版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_33656602/article/details/82766750
文章目录
MySQL 分库分表场景
针对频繁写更新和读操作较少的数据特点,如日志,聊天信息等 可用 MySQL 5.7 的分区特性来处理这类数据。
1. 用户类的数据
- 用户认证信息
- 用户基本资料
- 用户好友关系
2. 电商业务
- 商品信息
- 订单信息
- 商品配送信息
3. 将功能拆分成更小的功能
商城内所有数据存储在一个DB/集群中, proxy之下挂载多个 DB,则可能出现某个节点挂掉从而影响全局,可将一些功能垂直拆分成更小的功能,例如可将订单表拆分成 买家订单表和卖家订单表,即将数据从不同角度冗余存储两份。
MySQL 为什么要分库分表
做分库分表前要考虑是否到了必须分的时刻了,使用 MySQL 5.7 的分区功能能不能解决此类问题
- 单表行数太多出现性能捌点
单表行数在1 kw~1.5 kw左右进行拆分, 控制 btree 高度 <=3 - 单表物理太大,不方便管理
- 单实例超过1T,不方便管理
- 单表并发太多,锁争用明显
- 实例并发太高,锁争用明显
MySQL 数据库拆分方法
垂直拆分
在考虑拆分数据库时,一般情况下,应先考虑垂直拆分。
垂直 含义:
拆分出来的库表结构之间是互相独立的,没有业务上的来呢西。
数据库垂直拆分依赖规则
- 如果一个实例中存储着多个业务的数据,而每个业务直接关联性不大,则可将每个业务拆分为单独的实例/库/表
- 如果在一个实例上有多个数据库,那么从分摊读写压力的角度来考虑,则可以将每个数据库拆分到单独的实例上。
- 如果在一个库里面有多张表,则可将每张表拆分到不同的实例上
- 如果有一张具有很多字段的表,每个字段都有不同的含义, 例如 user 表里有姓名,生日,地址等个人信息,那么当该表行记录量太大时,就可以将每个字段独立出来拆分为一张新表。例如 user_birth 表,可以只有两个字段:user_id, user_birthday。
水平拆分
常见的分库分表方案
基于Hash
通过对 user_id 取模的方式,将一张表分成 M 份。
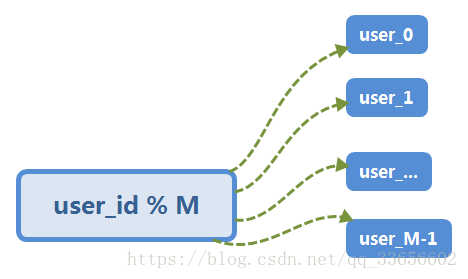
select * from user_M where userid=N
对1张表进行分库分表
- 场景
想将1张表拆分成10个库,再在每个库中将此表拆分M份。
- 思路
首先对 user_id 向左或向右移位再取模的方式来分库,然后对 user_id 取模的方式来分表。
基于 hash 拆分后,实际存储超出预先估计
单
不适应场景
日志类数据不适合使用基于 Hash 的方式来拆分,建议用 rang 方式来拆分。
基于 Range
先对 user_id 取模分库,按时间区间分表,如果月表数据还是过大或并发写满等情况,则对月表进行二次拆分。可拆分上中旬三张表或日表(日表跨日查询表太多),从而减少单表上的压力。
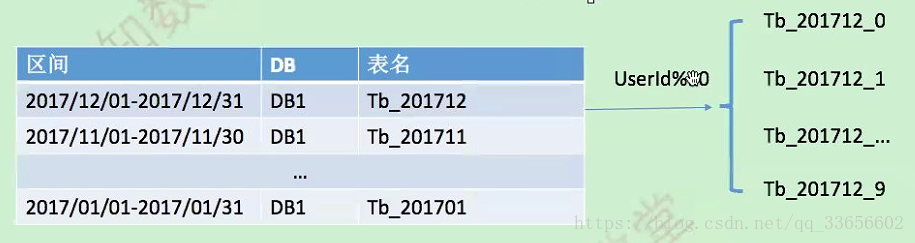
select ...
from tb_M_N
where user_id=N
and addtime between x and y;
优点
便于删除历史数据
代码层处理分库分表
SaveMessage(user_id, msgctx, addtime)
#分库
userid % 16 = N ->DB_N
#分表
addtime(range) ->tb_2018_08_X{0,1,2}
GetMessage(user_id, touser_id, btime, etime)
基于 List 拆分
针对 SVIP(如微博明星,淘宝卖家) 服务场景
- VipSet -> Userid int {10001, 10002, … 99999} -> DB1 -> tb_X
- Select … from tb_X where user_id = N;
Range+Hash复合模型
- Userid [1-2000W] -> DB_0
- Userid%10 -> tb_N
- Userid [2000W-unlimit] -> DB_1
- Userid%10 -> tb_N
- 一致性Hash + Range
- Userid % 4096=0 - 4095
- [0-128) -> DB0_0
- [128-256)->DB0_1
- …
Range+Hash拆分步骤
单节点扩容
1. 为需拆分实例 DB0 建立两个从库
2. 将数据拷贝到 DB0_0 和 DB0_1上
3. 确认数据一致时,修正代码层的拆分规则,将所有的写入划分到 DB0_0 和 DB0_1上,下线 DB_0
4. DB0_0 和 DB0_1 两个实例都有一半的冗余数据,在业务低峰期清除冗余数据
大小表拆分(金字塔设计)
大量内容写入场景,如 twiter 状态短语,基于 userid + 日期拆分
- (Userid >num)%100 -> DB_N (0<=N<=99)
Userid 左右移 N 位再取模来分库 - Userid%10 -> tb_n (0<=n<=9)
用户ID对预分表数取余- tb_20180821_m
天表,第二天将昨天的天表数据删除(尽量做到在日表中能查询到想要的数据) - tb_2018082_m
10天表(中下旬) - tb_201808_m
月表(最终保留的表,当月访问上月数据就要访问上月月表)
- tb_20180821_m
基于多种认证体系系统怎么分?
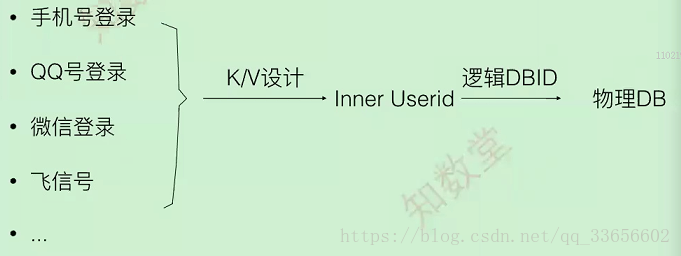
更复杂的应用
- 超级大 V,超级用户,超级VIP 怎么处理?
If Userid in VipSet { return VipDB;
}else if (id < 2千万){
if (id < 1千万)
return <DB+(id%2);
}else{
return,DB+((id%2)+2);
}
}else if (id <4千万){ return DB+(id%4)
}else{
throw new lllegalArgumentException ("id out of range.id:"+id);
}
-
多IDC架构中如何处理分库分表
-
日志类型数据处理
优秀开源中间件
- sharding-jdbc
- 基于 Proxy 模型:DBLE
分库分表后的二次扩容及缩容实现
- 以库为单位
- 以表为单位
- 以逻辑Set为单位
业界其他优秀方案
- TDSQL
- RadonDB