模仿英文词向量,样本是我随便在网上下的小说,经过测试中文的速度比英文慢很多。。。主要时间消耗在data,dictionary的生成那里,所以把程序分成两个部分,一个是完成data,dictionary的生成然后保存为文件,另一个直接读取然后训练。
tensorflow系列代码仓库:https://github.com/joliph/
字典生成:
import jieba
import re
import collections
import os
filename="G:/txtforchinese.txt"
vocabulary_size = 10000
def getfiletxt():
if not os.path.exists(filename):
print("can not find "+filename)
return
data=list()
with open(filename,encoding='UTF-8') as f:
temp=f.read()
words = re.sub("[\s+’!“”\"#$%&\'(())*,,\-.。·/::;;《》、<=>?@[\\]【】^_`{|}…~]+","", temp)
words_split=jieba.cut(words)
for i,word in enumerate(words_split):
data.append(word)
return data
def build_dataset(words):
count = [['Unknow', 0]]
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
dictionary=dict()
for word,num in count:
dictionary[word]=len(dictionary)
data=list()
for word in words:
if word in dictionary:
index=dictionary[word]
else:
index=0
count[0][1] += 1
data.append(index)
reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data,count,dictionary,reversed_dictionary
if __name__ == "__main__":
words=getfiletxt()
data, count, dictionary, reversed_dictionary = build_dataset(words)
del words
with open("G:/data.txt",'w') as f1:
f1.write(str(data))
f1.close()
print("data list has been written")
with open("G:/count.txt",'w') as f2:
f2.write(str(count))
f2.close()
print("count list has been written")
with open("G:/dictionary.txt",'w') as f3:
f3.write(str(dictionary))
f3.close()
print("dictionary has been written")
with open("G:/reversed_dictionary.txt",'w') as f4:
f4.write(str(reversed_dictionary))
f4.close()
print("reversed_dictionary has been written")训练代码
import collections
import math
import random
import numpy as np
import tensorflow as tf
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
vocabulary_size = 10000
data_index = 0
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window,valid_size,replace=False)
num_sampled = 64
num_steps = 100001
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer=collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index+1)%len(data)
for i in range(batch_size // num_skips):
target = skip_window
targets_to_avoid = [skip_window]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0,span-1)
targets_to_avoid.append(target)
batch[i*num_skips+j] = buffer[skip_window]
labels[i*num_skips+j,0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index+1)%len(data)
return batch,labels
def plot_with_labels(low_dim_embs,labels,filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels),"More labels than embeddings"
plt.figure(figsize=(18,18))
for i,label in enumerate(labels):
x,y=low_dim_embs[i,:]
plt.scatter(x,y)
plt.annotate(label,xy=(x,y),xytext=(5,2),textcoords='offset points',ha='right',va='bottom')
plt.savefig(filename)
plt.show()
if __name__ == "__main__":
with open("G:/data.txt",'r') as f1:
data=eval(f1.read())
f1.close()
with open("G:/count.txt",'r') as f2:
count = eval(f2.read())
f2.close()
with open("G:/dictionary.txt",'r') as f3:
dictionary = eval(f3.read())
f3.close()
with open("G:/reversed_dictionary.txt",'r') as f4:
reversed_dictionary = eval(f4.read())
f4.close()
print("数据已加载")
batch,labels = generate_batch(batch_size = 8,num_skips = 2,skip_window = 1)
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32,shape=[batch_size])
train_labels = tf.placeholder(tf.int32,shape=[batch_size,1])
valid_dataset = tf.constant(valid_examples,dtype=tf.int32)
with tf.device('/gpu:0'):
embeddings = tf.Variable(tf.random_uniform([vocabulary_size,embedding_size],-1.0,1.0))
embed=tf.nn.embedding_lookup(embeddings,train_inputs)
nce_weights=tf.Variable(tf.truncated_normal([vocabulary_size,embedding_size],stddev=1.0/math.sqrt(embedding_size)))
nce_biases=tf.Variable(tf.zeros([vocabulary_size]))
loss=tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
optimizer=tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm=tf.sqrt(tf.reduce_sum(tf.square(embeddings),1,keep_dims=True))
transpose_normalized_embeddings=normalized_embeddings=embeddings / norm
valid_embeddings=tf.nn.embedding_lookup(normalized_embeddings,valid_dataset) #valid_embeddings [16,128]
similarity=tf.matmul(valid_embeddings,tf.transpose(transpose_normalized_embeddings)) #similarity [16,50000]
init=tf.global_variables_initializer()
with tf.Session(graph=graph) as session:
init.run()
print("Intialized variables")
average_loss=0
for step in range(num_steps):
batch_inputs,batch_labels=generate_batch(batch_size,num_skips,skip_window)
feed_dict={train_inputs:batch_inputs,train_labels:batch_labels}
_,loss_val=session.run([optimizer,loss],feed_dict=feed_dict)
average_loss+=loss_val
if step % 2000 == 0:
average_loss /= 2000
print("Average loss at step ",step,": ",average_loss)
average_loss = 0
final_embeddings=normalized_embeddings.eval()
tsne=TSNE(perplexity=30,n_components=2,init='pca',n_iter=5000)
plot_only=100
low_dim_embs=tsne.fit_transform(final_embeddings[:plot_only,:])
labels=[reversed_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs,labels)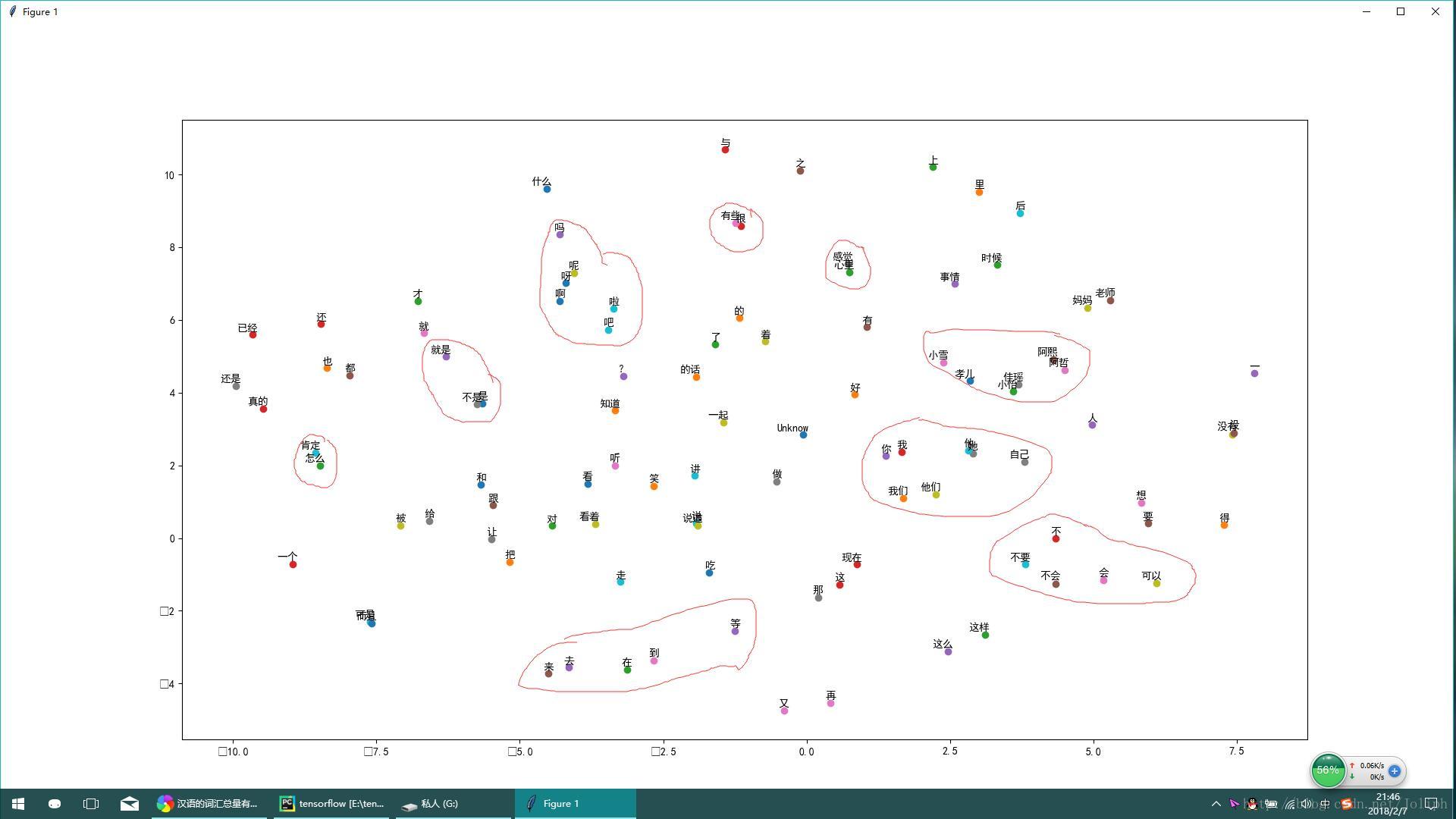
还行吧,中文确实比英文杂乱一点,一些没什么具体意义的助词比较多