分库分表要考虑的前提:
- 单机存储容量。数据量是否在单机存储中碰到瓶颈。
- 单表存储超过1000万,访问性能非常低 。数据量大了后B+数层级上升,查询数据时节点遍历的次数增多,效率下降。
- 连接数、处理能力。我们的用户量达到一定程度时,特定时间的并发量又成了一个大问题,在一个高并发的网站中秒级数十万的并发量都是很正常的。在普通的单机数据库中秒级千次的操作问题都很大。一台mysql机器,能支持1000qps就已经快到极限了。
垂直拆库:
比如电商业务中,用户、订单、商品都是一个库中,那么可以拆分到多个库中存储。
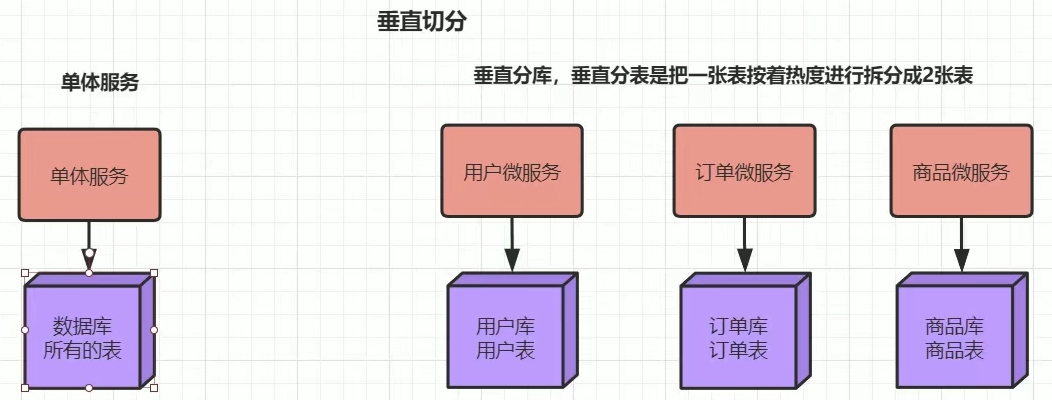
垂直拆表:
比如有商品的表,里面字段很多,比如商品名称、描述、特点。我们查询的时候正常只要名称,看详情才会需要描述、特定等。我们可以按照字段查询的热度进行拆分,拆分为若干张表。
水平拆库拆表:
两个库都存放同一类数据,只是分开到两个库存放,一个库存放数据量有些大。比如下图。两个库都放user表数据,但是存的数据是分开的,a、b两个用户在不同的库里。具体同一类数据怎么拆分,就看实际选用的算法。
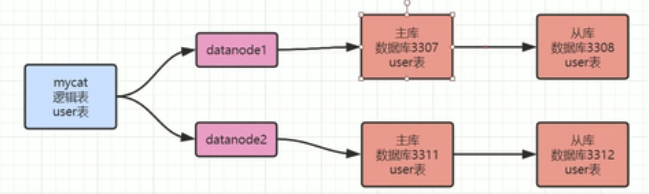
拆表代码的问题:
分库分表导致问题
1、分页查询问题
分库并行查询时,若需要分页查询则将出现悲剧,每个库返回的结果集本身是无序的,无法确定应该如何返回数据给用户。目前像MyCat这类中间件要求分页查询时必须带上ORDER BY 字段,好使得多库查询结果全部出来后,再在内存汇总根据排序字段单独进行排序,最后返回最小结果集。可以想象,当查询的总结果集过大时,这一排序过程对资源和时间的消耗相当可观。
2、事务一致性问题
当我们需要更新的内容同时分布在不同库时,不可避免会带来跨库事务问题,在JavaEE体系下使用分布式事务进行协调解决,但XA事务目前也并非完全安全,在最后确认提交这一步若某个库失败时,并不能确保所有库都能成功roolback。目前针对此中情况尚无简单的方案,需要采用日志分析、事后补偿的方式来解决,以达到互联网类系统宣城的“最终一致性”。
3、主键避重问题
由于表同时存在于多个数据库内,主键值我们平时常用的自增序列将无用武之地,因此需要单独设计全局主键,以避免跨库主键重复问题。
uuid可以解决,但是排序又是问题,所以不推荐用uuid。
4、公共表问题
实际应用中大量的参数、产品表等都数据量较小,而且属于高频联合查询的依赖表,这类表的所有数据都需要同时出现在各个库中。
一种办法就是我们对公共表的所有更新操作都同时发送到所有分库执行,然后指定一个主库,若主库成功我们就认为操作成功,然后在定期对其它库的数据进行同步操作。
mycat配置说明
实验准备:
机器上安装docker,通过docker启动4个mysql服务,他们的端口不同。两台master之间没有关系,是两组一主一从的mysql集群。

mycat架构:
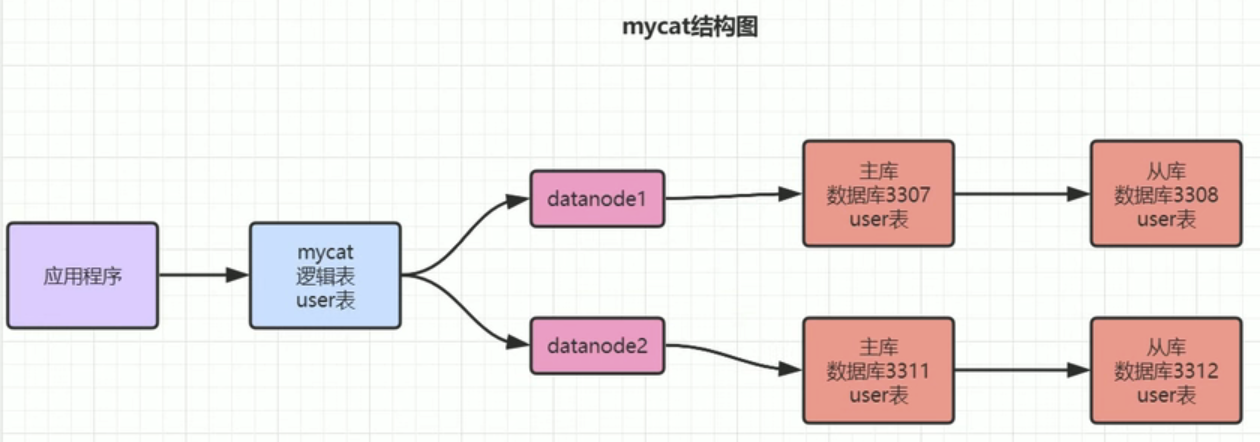
逻辑表
- 逻辑表是配置schema中的table标签。name就是逻辑表的名称,是mycat中我们创建的表名称,一般就是跟实际数据库中的表对应。type有多个值,这里用了global。数据节点就是dn1,和dn2,下面会说到数据节点配置。
- type=global,其实就是往t_user表操作的时候,操作会发到两个节点,一般就是字典表要同步都写,字典表在多个库上要一致,这样需要字典表的查询也不用跨库了。
- 下图表示,我们通过mycat往t_user逻辑表写数据时,它会同时写到dn1和dn2两个节点。

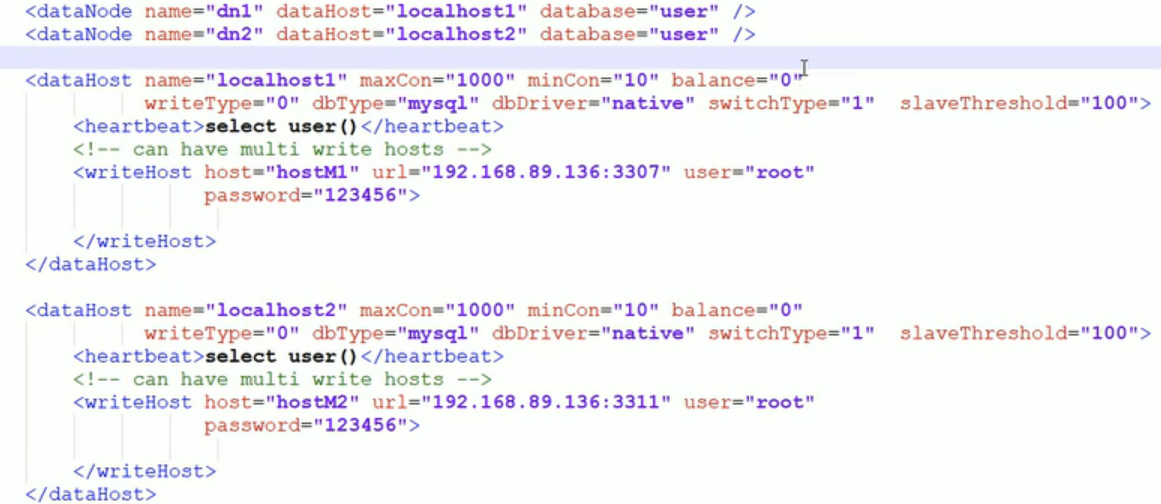
节点和主机关联
- datanode是节点,可以理解为路由,当我们写数据,请求发到mycat,mycat根据节点配置,写到后面真正的数据库中。
- 在配置文件schema.xml中,配置dataNode和dataHost标签,就能维护节点和其后面实际主机的关系。
- dataNode标签说明: name是节点名称,dataHost是主机配置的name对应下面dataHost标签,database对应数据库名称。
- 下图,有dn1、dn2两个节点,dn1后面关联到localhost1主机,dn2后面关联到localhost2主机,dn1和dn2连接的都是对应主机上面的user数据库。
mycat数据分片
mycat数据分片的方式,枚举分片、取模分片、按日期分片等。
- 枚举分配: 比如表中性别sex字段是枚举,按照其值进行分片。
- 取模分片: 数字计算后根据值分片。
- 日期: 比如按月。
按照取模分片的配置例子
修改rule.xml, 两个地方,一个是我们按照哪个字段取模,一个是取模的计数,要改为数据库的数量,我们是写到2个库。
下面是默认的按照id取模

下面改为取模计数2.

修改schema.xml, rule采用mod-long,代表取模的方式。

查询乱序的解决
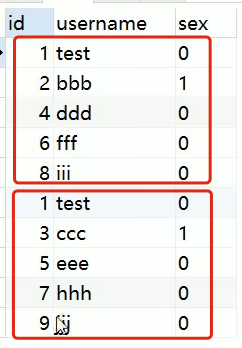
查询的时候,因为是从两个库查的,会乱序。如下图,
select * from t_user;
要解决这个问题,只要加上order by就可以,mymat会在内存中进行排序。
select * from t_user order by id limit 6;
z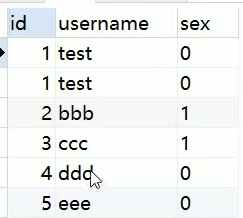
主键重复的问题解决
两个数据库分库,里面都有user表,如果主键id都是自增的,那么会出现两个表的主键重复。
解决办法
- 程序自己维护,可以很多算法,比如雪花算法生成id。
- mycat提供序列的方式。
- 在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,MyCat提供了全局sequence,并且提供了包含本地配置和数据库配置等多种实现方式。指定使用MyCat全局序列的类型。0为本地文件方式,1 为数据库方式,2为时间戳序列方式。3为分布式ZK ID生成器。4为ZK递增id生成。
mycat配置序列 - 数据库方式
在数据库即某一个master上面,配置一个函数。再配置节点让其对应这个master库并知道是哪个函数。