文章目录
环境搭建
Python 3.6
tensorflow 1.13.1
keras 2.2.4
pip install tensorflow==1.13.1
pip install keras==2.2.4
程序进程
读入手写数据集
import keras
from keras.datasets import mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
该手写数据集位于 keras 包里面,这时程序自动从官网下载数据;
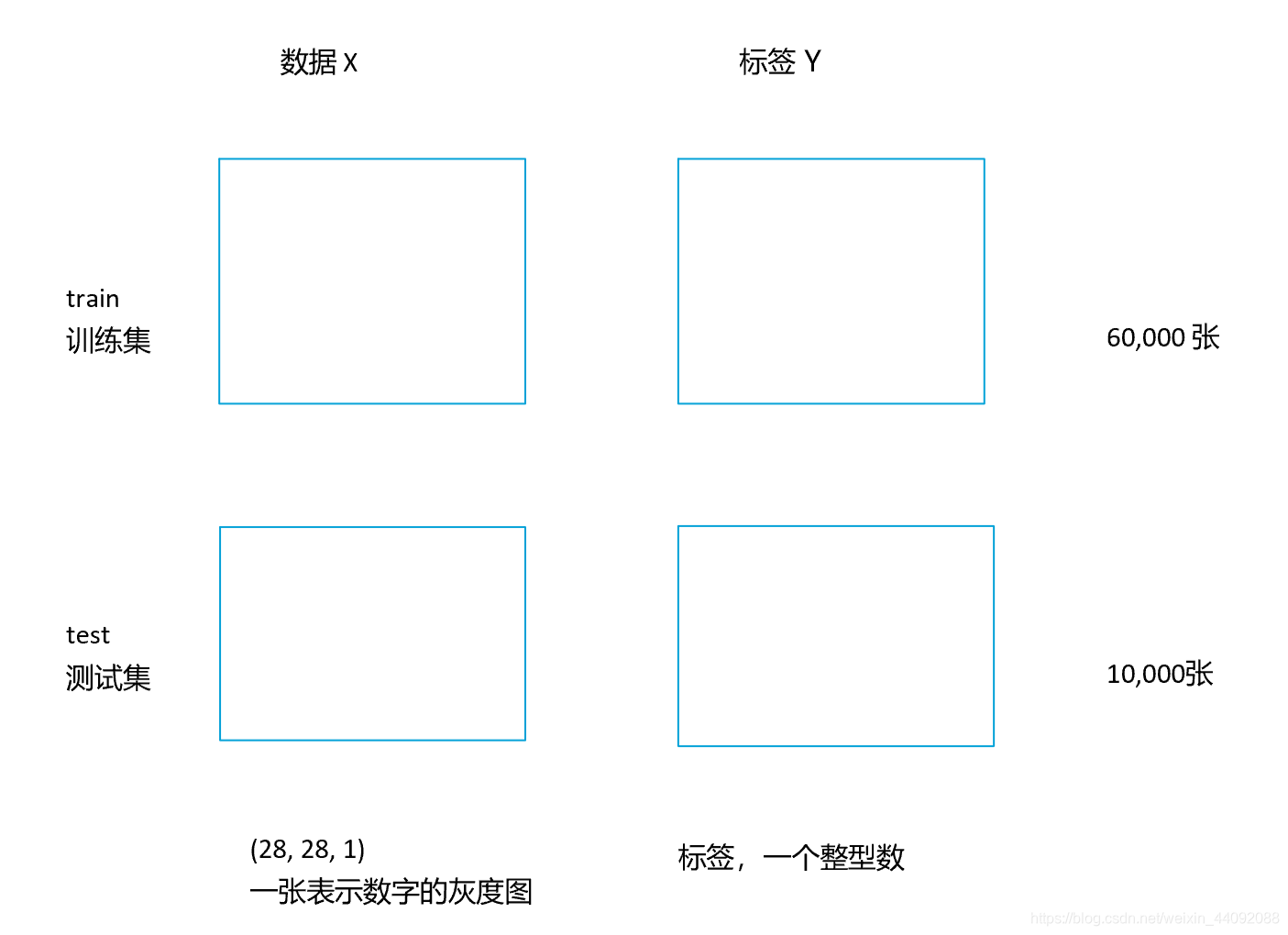
手写数据集:
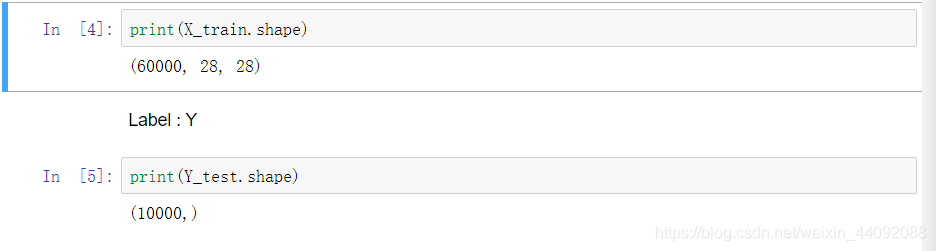
查看 X, Y 的格式如下:
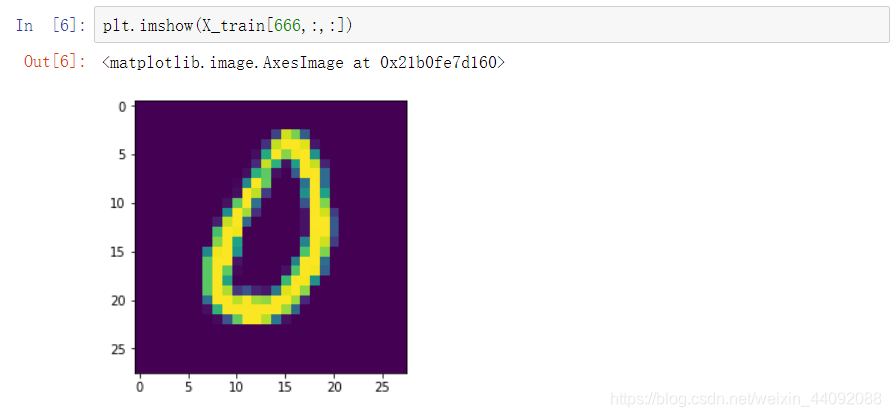
X_train 里面是一张张图片:
对应的标签 Y_train 是一个整形数,表示该图片是什么数字:

把输入数据整理成模型可以接受的格式
X_train = X_train.reshape(60000, 28, 28, 1)
X_test = X_test.reshape(10000, 28, 28, 1)
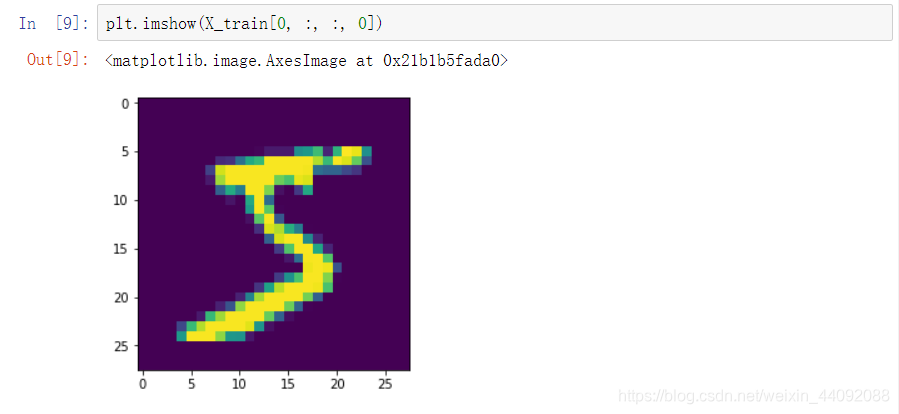
训练集第一个图片数据,好像是5,(注意最后一个参数一定要写 0,试过 “:”不管用)
测试集的数据也类似,其中第一个测试图片:
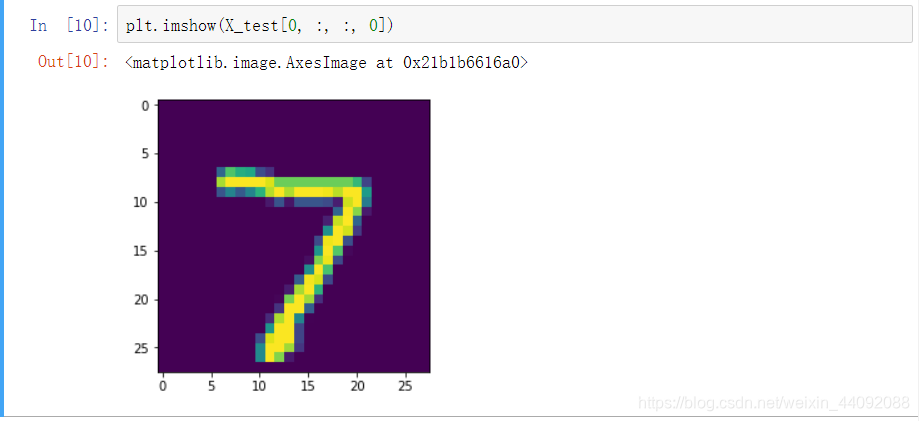
查看转换后的格式:

只是多加了一个维度而已
查看输入图像数据的范围:

数值在 0 ~ 255 之间,下面转化为 0 ~ 1 之间,进行归一化处理:
X_train = X_train / 255
X_test = X_test / 255

对输出数据进行 one-hot-codeing
简单来说,用稀疏矩阵表示预测结果,有 n 种分类结果,矩阵就有 n 列,第 j 列为 1 表示第 j 类预测结果的可能性最大。
Y_train = keras.utils.to_categorical(Y_train, 10)
Y_test = keras.utils.to_categorical(Y_test, 10)
查看格式:

确实变宽了。
查看第 101 个标签,顺带看看图片数据:
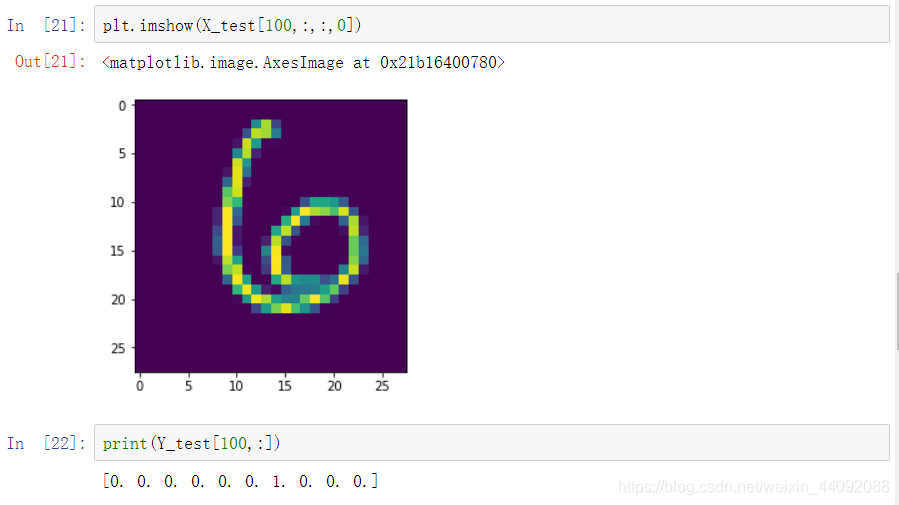
分类共有10种,0,1,2, …,9,这里第 7 列为 1,表示结果为 6,确实看上去像 6
搭建模型
model = Sequential() # 空模型
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten()) # 展开成一维
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(10, activation="softmax"))
简单解释解释:
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
Conv2D 第一个参数 32 表示最后结果吐出来是 32层的 ( m ∗ n ∗ 3 m*n*3 m∗n∗3 --> m ′ ∗ n ′ ∗ 32 m'*n'*32 m′∗n′∗32)
第二个参数 (3, 3) 表示卷积算子的大小;
input_shape 是输入数据的格式
model.add(Dense(200))
叠加 200 层神经网络(好像是最普通的那种,还是隐藏层。。。没怎么理解)
查看模型信息:(忽略表示运行进程的那个中括号里的数字)

定义模型的优化器
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
选用 Adam 优化器,引入了参数 β 1 β_1 β1, β 2 β_2 β2, ε ε ε,取常用的值,lr 是学习率,设置为 0.001
损失函数用交叉熵,衡量模型表现的准确率计算公式选用 accuracy
训练模型
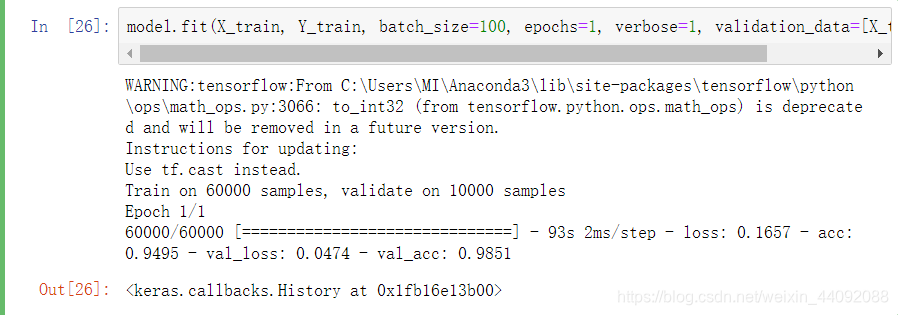
model.fit(X_train, Y_train, batch_size=100, epochs=1, verbose=1, validation_data=[X_test, Y_test])
批处理训练,数据分成 100 份,只训练 1遍 (epochs 为迭代的次数),verbose 是什么还不清楚。。。
咆哮吧,电风扇!
输入图片进行预测
先查看一下测试集 第 3 张图片:(这张图片是它见过了的)
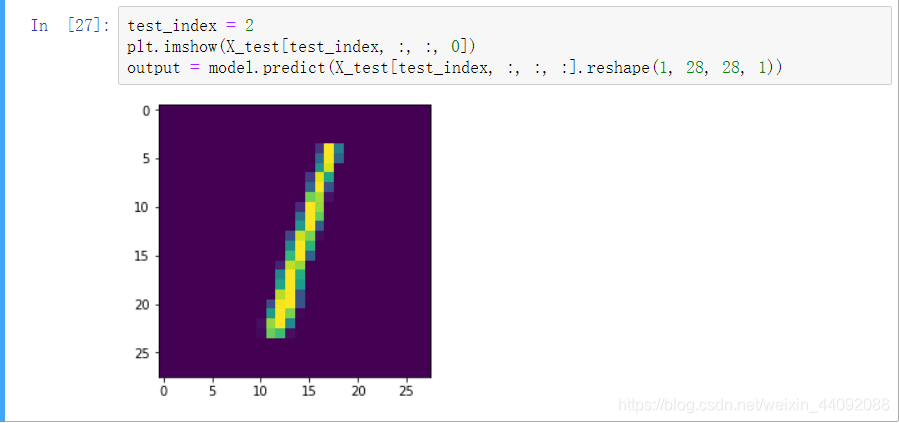
打印输出,预测结果为数字 1,和数据标签是一致的

output 是一个列表,记录了每个分类结果的可能性,我们需要手动提取可能最大的结果作为我么最后的预测结果哦。
这里 np.round() 功能是保留几位小数,第一个参数是输入数据,第二个参数是保留几位小数,默认为 1 位
上面的 .reshape(1, 28, 28, 1) 是必须的,因为其它方式都报错了。。。
(1)


(2)


我的理解,像最后一个参数,取 0,也就是只有一层的话,那么就被认为没有这个维度 (见(1)),只有取所有的,用符号“:”,才会被认为有这个维度,但好像在我看来都是一样的。
所以第一个参数,只用了一个数字,也被认为没有这个维度才会报错。
这样也应证了之前为什么显示图片信息时,最后一个参数用符号“:”取所有的会报错,因为这样会被认为相比图片多了一个维度。
模型的存储
主要是存取训练得到的一系列参数:
model.save("model/My_Alexnet_mnist.h5")
# 这里我之前手动创建了文件夹 model, 如果没有的话,应该会报文件不存在的错
保存在程序文件主目录下 model 文件夹里的 .h5 文件中
模型的载入
from keras.models import load_model
model = load_model("model/My_Alexnet_mnist.h5")
原来的模型又回来啦!
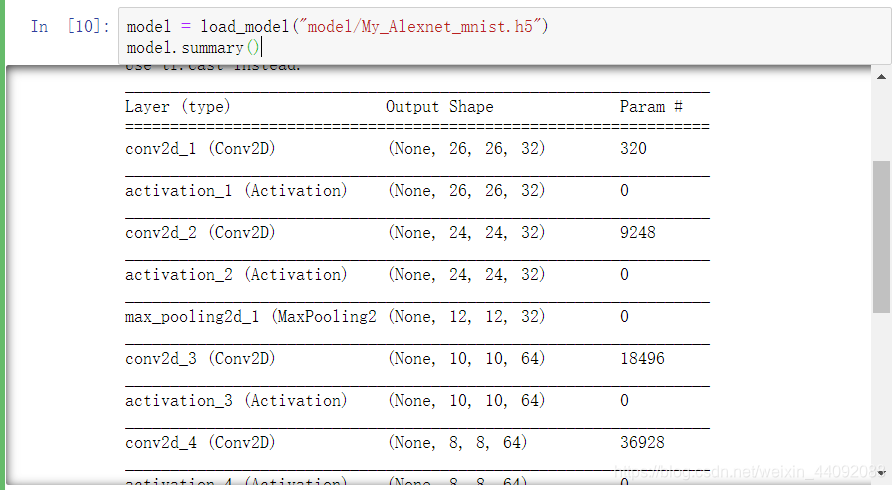
以后就不用担心电脑关闭后要再跑一遍啦!
完整源代码
无不必要输出;
# 完整版
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D
#from keras import backend as K
# 手写数据集读入
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# 把输入数据整理成模型可以接受的格式
X_train = X_train.reshape(60000, 28, 28, 1)
X_test = X_test.reshape(10000, 28, 28, 1)
# 进行归一化处理
X_train = X_train / 255
X_test = X_test / 255
# 对于输出进行 one-hot-codeing
Y_train = keras.utils.to_categorical(Y_train, 10)
Y_test = keras.utils.to_categorical(Y_test, 10)
# 搭建模型
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten()) # 展开成一维
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(10, activation="softmax"))
# 定义模型的优化器
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
# 训练模型
model.fit(X_train, Y_train, batch_size=100, epochs=1, verbose=1, validation_data=[X_test, Y_test])
# 模型预测
test_index = 2
plt.imshow(X_test[test_index, :, :, 0])
output = model.predict(X_test[test_index, :, :, :].reshape(1, 28, 28, 1))
print("predicted output: ", np.round(output))
print("the label is: ", Y_test[test_index])
# 模型的存储
model.save("model/My_Alexnet_mnist.h5")
# 载入训练完成的模型
# from keras.models import load_model
# model = load_model("model/My_Alexnet_mnist.h5")
model.summary()