通过预测 10,000 个类别的深度学习人脸表示
paper题目:Deep Learning Face Representation from Predicting 10,000 Classes
paper是香港中文大学发表在CVPR 2014的工作
paper地址:链接
Abstract
本文提出通过深度学习学习一组高级特征表示,称为深度隐藏身份特征(DeepID),用于人脸验证。作者认为,DeepID 可以通过具有挑战性的多类人脸识别任务有效地学习,同时它们可以推广到其他任务(例如验证)和训练集中看不到的新身份。此外,随着在训练中要预测更多的人脸类别,DeepID 的泛化能力也会提高。 DeepID 特征取自深度卷积网络 (ConvNets) 的最后一个隐藏层神经元激活。当作为分类器学习以识别训练集中大约 10,000 个人脸身份并配置为沿特征提取层次不断减少神经元数量时,这些深度卷积网络逐渐在顶层形成紧凑的身份相关特征,只有少量隐藏的神经元。提出的特征是从各种面部区域中提取的,以形成互补和过完备的表示。任何最先进的分类器都可以基于这些用于人脸验证的高级表示来学习。 LFW 上 97.45% 的验证准确率仅通过弱对齐的人脸实现。
1. Introduction
近年来,由于其实际应用和LFW的发布,在无约束条件下的人脸验证被广泛研究,这是一个广泛使用的人脸验证算法的数据集。目前表现最好的人脸验证算法通常用过度完整的低层次特征来表示人脸,其次是浅层模型。最近,深度模型如ConvNets已被证明能有效地提取高层次的视觉特征,并被用于人脸验证。Huang等人在没有监督的情况下学习了一个生成的深度模型。Cai等人学习了深度非线性度量。在[31]中,深度模型是由二进制人脸验证目标监督的。不同的是,本文提出通过人脸识别,即把训练图像归入 n n n个身份(在这项工作中 n ≈ 10 , 000 n \approx 10,000 n≈10,000)中的一个,用深度模型学习高水平的人脸身份特征。这个高维预测任务比人脸验证更具挑战性,然而,它导致了对所学特征表示的良好概括。虽然是通过识别来学习的,但这些特征被证明对人脸验证和训练集中未见过的新面孔是有效的。
本文提出了一种有效的方法来学习具有深度网络的高级过完备特征。图1显示了特征提取过程的高级图示。ConvNets通过其身份对所有可用于训练的人脸进行分类学习,最后一个隐藏层神经元激活作为特征(称为深层隐藏身份特征或深度ID)。每个ConvNet将人脸切片作为输入,并在底层提取局部低级特征。特征数量沿着特征提取级联继续减少,同时在顶层中逐渐形成更多的全局和高级特征。在级联的末端获得高度紧凑的160维DeepID,其包含丰富的身份信息并直接预测更大数量(例如, 10 , 000 10,000 10,000)的身份类别。同时对所有身份进行分类,这是基于两个考虑。首先,与执行二元分类相比,将训练样本预测到许多类别中的一个类别要困难得多。这一具有挑战性的任务可以充分利用神经网络的超强学习能力来提取有效的特征用于人脸识别。第二,它隐式地为ConvNets添加了一个强正则化,这有助于形成可以很好地分类所有身份的共享隐藏表示。因此,学习到的高级特征具有良好的泛化能力,并且不会过度适应训练人脸的小子集。将DeepID限制为明显少于它们预测的身份类别,这是学习高度紧凑和判别性的特征的关键。进一步连接从各个人脸区域提取的DeepID,以形成互补和过完备的表示。学习到的特征可以很好地推广到测试中的新身份,这在训练中是看不到的,并且可以容易地与任何最先进的人脸分类器(例如,联合贝叶斯)集成用于人脸验证。
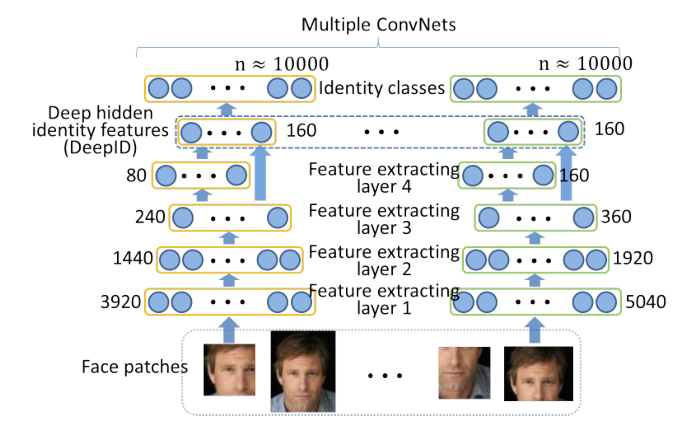
图 1. 特征提取过程示意图。箭头表示前向传播方向。多个深度卷积网络的每一层中的神经元数量在每一层旁边标记。 DeepID 特征取自每个 ConvNet 的最后一个隐藏层,并预测大量的身份类别。特征数量沿着特征提取级联继续减少,直到 DeepID 层。
本文的方法仅使用弱对齐的人脸在 LFW 上实现了 97.45% 的人脸验证准确率,这几乎与人类 97.53% 的表现一样好。作者还观察到,随着训练身份数量的增加,验证性能稳步提高。尽管训练阶段的预测任务变得更具挑战性,但学习到的特征的判别和泛化能力增加了。它为未来通过更多训练数据提高准确性敞开了大门。
2. Related work
许多人脸验证方法通过高维过完备人脸描述符来表示人脸,然后是浅层模型。Cao等人将每个人脸图像编码为 26K 个基于学习的(LE)描述符,然后在 PCA 之后计算 LE 描述符之间的 L 2 L_{2} L2距离。Chen等人在具有多个尺度的密集面部标志处提取了 100K LBP 描述符,并在 PCA 之后使用联合贝叶斯进行验证。Simonyan等人在尺度和空间上密集计算 1.7M SIFT 描述符,将密集的 SIFT 特征编码为 Fisher 向量,并学习线性投影以进行判别性降维。Huang等人结合了 1.2M CMD和 SLBP描述符,并学习了用于人脸验证的稀疏Mahalanobis度量。
之前的一些研究在低级特征的基础上进一步学习了与身份相关的特征。Kumar等人训练属性和模拟分类器来检测面部属性并测量与一组参考人的面部相似性。 Berg和Belhumeur训练了分类器来区分两个不同人的面孔。特征是学习分类器的输出。他们使用了SVM分类器,属于浅层结构,学习到的特征仍然比较低级。相反,本文同时对训练集中的所有身份进行分类。此外,本文使用最后的隐藏层激活作为特征而不是分类器输出。在ConvNets中,最后一个隐藏层的神经元数量远小于输出的神经元数量,这迫使最后一个隐藏层学习不同人脸的共享隐藏表示,以便对所有人进行很好的分类,从而产生高度的判别力以及具有良好泛化能力的紧凑特征。
一些深度模型已经被用于人脸验证或识别。Chopra等人使用孪生网络进行深度度量学习。 孪生网络用两个相同的子网络从两个比较的输入中分别提取特征,把两个子网络的输出之间的距离作为异同。[10]使用深度ConvNets作为子网络。与孪生网络中的特征提取和识别与人脸验证目标共同学习不同,本文分两步进行特征提取和识别,第一步特征提取是以人脸识别为目标学习的,这比验证的监督信号强得多。Huang等人用CDBNs生成地学习特征,然后用TML和线性SVM进行人脸验证。Cai等人也像[10]一样在孪生网络框架下学习了深度度量,但使用两级ISA网络作为子网络。Zhu等人学习了深度神经网络,将任意姿势和照度的人脸转化为正常照度的正面人脸,然后使用最后的隐藏层特征或转化后的人脸进行人脸识别。Sun等人使用多个深度ConvNets学习高水平的人脸相似性特征,并训练分类RBM用于人脸验证。他们的特征是从一对人脸中联合提取的,而不是从一张脸中提取。
3. Learning DeepID for face verification
3.1. Deep ConvNets
本文的深度ConvNets包含四个卷积层(带有最大池),分层提取特征,然后是全连接的DeepID层和表示身份类别的softmax输出层。矩形切片的输入是 39 × 31 × k 39\times 31\times k 39×31×k,方形切片的输入是 31 × 31 × k 31\times 31\times k 31×31×k,其中彩色切片的k=3,灰色切片的k=1。图2显示了ConvNet的详细结构,它接受 39 × 31 × 1 39 \times 31 \times 1 39×31×1的输入并预测 n n n(例如, n = 10 , 000 n=10,000 n=10,000)个身份类别。当输入的尺寸发生变化时,下面各层的特征图的高度和宽度也会相应发生变化。DeepID层的尺寸固定为160,而输出层的尺寸则根据其预测的类的数量而变化。特征数量沿着特征提取层次不断减少,直到最后一个隐藏层(DeepID层),这里形成了高度紧凑和预测性的特征,只用几个特征就能预测出更多的身份类。
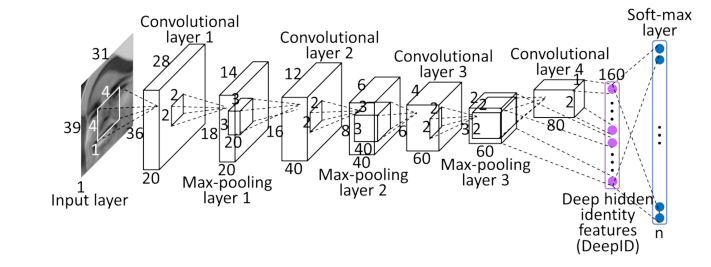
图2. ConvNet结构。每个立方体的长度、宽度和高度表示所有输入层、卷积层和最大池化层的特征图编号和每个特征图的尺寸。里面的小立方体和正方形分别表示卷积层和maxpooling层的三维卷积核大小和二维池化区域大小。每层旁边都标有最后两个完全连接的层的神经元编号。
卷积操作表示为
y j ( r ) = max ( 0 , b j ( r ) + ∑ i k i j ( r ) ∗ x i ( r ) ) , y^{j(r)}=\max \left(0, b^{j(r)}+\sum_{i} k^{i j(r)} * x^{i(r)}\right), yj(r)=max(0,bj(r)+i∑kij(r)∗xi(r)),
其中 x i x^{i} xi和 y j y^{j} yj分别是第 i i i个输入映射和第 j j j个输出映射。 k i j k^{i j} kij是第 i i i个输入映射和第 j j j个输出映射之间的卷积核。 ∗ * ∗表示卷积。 b j b^{j} bj是第 j j j个输出映射的偏差。对隐藏神经元使用 ReLU 非线性( y = max ( 0 , x ) y=\max (0, x) y=max(0,x)),它被证明比 sigmoid 函数具有更好的拟合能力。ConvNet的较高卷积层中的权重在局部共享,以学习不同区域中的不同中级或高级特征。公式1 中的 r r r表示共享权重的局部区域。在第三个卷积层中,权重在每 2 × 2 2 \times 2 2×2个区域中局部共享,而第四个卷积层中的权重完全不共享。最大池化公式为
y j , k i = max 0 ≤ m , n < s { x j ⋅ s + m , k ⋅ s + n i } , y_{j, k}^{i}=\max _{0 \leq m, n< s}\left\{x_{j \cdot s+m, k \cdot s+n}^{i}\right\}, yj,ki=0≤m,n<smax{
xj⋅s+m,k⋅s+ni},
其中第 i i i个输出映射 y i y^{i} yi中的每个神经元汇集在第 i i i个输入映射 x i x^{i} xi中的一个 s × s s \times s s×s非重叠局部区域上。
DeepID 的最后一个隐藏层全连接到第三和第四卷积层(在最大池化之后),因此它可以看到多尺度特征(第四卷积层中的特征比第三层中的特征更具全局性)。这对特征学习至关重要,因为在沿级联连续下采样后,第四卷积层包含的神经元太少,成为信息传播的瓶颈。在第三个卷积层(称为跳过层)和最后一个隐藏层之间添加旁路连接减少了第四个卷积层中可能的信息丢失。最后一个隐藏层取函数
y j = max ( 0 , ∑ i x i 1 ⋅ w i , j 1 + ∑ i x i 2 ⋅ w i , j 2 + b j ) y_{j}=\max \left(0, \sum_{i} x_{i}^{1} \cdot w_{i, j}^{1}+\sum_{i} x_{i}^{2} \cdot w_{i, j}^{2}+b_{j}\right) yj=max(0,i∑xi1⋅wi,j1+i∑xi2⋅wi,j2+bj)
其中 x 1 , w 1 , x 2 , w 2 x^{1}, w^{1}, x^{2}, w^{2} x1,w1,x2,w2分别表示第三和第四卷积层中的神经元和权重。它线性组合了前两个卷积层中的特征,然后是 ReLU 非线性。
ConvNet 输出是一个 n n n-way softmax,预测 n n n个不同身份的概率分布。
y i = exp ( y i ′ ) ∑ j = 1 n exp ( y j ′ ) y_{i}=\frac{\exp \left(y_{i}^{\prime}\right)}{\sum_{j=1}^{n} \exp \left(y_{j}^{\prime}\right)} yi=∑j=1nexp(yj′)exp(yi′)
其中 y j ′ = ∑ i = 1 160 x i ⋅ w i , j + b j y_{j}^{\prime}=\sum_{i=1}^{160} x_{i} \cdot w_{i, j}+b_{j} yj′=∑i=1160xi⋅wi,j+bj线性组合了 160 个 DeepID 特征 x i x_{i} xi作为神经元 j j j的输入, y j y_{j} yj是它的输出。 ConvNet 是通过使用第 t t t个目标类最小化 − log y t -\log y_{t} −logyt来学习的。随机梯度下降与通过反向传播计算的梯度一起使用。
参考文献
[10] S. Chopra, R. Hadsell, and Y . LeCun. Learning a similarity metric discriminatively, with application to face verification. In Proc. CVPR, 2005. 2
[31] Y . Sun, X. Wang, and X. Tang. Hybrid deep learning for face verification. In Proc. ICCV, 2013. 1, 2, 5, 8