使用Keras训练Lenet网络来进行手写数字识别
这篇博客将介绍如何使用Keras训练Lenet网络来进行手写数字识别。
- LeNet架构是深度学习中的一项开创性工作,演示了如何训练神经网络以端到端的方式识别图像中的对象(即不必进行特征提取,网络能够从图像本身学习模式)。首先由LeCun等人介绍。在他们1998年的论文中,基于梯度的学习应用于文档识别。正如论文名称所示,作者实现LeNet的动机主要是为了光学字符识别(Optical Character Recognition OCR)。
- 尽管具有开创性意义,但按照今天的标准,LeNet仍然被认为是一个“肤浅”的网络。由于只有四个可训练层(两个CONV层和两个FC层),LeNet的深度与当前最先进的架构(如VGG(16和19层)和ResNet(100多层))的深度相比相形见绌。
- LeNet架构简单且小(就内存占用而言),非常适合学习CNN的基础知识。
这篇博客将首先回顾LeNet架构,然后使用Keras实现网络。最后将在MNIST数据集上评估用于手写数字识别的LeNet。
1. 效果图
训练20,10个纪元都报错,直接cpu 100%卡死了。调整8个纪元,成功…
2022-07-04 22:34:57.847384: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-07-04 22:34:57.848391: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
[INFO] accessing MNIST...
[INFO] compiling model...
D:\python374\lib\site-packages\keras\optimizer_v2\optimizer_v2.py:356: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
"The `lr` argument is deprecated, use `learning_rate` instead.")
2022-07-04 22:35:35.461843: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'nvcuda.dll'; dlerror: nvcuda.dll not found
2022-07-04 22:35:35.462571: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2022-07-04 22:35:35.467148: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: WIN10-20180515Z
2022-07-04 22:35:35.467837: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: WIN10-20180515Z
2022-07-04 22:35:35.468665: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
[INFO] training network...
2022-07-04 22:35:38.528379: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/8
1/469 [..............................] - ETA: 4:54 - loss: 2.3132 - accuracy: 0.1250
2/469 [..............................] - ETA: 27s - loss: 2.3172 - accuracy: 0.1211
3/469 [..............................] - ETA: 27s - loss: 2.3099 - accuracy: 0.1354
4/469 [..............................] - ETA: 26s - loss: 2.3119 - accuracy: 0.1387
5/469 [..............................] - ETA: 27s - loss: 2.3136 - accuracy: 0.1375
6/469 [..............................] - ETA: 27s - loss: 2.3145 - accuracy: 0.1289
7/469 [..............................] - ETA: 27s - loss: 2.3133 - accuracy: 0.1306
8/469 [..............................] - ETA: 27s - loss: 2.3121 - accuracy: 0.1348
...
...
...
467/469 [============================>.] - ETA: 0s - loss: 1.0499 - accuracy: 0.7285
468/469 [============================>.] - ETA: 0s - loss: 1.0482 - accuracy: 0.7290
469/469 [==============================] - 28s 58ms/step - loss: 1.0469 - accuracy: 0.7293 - val_loss: 0.2980 - val_accuracy: 0.9138
Epoch 2/8
...
...
...
Epoch 8/8
...
...
...
468/469 [============================>.] - ETA: 0s - loss: 0.0795 - accuracy: 0.9769
469/469 [==============================] - 26s 55ms/step - loss: 0.0795 - accuracy: 0.9769 - val_loss: 0.0639 - val_accuracy: 0.9791
[INFO] evaluating network...
precision recall f1-score support
0 0.98 0.99 0.98 980
1 0.99 0.99 0.99 1135
2 0.98 0.98 0.98 1032
3 0.99 0.97 0.98 1010
4 0.98 0.98 0.98 982
5 0.98 0.98 0.98 892
6 0.98 0.98 0.98 958
7 0.98 0.97 0.98 1028
8 0.96 0.98 0.97 974
9 0.97 0.96 0.97 1009
accuracy 0.98 10000
macro avg 0.98 0.98 0.98 10000
weighted avg 0.98 0.98 0.98 10000
可以看到,LeNet获得了98%的分类精度,比使用标准前馈神经网络时的92%有了很大提高。
随时间变化的损耗和精度图如下:
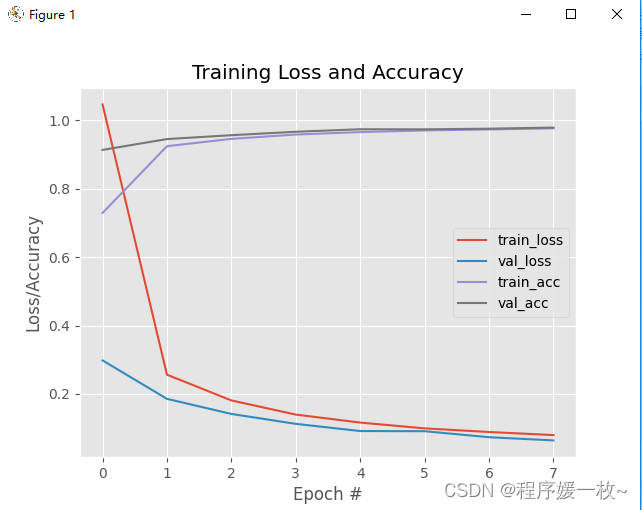
可以看出网络表现得相当好。在5个纪元之后已经到达了≈96%的分类准确率。由于学习速度保持不变且没有衰减,训练和验证数据的损失持续下降,只有少数小的“尖峰”。在8个纪元后,测试集的准确率达到了98%。
训练和验证损失和精度(几乎)完全相互模仿,没有过度拟合的迹象。通常很难获得这种表现如此良好的训练图,这表明网络在不过度拟合的情况下正在学习底层模式。
MNIST数据集经过了大量预处理,不能代表在现实世界中会遇到的图像分类问题。研究人员倾向于使用MNIST数据集作为基准来评估新的分类算法。如果他们的方法无法获得>95%的分类精度,则在(1)算法的逻辑或(2)实现本身中存在缺陷。
2. 原理
pip install opencv-contrib-python
-
LeNet架构是一个优秀的“真实世界”网络。该网络很小,易于理解,也足够大,可以提供有趣的结果。
-
LeNet架构由两系列CONV=>TANH=>POOL层集组成,然后是完全连接层和softmax输出。
-
LeNet+MNIST的组合能够轻松在CPU上运行,使初学者更容易在深度学习和CNN中迈出第一步。(LeNet+MNIST是应用于图像分类的深度学习的“Hello,World”等价物。)
-
LeNet架构由以下层组成,使用卷积神经网络(CNN)的CONV=>ACT=>POOL模式和层类型:
INPUT => CONV => TANH => POOL => CONV => TANH => POOL => FC => TANH => FC
-
LeNet架构使用tanh激活函数,而不是更流行的ReLU。早在1998年,ReLU还没有在深度学习中使用——更常见的是使用tanh或sigmoid作为激活函数。
表1总结了LeNet架构的参数。输入层获取具有28行28列的输入图像,并使用单通道(灰度)表示深度(即MNIST数据集中图像的尺寸)。然后学习20个滤波器,每个滤波器为5×5。CONV层之后是ReLU激活,然后是2×2大小和2×2步幅的最大池。
架构的下一个块遵循相同的模式,这次学习50个5×5滤波器。随着实际空间输入维度的减少,网络深层的CONV层数量增加是很常见的。
然后有两个FC层。第一个FC包含500个隐藏节点,然后是ReLU激活。最后一个FC层控制输出类标签的数量(0-9;可能的十位数字中每一位一个)。最后应用softmax激活来获得类概率。
3. 源码
# 使用LeNet进行手写数字识别
# USAGE
# python lenet_mnist.py
# 1. 从磁盘加载MNIST数据集
# 2. 实例化LeNet架构
# 3. 训练LeNet模型
# 4. 评估网络性能
# 在绝大多数机器学习情况下,几乎所有的示例都遵循这种通用的导入模式:
# 将要训练的网络架构、用于训练网络的优化器(SGD)、用于构造给定数据集的训练和测试分割的(一组)便利函数、一个用于计算分类报告的函数,以便评估分类器的性能;
# 以及一些额外的类,以方便执行某些任务(例如预处理图像)。
# 导入必要的包
from pyimagesearch.nn.conv.lenet import LeNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import mnist
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# MNIST数据集已经过预处理(11MB第一次会自动下载)
# load_data()会从Keras数据集存储库下载MNIST数据集。MNIST数据集被序列化为单个11MB文件,
# 注意:每个MNIST样本内部数据由28×28灰度图像的784-d矢量(即原始像素强度)表示。因此需要根据“通道优先”还是“通道最后”排序来重塑数据矩阵:
print("[INFO] accessing MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# 如果是通道优先,则转换为样本数*深度*高度*宽度
if K.image_data_format() == "channels_first":
trainData = trainData.reshape((trainData.shape[0], 1, 28, 28))
testData = testData.reshape((testData.shape[0], 1, 28, 28))
# 如果是通道最后,则转换矩阵为:num_samples x rows x columns x depth
else:
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
# 将图像像素强度缩放到[0,1]范围
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
# 转换类标签编码为一个热向量,而不是单个整数值。如3,转换为热编码:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
# 注意:向量中的所有项都是零,数字0是第一个索引,因此为什么三是第四个索引
le = LabelBinarizer()
trainLabels = le.fit_transform(trainLabels)
testLabels = le.transform(testLabels)
# 初始化优化器和模型
# 以0.01的学习率初始化SGD优化器
# 实例化LeNet,表明数据集中的所有输入图像都将是28像素宽、28像素高,深度为1。假设MNIST数据集中有十个类(每个数字一个,0−8) 因此将标签类型设置为10
# 使用交叉熵损失作为损失函数来编译模型
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# 训练网络
# 使用128个小批量在MNIST上训练LeNet总共10个纪元
print("[INFO] training network...")
H = model.fit(trainData, trainLabels,
validation_data=(testData, testLabels), batch_size=128,
epochs=8, verbose=1)
# 评估网络的性能,并绘制随时间变化的损失和准确性图表
# 调用model.predict() 对于testX中的每个样本,构造128个批量,然后通过网络进行分类。对所有测试数据点进行分类后,返回预测变量。
# 预测变量实际上是一个NumPy数组,形状为(len(testX),10),这意味着现在有10个概率与testX中每个数据点的每个类标签相关。
# classification_report中的argmax(axis=1)查找概率最大的标签索引(即最终输出分类)。给定网络的最终分类,可以将预测的类标签与实际的标签值进行比较。
print("[INFO] evaluating network...")
predictions = model.predict(testData, batch_size=128)
print(classification_report(testLabels.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in le.classes_]))
# 绘制训练/验证的损失/准确度图表
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 8), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 8), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 8), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 8), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()