前言
虽然实验难度写的是easy,但是感觉仅停留在test,如果从理解或者代码实现来说还是有一定难度的。
一、实验背景
对于这次的实验并不像以往的实验那般需要研读paper之类,但是单纯靠 introduction来理解还是有点难度。
- 本次的lab4A在介绍中也提到过了,他与lab3其实比较类似。类似的原因就是如果说lab3是利用raft共识实现一个put/get的简单的存取数据库,那么lab4A其实就是再换一个更真实的业务场景,利用raft进行配置的统一。 也就是将put/get之间的操作,换成query/leave/join/move等操作。
- 总体的架构图:
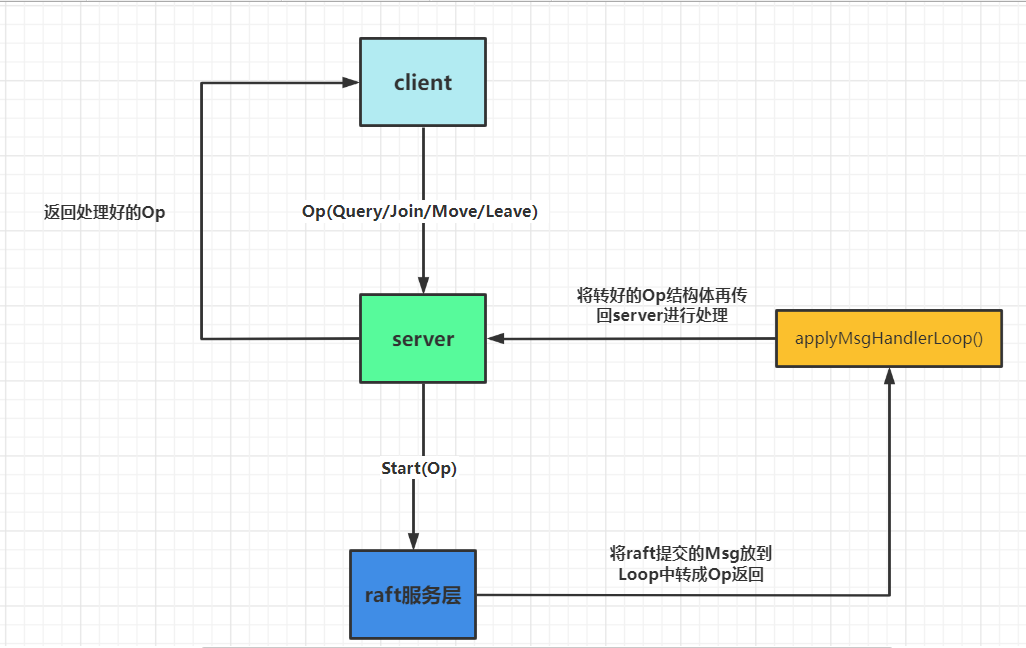
值得一提的是这里并没有去实现快照,因为在lab3B中实现快照是因为在start的时候传入了一个maxSize,超过这个size才需要进行快照,而lab4A中并没有提到,到这里其实都算是比较好理解的。 - 接下来会着重讲下lab4A的配置到底是什么。
首先你会发现在server层有一个config切片:
configs []Config // indexed by config num
它其实存放得就是一系列版本的配置信息,最新的下标对应的最新的配置。
接着点开看一下config的构造:
type Config struct {
Num int // config number
Shards [NShards]int // shard -> gid
Groups map[int][]string // gid -> servers[]
}
可以看出有三个成员:
一个对应的版本的配置号,分片所对应的组信息(实验中的分片为10个),每个组对应的服务器映射名称列表(也就是组信息)。
由此我们其实可以总结出以下的关系:
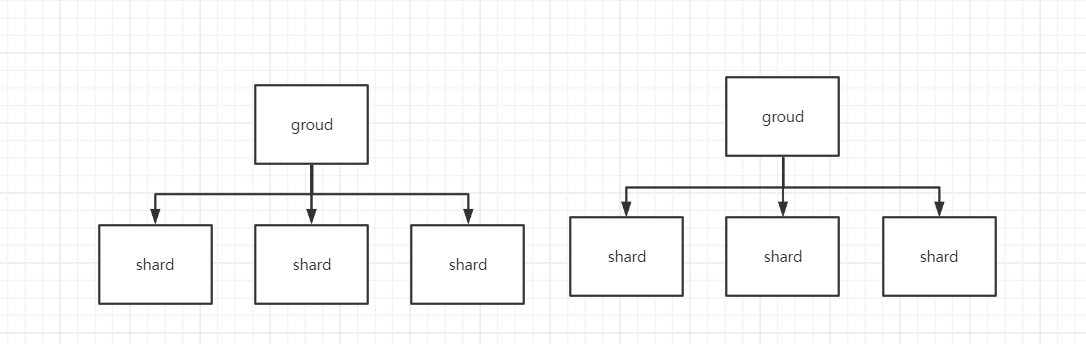
一个分片由一个组进行处理,一对一的关系。而一个组可以用来处理多个分片,也因此加入组只要不是超过分片的数量,加入的组可以使系统的性能达到提升。也就是介绍中提到的:
thus total system throughput (puts and gets per unit time) increases in proportion to the number of groups.
二、RPC
2.1、RPC总体概述
对于各个操作做什么包括怎么实现其实在介绍中也有具体的描述:
- The Join RPC is used by an administrator to add new replica groups. Its argument is a set of mappings from unique, non-zero replica group identifiers (GIDs) to lists of server names.
- The Leave RPC’s argument is a list of GIDs of previously joined groups. The shardctrler should create a new configuration that does not include those groups, and that assigns those groups’ shards to the remaining groups. The new configuration should divide the shards as evenly as possible among the groups, and should move as few shards as possible to achieve that goal.
- The Move RPC’s arguments are a shard number and a GID. The shardctrler should create a new configuration in which the shard is assigned to the group. The purpose of Move is to allow us to test your software. A Join or Leave following a Move will likely un-do the Move, since Join and Leave re-balance.
- The Query RPC’s argument is a configuration number. The shardctrler replies with the configuration that has that number. If the number is -1 or bigger than the biggest known configuration number, the shardctrler should reply with the latest configuration. The result of Query(-1) should reflect every Join, Leave, or Move RPC that the shardctrler finished handling before it received the Query(-1) RPC.
这里简单的做出下翻译解释:
- Join :加入一个新的组 ,创建一个最新的配置,加入新的组后需要重新进行负载均衡。
- Leave: 将给定的一个组进行撤离,并进行负载均衡。
- Move: 为指定的分片,分配指定的组。
- Query: 查询特定的配置版本,如果给定的版本号不存在切片下标中,则直接返回最新配置版本。
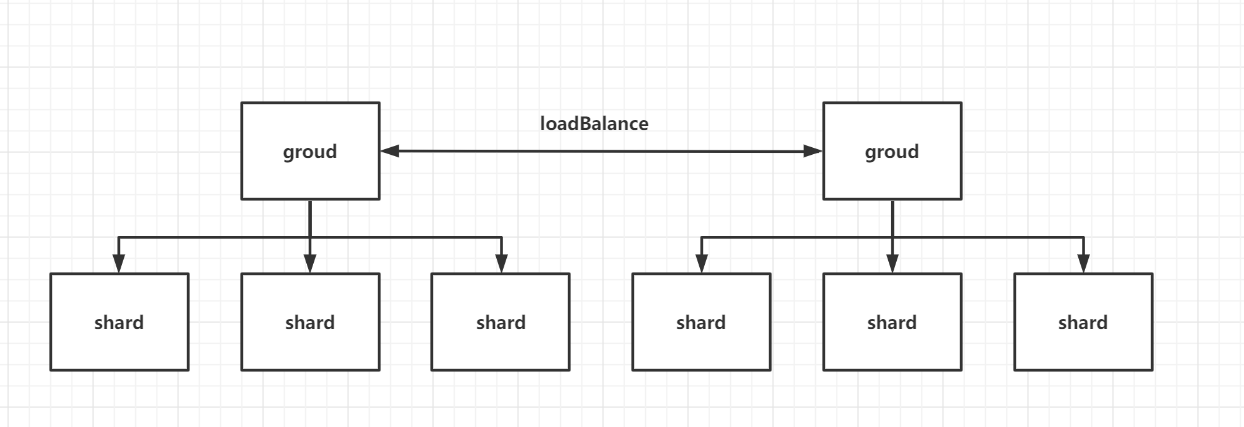
也因此可以看出四个操作,这四个操作可以简单的看成对配置的增删改查。但是这里的可以看出还需要实现负载均衡,也因此上面组与切片的关系可以看成下图:
2.2、RPC实现
也因此理解好4个RPC是做什么的还是很好实现的(照着lab3实现就好):
//The Join RPC is used by an administrator to add new replica groups. Its argument is a set of mappings from unique,
//non-zero replica group identifiers (GIDs) to lists of server names.
// Join参数就是为一个组,一个组对应的就是gid -> lists of server names.
func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// 封装Op传到下层start
op := Op{
OpType: JoinType, SeqId: args.SeqId, ClientId: args.ClientId, JoinServers: args.Servers}
//fmt.Printf("[ ----Server[%v]----] : send a Join,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// 设置超时ticker
timer := time.NewTicker(JoinOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a JoinAsk :%+v,replyOp:+%v\n", sc.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
func (sc *ShardCtrler) Leave(args *LeaveArgs, reply *LeaveReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// 封装Op传到下层start
op := Op{
OpType: LeaveType, SeqId: args.SeqId, ClientId: args.ClientId, LeaveGids: args.GIDs}
//fmt.Printf("[ ----Server[%v]----] : send a Leave,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// 设置超时ticker
timer := time.NewTicker(LeaveOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a GetAsk :%+v,replyOp:+%v\n", kv.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
func (sc *ShardCtrler) Move(args *MoveArgs, reply *MoveReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// 封装Op传到下层start
op := Op{
OpType: MoveType, SeqId: args.SeqId, ClientId: args.ClientId, MoveShard: args.Shard, MoveGid: args.GID}
//fmt.Printf("[ ----Server[%v]----] : send a MoveOp,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// 设置超时ticker
timer := time.NewTicker(MoveOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a GetAsk :%+v,replyOp:+%v\n", sc.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
// Query 相应配置号的配置
// The shardctrler replies with the configuration that has that number. If the number is -1 or bigger than the biggest
// known configuration number, the shardctrler should reply with the latest configuration. The result of Query(-1) should
// reflect every Join, Leave, or Move RPC that the shardctrler finished handling before it received the Query(-1) RPC.
func (sc *ShardCtrler) Query(args *QueryArgs, reply *QueryReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// 封装Op传到下层start
op := Op{
OpType: QueryType, SeqId: args.SeqId, ClientId: args.ClientId, QueryNum: args.Num}
//fmt.Printf("[ ----Server[%v]----] : send a Query,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// 设置超时ticker
timer := time.NewTicker(QueryOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a QueryAsk :%+v,replyOp:+%v\n", sc.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
sc.seqMap[op.ClientId] = op.SeqId
if op.QueryNum == -1 || op.QueryNum >= len(sc.configs) {
reply.Config = sc.configs[len(sc.configs)-1]
} else {
reply.Config = sc.configs[op.QueryNum]
}
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
三、Loop及Handler
对于loop其实也与lab3大同小异:
func (sc *ShardCtrler) applyMsgHandlerLoop() {
for {
select {
case msg := <-sc.applyCh:
//fmt.Printf("[----Loop-Receive----] Msg: %+v\n ", msg)
// 走正常的Command
if msg.CommandValid {
index := msg.CommandIndex
op := msg.Command.(Op)
//fmt.Printf("[ ~~~~applyMsgHandlerLoop~~~~ ]: %+v\n", msg)
// 判断是不是重复的请求
if !sc.ifDuplicate(op.ClientId, op.SeqId) {
sc.mu.Lock()
switch op.OpType {
case JoinType:
//fmt.Printf("[++++Receive-JoinType++++] : op: %+v\n", op)
sc.seqMap[op.ClientId] = op.SeqId
sc.configs = append(sc.configs, *sc.JoinHandler(op.JoinServers))
case LeaveType:
//fmt.Printf("[++++Receive-LeaveType++++] : op: %+v\n", op)
sc.seqMap[op.ClientId] = op.SeqId
sc.configs = append(sc.configs, *sc.LeaveHandler(op.LeaveGids))
case MoveType:
//fmt.Printf("[++++Receive-MoveType++++] : op: %+v\n", op)
sc.seqMap[op.ClientId] = op.SeqId
sc.configs = append(sc.configs, *sc.MoveHandler(op.MoveGid, op.MoveShard))
}
sc.seqMap[op.ClientId] = op.SeqId
sc.mu.Unlock()
}
// 将返回的ch返回waitCh
sc.getWaitCh(index) <- op
}
}
}
}
以及各种信息的处理在介绍中也有提到:
// JoinHandler 处理Join进来的gid
// The shardctrler should react by creating a new configuration that includes the new replica groups. The new
//configuration should divide the shards as evenly as possible among the full set of groups, and should move as few
//shards as possible to achieve that goal. The shardctrler should allow re-use of a GID if it's not part of the
//current configuration (i.e. a GID should be allowed to Join, then Leave, then Join again).
func (sc *ShardCtrler) JoinHandler(servers map[int][]string) *Config {
// 取出最后一个config将分组加进去
lastConfig := sc.configs[len(sc.configs)-1]
newGroups := make(map[int][]string)
for gid, serverList := range lastConfig.Groups {
newGroups[gid] = serverList
}
for gid, serverLists := range servers {
newGroups[gid] = serverLists
}
// GroupMap: groupId -> shards
// 记录每个分组有几个分片(group -> shards可以一对多,也因此需要负载均衡,而一个分片只能对应一个分组)
GroupMap := make(map[int]int)
for gid := range newGroups {
GroupMap[gid] = 0
}
// 记录每个分组存了多少分片
for _, gid := range lastConfig.Shards {
if gid != 0 {
GroupMap[gid]++
}
}
// 都没存自然不需要负载均衡,初始化阶段
if len(GroupMap) == 0 {
return &Config{
Num: len(sc.configs),
Shards: [10]int{
},
Groups: newGroups,
}
}
//需要负载均衡的情况
return &Config{
Num: len(sc.configs),
Shards: sc.loadBalance(GroupMap, lastConfig.Shards),
Groups: newGroups,
}
}
// LeaveHandler 处理需要离开的组
// The shardctrler should create a new configuration that does not include those groups, and that assigns those groups'
// shards to the remaining groups. The new configuration should divide the shards as evenly as possible among the groups,
// and should move as few shards as possible to achieve that goal.
func (sc *ShardCtrler) LeaveHandler(gids []int) *Config {
// 用set感觉更合适点但是go并没有内置的set..
leaveMap := make(map[int]bool)
for _, gid := range gids {
leaveMap[gid] = true
}
lastConfig := sc.configs[len(sc.configs)-1]
newGroups := make(map[int][]string)
// 取出最新配置的groups组进行填充
for gid, serverList := range lastConfig.Groups {
newGroups[gid] = serverList
}
// 删除对应的gid的值
for _, leaveGid := range gids {
delete(newGroups, leaveGid)
}
// GroupMap: groupId -> shards
// 记录每个分组有几个分片(group -> shards可以一对多,也因此需要负载均衡,而一个分片只能对应一个分组)
GroupMap := make(map[int]int)
newShard := lastConfig.Shards
// 对groupMap进行初始化
for gid := range newGroups {
if !leaveMap[gid] {
GroupMap[gid] = 0
}
}
for shard, gid := range lastConfig.Shards {
if gid != 0 {
// 如果这个组在leaveMap中,则置为0
if leaveMap[gid] {
newShard[shard] = 0
} else {
GroupMap[gid]++
}
}
}
// 直接删没了
if len(GroupMap) == 0 {
return &Config{
Num: len(sc.configs),
Shards: [10]int{
},
Groups: newGroups,
}
}
return &Config{
Num: len(sc.configs),
Shards: sc.loadBalance(GroupMap, newShard),
Groups: newGroups,
}
}
// MoveHandler 为指定的分片分配指定的组
// The shardctrler should create a new configuration in which the shard is assigned to the group. The purpose of Move is
// to allow us to test your software. A Join or Leave following a Move will likely un-do the Move, since Join and Leave
// re-balance.
func (sc *ShardCtrler) MoveHandler(gid int, shard int) *Config {
lastConfig := sc.configs[len(sc.configs)-1]
newConfig := Config{
Num: len(sc.configs),
Shards: [10]int{
},
Groups: map[int][]string{
}}
// 填充并赋值
for shards, gids := range lastConfig.Shards {
newConfig.Shards[shards] = gids
}
newConfig.Shards[shard] = gid
for gids, servers := range lastConfig.Groups {
newConfig.Groups[gids] = servers
}
return &newConfig
}
四、负载均衡
对于以上的那些其实都是比较简单之前写的一样的,对于Lab4A来说负载均衡其实才算是其中的一个难点。
为什么需要实现loadBalance?
如果不实现负载均衡那么可能会有这种情况:
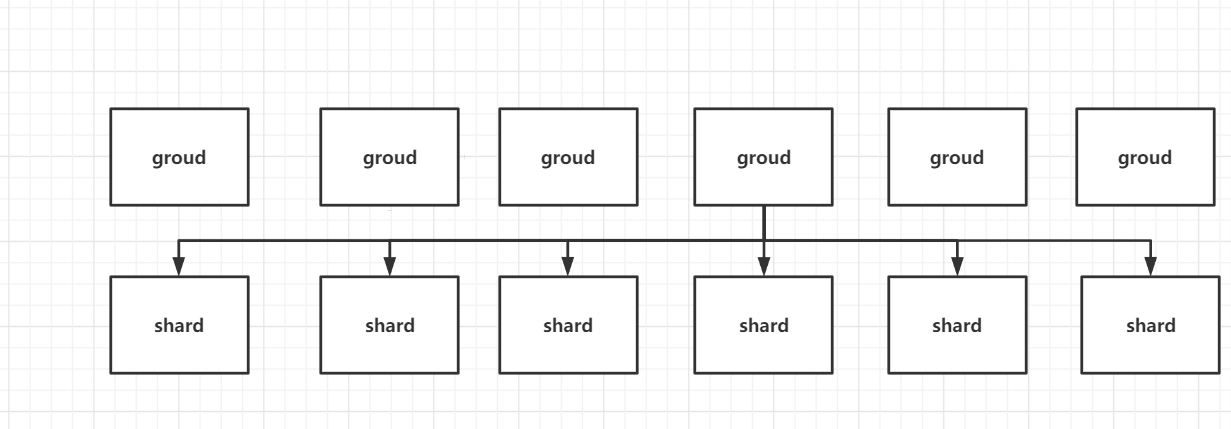
那么极端情况下就是这种情况,有6个组处理6个分片,但是6个分片集中给一个组处理了,导致这个组的压力会特别大。 如果是进行负载均衡后的组分配分片应该是这样的:
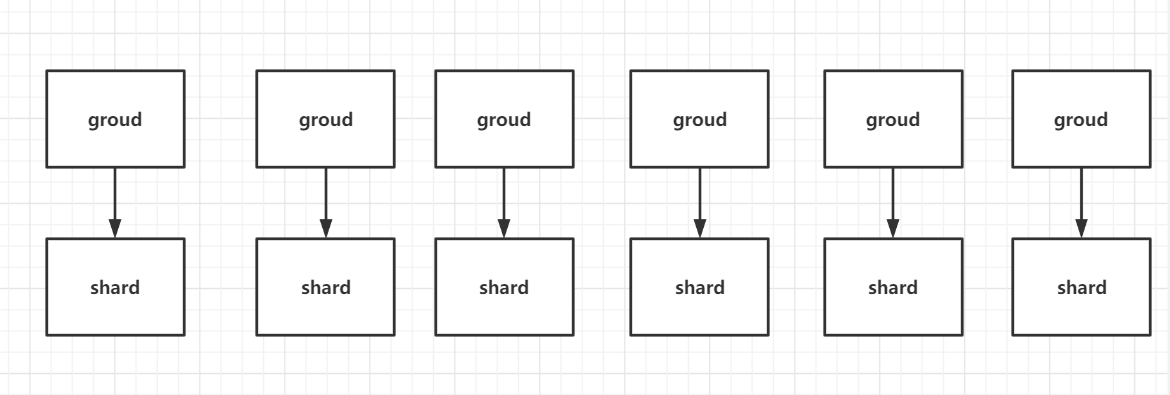
也因此在加入组和离开组的时候就需要进行负载均衡。而对于负载均衡的流程应该是:
- 首先对根据负载的情况进行排序,要记住的是如果有负载相同的情况下,需要对gid也进行排序,生成唯一序列,要不然会有一致性问题(TestMulti),因为排序的目的主要有以下原因:
- 可以通过排序就进行更少的交换,当然要确保这个过程中不会有Move等操作影响负载。
- 理想负载的情况并不可能均分,如10个分片分给4个组并不能是{2.5,2.5,2.5,2.5}。而应该是
{3,3,2,2}。对于这种情况就可以根据排序后的序列就可以通过预期的个数,确定哪几个组需要多负载一个分片。 - 需要对排序后的唯一序列对应到负载分片的map(具体可以见整体负载代码)。
// 根据sortGroupShard进行排序
// GroupMap : groupId -> shard nums
func sortGroupShard(GroupMap map[int]int) []int {
length := len(GroupMap)
gidSlice := make([]int, 0, length)
// map转换成有序的slice
for gid, _ := range GroupMap {
gidSlice = append(gidSlice, gid)
}
// 让负载压力大的排前面
// except: 4->3 / 5->2 / 6->1 / 7-> 1 (gids -> shard nums)
for i := 0; i < length-1; i++ {
for j := length - 1; j > i; j-- {
if GroupMap[gidSlice[j]] < GroupMap[gidSlice[j-1]] {
gidSlice[j], gidSlice[j-1] = gidSlice[j-1], gidSlice[j]
}
}
}
return gidSlice
}
然后每轮进行循环找到过载的,和比较空闲,进行互补就行了。
假设现在有10个分片,分配给4个组,且现在的负载情况为 {3,3,3,1},则第3个3应该为2,因为他不是需要多分配的那一个组就是过载。 而空闲的则为1,进行交换后就是为 {3,3,2,2}。
// 负载均衡
// GroupMap : gid -> servers[]
// lastShards : shard -> gid
func (sc *ShardCtrler) loadBalance(GroupMap map[int]int, lastShards [NShards]int) [NShards]int {
length := len(GroupMap)
ave := NShards / length
remainder := NShards % length
sortGids := sortGroupShard(GroupMap)
// 先把负载多的部分free
for i := 0; i < length; i++ {
target := ave
// 判断这个数是否需要更多分配,因为不可能完全均分,在前列的应该为ave+1
if !moreAllocations(length, remainder, i) {
target = ave + 1
}
// 超出负载
if GroupMap[sortGids[i]] > target {
overLoadGid := sortGids[i]
changeNum := GroupMap[overLoadGid] - target
for shard, gid := range lastShards {
if changeNum <= 0 {
break
}
if gid == overLoadGid {
lastShards[shard] = InvalidGid
changeNum--
}
}
GroupMap[overLoadGid] = target
}
}
// 为负载少的group分配多出来的group
for i := 0; i < length; i++ {
target := ave
if !moreAllocations(length, remainder, i) {
target = ave + 1
}
if GroupMap[sortGids[i]] < target {
freeGid := sortGids[i]
changeNum := target - GroupMap[freeGid]
for shard, gid := range lastShards {
if changeNum <= 0 {
break
}
if gid == InvalidGid {
lastShards[shard] = freeGid
changeNum--
}
}
GroupMap[freeGid] = target
}
}
return lastShards
}
func moreAllocations(length int, remainder int, i int) bool {
// 这个目的是判断index是否在安排ave+1的前列:3、3、3、1 ,ave: 10/4 = 2.5 = 2,则负载均衡后应该是2+1,2+1,2,2
if i < length-remainder {
return true
} else {
return false
}
}
- 虽然笔者现在讲解了这段代码后读者可能会觉得比较简单,但是其实自己完全实现负载均衡这个过程其实还是有点难的。包括负载均衡的方法也远远不止我这一种方式,笔者的方式是先加进去然后排序最后交换。 这时间复杂度应该就取决排序的复杂度,当然笔者这里就使用的是简单的冒泡,时间复杂度为n²,如果使用快排、归并等就可以优化到n*logn。
- 还有一种方式比较快的,那就是改变整个代码结构,实现个大顶堆或者小顶堆的数据结构。那么在join或者leave的就会自动进行排序了,其插入的复杂度就是logn。但是每次都需要重新建堆,因为堆并没有遍历这个说法,因此其实还是比较复杂的,还有个原因就是go其实没有内置的堆的数据结构。
五、总结
转眼也到lab4了,对于这次实验如果理解了实现通过还是比较容易的。
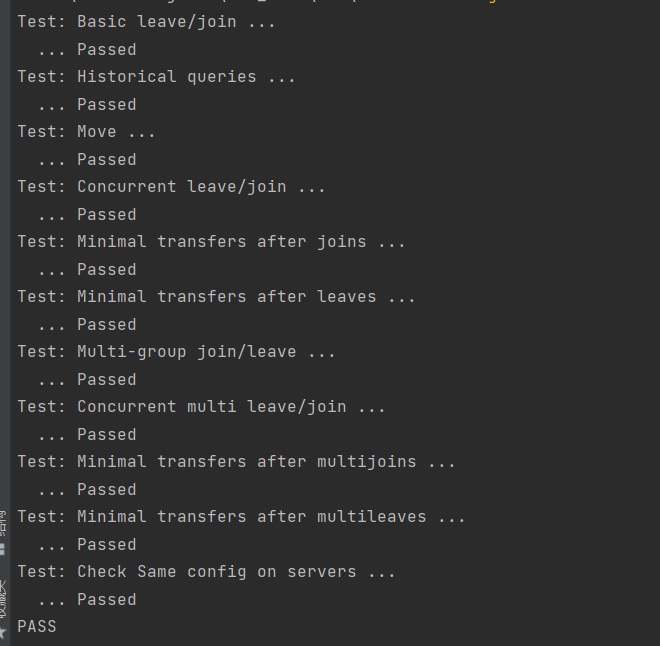
gitee:2022-6.824,如果后续lab实现有影响当前的lab,请参考master分支。