介绍
简而言之,词向量技术是将词转化成为稠密向量,并且对于相似的词,其对应的词向量也相近。
在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。
生成词向量:
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来定义word representation。
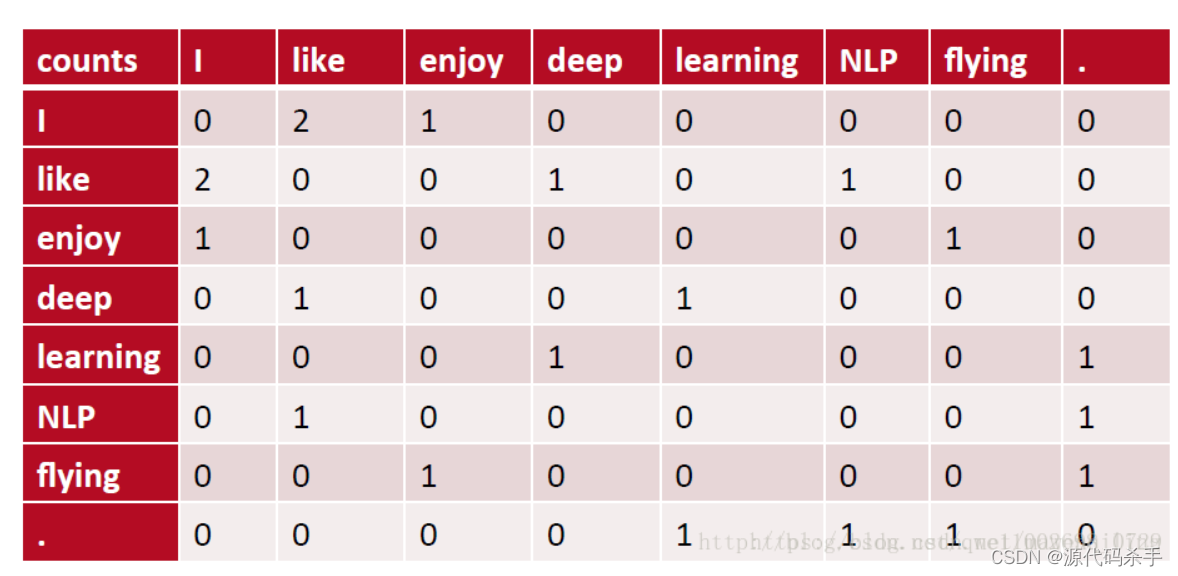
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则其共现矩阵如下:计算与关键词前后关联的相同词的数据量,例如like前后有deep\I\NLP。
矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
既然基于co-occurrence矩阵得到的离散词向量存在着高维和稀疏性的问
题,一个自然而然的解决思路是对原始词向量进行降维,从而得到一个稠密的连续词向量。
进行SVD分解,计算方法参考(https://blog.csdn.net/qq_56780627/article/de