16 Unsupervised Learning: Auto-encoder
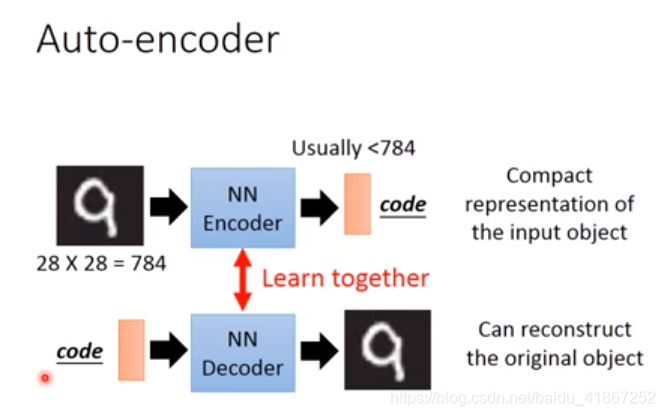
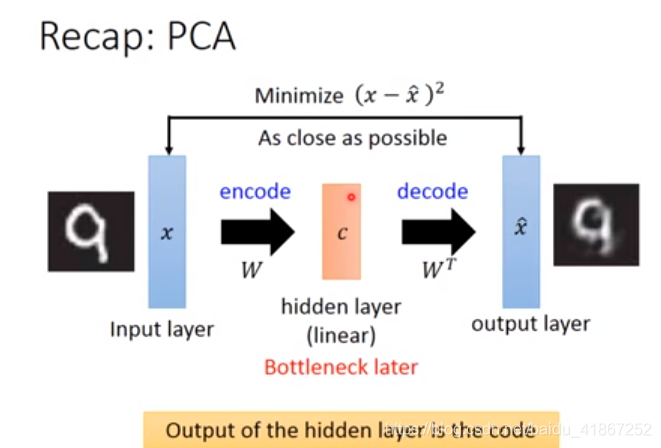
PCA是线性的
encoder 在做降维,本身是一个神经网络。
c的维度特别小,称为瓶颈层
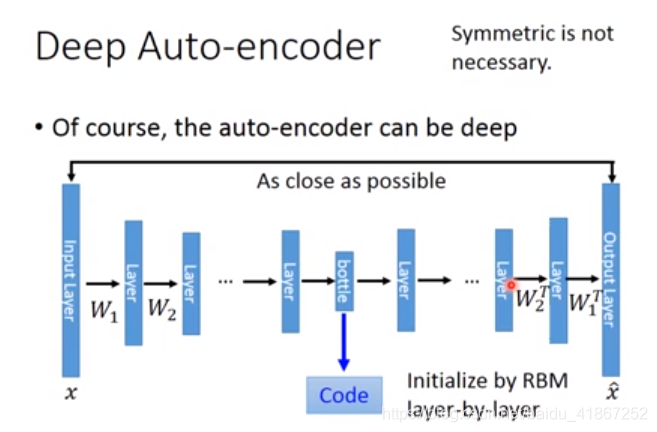
auto-encoder 比 PCA多了几层。W的设置,保持对称,可以减少参数,防止过拟合。但并不是必要。
symmetric 对称的,保持平衡的
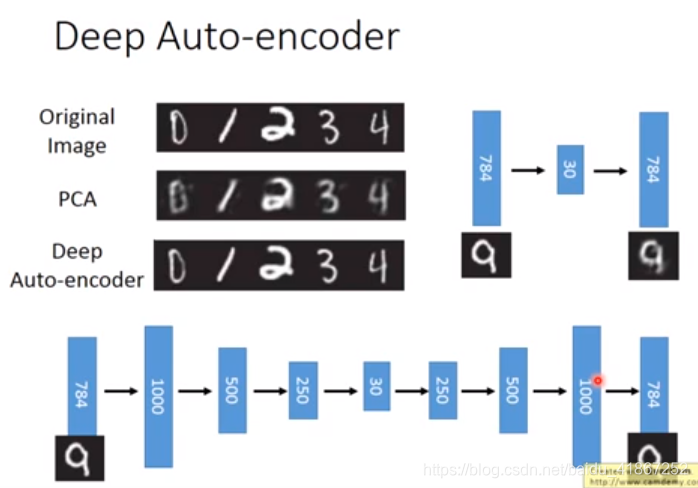
reconstruct 的loss大小并不是重点,直接令输出=输入,loss=0,重要的是code的好坏

每种颜色代表一种数字,可以看出,auto-encoder分的更开

为了auto-encodet做的更好,给input增加噪声,期望
与
接近。
待续
25-26 Recurrent Neural Network
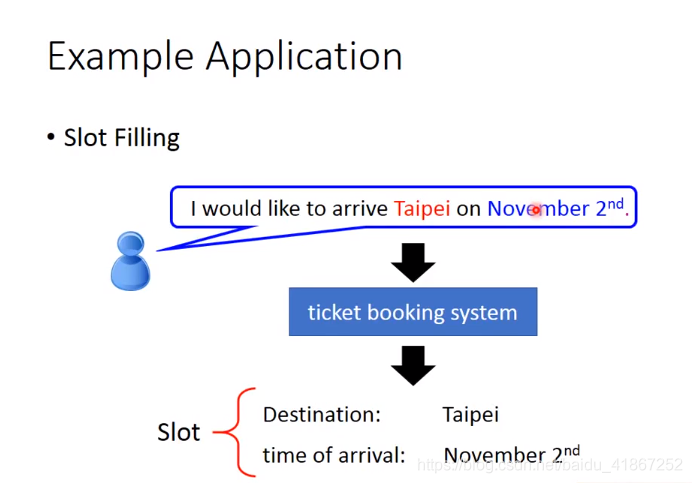

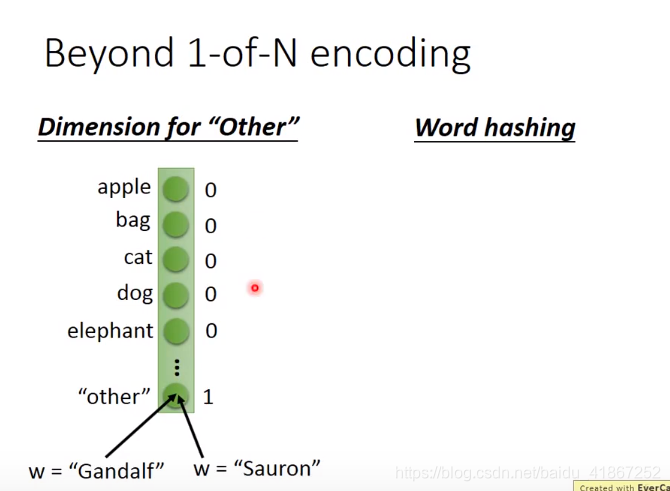
注:lexicon 全部词汇,词汇表
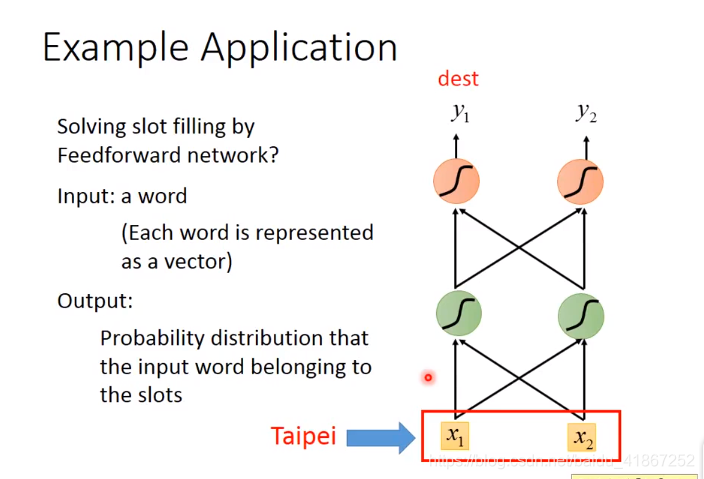

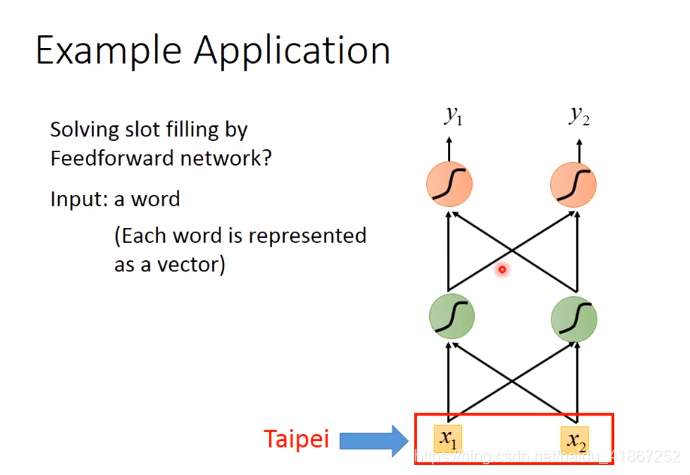
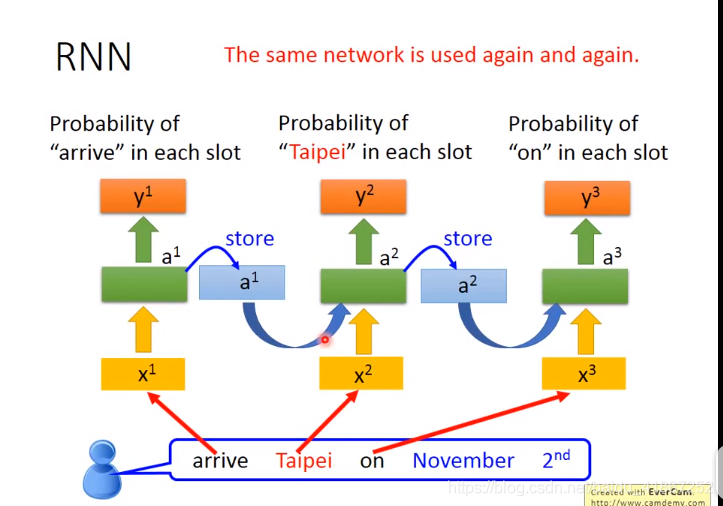
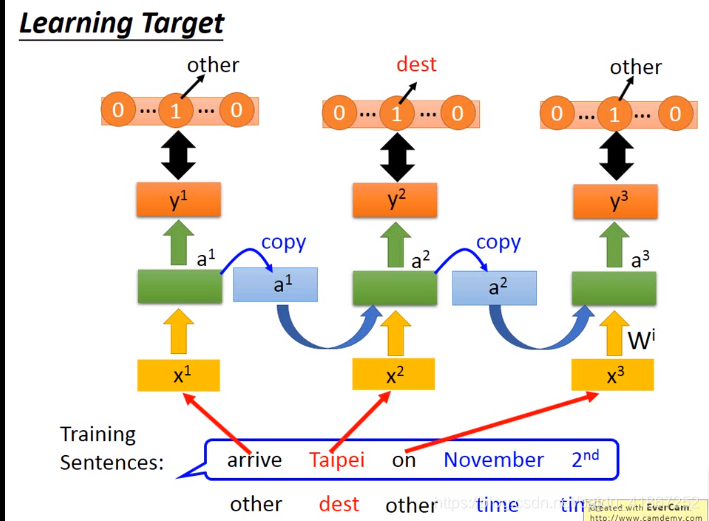
相同的输入要求有不同输出,这需要NN有记忆功能。
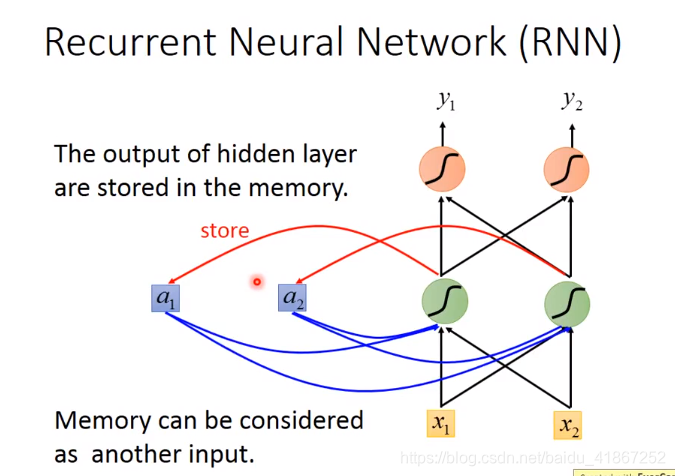
更新记忆:
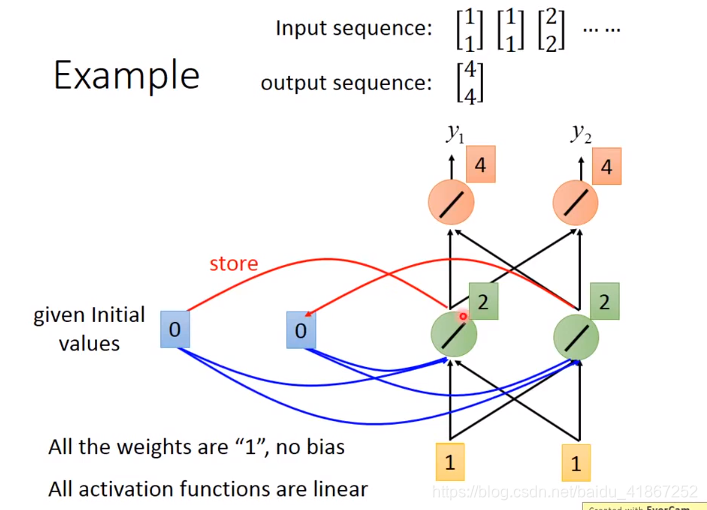
可见输入相同的
,输出不同,
,
,因为存在记忆。
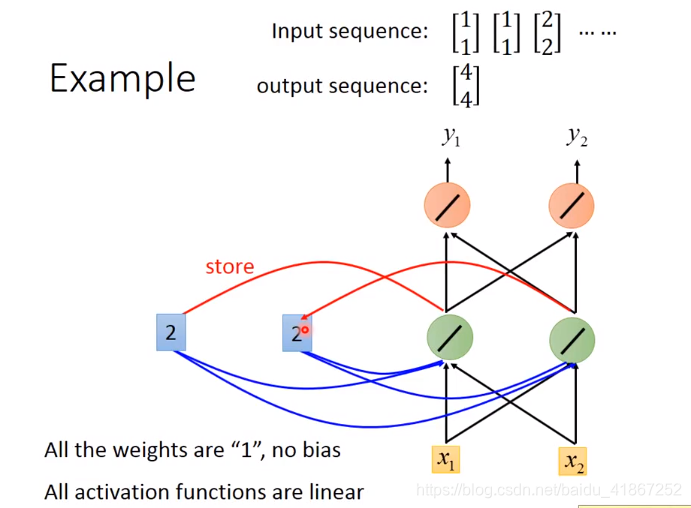
更新记忆:
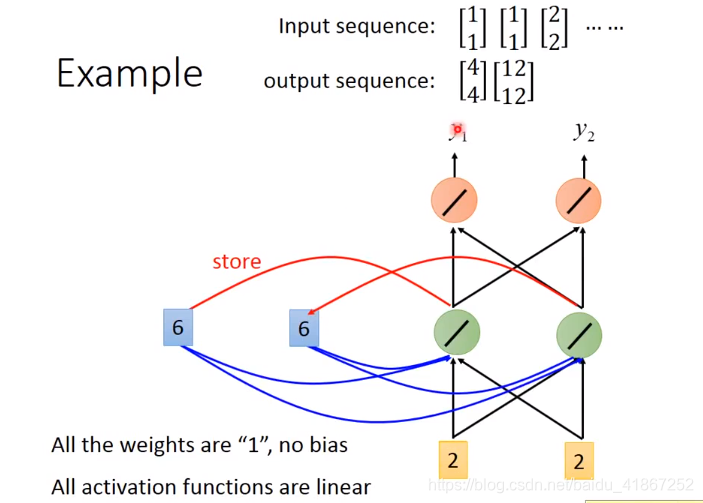

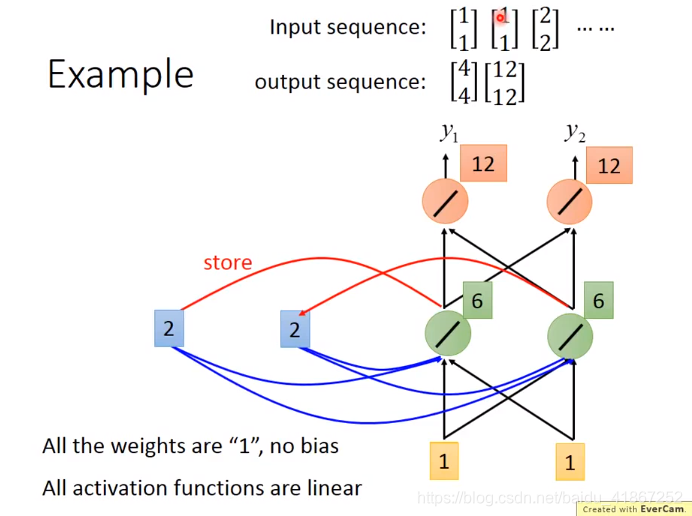
改变序列顺序,影响输出,如先输入
,后输


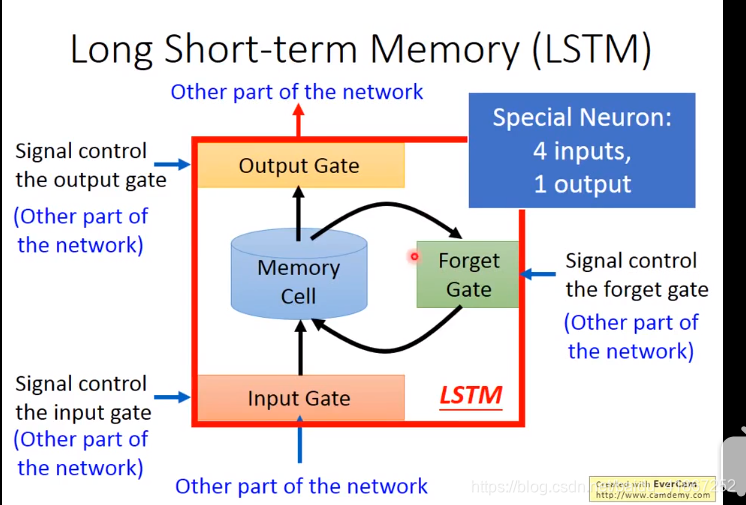
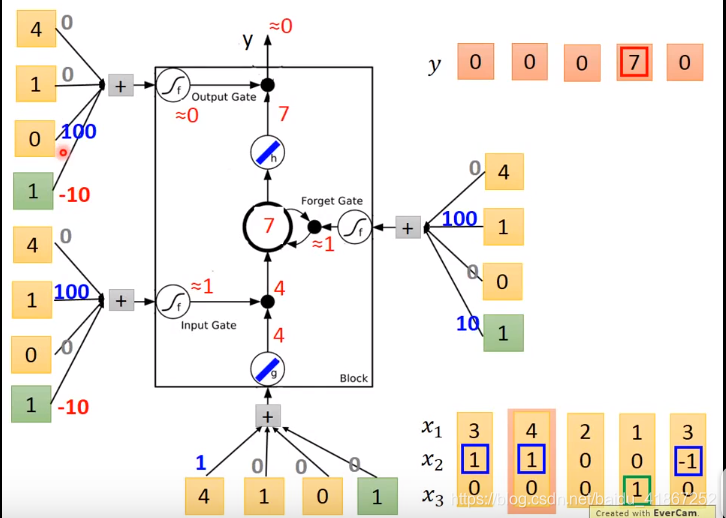
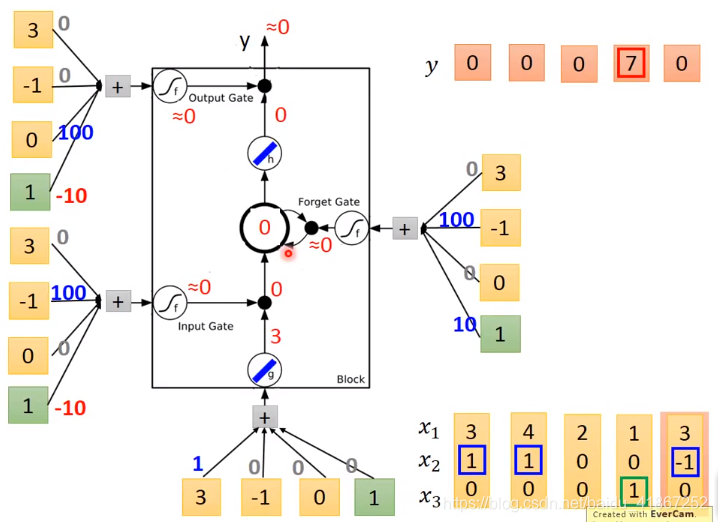
三个门,每个门有控制信号,决定门打开还是关闭,如在输入门中,门关闭外部的信息就无法读入,输出门关闭信息就无法输出,遗忘门决定信息遗忘(用新的信息代替)或者继续保留,这些门的信息可以学习。
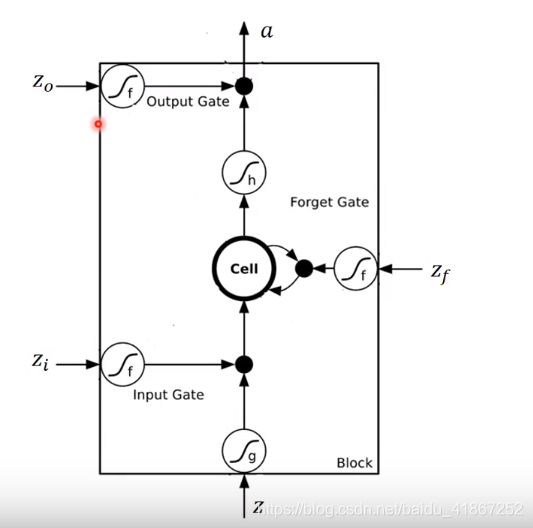
假设cell 的初始值为 c:

各输入门的激活函数一般为sigmoid,那么其输出值为0到1之间的数,为0表示门关闭,1打开
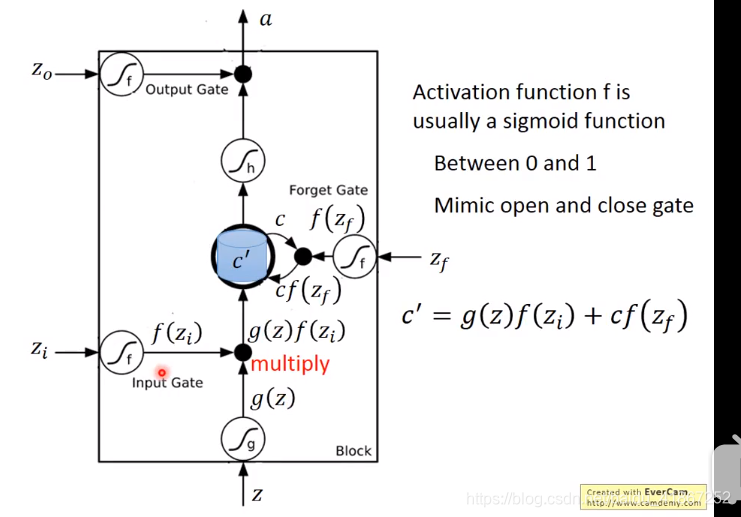
是控制
能否输入的关卡,
,
值可以直接输入;
,表示保留记忆
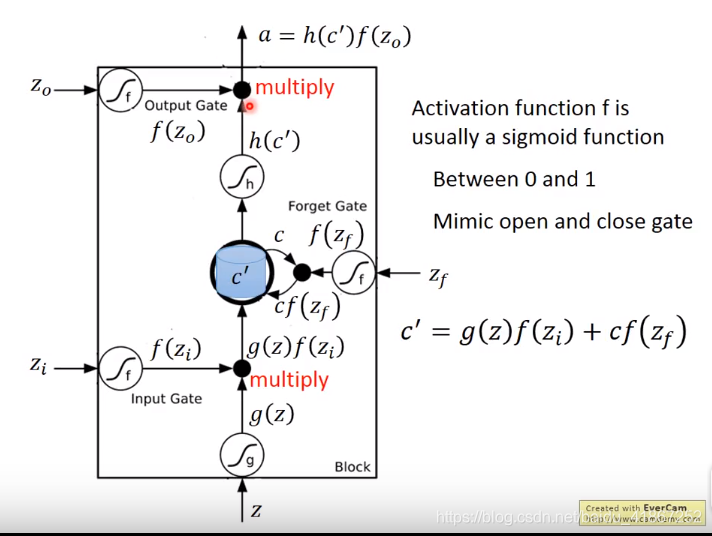
表示信息无法读出

表示记忆值保持不变




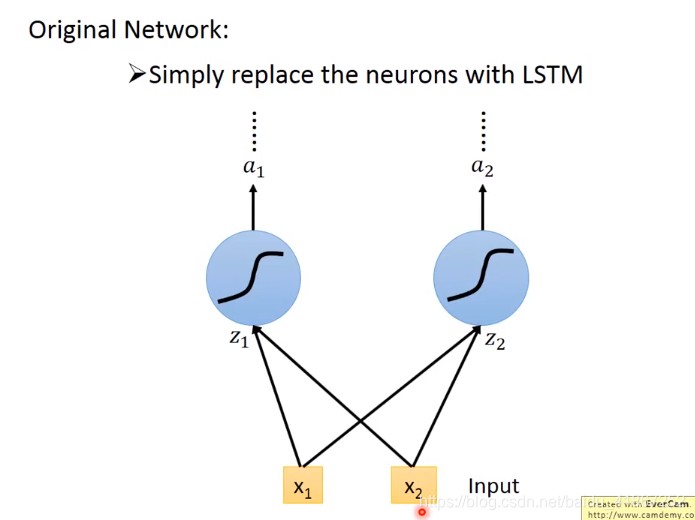
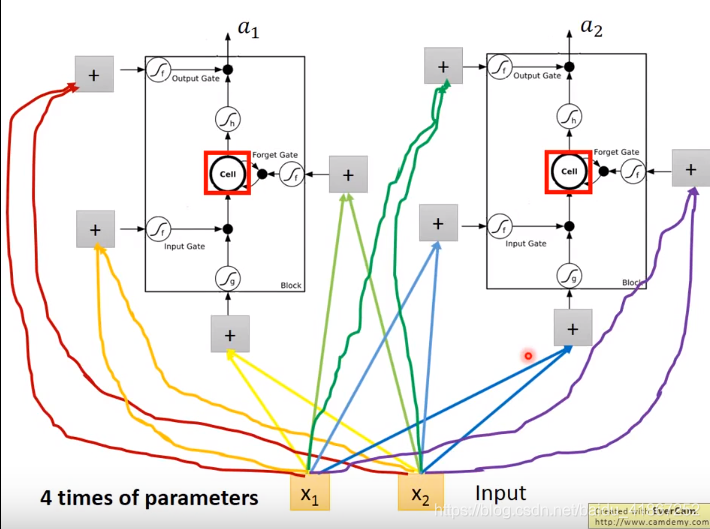


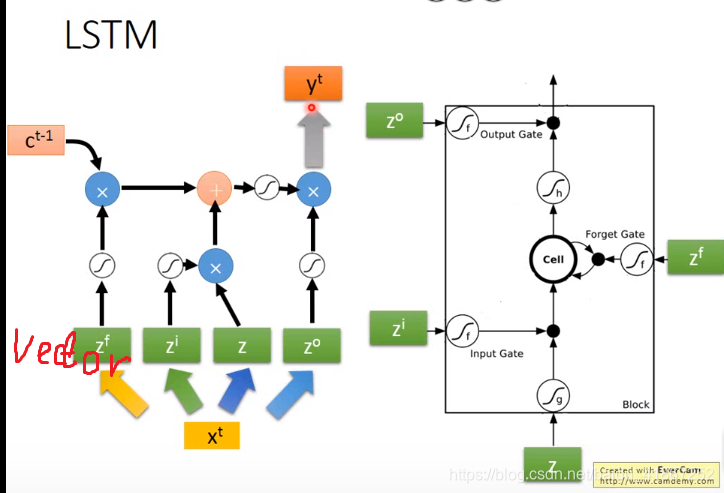
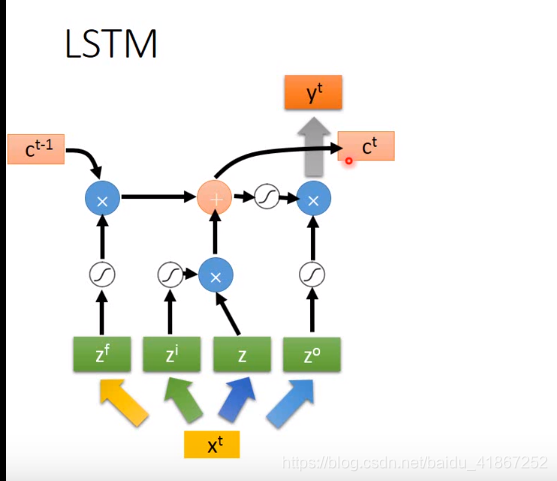
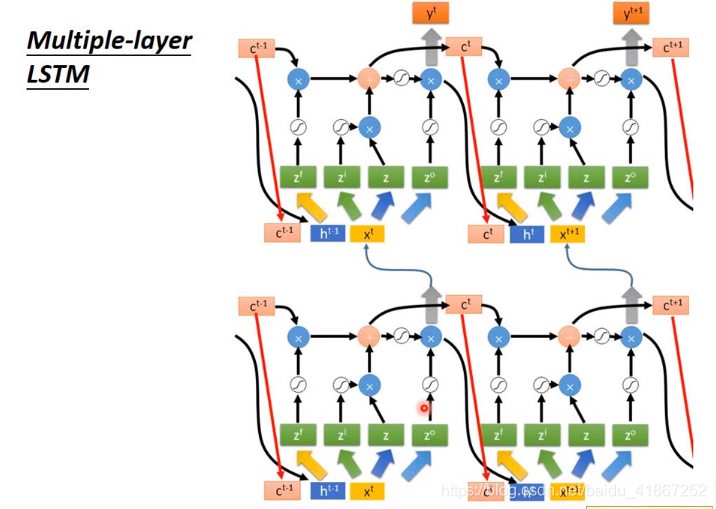
连接更多:
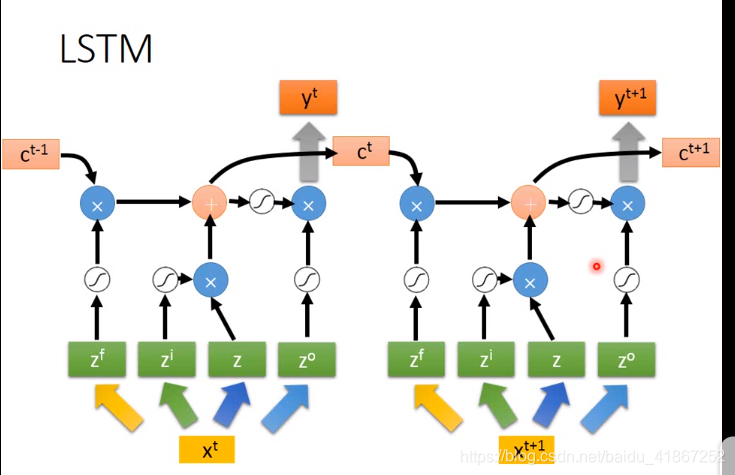
下面是完整形态:

还可以加入窥视孔peephole:
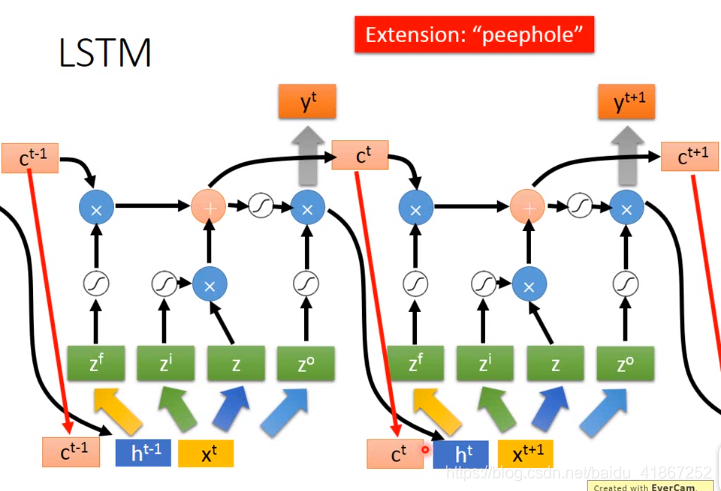

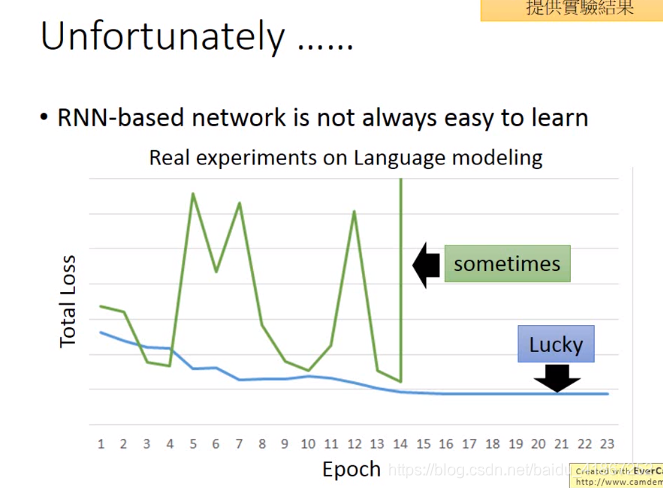
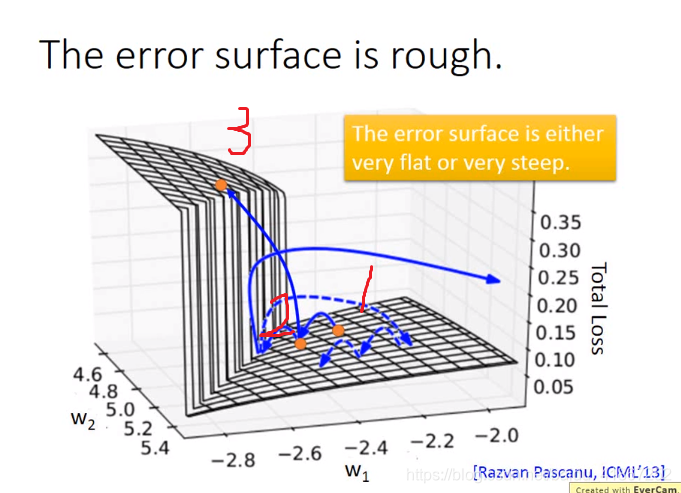
更坏的情况:

梯度爆炸可使用梯度修剪解决
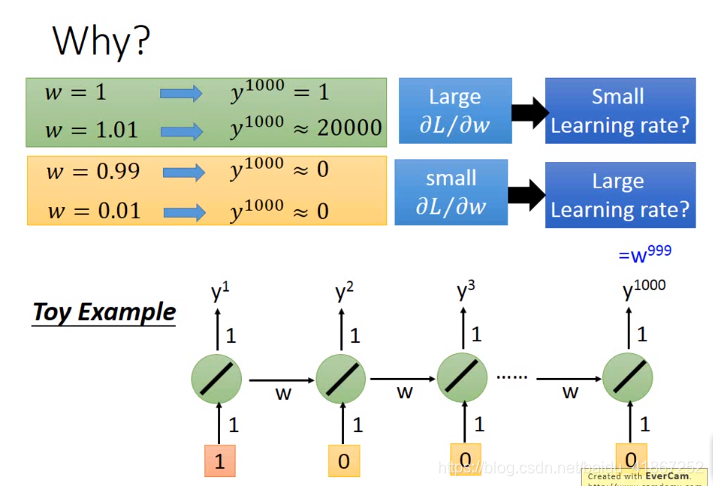
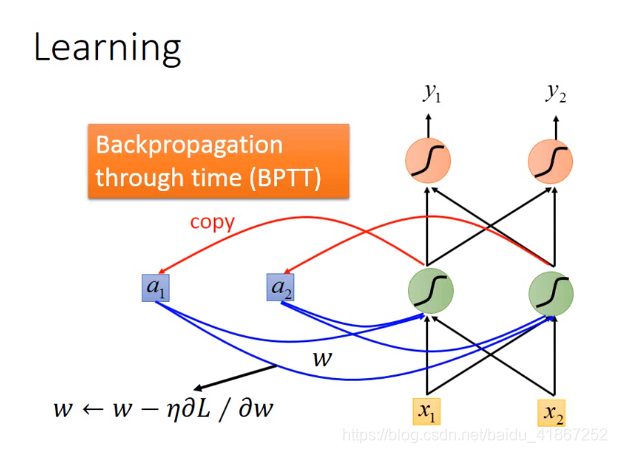
上图说明,RNN不易训练的原因不在于激活函数的选择,而是由于同一结构反复使用
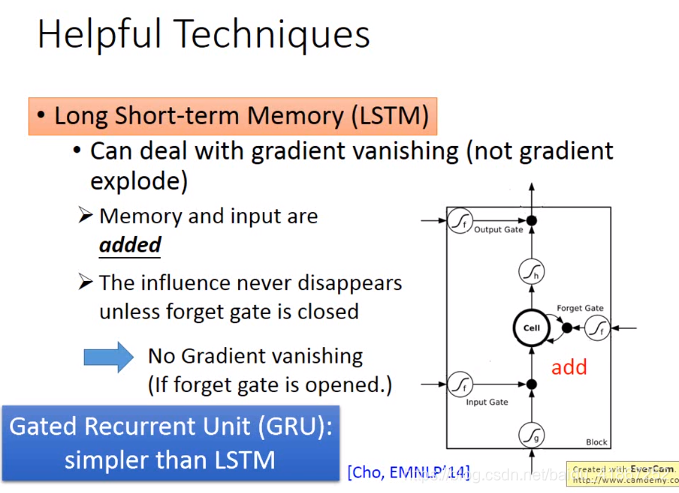
RNN的记忆值每个时间都会被洗掉,而LSTM则保留了上一个记忆,所以不会梯度消失
未完待续。。。
