的
文章目录
一、Lab3A背景
对于3A来说的话,整体实现并不是很难,在paper中主要对应的是 section8。这次的实验就是实现在lab2中raft服务层的上一层service与client的交互。

这是总体的交互,而对于本次实验我也简单画了个图:

- 我们需要进行在client中去编写make,put/get/append等关于RPC又或者clerk初始化的函数。
- 然后这个函数的RPC会传到server中对应的put/get/append函数中,再由这些函数调用raft服务层,在raft进行共识。
- 最后由raft服务层apply到server中的applyCh中,但是这里返回的msg为raft封装好的command我们需要用自定义的Loop将command封装回传进来的op结构体给server,最后再返回回去。
二、client端
2.1、Clerk结构体与初始化
- clerk主要保存的是client信息
type Clerk struct {
servers []*labrpc.ClientEnd
// You will have to modify this struct.
seqId int
leaderId int // 确定哪个服务器是leader,下次直接发送给该服务器
clientId int64
}
- 其中对于seqId其实是为了这种情况:
if the leader crashes after committing the log entry but before responding to the client, the client will retry the command with a new leader, causing it to be executed a second time。
- 如果这个leader在commit log后crash了,但是还没响应给client,client就会重发这条command给新的leader,这样就会导致这个op执行两次。
- 而这种解决办法就是每次发送操作时附加一个唯一的序列号去为了标识操作,避免op被执行两次。
If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
- 而leaderId其实是为了下次能够直接发给正确leader(在hint中也有提到)
You will probably have to modify your Clerk to remember which server turned out to be the leader for the last RPC, and send the next RPC to that server first. This will avoid wasting time searching for the leader on every RPC, which may help you pass some of the tests quickly enough.
- 初始化
func MakeClerk(servers []*labrpc.ClientEnd) *Clerk {
ck := new(Clerk)
ck.servers = servers
// You'll have to add code here.
ck.clientId = nrand()
ck.leaderId = mathrand.Intn(len(ck.servers))
return ck
}
nrand()就是为了随机生成clientId,提供好的,mathrand这里是直接用的库随机生成一个开头LeaderId。
2.2 OP RPC
- get操作Rpc
func (ck *Clerk) Get(key string) string {
// You will have to modify this function.
ck.seqId++
args := GetArgs{
Key: key, ClientId: ck.clientId, SeqId: ck.seqId}
serverId := ck.leaderId
for {
reply := GetReply{
}
//fmt.Printf("[ ++++Client[%v]++++] : send a Get,args:%+v,serverId[%v]\n", ck.clientId, args, serverId)
ok := ck.servers[serverId].Call("KVServer.Get", &args, &reply)
if ok {
if reply.Err == ErrNoKey {
ck.leaderId = serverId
return ""
} else if reply.Err == OK {
ck.leaderId = serverId
return reply.Value
} else if reply.Err == ErrWrongLeader {
serverId = (serverId + 1) % len(ck.servers)
continue
}
}
// 节点发生crash等原因
serverId = (serverId + 1) % len(ck.servers)
}
}
- Put/Append 操作RPC
func (ck *Clerk) PutAppend(key string, value string, op string) {
// You will have to modify this function.
ck.seqId++
serverId := ck.leaderId
args := PutAppendArgs{
Key: key, Value: value, Op: op, ClientId: ck.clientId, SeqId: ck.seqId}
for {
reply := PutAppendReply{
}
//fmt.Printf("[ ++++Client[%v]++++] : send a %v,serverId[%v] : serverId:%+v\n", ck.clientId, op, args, serverId)
ok := ck.servers[serverId].Call("KVServer.PutAppend", &args, &reply)
if ok {
if reply.Err == OK {
ck.leaderId = serverId
return
} else if reply.Err == ErrWrongLeader {
serverId = (serverId + 1) % len(ck.servers)
continue
}
}
serverId = (serverId + 1) % len(ck.servers)
}
}
三、server端
3.1、server结构体及初始化
- op结构体:
type Op struct {
// Your definitions here.
// Field names must start with capital letters,
// otherwise RPC will break.
SeqId int
Key string
Value string
ClientId int64
Index int // raft服务层传来的Index
OpType string
}
op结构体的设计要能接受上层client发来的参数,并且能够转接的raft服务层回来的command。
- KVServer结构体:
type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
dead int32 // set by Kill()
maxraftstate int // snapshot if log grows this big
// Your definitions here.
seqMap map[int64]int //为了确保seq只执行一次 clientId / seqId
waitChMap map[int]chan Op //传递由下层Raft服务的appCh传过来的command index / chan(Op)
kvPersist map[string]string // 存储持久化的KV键值对 K / V
}
主要定义的就是seqMap,waitChMap,kvPersist作为信息临时存放、处理、持久化等。
- 初始化:
func StartKVServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int) *KVServer {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Op{
})
kv := new(KVServer)
kv.me = me
kv.maxraftstate = maxraftstate
// You may need initialization code here.
kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh)
// You may need initialization code here.
kv.seqMap = make(map[int64]int)
kv.kvPersist = make(map[string]string)
kv.waitChMap = make(map[int]chan Op)
go kv.applyMsgHandlerLoop()
return kv
}
主要定义的就是初始化几个map,并开启转接Loop;
3.2、信息转接及RPC定义
- Get操作RPC
func (kv *KVServer) Get(args *GetArgs, reply *GetReply) {
// Your code here.
if kv.killed() {
reply.Err = ErrWrongLeader
return
}
_, ifLeader := kv.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// 封装Op传到下层start
op := Op{
OpType: "Get", Key: args.Key, SeqId: args.SeqId, ClientId: args.ClientId}
//fmt.Printf("[ ----Server[%v]----] : send a Get,op is :%+v \n", kv.me, op)
lastIndex, _, _ := kv.rf.Start(op)
ch := kv.getWaitCh(lastIndex)
defer func() {
kv.mu.Lock()
delete(kv.waitChMap, op.Index)
kv.mu.Unlock()
}()
// 设置超时ticker
timer := time.NewTicker(100 * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a GetAsk :%+v,replyOp:+%v\n", kv.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
kv.mu.Lock()
reply.Value = kv.kvPersist[args.Key]
kv.mu.Unlock()
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
其中的getWaitCh就是为了获取raftStart对应下标的缓冲chan。
func (kv *KVServer) getWaitCh(index int) chan Op {
kv.mu.Lock()
defer kv.mu.Unlock()
ch, exist := kv.waitChMap[index]
if !exist {
kv.waitChMap[index] = make(chan Op, 1)
ch = kv.waitChMap[index]
}
return ch
}
要注意的对raft进行start后他其实提交的其实是applyCh,主体是raft.ApplyMsg,因此还需要loop将applyMsg转接成op再返回到waitCh中。
- 转接信息的Loop。
func (kv *KVServer) applyMsgHandlerLoop() {
for {
if kv.killed() {
return
}
select {
case msg := <-kv.applyCh:
index := msg.CommandIndex
op := msg.Command.(Op)
//fmt.Printf("[ ~~~~applyMsgHandlerLoop~~~~ ]: %+v\n", msg)
if !kv.ifDuplicate(op.ClientId, op.SeqId) {
kv.mu.Lock()
switch op.OpType {
case "Put":
kv.kvPersist[op.Key] = op.Value
case "Append":
kv.kvPersist[op.Key] += op.Value
}
kv.seqMap[op.ClientId] = op.SeqId
kv.mu.Unlock()
}
// 将返回的ch返回waitCh
kv.getWaitCh(index) <- op
}
}
}
而其中判断是否是重复操作的也比较简单,因为我是对seq进行递增,所以直接比大小即可。
func (kv *KVServer) ifDuplicate(clientId int64, seqId int) bool {
kv.mu.Lock()
defer kv.mu.Unlock()
lastSeqId, exist := kv.seqMap[clientId]
if !exist {
return false
}
return seqId <= lastSeqId
}
- put/append RPC 这个函数就与get大同小异了
func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
// Your code here.
if kv.killed() {
reply.Err = ErrWrongLeader
return
}
_, ifLeader := kv.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// 封装Op传到下层start
op := Op{
OpType: args.Op, Key: args.Key, Value: args.Value, SeqId: args.SeqId, ClientId: args.ClientId}
//fmt.Printf("[ ----Server[%v]----] : send a %v,op is :%+v \n", kv.me, args.Op, op)
lastIndex, _, _ := kv.rf.Start(op)
ch := kv.getWaitCh(lastIndex)
defer func() {
kv.mu.Lock()
delete(kv.waitChMap, op.Index)
kv.mu.Unlock()
}()
// 设置超时ticker
timer := time.NewTicker(100 * time.Millisecond)
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a %vAsk :%+v,Op:%+v\n", kv.me, args.Op, args, replyOp)
// 通过clientId、seqId确定唯一操作序列
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
defer timer.Stop()
}
四、Lab3B
4.1、lab3B结构
对于lab3B来说就是要引入raft2D的快照,去尽可能的减少时间。这里重新画下加上snapshot的结构图:
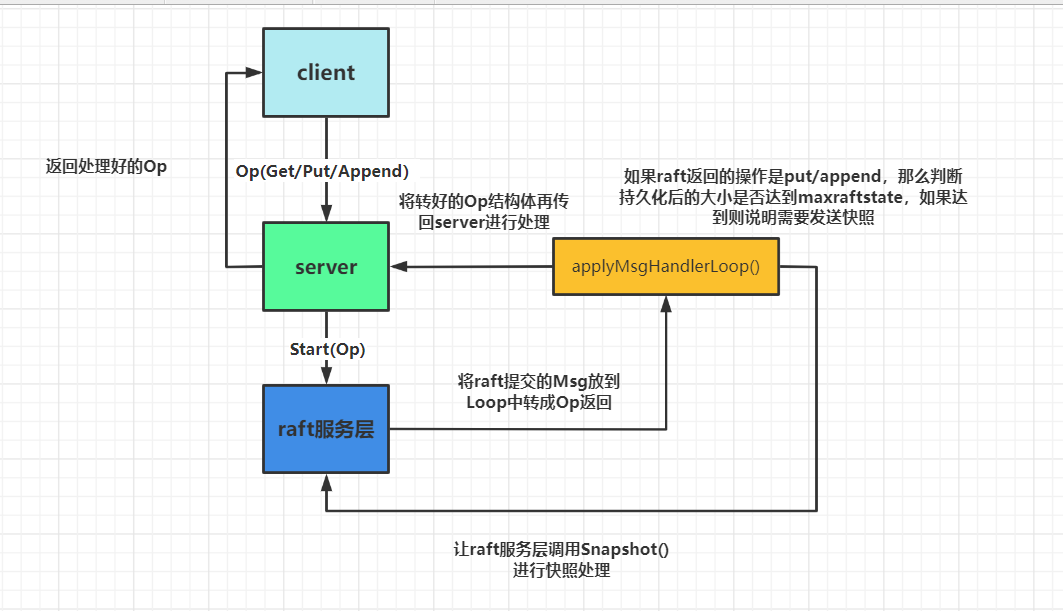
其实就只要在写入操作时,判断持久化的大小需不需要进行快照存储就行。
4.2、重写loop
- 重写loop
// 处理applyCh发送过来的ApplyMsg
func (kv *KVServer) applyMsgHandlerLoop() {
for {
if kv.killed() {
return
}
select {
case msg := <-kv.applyCh:
if msg.CommandValid {
// 传来的信息快照已经存储了
if msg.CommandIndex <= kv.lastIncludeIndex {
return
}
index := msg.CommandIndex
op := msg.Command.(Op)
//fmt.Printf("[ ~~~~applyMsgHandlerLoop~~~~ ]: %+v\n", msg)
if !kv.ifDuplicate(op.ClientId, op.SeqId) {
kv.mu.Lock()
switch op.OpType {
case "Put":
kv.kvPersist[op.Key] = op.Value
case "Append":
kv.kvPersist[op.Key] += op.Value
}
kv.seqMap[op.ClientId] = op.SeqId
kv.mu.Unlock()
}
// 如果需要snapshot,且超出其stateSize
if kv.maxraftstate != -1 && kv.rf.GetRaftStateSize() > kv.maxraftstate {
snapshot := kv.PersistSnapShot()
kv.rf.Snapshot(msg.CommandIndex, snapshot)
}
// 将返回的ch返回waitCh
kv.getWaitCh(index) <- op
}
if msg.SnapshotValid {
kv.mu.Lock()
// 判断此时有没有竞争
if kv.rf.CondInstallSnapshot(msg.SnapshotTerm, msg.SnapshotIndex, msg.Snapshot) {
// 读取快照的数据
kv.DecodeSnapShot(msg.Snapshot)
kv.lastIncludeIndex = msg.SnapshotIndex
}
kv.mu.Unlock()
}
}
}
}
超出范围传到raft服务层,自身也要进行持久序列化:
// 如果需要snapshot,且超出其stateSize
if kv.maxraftstate != -1 && kv.rf.GetRaftStateSize() > kv.maxraftstate {
snapshot := kv.PersistSnapShot()
kv.rf.Snapshot(msg.CommandIndex, snapshot)
}
收到snapshot返回的msg直接反序列化出来:
if msg.SnapshotValid {
kv.mu.Lock()
// 判断此时有没有竞争
if kv.rf.CondInstallSnapshot(msg.SnapshotTerm, msg.SnapshotIndex, msg.Snapshot) {
// 读取快照的数据
kv.DecodeSnapShot(msg.Snapshot)
kv.lastIncludeIndex = msg.SnapshotIndex
}
kv.mu.Unlock()
}
4.3、序列化与反序列化、初始化
对于序列化和反序列化就是之前的那一套了,除了缓冲等待的chan不需要其实的都persist就行。
func (kv *KVServer) DecodeSnapShot(snapshot []byte) {
if snapshot == nil || len(snapshot) < 1 {
return
}
r := bytes.NewBuffer(snapshot)
d := labgob.NewDecoder(r)
var kvPersist map[string]string
var seqMap map[int64]int
if d.Decode(&kvPersist) == nil && d.Decode(&seqMap) == nil {
kv.kvPersist = kvPersist
kv.seqMap = seqMap
} else {
fmt.Printf("[Server(%v)] Failed to decode snapshot!!!", kv.me)
}
}
// PersistSnapShot 持久化快照对应的map
func (kv *KVServer) PersistSnapShot() []byte {
kv.mu.Lock()
defer kv.mu.Unlock()
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.kvPersist)
e.Encode(kv.seqMap)
data := w.Bytes()
return data
}
- 初始化也是加上快照的信息:
func StartKVServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int) *KVServer {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Op{
})
kv := new(KVServer)
kv.me = me
kv.maxraftstate = maxraftstate
// You may need initialization code here.
kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh)
// You may need initialization code here.
kv.seqMap = make(map[int64]int)
kv.kvPersist = make(map[string]string)
kv.waitChMap = make(map[int]chan Op)
kv.lastIncludeIndex = -1
// 因为可能会crash重连
snapshot := persister.ReadSnapshot()
if len(snapshot) > 0 {
kv.DecodeSnapShot(snapshot)
}
go kv.applyMsgHandlerLoop()
return kv
}
五、Debug杂谈
-
3A:
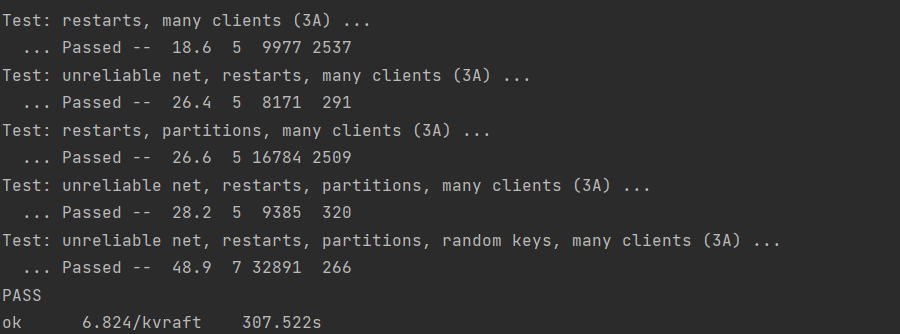
对于本次的lab3A总体构建其实并不难,但是其中的test对lab2的实现其实要求还是挺高的。就拿TestSpeed3A来说这个test主要是进行1000次的op请求,再计算平均每次的op时间,要求在30ms以下。对比笔者来说一开始test截图是这样的:
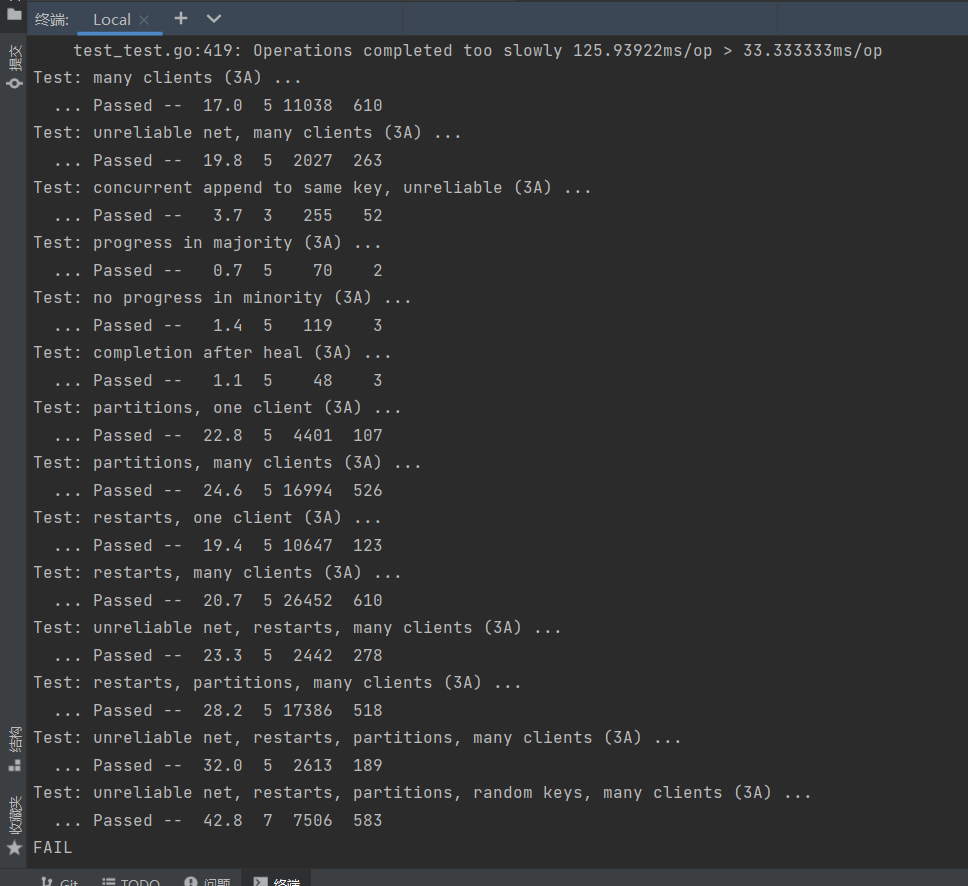
比要求的30ms慢了四倍,后面一部分的原因是因为我在进行发送RPC的时候,发现其实还是重新进行了初始的serverId进行发送,并没有按照原来的进行。 -
这一部分的原因在于我在发送rpc返回成功时并没有再一次的锁定,导致被马上第二次发送的rpc给重新覆盖了,因此在发送成功后再进行锁定就行。
然后再者就是我在raft中三个Loop之间的休眠时间太长,因为lab2中也定义了相关投票时间为150~300,也应该有笔者实现的可能不是那么的完美orz…
在进行raft的三个ticker的休眠时间后,勉强能降到46ms。
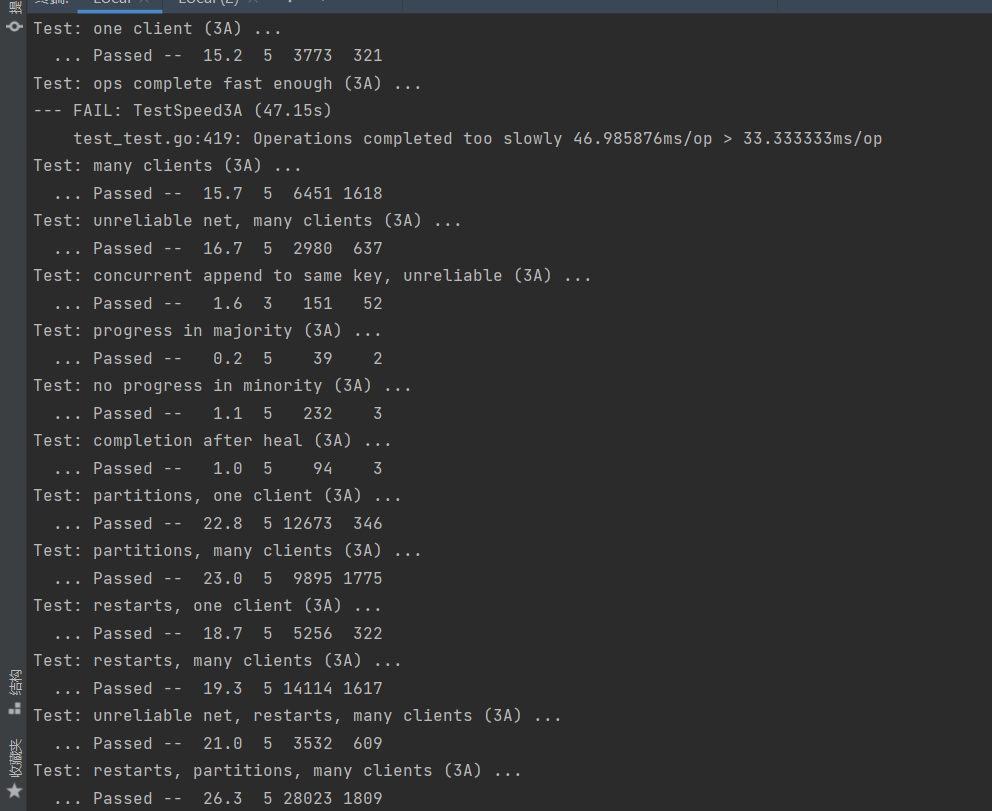
还差一点,不过相比当初的120ms已经算是减少了2/3,到46ms,lab2的时间也大概缩短了100s左右到400s进行,但是如果只是为了lab3A这个实验能够达到allpast其实也是可以的。
将2b的休眠改的非常短:
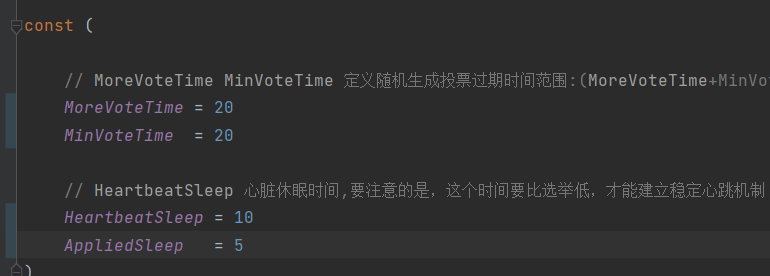
但是这样对于我来说这就会有一个很矛盾的点,特别是在raft的2b的testCount中,他其实是为了测试你的RPC数量是否过多,要保持在30以内,那么你就要为了减少heartbeat rpc的次数,而增大休眠时间,而这个则是跟3a的速度测试矛盾的。而且如果把各个休眠时间减少,那么在raft很容易造成容错问题,因为选举等因为时间减少很容易时间散列会到一起,造成平常可能几百份之一的特殊情况现在可能出现的概率会提高几十倍,我认为这是不值得。也因此最后的平衡的情况就是为了通过lab2的全部test保证更高的可用性,牺牲lab3A的性能保证结果的正确性。
同样对于3b来说也是如此:
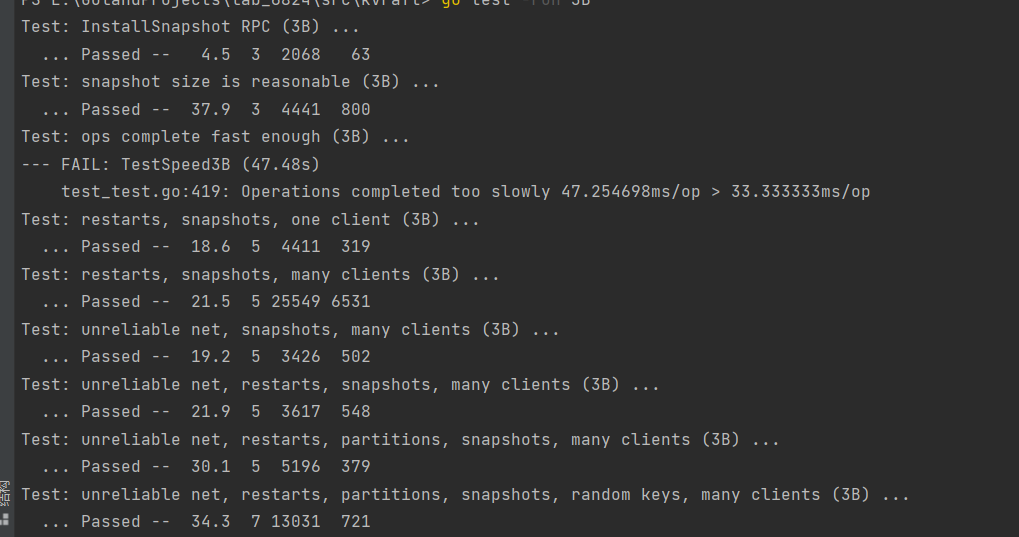
总结
这次实验虽然简单但是,也很清晰的体验到了分布式系统三个特性可能有的时候并不是能全不达到,可扩展性、性能、可用性,而这三个特性其实在一开始的lab1的introduction就有提到,希望在后续做完的时候能够去进行一次总结。
gitee:lab3A