提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
由于深度学习模型结构越来越复杂,参数量也越来越大,需要大量的算力去做模型的训练和推理。然而随着移动设备的普及,将深度学习模型部署于计算资源有限基于ARM的移动设备成为了研究的热点。
ShuffleNet是一种专门为计算资源有限的设备设计的神经网络结构,主要采用了pointwise group convolution 和 channel shuffle两种技术,在保留了模型精度的同时极大减少了计算开销。
在论文中,提到了目前sota的两个工作,一个是谷歌的Xception,另一个是facebook推出的ResNeXt。
Xception主要涉及了一个技术:深度可分离卷积,即把原本常规的卷积操作分为两步去做。
普通卷积

深度可分离卷积(逐点卷积(PointWise Convolution)和深度卷积(DepthWise Convolution))
DW

PW
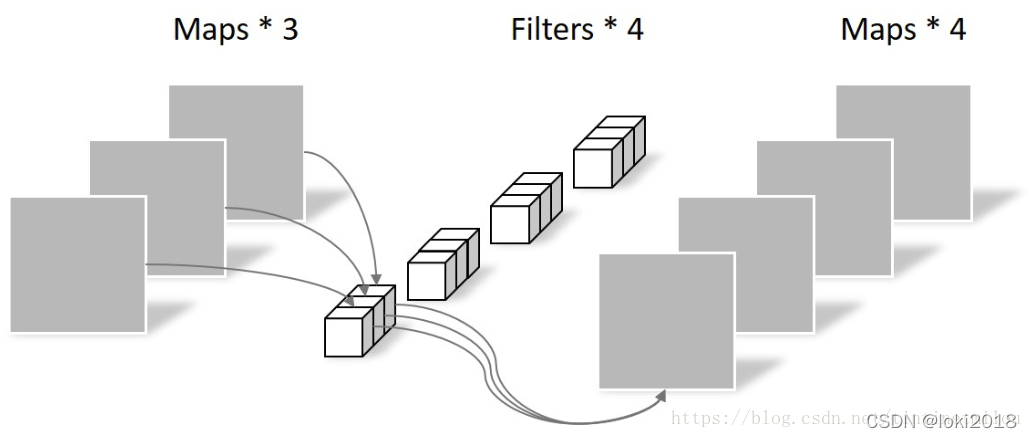
这样做的好处是降低了常规卷积时的参数量,假设输入通道为M, 输出通道为N ,卷积核大小为k × k , 那么k×k,那么常规卷积的参数是:N × M × k × k 。而通过深度可分离卷积之后,参数量为M × k × k + N × M × 1 × 1
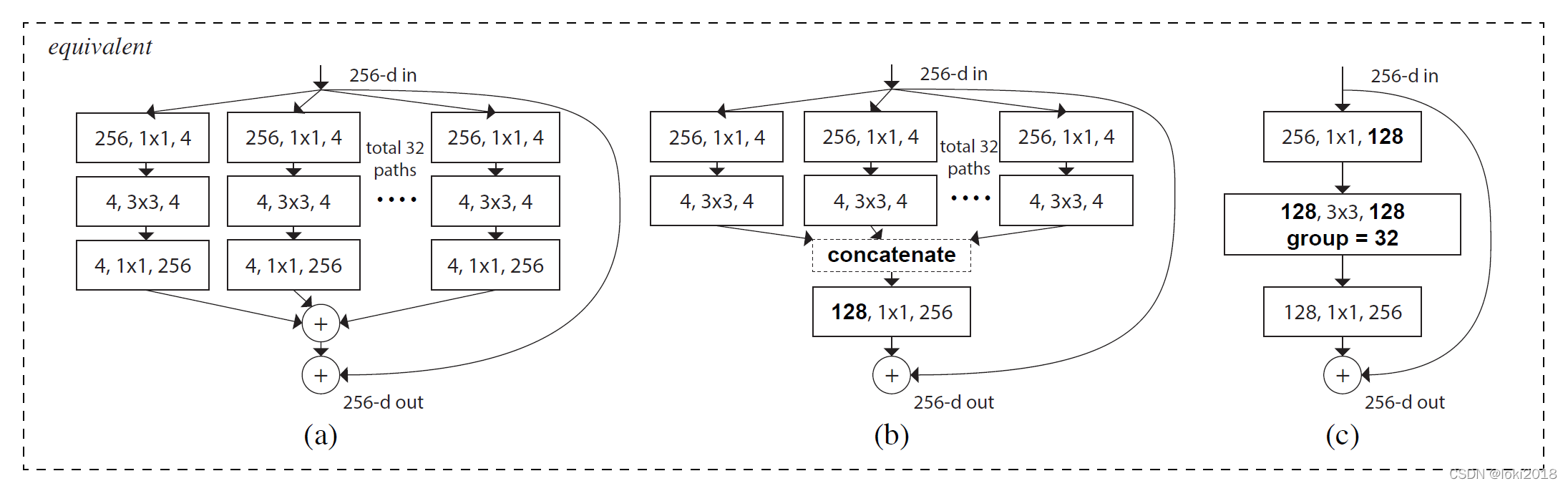
灵感来源于VGG的模块化堆叠的结构,提出了一种基于分组卷积和残差连接的模块化卷积块从而降低了参数的数量。
————————————————
版权声明:本文为CSDN博主「loki2018」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/loki2018/article/details/124077822
提示:以下是本篇文章正文内容,下面案例可供参考
一、shufflenetV1
由于使用1 × 1 卷积核进行操作时的复杂度较高,因为需要和每个像素点做互相关运算,作者关注到ResNeXt的设计中,1 × 1 卷积操作的那一层需要消耗大量的计算资源,因此提出将这一层也设计为分组卷积的形式。然而,分组卷积只会在组内进行卷积,因此组和组之间不存在信息的交互,为了使得信息在组之间流动,作者提出将每次分组卷积后的结果进行组内分组,再互相交换各自的组内的子组。
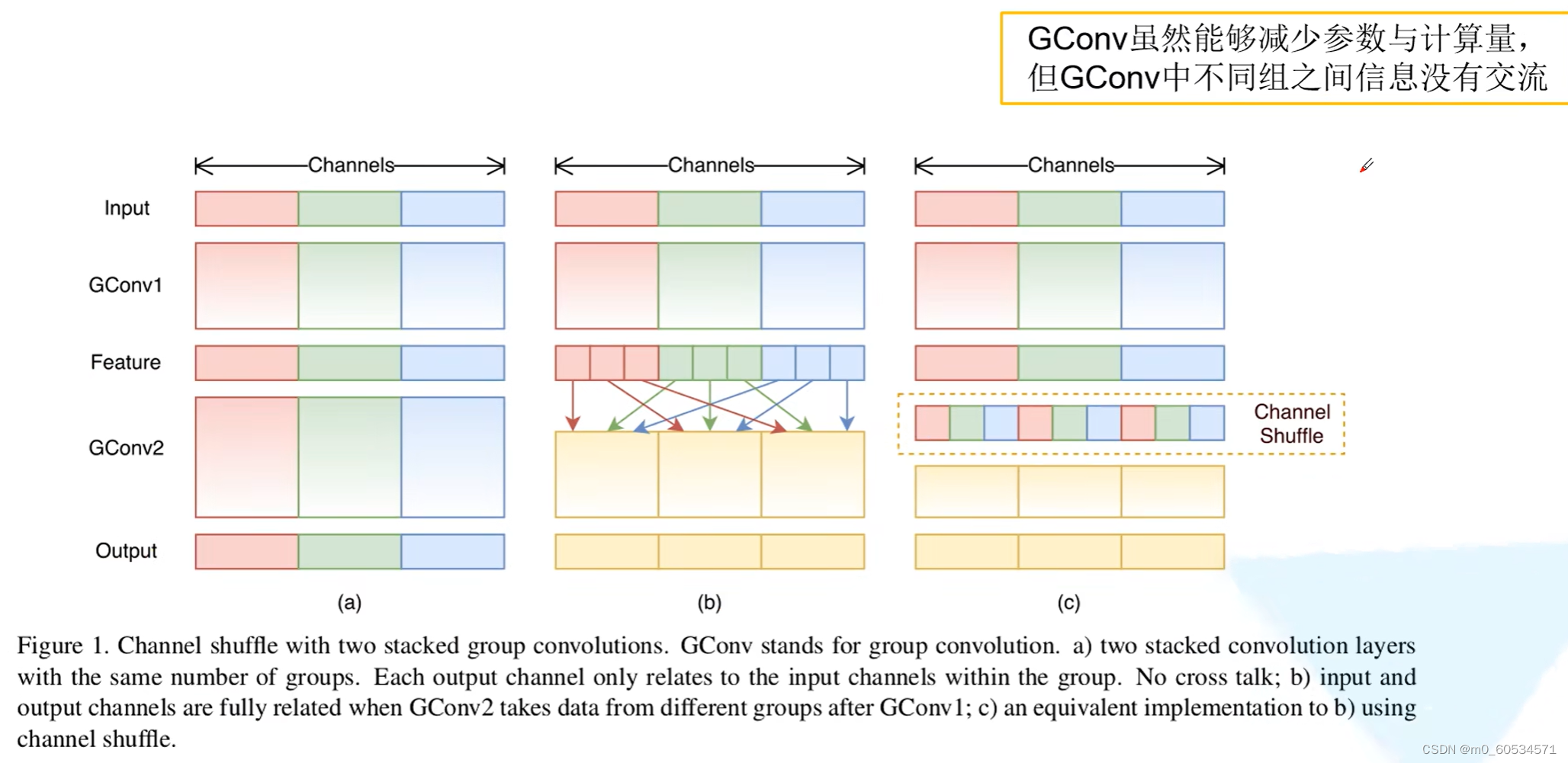
shufflenet Unit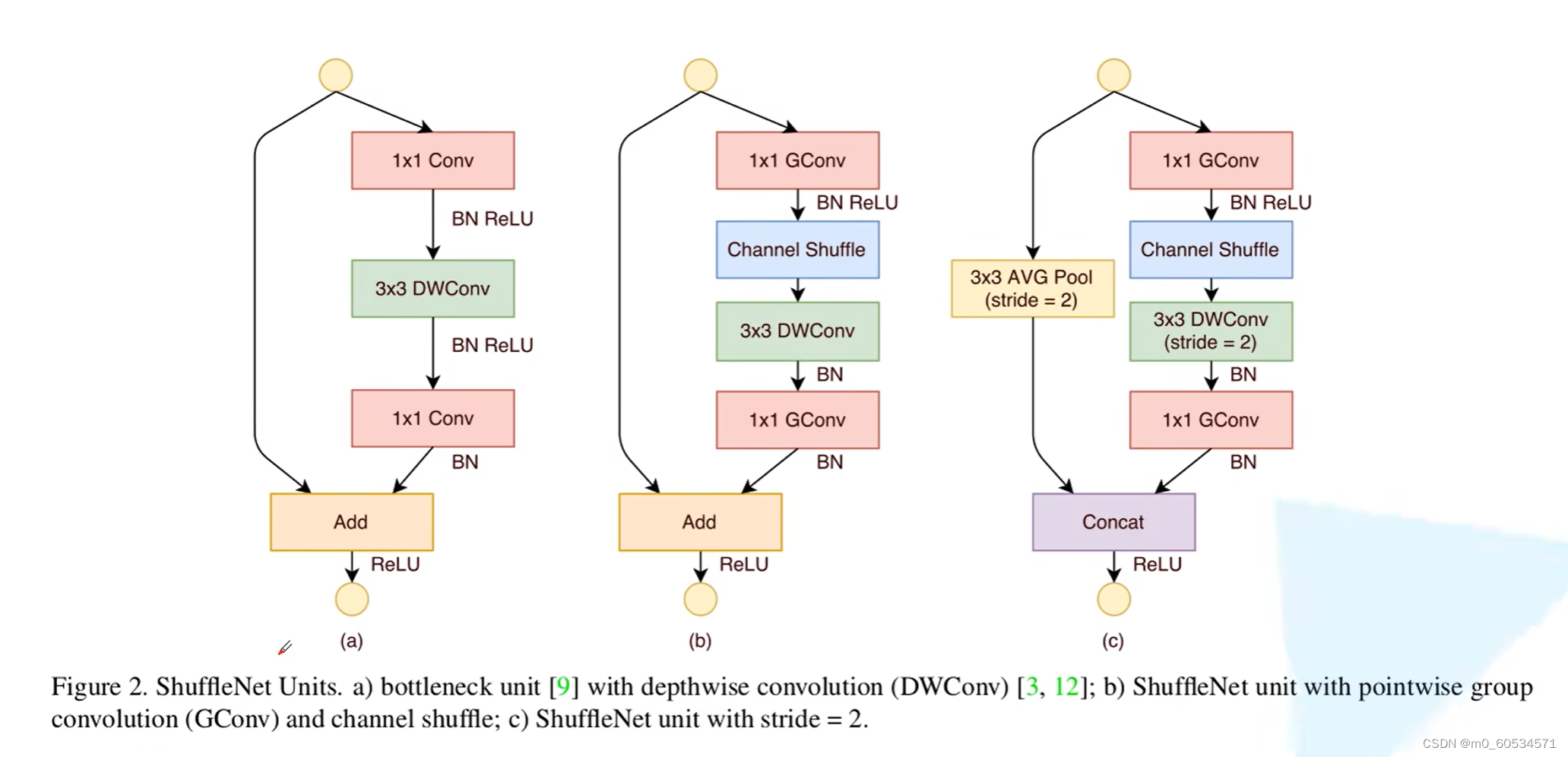
二、ShuffleNetV2

不同操作在不同设备的时间

四个设计轻量化网络的原则:
- 当卷积层的输入特征矩阵与输出特征矩阵channel相等时MAC最小(保持FLOPs不变)
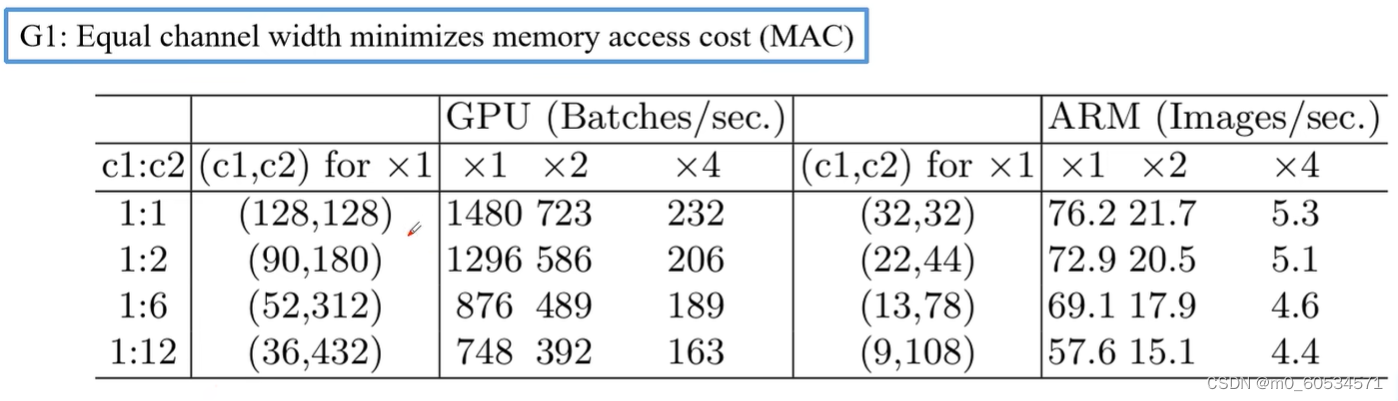
- 分组卷积的分组数过大也会导致MAC增加,(保持FLOPs不变)

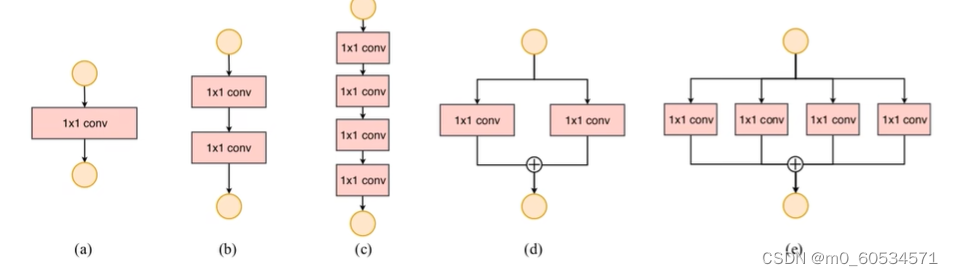
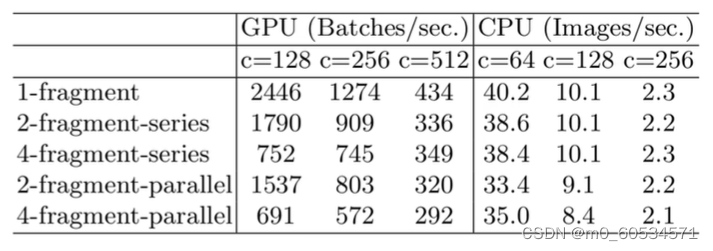
- 网络碎片化(分支)程度越高,速度越慢
- Element—wise操作(如ReLU,AddBias,AddTensor,etc)会增加内存的消耗

总结

- 当卷积层的输入特征矩阵与输出特征矩阵channel的比值尽可能接近1
- 不能一味增加分组卷积的分组数
- 降低碎片化程度
- 减少element—wise操作
shuffleNet v2 的结构
