前言
趁着最近有一点时间,把2C过一遍…
一、实验目标
对于lab2C来讲如果2A、2B的实验比较完善,且实现了论文中的细节来说2C是比较简单的。
对于2C来说实现的话就是其状态的persist(持久化)为了能在机器crash的时候能够restore原来的状态。而对于状态的持久化的内容来说的话就是一开始表格所提供的:

currentTerm、voteFor、log[]三个state。因此只要当raft节点的这三个状态发生改变时,就直接persist就好了。当然在课程的lab2C介绍中还要求做到paper中p7末到p7顶部那一段的细节实现。
If desired, the protocol can be optimized to reduce thenumber of rejected AppendEntries RPCs. For example,when rejecting an AppendEntries request, the follower.can include the term of the conflicting entry and the first index it stores for that term. With this information, the leader can decrement nextIndex to bypass all of the conflicting entries in that term; one AppendEntries RPC will be required for each term with conflicting entries, rather than one RPC per entry. In practice, we doubt this optimization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent entries.
对于这一段来说的话,他其实实现的细节就是你可以在RPC的时候,如果有冲突,直接返回冲突的下标,或者term,然后返回冲突的下标,进行修改nextIndex[i]亦或者是term,达到减少RPC的次数。而2C的实验中的Figure 8 (unreliable)也是基于此方法,测试你的RPC次数会不会过多。
二、lab正文
2.1、编码/解码
对于此次实验来说首先应该实现:persist、与readPersist两个函数。分别是编码(encode)、解码(decode)。对于这两个函数框架内也给了Example。这里就简单提供下笔者的实现。
//
// save Raft's persistent state to stable storage,
// where it can later be retrieved after a crash and restart.
// see paper's Figure 2 for a description of what should be persistent.
//
func (rf *Raft) persist() {
// Your code here (2C).
// Example:
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
data := w.Bytes()
rf.persister.SaveRaftState(data)
//fmt.Printf("RaftNode[%d] persist starts, currentTerm[%d] voteFor[%d] log[%v]\n", rf.me, rf.currentTerm, rf.votedFor, rf.logs)
//fmt.Printf("%v\n", string(data))
}
//
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 {
// bootstrap without any state?
return
}
// Your code here (2C).
// Example:
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var logs []LogEntry
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&logs) != nil {
fmt.Println("decode error")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.logs = logs
//fmt.Printf("RaftNode[%d] persist read, currentTerm[%d] voteFor[%d] log[%v]\n", rf.me, currentTerm, votedFor, logs)
}
}
值得一提的是要注意自己编码与解码时变量是否一致,否则在解码(decode)的时候会取不到值,而爆出decode error,这个坑也花了笔者的两三个小时。
2.2、日志增量回退
对于这部分笔者其实在2b的时候就采用了直接返回冲突的地方,对于笔者来说是直接回退到applied的地方,继续日志提交,当然也可以自己另起一个协程做日志commit,而回退就进行for循环回退到相等的地方,其余的交给日志提交的协程来做。这里也是简单的提供下思路代码:
RPC结构体:
type AppendEntriesReply struct {
Term int // leader的term可能是过时的,此时收到的Term用于更新他自己
Success bool // 如果follower与Args中的PreLogIndex/PreLogTerm都匹配才会接过去新的日志(追加),不匹配直接返回false
AppState AppendEntriesState // 追加状态
UpNextIndex int // 用于更新请求节点的nextIndex[i]
}
// AppendEntriesArgs 由leader复制log条目,也可以当做是心跳连接,注释中的rf为leader节点
type AppendEntriesArgs struct {
Term int // leader的任期
LeaderId int // leader自身的ID
PrevLogIndex int // 预计要从哪里追加的index,因此每次要比当前的len(logs)多1 args初始化为:rf.nextIndex[i] - 1
PrevLogTerm int // 追加新的日志的任期号(这边传的应该都是当前leader的任期号 args初始化为:rf.currentTerm
Entries []LogEntry // 预计存储的日志(为空时就是心跳连接)
LeaderCommit int // leader的commit index指的是最后一个被大多数机器都复制的日志Index
}
日志增量的实现:
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply, appendNums *int) {
if rf.killed() {
return
}
// paper中5.3节第一段末尾提到,如果append失败应该不断的retries ,直到这个log成功的被store
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
for !ok {
if rf.killed() {
return
}
ok = rf.peers[server].Call("Raft.AppendEntries", args, reply)
}
// 必须在加在这里否则加载前面retry时进入时,RPC也需要一个锁,但是又获取不到,因为锁已经被加上了
rf.mu.Lock()
defer rf.mu.Unlock()
//fmt.Printf("[ sendAppendEntries func-rf(%v) ] get reply :%+v from rf(%v)\n", rf.me, reply, server)
// 对reply的返回状态进行分支
switch reply.AppState {
// 目标节点crash
case AppKilled:
{
return
}
// 目标节点正常返回
case AppNormal:
{
// 2A的test目的是让Leader能不能连续任期,所以2A只需要对节点初始化然后返回就好
// 2B需要判断返回的节点是否超过半数commit,才能将自身commit
if reply.Success && reply.Term == rf.currentTerm && *appendNums <= len(rf.peers)/2 {
*appendNums++
}
// 说明返回的值已经大过了自身数组
if rf.nextIndex[server] > len(rf.logs)+1 {
return
}
rf.nextIndex[server] += len(args.Entries)
if *appendNums > len(rf.peers)/2 {
// 保证幂等性,不会提交第二次
*appendNums = 0
if len(rf.logs) == 0 || rf.logs[len(rf.logs)-1].Term != rf.currentTerm {
return
}
for rf.lastApplied < len(rf.logs) {
rf.lastApplied++
applyMsg := ApplyMsg{
CommandValid: true,
Command: rf.logs[rf.lastApplied-1].Command,
CommandIndex: rf.lastApplied,
}
rf.applyChan <- applyMsg
rf.commitIndex = rf.lastApplied
//fmt.Printf("[ sendAppendEntries func-rf(%v) ] commitLog \n", rf.me)
}
}
//fmt.Printf("[ sendAppendEntries func-rf(%v) ] rf.log :%+v ; rf.lastApplied:%v\n",
// rf.me, rf.logs, rf.lastApplied)
return
}
case Mismatch, AppCommitted:
if reply.Term > rf.currentTerm {
rf.status = Follower
rf.votedFor = -1
rf.timer.Reset(rf.overtime)
rf.currentTerm = reply.Term
rf.persist()
}
rf.nextIndex[server] = reply.UpNextIndex
//If AppendEntries RPC received from new leader: convert to follower(paper - 5.2)
//reason: 出现网络分区,该Leader已经OutOfDate(过时),term小于发送者
case AppOutOfDate:
// 该节点变成追随者,并重置rf状态
rf.status = Follower
rf.votedFor = -1
rf.timer.Reset(rf.overtime)
rf.currentTerm = reply.Term
rf.persist()
}
return
}
// AppendEntries 建立心跳、同步日志RPC
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
//fmt.Printf("[ AppendEntries func-rf(%v) ] arg:%+v,------ rf.logs:%v \n", rf.me, args, rf.logs)
// 节点crash
if rf.killed() {
reply.AppState = AppKilled
reply.Term = -1
reply.Success = false
return
}
// args.Term < rf.currentTerm:出现网络分区,args的任期,比当前raft的任期还小,说明args之前所在的分区已经OutOfDate 2A
if args.Term < rf.currentTerm {
reply.AppState = AppOutOfDate
reply.Term = rf.currentTerm
reply.Success = false
return
}
// 出现conflict的情况
// paper:Reply false if log doesn’t contain an entry at prevLogIndex,whose term matches prevLogTerm (§5.3)
// 首先要保证自身len(rf)大于0否则数组越界
// 1、 如果preLogIndex的大于当前日志的最大的下标说明跟随者缺失日志,拒绝附加日志
// 2、 如果preLog出`的任期和preLogIndex处的任期和preLogTerm不相等,那么说明日志存在conflict,拒绝附加日志
if args.PrevLogIndex > 0 && (len(rf.logs) < args.PrevLogIndex || rf.logs[args.PrevLogIndex-1].Term != args.PrevLogTerm) {
reply.AppState = Mismatch
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
// 如果当前节点提交的Index比传过来的还高,说明当前节点的日志已经超前,需返回过去
if args.PrevLogIndex != -1 && rf.lastApplied > args.PrevLogIndex {
reply.AppState = AppCommitted
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
// 对当前的rf进行ticker重置
rf.currentTerm = args.Term
rf.votedFor = args.LeaderId
rf.status = Follower
rf.timer.Reset(rf.overtime)
// 对返回的reply进行赋值
reply.AppState = AppNormal
reply.Term = rf.currentTerm
reply.Success = true
// 如果存在日志包那么进行追加
if args.Entries != nil {
rf.logs = rf.logs[:args.PrevLogIndex]
rf.logs = append(rf.logs, args.Entries...)
}
rf.persist()
// 将日志提交至与Leader相同
for rf.lastApplied < args.LeaderCommit {
rf.lastApplied++
applyMsg := ApplyMsg{
CommandValid: true,
CommandIndex: rf.lastApplied,
Command: rf.logs[rf.lastApplied-1].Command,
}
rf.applyChan <- applyMsg
rf.commitIndex = rf.lastApplied
//fmt.Printf("[ AppendEntries func-rf(%v) ] commitLog \n", rf.me)
}
return
}
三、总结
对于排错:在做实验中,分布式排查应该主要对于每个状态间的转化,并把问题压缩到某一个test,某一个状态转化的顺序是否如预期所想,才是最重要的。
连续做到lab2C也开始逐渐有些感觉,每个2的每个lab都是在承接上一个的实现,也看了下lab2D实现的就是paper中(InstallSnapshot)快照。接下来附上自己的allPast包括回归性测试。
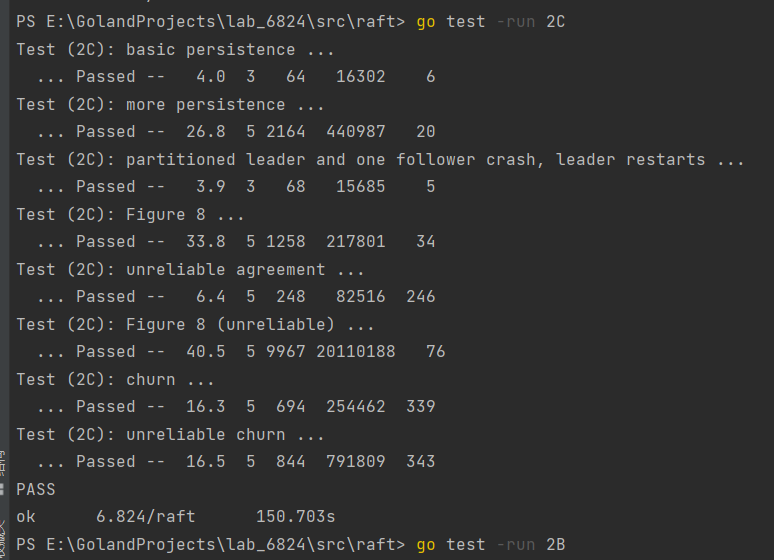
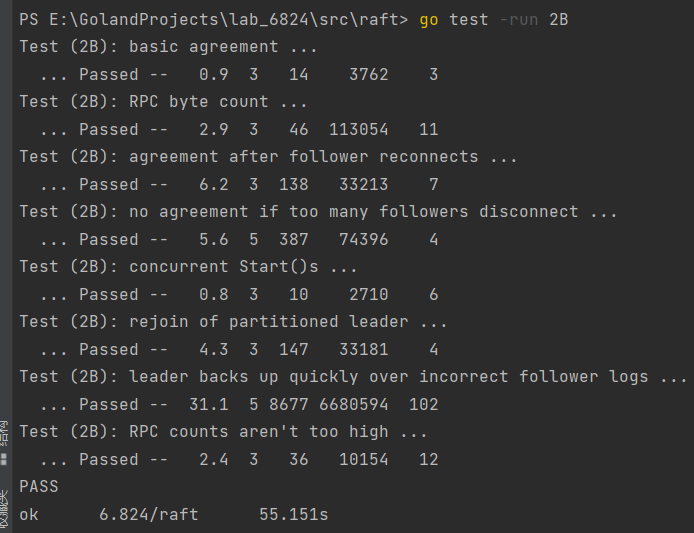
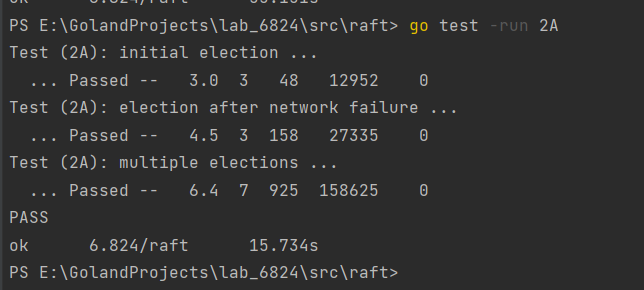
对于Figure 8 (unreliable)还是有点水分的,因为对于ticker的时候我并没有去试图更新各个nextIndex[i],而对于Rpc次数也是有一定的偶然性,对于这部分的打磨,打算放到2D去具体的实现。各位笔者,也应尽量遵守课程的要求,去自己实现一遍自己的raft框架,确保lab的最大食用体验,代码和思路也仅供参考。gitee地址:6.824-lab2C-2022
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。