast["y"] = df["y"].reset_index(drop = True)
forecast[["ds","y","yhat","yhat_lower","yhat_upper"]].head()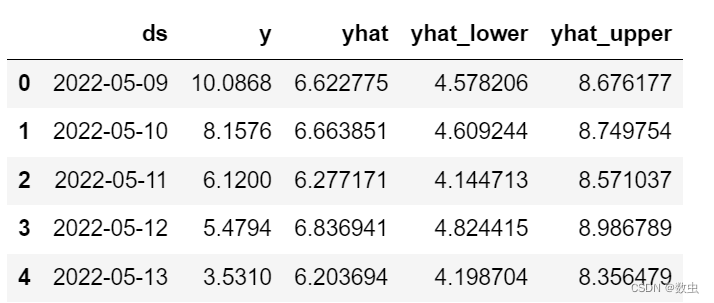
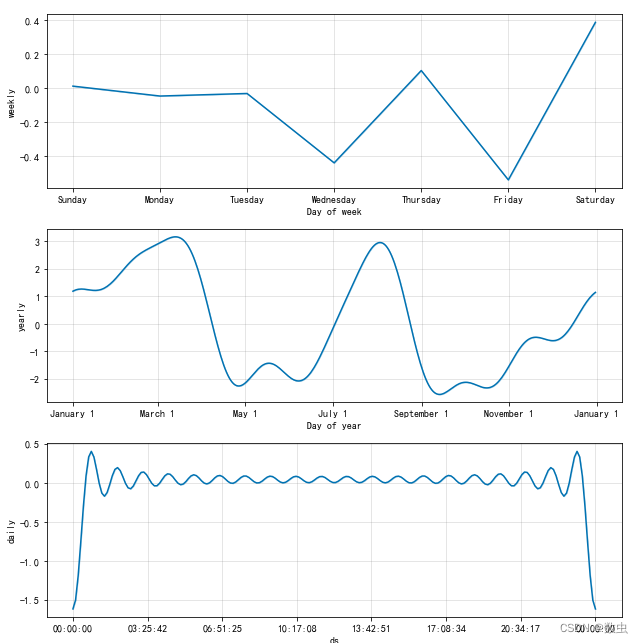
模型自带画图,画出趋势分量、周期分量、假期分量以及剩余项;
m.plot_components(forecast)
plt.show()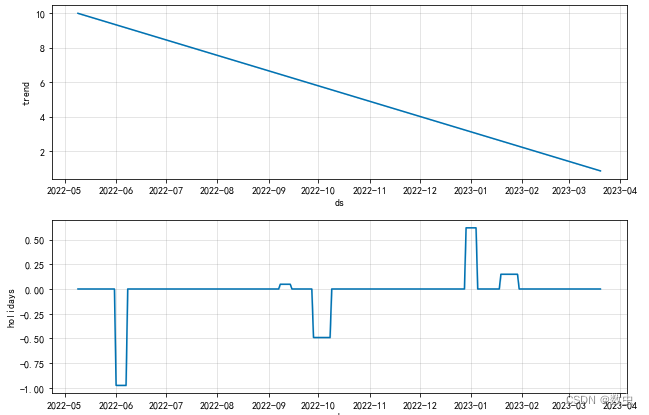
模型自带画图,画出模型的预测结果、置信区间、原始散点图;
m.plot(forecast)
plt.show()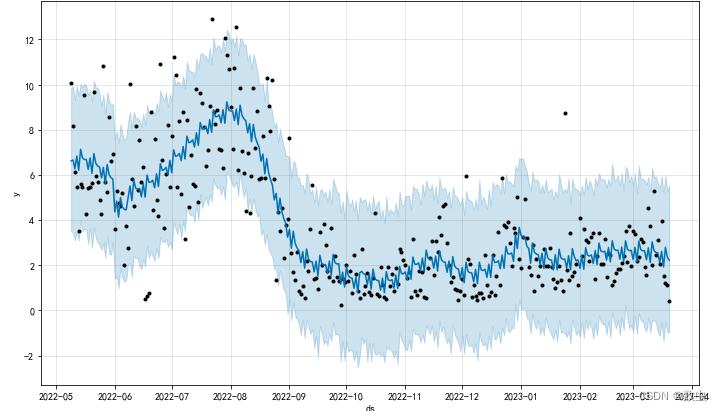
Prophet异常数据检测
对于原始数据落于置信区间之外的点可以认为是时间序列的异常值,异常值检测代码如下:
#异常值索引
def outlier_detection(forecast):
index = np.where((forecast["y"] <= forecast["yhat_lower"])|
(forecast["y"] >= forecast["yhat_upper"]),True,False)
return index
outlier_index = outlier_detection(forecast)
outlier_df = df[outlier_index]
print(outlier_df)
print("异常值的数量为:",np.sum(outlier_index))
异常检测数据可视化代码如下:
# 可视化异常值的结果
fig, ax = plt.subplots()
## 可视化预测值
forecast.plot(x = "ds",y = "yhat",style = "b-",figsize=(14,7),
label = "预测值",ax=ax)
## 可视化出置信区间
ax.fill_between(forecast["ds"].values, forecast["yhat_lower"].values,
forecast["yhat_upper"].values,color='b',alpha=.2,
label = "95%置信区间")
forecast.plot(kind = "scatter",x = "ds",y = "y",c = "k",
s = 20,label = "原始数据",ax = ax)
## 可视化出异常值的点
outlier_df.plot(kind = "scatter",x = "ds",y = "y",ax = ax,
c = "red",label = "异常值")
plt.grid()
plt.title("时间序列异常点检测")
plt.show()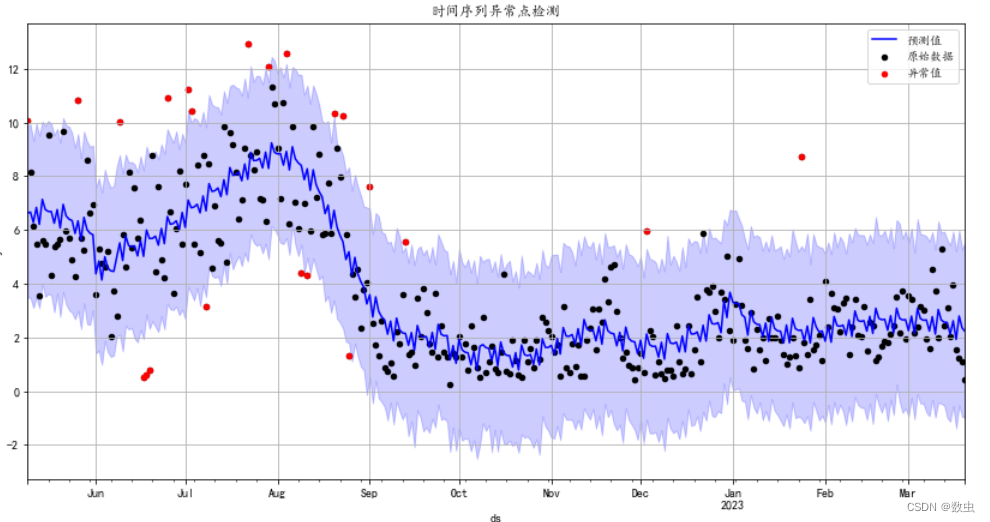
对于异常检测的数据模型预测出的结果进行回填,时间序列原始数据、与异常检测后数据进行对比,代码如下:
dfnew = df.copy()
dfnew['y'][outlier_index] =forecast["yhat"][outlier_index]
fig, ax = plt.subplots()
plt.plot(df['y'],label='原始数据')
plt.plot(dfnew['y'],label='处理后')
plt.legend(loc = 2)
plt.grid()
plt.title("时间序列处理对比图")
plt.show()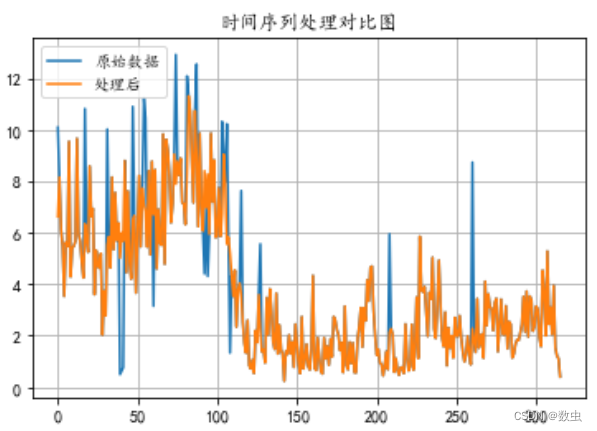
Prophet缺失值填充
对于时间序列的缺失值,同样可采用上述方式,缺失值用预测值进行回填,代码如下:
#空值索引
def null_detection(forecast):
index = np.where(pd.isna(forecast["y"]),True,False)
return index
null_index = null_detection(forecast)
dfnew = df.copy()
dfnew['y'][null_index] =forecast["yhat"][null_index]