点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
明敏 发自 凹非寺
转载自:量子位(QbitAI)
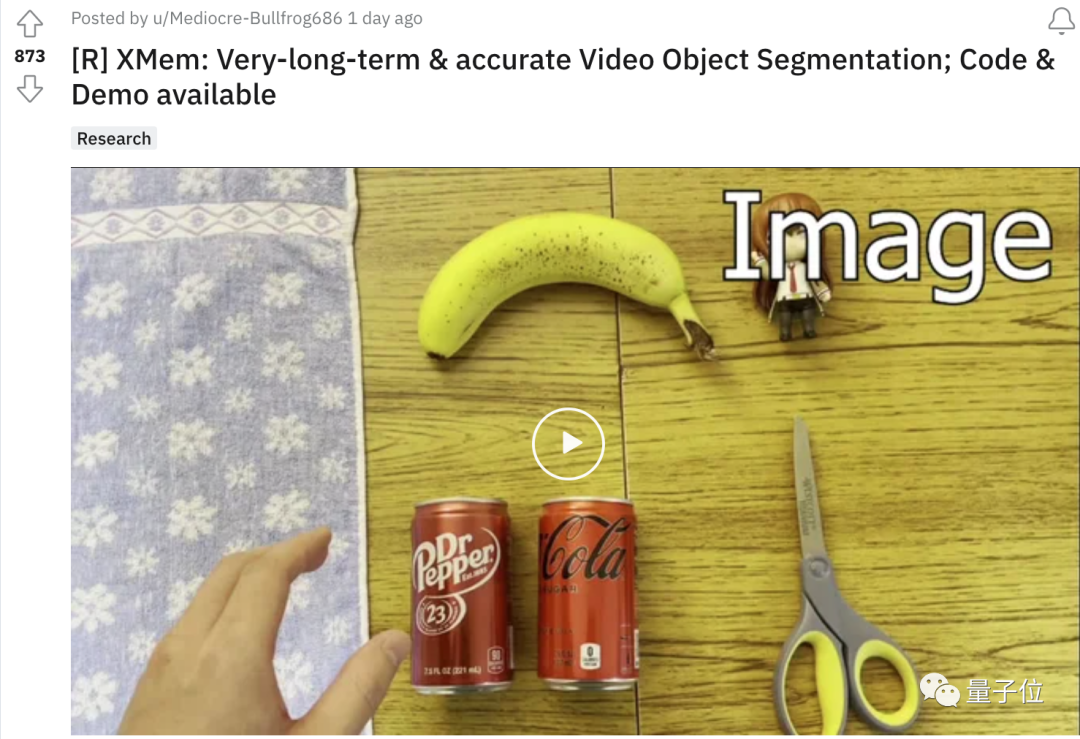
咦,怎么好好的藤原千花,突然变成了“高温红色版”?

这大紫手,难道是灭霸在世??

如果你以为上面的这些效果只是对物体后期上色了,那还真是被AI给骗到了。
这些奇怪的颜色,其实是对视频对象分割的表示。
但u1s1,这效果还真是让人一时间分辨不出。
无论是萌妹子飞舞的发丝:

还是发生形状改变的毛巾、物体之间来回遮挡:
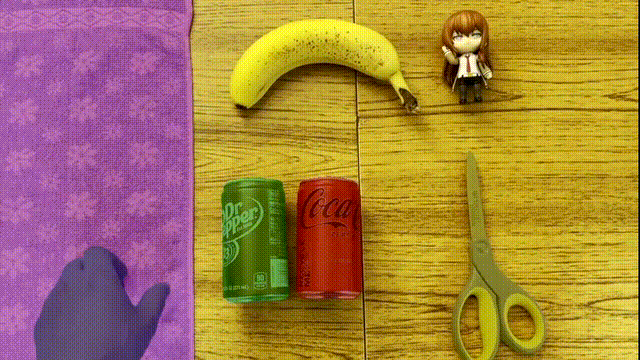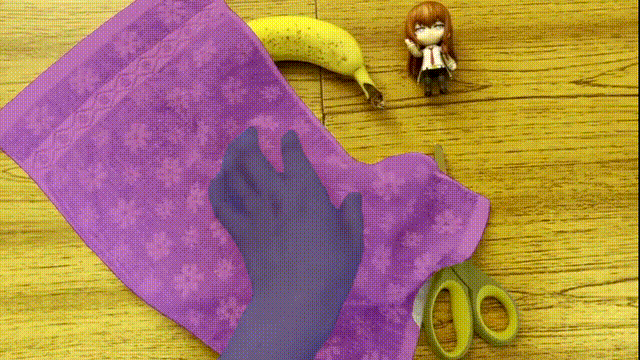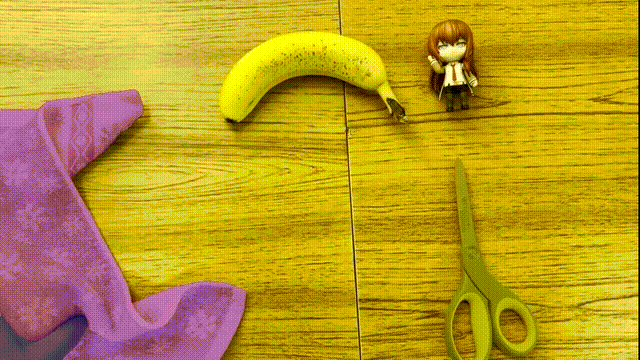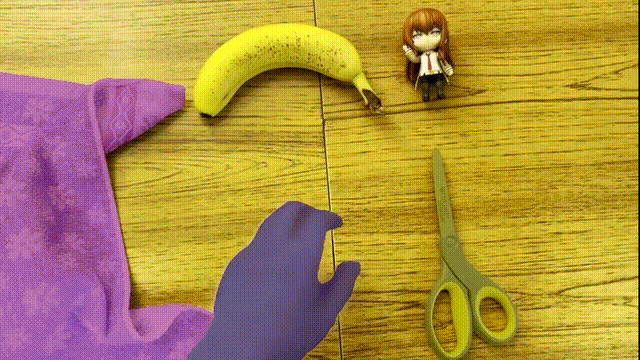
AI对目标的分割都称得上是严丝合缝,仿佛是把颜色“焊”了上去。
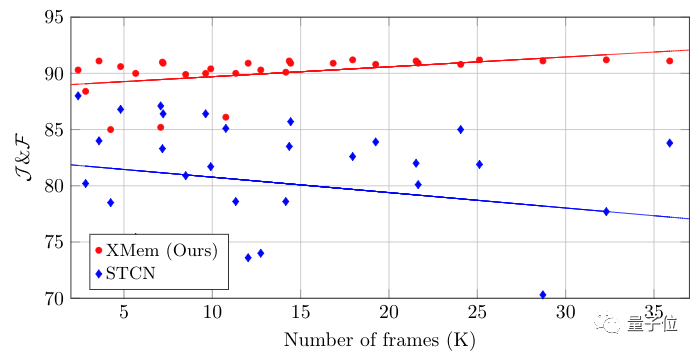
不只是高精度分割目标,这种方法还能处理超过10000帧的视频。
而且分割效果始终保持在同一水平,视频后半段依旧丝滑精细。

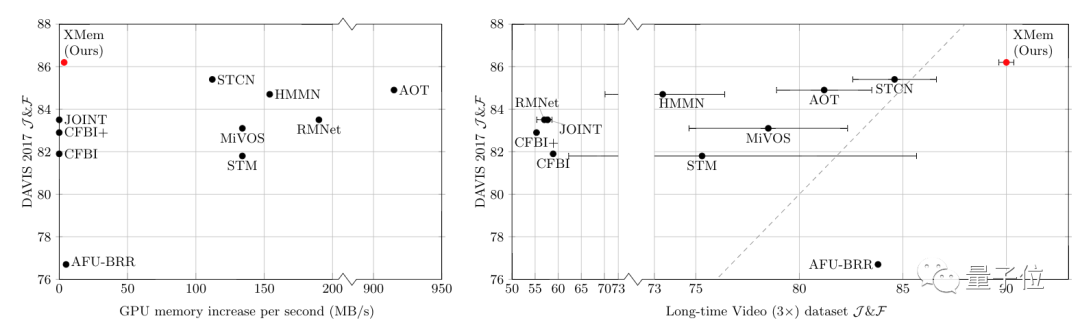
更意外的是,这种方法对GPU要求不高。
研究人员表示实验过程中,该方法消耗的GPU内存从来没超过1.4GB。
要知道,当下基于注意力机制的同类方法,甚至都不能在普通消费级显卡上处理超过1分钟的视频。
这就是伊利诺伊大学厄巴纳-香槟分校学者最新提出的一种长视频目标分割方法XMem。

论文:https://arxiv.org/abs/2207.07115
GitHub:
https://github.com/hkchengrex/XMem
目前已被ECCV 2022接收,代码也已开源。
如此丝滑的效果,还在Reddit上吸引不少网友围观,热度达到800+。
网友都在打趣说:
为什么要把你的手涂成紫色?
谁知道灭霸是不是有计算机视觉方面的爱好呢?
模仿人类记忆法
目前已有的视频对象分割方法非常多,但是它们要么处理速度比较慢,要么对GPU要求高,要么精度不够高。
而本文提出的方法,可以说是兼顾了以上三方面。
不仅能对长视频快速进行对象分割,画面帧数可达到20FPS,同时在普通GPU上就能完成。
其特别之处在于,它受人类记忆模式所启发。
1968年,心理学家阿特金森和希夫林提出多重存储模型(Atkinson-Shiffrin memory model)。
该模型认为,人类记忆可以分为3种模式:瞬时记忆、短期记忆和长期记忆。
参考如上模式,研究人员将AI框架也划分出3种内存方式。分别是:
及时更新的瞬时内存
高分辨率工作内存
密集长期记忆内存。
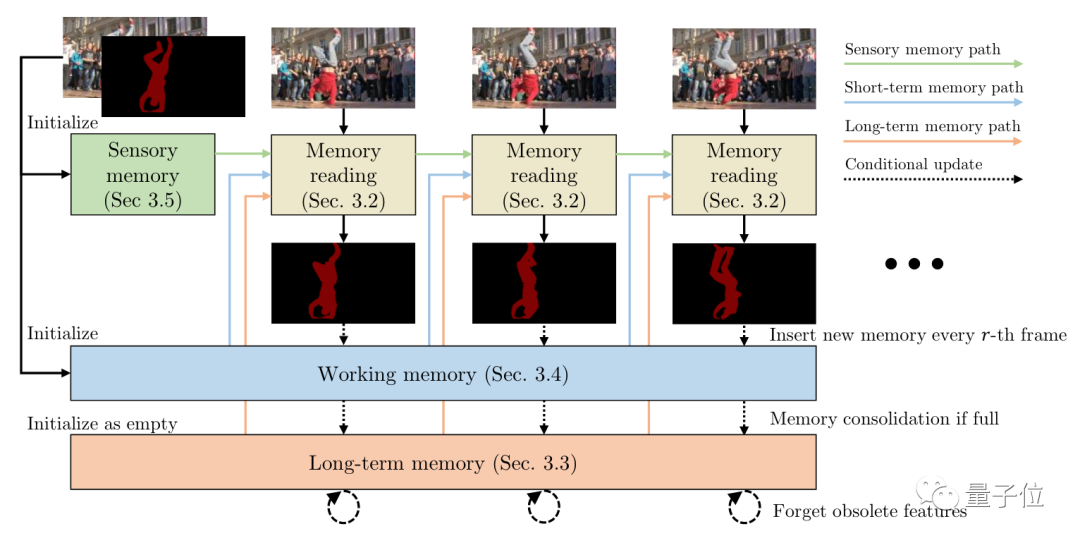
其中,瞬时内存会每帧更新一次,来记录画面中的图像信息。
工作内存从瞬时内存中收集画面信息,更新频率为每r帧一次。
当工作内存饱和时,它会被压缩转移到长期内存里。
而长期内存也饱和时,会随着时间推移忘记过时的特征;一般来说这会在处理过数千帧后才会饱和。
这样一来,GPU内存也就不会因为时间推移而不足了。
通常,对视频目标进行分割会给定第一帧的图像和目标对象掩码,然后模型会跟踪相关目标,为后续帧生成相应的掩码。
具体来看,XMem处理单帧画面的过程如下:
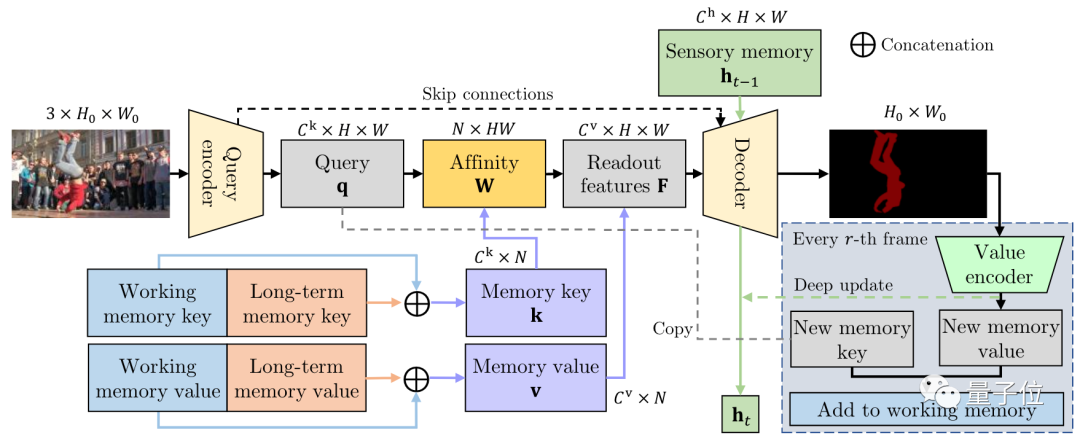
整个AI框架由3个端到端卷积网络组成。
一个查询编码器(Query encoder)用来追踪提取查询特定图像特征。
一个解码器(Decoder)负责获取内存读取步骤的输出,以生成对象掩码。
一个值编码器(Value encoder)可以将图像和目标的掩码相结合,从而来提取新的内存特征值。
最终值编码器提取到的特征值会添加到工作内存中。
从实验结果来看,该方法在短视频和长视频上,都实现了SOTA。
在处理长视频时,随着帧数的增加,XMem的性能也没有下降。
研究团队
作者之一为华人Ho Kei (Rex) Cheng。

他研究生毕业于香港科技大学,目前在伊利诺伊大学厄巴纳-香槟分校读博。
研究方向为计算机视觉。
他先后有多篇论文被CVPR、NeurIPS、ECCV等顶会接收。
另一位作者是 Alexander G. Schwing。

他现在是伊利诺伊大学厄巴纳-香槟分校的助理教授,博士毕业于苏黎世联邦理工学院。
研究方向为机器学习和计算机视觉。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看