文章目录
- 2020
- 2021
-
- Dense Contrastive Learning for Self-Supervised Visual Pre-Training
- Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
- Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
- 2022
- 相关开源库
2020
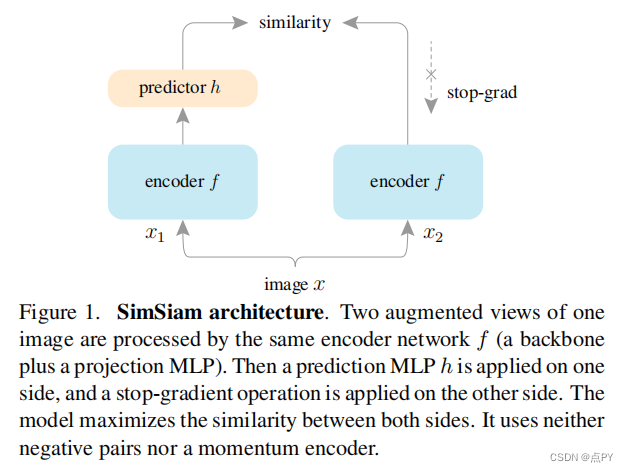
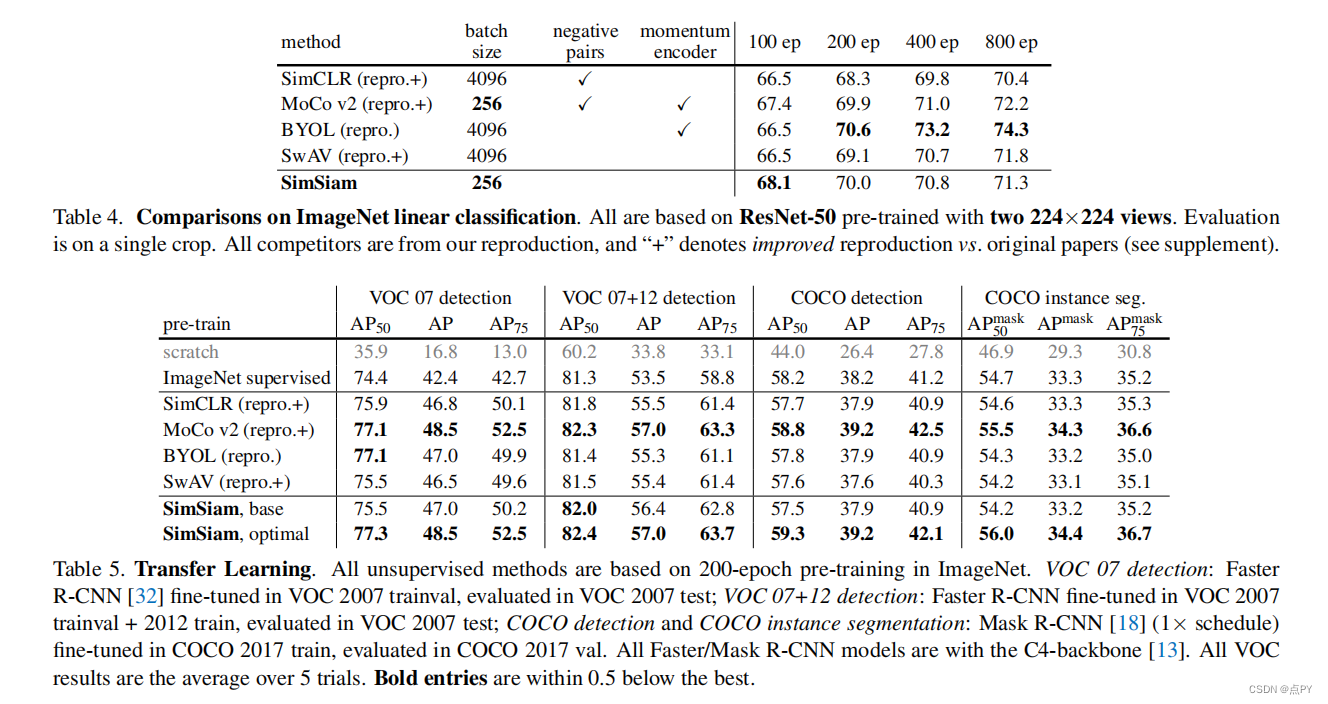
Exploring Simple Siamese Representation Learning
code: https://paperswithcode.com/paper/exploring-simple-siamese-representation
暹罗网络已经成为最近各种无监督视觉表示学习模型的共同结构。这些模型最大限度地提高了一个图像的两个增强之间的相似性,在一定的条件下避免崩溃的解。在本文中,我们报告了令人惊讶的经验结果,简单的暹罗网络可以学习有意义的表示,即使不使用以下内容:(i)负样本对,(ii)大批量,(iii)动量编码器。我们的实验表明,对于损失和结构确实存在坍塌解,但停止梯度操作在防止坍塌方面起着至关重要的作用。我们给出了一个关于停止梯度含义的假设,并进一步证明了概念验证实验的验证。我们的“SimSiam”方法在ImageNet和下游任务上取得了有竞争的结果。我们希望这个简单的基线将激励人们重新思考暹罗体系结构在无监督表示学习中的作用。
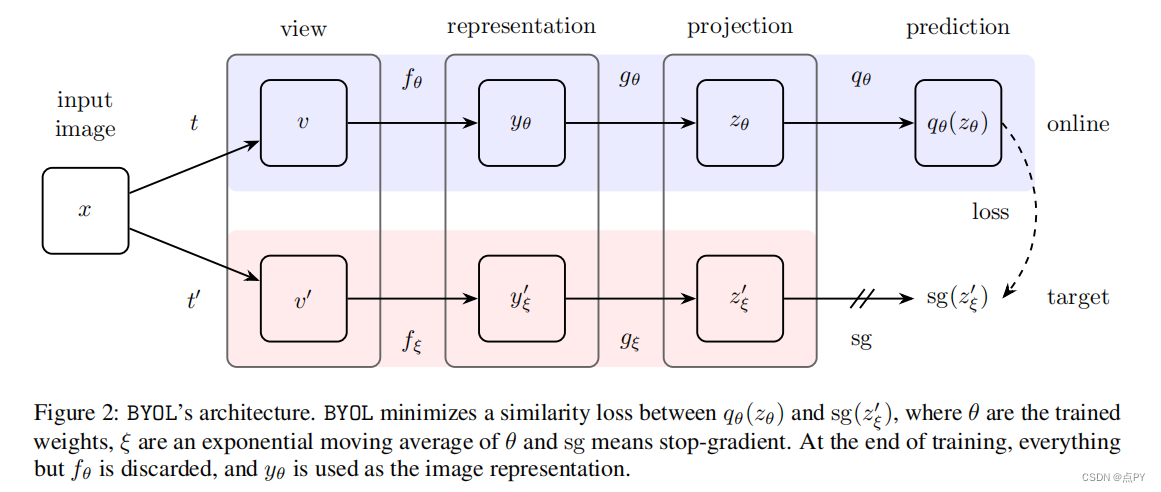
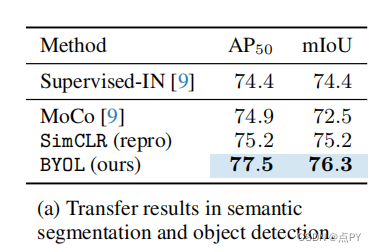
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
code: https://paperswithcode.com/paper/bootstrap-your-own-latent-a-new-approach-to
摘要: 我们介绍了引导你自己的潜在性(BYOL),一种新的自监督图像表示学习方法。BYOL依赖于两个神经网络,即在线网络和目标网络,它们相互作用和相互学习。从一个图像的增广视图出发,我们训练在线网络来预测同一图像在不同的增广视图下的目标网络表示。同时,我们用在线网络的慢移动平均值来更新目标网络。虽然最先进的方法依赖于负对,但BYOL在没有它们的情况下实现了一种新的艺术状态。使用ResNet-50架构的线性评估,BYOL在ImageNet上的分类准确率达到74.3%,使用更大的ResNet的分类准确率达到79.6%。我们证明了BYOL在转移和半监督基准上的表现与当前的水平相当或更好。
2021
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
code: https://paperswithcode.com/paper/dense-contrastive-learning-for-self
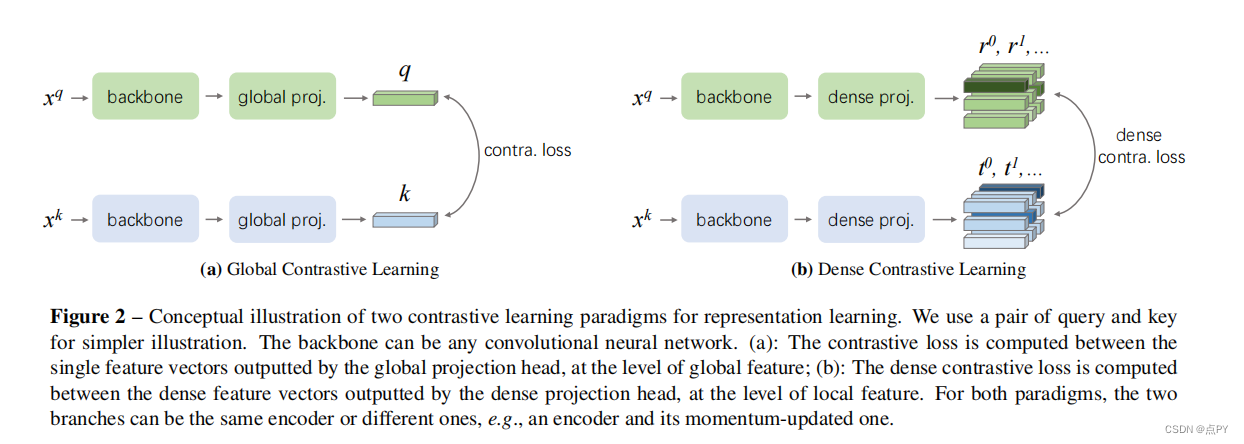
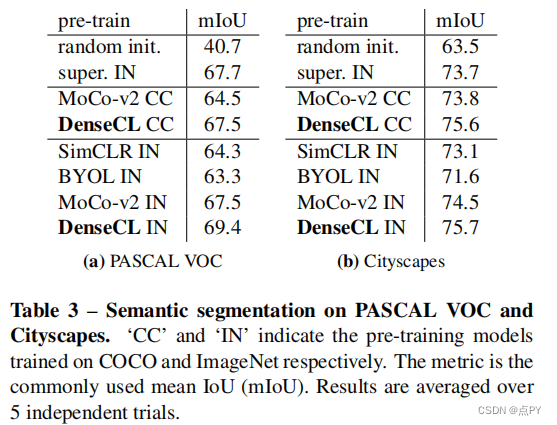
摘要: 到目前为止,大多数现有的自监督学习方法都是为图像分类而设计和优化的。由于图像级预测和像素级预测之间的差异,这些预先训练好的模型对于密集的预测任务可能是次优的。为了填补这一空白,我们的目标是设计一种有效的、密集的自监督学习方法,通过考虑局部特征之间的对应关系,直接在像素(或局部特征)的水平上工作。我们提出了密集对比学习(DenseCL),它通过在输入图像的两个视图之间优化像素水平上的成对对比(dis)相似性损失来实现自监督学习。
与基准方法MoCo-v2相比,我们的方法引入的计算开销可以忽略不计(仅慢1%),但在转移到下游密集预测任务(包括对象检测、语义分割和实例分割)时,表现出持续卓越的性能mance;而且远远超过了最先进的方法。具体而言,在强MoCo-v2基线上,我们的方法在PASCAL VOC对象检测上取得了2.0% AP、COCO对象检测上1.1% AP、COCO 姿态分割上0.9% AP、PASCAL VOC s上3.0% mIoU的显著改进。
Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
code: https://paperswithcode.com/paper/unsupervised-semantic-segmentation-by
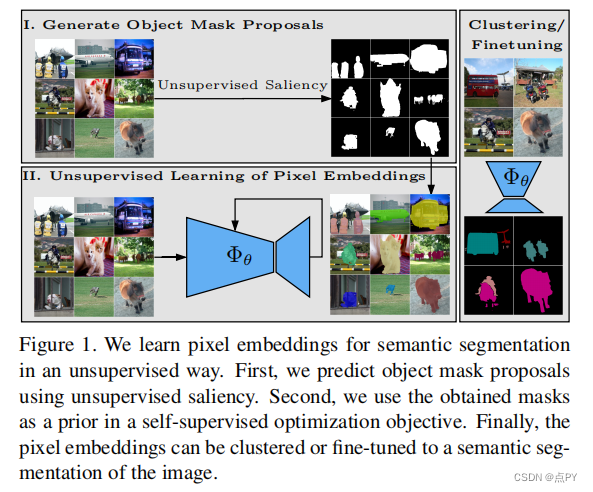
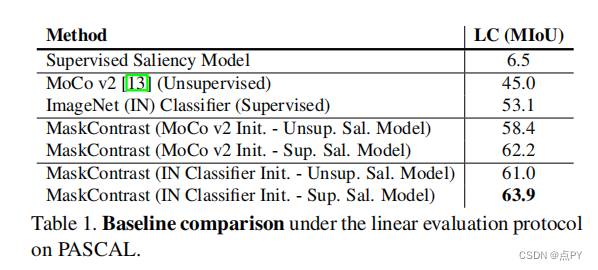
摘要:能够在没有监督的情况下学习图像的密集语义表示是计算机视觉中的一个重要问题。然而,尽管这个问题很重要,但这个问题仍然相当未被探索,除了少数例外,考虑了在具有狭窄视觉域的小规模数据集上的无监督语义分割。在本文中,我们首次尝试解决传统上用于监督情况的数据集上的问题。为了实现这一点,我们引入了一个两步框架,在一个对比优化目标中采用一个预先确定的中间水平先验来学习像素嵌入。这标志着与依赖于代理任务或端到端集群的现有工作有很大的偏差。此外,我们讨论了包含对象或其部分信息的先验的重要性,并讨论了以无监督的方式获得这样种先验的几种可能性。
实验评价表明,我们的方法比现有的工作具有关键的优势。首先,学习到的像素嵌入可以利用pascal上的K-Means直接聚类在语义组中。在完全无监督的设置下,在这样一个具有挑战性的基准测试上解决语义分割任务是没有先例的。其次,当转移到新的数据集时,例如COCO和davis时,我们的表示可以改进超过强基线。
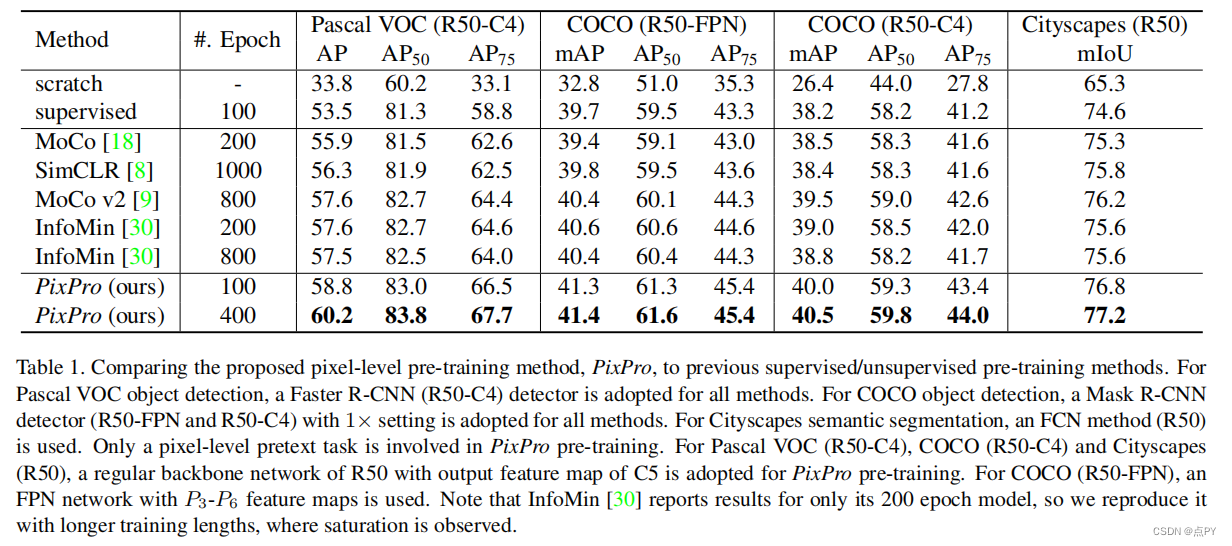
Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
code: https://paperswithcode.com/paper/propagate-yourself-exploring-pixel-level
摘要: 无监督视觉表示学习的对比学习方法已经达到了显著的迁移表现水平。我们认为,对比学习的能力尚未被完全释放,因为目前的方法只在实例级的借口任务上进行训练,导致对于需要密集像素预测的下游任务可能是次优的表示。在本文中,我们引入了像素级的借口任务来学习密集的特征表示。第一个任务直接在像素水平上应用对比学习。此外,我们还提出了一个像素到传播的一致性任务,它可以产生更好的结果,甚至大大超过了最先进的方法。具体来说,通过转移到PascalVOC目标检测(C4)、COCO目标检测(FPN/C4)和城市网络实现60.2AP、60.2AP、41.4/40.5mAP和77.2mIoU语义分割,达到2.6AP、0.8/1.0mAP和1.0mIoU。
此外,像素级借口任务不仅对常规主干网络进行预训练,而且对密集下游任务的头网络也有效,是实例级对比方法的补充。这些结果表明了在像素水平上定义借口任务的强大潜力,并为无监督视觉表示学习提供了一条新的前进路径。

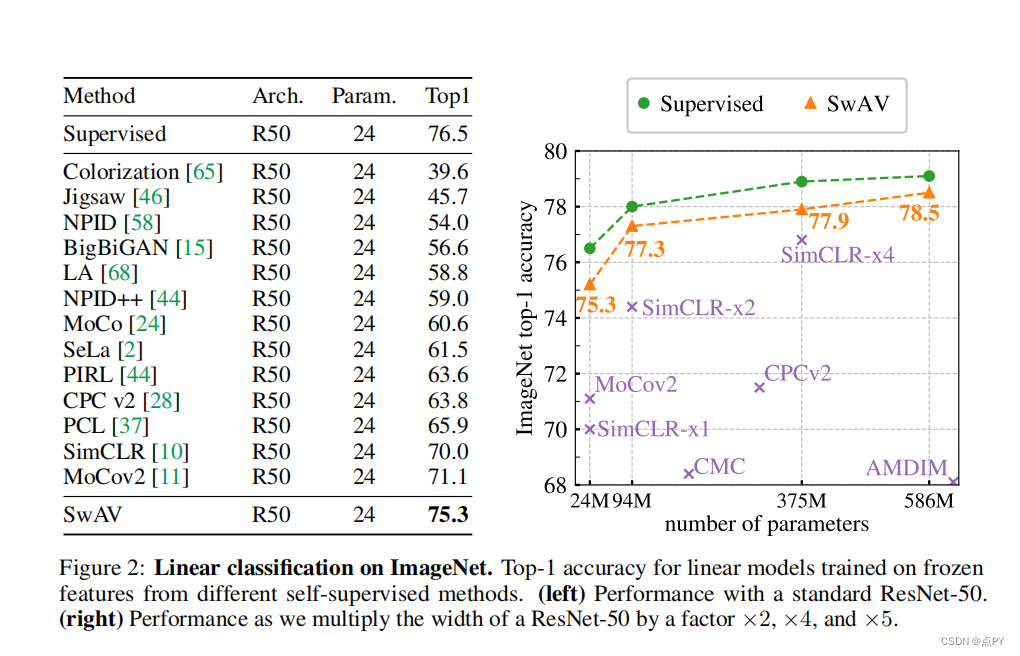
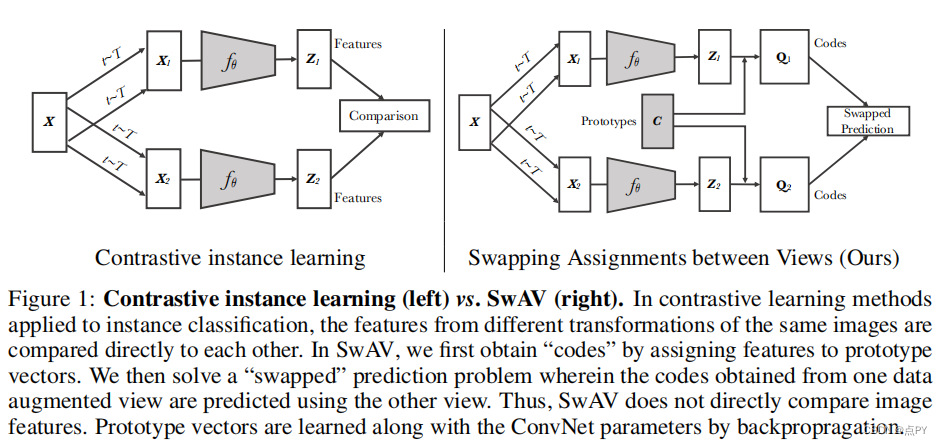
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
code: https://paperswithcode.com/paper/unsupervised-learning-of-visual-features-by
摘要:无监督图像表示显著减少了监督预训练的差距,特别是最近对比学习方法的成就。这些对比方法通常在线工作,依赖于大量显式成对特征比较,这在计算上具有挑战性。在本文中,我们提出了一个在线算法,SWAV,它利用了对比的方法,而不需要计算两两比较。具体来说,我们的方法同时对数据进行聚类,同时加强为同一图像的不同增强(或“视图”)产生的聚类分配之间的一致性,而不是像对比学习那样直接比较特征。简单地说,我们使用一种“交换”的预测机制,其中我们从另一个视图的表示来预测一个视图的代码。我们的方法可以用大批量和小批量进行训练,并可以扩展到无限量的数据。与以往的对比方法相比,我们的方法的内存效率更高,因为它不需要一个大的内存库或一个特殊的动量网络。此外,我们还提出了一种新的数据增强策略,多作物,它使用不同分辨率的混合视图来代替两个全分辨率的视图,而不增加内存或计算需求。我们通过使用ResNet-50在ImageNet上达到75.3%的前1名准确率,并在所有考虑的转移任务上超过监督预训练来验证我们的发现。
2022
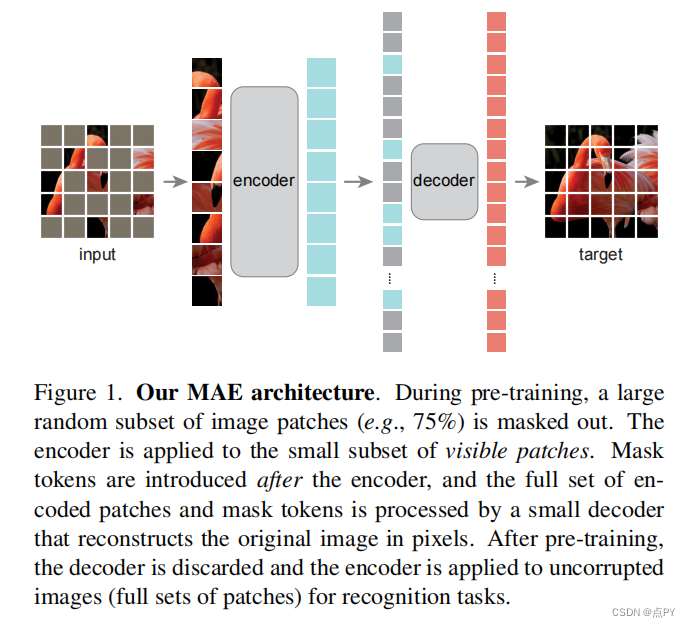
Masked Autoencoders Are Scalable Vision Learners
code: https://paperswithcode.com/paper/masked-autoencoders-are-scalable-vision
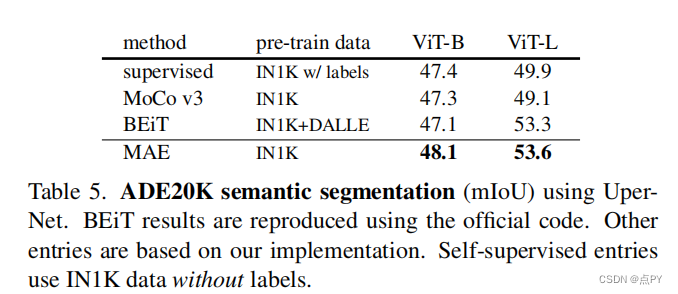
摘要: 本文证明了掩码自动编码器(MAE)是一种可扩展的计算机视觉自监督学习者。我们的MAE方法很简单:我们掩蔽输入图像的随机斑块,并重建缺失的像素。它是基于两个核心的设计。首先,我们开发了一个非对称的编码-解码器架构,一个编码器只操作于补丁的可见子集(没有掩码标记),以及一个轻量级解码器,从潜在表示和掩码标记重构原始图像。其次,我们发现掩盖高比例的输入图像,例如75%,产生一个平凡和有意义的自我监督任务。耦合这两种设计使我们能够有效地训练大型模型:我们加速训练(3×或更多)并提高准确性。我们的可扩展方法允许学习能够很好地推广的高容量模型:例如,在只使用ImageNet-1K数据的方法中,一个普通的ViT-Huge模型达到了最好的精度(87.8%)。在下游任务中的传输性能优于监督预训练,并显示出良好的缩放行为。
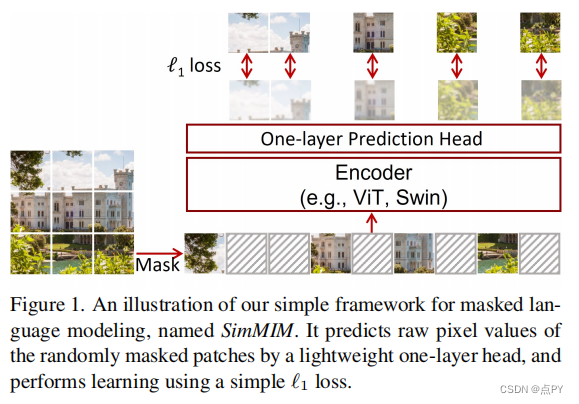
SimMIM: a Simple Framework for Masked Image Modeling
code: https://github.com/microsoft/simmim
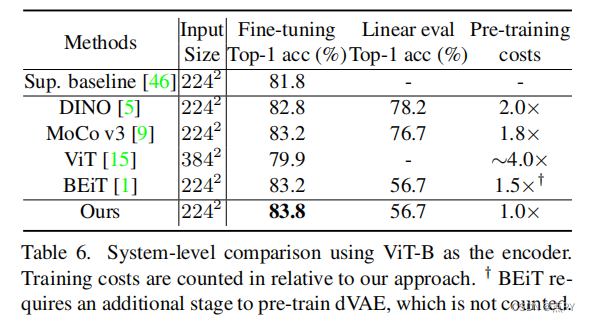
摘要: 本文提出了一个简单的掩蔽图像建模框架SimMIM。我们已经简化了最近提出的相关方法,而不需要特殊的设计,如通过离散VAE或聚类的块级掩蔽和标记化。调查是什么使掩蔽图像建模任务学习良好的表示,我们系统地研究主要组件框架,发现每个组件的简单设计显示了非常强的表示学习性能:1)随机掩蔽的输入图像中等大屏蔽补丁大小(例如,32)使一个强大的预文本任务;2)通过直接回归预测原始像素的RGB值表现并不比复杂设计的补丁分类方法差;3)预测头可以像线性层一样轻,不会比较重的层差。使用ViT-B,我们的方法也在该数据集上通过预训练,在ImageNet-1K上达到83.8%的前1微调精度,超过之前的最佳方法+0.6%。当应用于具有约6.5亿参数的更大模型SwinV2-H时,仅使用ImageNet-1K数据在ImageNet-1K上达到87.1%的前1精度。我们还利用这种方法来解决大规模模型训练所面临的数据需求问题,即3B模型(SwinV2-G)被成功训练,以在四个具有代表性的视觉基准上实现最先进的准确性,使用比以往的实践(JFT-3B)少40×的标记数据。
相关开源库
https://github.com/alibaba/EasyCV